
- 1数据结构->手把手教入门栈与列队(基础)
- 2Robust Dynamic Indoor Visible Light Positioning Method Based on CMOS Image Sensor_data rate positioning accuracy
- 3鸿蒙开发入门:构建第一个ArkTS应用(Stage模型)_arkts语言开发文档
- 4c语言统计素数并求和oj,浙大版《C语言程序设计(第3版)》题目集 练习4-11 统计素数并求和...
- 5冒泡排序算法 递归算法,求n的阶乘 求最大公约数和最小公倍数 java分解质因数_n的阶乘的最大公约数
- 6javascript的深拷贝与浅拷贝_javascript深拷贝和浅拷贝
- 7华为鸿蒙os手机版,华为鸿蒙os2.0系统正式版安装包下载-华为鸿蒙2.0系统手机版v2.0安卓版_289手游网下载...
- 8c语言微信挑一挑编程,.NET开发实现一个微信跳一跳的辅助程序
- 9FPGA中仿真概念
- 10【备忘】win 10访问华为荣耀Pro 2路由器USB文件共享_荣耀 路由usb 访问
哈工大|NLP数据增强方法?我有15种
赞
踩
每天给你送来NLP技术干货!
来自:李rumor
卷友们好,我是rumor。

这篇40多页的综述出自哈工大车万翔老师的团队,一共总结了15种NLP可以用到的数据增强方法、优缺点,还有一些使用技巧,十分良心。下面就速读一下,如果要使用的话还是建议参考原文以及其他文献的应用细节。
- 论文:Data Augmentation Approaches in Natural Language Processing: A Survey
- 地址:https://arxiv.org/abs/2110.01852
数据增强方法
数据增强(Data Augmentation,简称DA),是指根据现有数据,合成新数据的一类方法。毕竟数据才是真正的效果天花板,有了更多数据后可以提升效果、增强模型泛化能力、提高鲁棒性等。然而由于NLP任务天生的难度,类似CV的裁剪方法可能会改变语义,既要保证数据质量又要保证多样性,使得大家在做数据增强时十分谨慎。
作者根据生成样本的多样性程度,将DA方法分为了以下三种:
Paraphrasing:对句子中的词、短语、句子结构做一些更改,保留原始的语义
Noising:在保证label不变的同时,增加一些离散或连续的噪声,对语义的影响不大
Sampling:旨在根据目前的数据分布选取新的样本,会生成更多样的数据

Paraphrasing
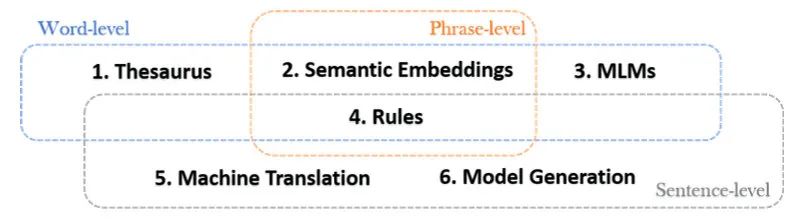
这类方法根据替换的成分不同,又可以分为词、短语、句子级别。作者共总结了6种方法:
Thesaurus:利用词典、知识图谱等外部数据,随机将非停用词替换成同义词或上位词,如果增加多样性的话还可以替换成相同词性的其他词
Semantic Embeddings:利用语义向量,将词或短语替换成相近的(不一定是同义词)。由于每个词都有语义表示,可替换的范围更大。而上一种方法只能替换图谱里的
MLMs:利用BERT等模型,随机mask掉一些成分后生成新的
Rules:利用一些规则,例如缩写、动词变位、否定等,对句子一些成分进行改写,比如把 is not 变成 isn't
Machine Translation:分为两种,Back-translation指把句子翻译成其他语言再翻译回来,Unidirectional Translation指在跨语言任务中,把句子翻译成其他语言
Model Generation:利用Seq2Seq模型生成语义一致的句子
作者还贴心地整理了上述方法的优缺点。其中「歧义」主要是指有些多义词在不同场景下意思不一样,比如「我每天吃一个苹果」,替换成「我每天吃一个iphone」就不合适了。

P.S. 作者写的Strong application我没有太懂,个人觉得可以理解为应用效果好,如果有不同解读可以留言哈。
Noising
人在读文本时对噪声是免疫的,比如单词乱序、错别字等。基于这个思想,可以给数据增加些噪声来提升模型鲁棒性。

作者给出了以上5种增加噪声的方法:
Swapping:除了交换词之外,在分类任务中也可以交换instance或者sentence
Deletion:可以根据tf-idf等词的重要程度进行删除
Insertion:可以把同义词随机插入句子中
Substitution:把一些词随机替换成其他词(非同义),模拟misspelling的场景。为了避免改变label,可以使用label-independent的词,或者利用训练数据中的其他句子
Mixup:这个方法最近两年比较火,把句子表示和标签分别以一定权重融合,引入连续噪声,可以生成不同label之间的数据,但可解释性较差
总的来说,引入噪声的DA方法使用简单,但会对句子结构和语义造成影响,多样性有限,主要还是提升鲁棒性。
这里我私下多加几个没提到的,也是我们在做ConSERT
对抗样本
Dropout:也是SimCSE用到的,还有R-drop,都是通过dropout来加入连续噪声
Feature Cut-off:比如BERT的向量都是768维,可以随机把一些维度置为0,这个效果也不错
Sampling

Sampling是指从数据分布中采样出新的样本,不同于较通用的paraphrasing,采样更依赖任务,需要在保证数据可靠性的同时增加更多多样性,比前两个数据增强方法更难。作者整理了4种方法:
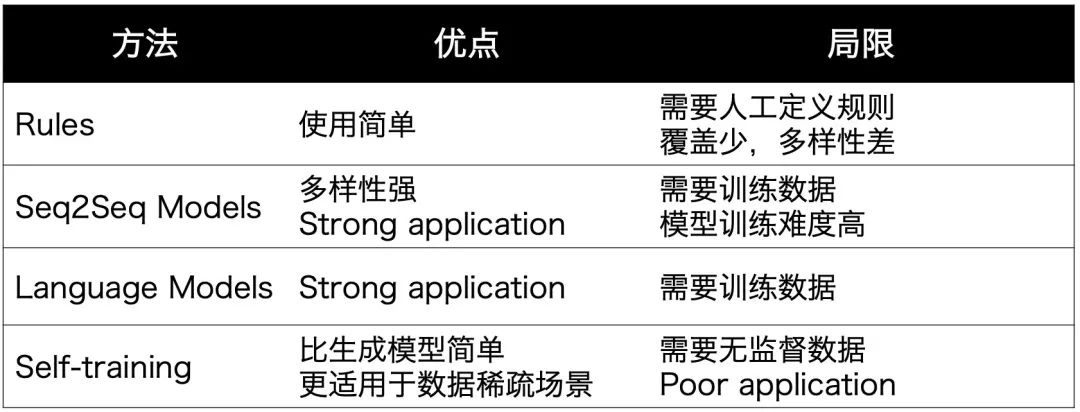
Rules:用规则定义新的样本和label,比如把句子中的主谓进行变换
Seq2Seq Models:根据输入和label生成新的句子,比如在NLI任务中,有研究者先为每个label(entailment,contradiction,neutral)训一个生成模型,再给定新的句子,生成对应label的。对比之下,paraphrasing主要是根据当前训练样本进行复述
Language Models:给定label,利用语言模型生成样本,有点像前阵子看的谷歌UDG。有些研究会加个判别模型过滤
Self-training:先有监督训练一个模型,再给无监督数据打一些标签,有点蒸馏的感觉
作者依旧贴心地给出了4中方法的优点和局限:
使用技巧
方法选择
作者给出了这些方法在6个维度的对比,大家可以更好地体会他们的区别和适用场景。其中Level表示DA方法会增强的部分:t=text, e=embedding, l=label,Granularity表示增强的粒度:w=word, p=phrase, s=sentence。

Method Stacking
实际应用时可以应用多种方法、或者一种方法的不同粒度。
作者推荐了两款工具:
- Easy DA: https://github.com/jasonwei20/eda_nlp
- Unsupervised DA:https://github.com/google-research/uda
同时我搜索了一下github又发现了两个宝藏:
- 英文:https://github.com/makcedward/nlpaug
- 中文:https://github.com/zhanlaoban/eda_nlp_for_Chinese
Optimization
第一,在使用增强的数据时,如果数据质量不高,可以先让模型在增强后的数据上pre-train,之后再用有标注数据训练。如果要一起训练,在增强数据量过大的情况下,可以对原始训练数据过采样
第二,在进行数据增强时注意这些超参数的调整:

第三,其实增强很多简单数据的提升有限,可以注重困难样本的生成。比如有研究加入对抗训练、强化学习、在loss上下文章等。如果用生成方法做数据增强,也可以在生成模型上做功夫,提升数据多样性。
第四,如果生成错数据可能引入更多噪声,可以增加其他模型对准确性进行过滤。
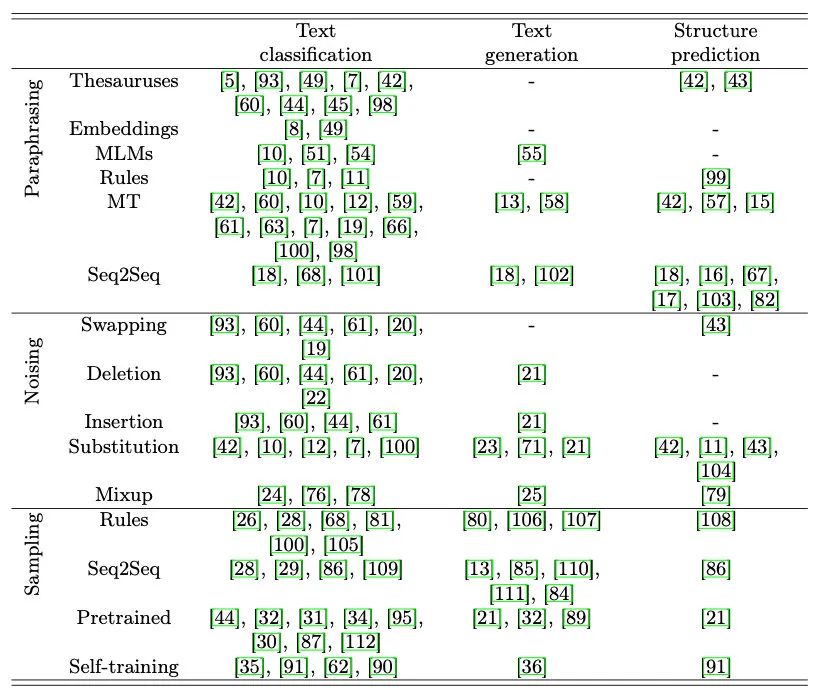
最后,作者列举了其他研究的数据增强应用场景,大家在落地时可以借鉴:
总结
数据增强算是很接地气的研究了,少样本、领域迁移是每个NLPer都会遇到的问题,而在数据上做文章可能比其他模型改动的方法更为有效。同时从这篇综述也可以看到,数据增强其实可以做得很fancy,还不影响线上速度,比如我之前就用T5和ELECTRA做过数据增强,都有一些效果,可谓低调而不失奢华,典雅而不失大气,深度拿捏得稳稳的。
那今天就这样,祝大家早日从假期综合症缓过来,高歌猛进冲刺完2021。
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
整理不易,还望给个在看!

