
热门标签
热门文章
- 1机器学习鸢尾花使用csv
- 2PostgreSQL 聚合函数讲解 - 3 总体|样本 方差, 标准方差_pg数据库求方差函数
- 3用c语言小游戏代码大全,c语言经典游戏代码
- 4Servlet的Cookie和Session机制_servlet cookie session
- 5【鸿蒙开发】第九章 ArkTS语言UI范式-状态管理(一)_鸿蒙强制刷新状态
- 6c语言链表和fifo,HDL的RAM与FIFO <===> C的数组与链表
- 7LeetCode 134. Gas Station (贪心)
- 8HMAC-SHA256 算法介绍_hmacsha256
- 9flask服务中如何request获取请求的headers信息
- 1007爬虫-selenium其它使用方法1,标签切换、窗口切换_爬虫浏览器对象怎么切换
当前位置: article > 正文
关于大模型ChatGLM3-6B在CPU下运行_chatglm3 cpu
作者:小小林熬夜学编程 | 2024-04-13 20:10:34
赞
踩
chatglm3 cpu
最近在调研市场上语言大模型,为公司的产品上虚拟人的推出做准备。各厂提供语言模型都很丰富,使用上也很方便,有API接口可以调用。但唯一的不足,对于提供给百万用户使用的产品,相比价格都比较贵。所以对ChatGLM3-6B的使用做了深入了解,特别只有CPU没有GPU的本地运行,ChatGLM3-6B最好的选择之一。
ChatGLM3-6B的安装见:
chatglm3-6b https://modelscope.cn/models/ZhipuAI/chatglm3-6b/summary
在CPU上运行需要修改下调用方法,以安装文章中的例子做说明:
- from modelscope import AutoTokenizer, AutoModel, snapshot_download
- model_dir = snapshot_download("ZhipuAI/chatglm3-6b", revision = "v1.0.0")
- tokenizer = AutoTokenizer.from_pretrained(model_dir, trust_remote_code=True)
- #model = AutoModel.from_pretrained(model_dir, trust_remote_code=True).half().cuda()
- #cuda使用GPU计算, float使用CPU计算
- model = AutoModel.from_pretrained(model_dir, trust_remote_code=True).half().float()
- model = model.eval()
- response, history = model.chat(tokenizer, "你好", history=[])
- print(response)
- response, history = model.chat(tokenizer, "晚上睡不着应该怎么办", history=history)
- print(response)
将代码中cuda()方法改为float()即可。cuda使用GPU计算, float使用CPU计算。运行的结果如下:
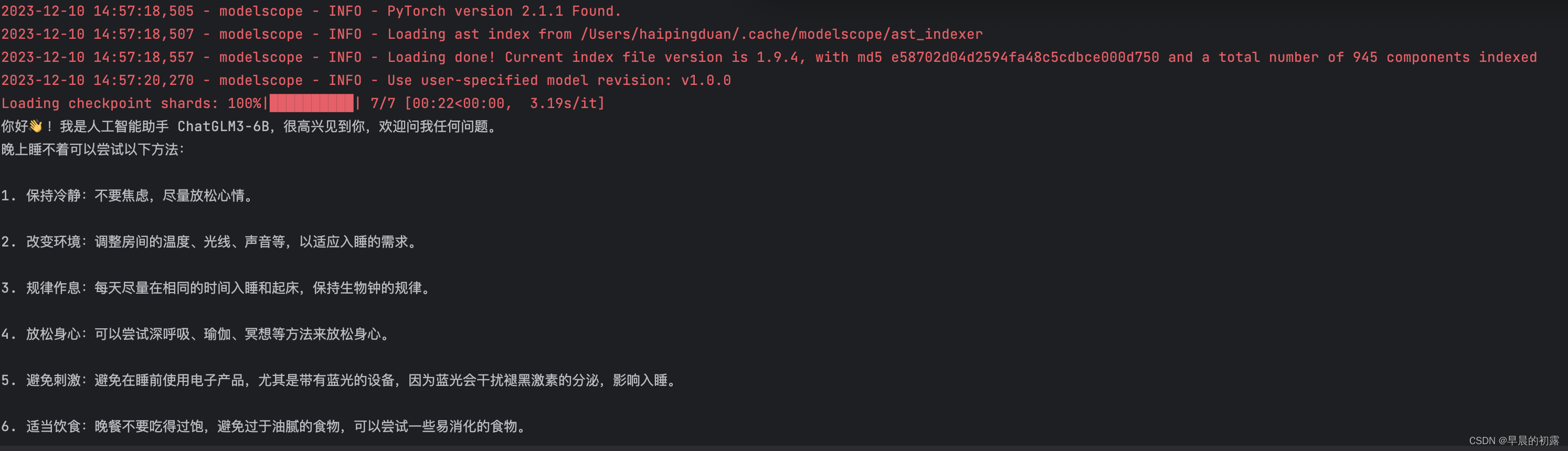
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/小小林熬夜学编程/article/detail/418293
推荐阅读
相关标签

