
热门标签
热门文章
- 1LeetCode39:组合总和
- 2html网页blink是什么,什么是HTML?Web前端基础知识
- 3【雕爷学编程】Arduino智能家居之ESP32-CAM图像流传输到Web页面_esp cam网页图传
- 4STDIN_FILENO
- 5第0章:初识StarRocks_startrocks 支持百亿
- 6axios配置多个接口请求(一)——vue项目axios配置多个接口请求_axios请求多个接口
- 7数据结构实验——查找算法C语言_数据结构查找算法c语言
- 8超详细中文车牌识别开源库EasyPR入门实战(win10_VS2019_opencv34)
- 9【LSTM时序预测】基于贝叶斯网络优化CNN-LSTM实现股票价格预测附matlab代码_lstm预测股票准确率一般多少
- 10使用mqtt.fx通过mqtt协议将数据上传到onenet平台,并使用mqtt命令下发接收消息_onenet 新版 mqtt.fx
当前位置: article > 正文
开源模型应用落地-chatglm3-6b-zero/one/few-shot-入门篇(五)
作者:盐析白兔 | 2024-04-12 06:57:05
赞
踩
开源模型应用落地-chatglm3-6b-zero/one/few-shot-入门篇(五)
一、前言
Zero-Shot、One-Shot和Few-Shot是机器学习领域中重要的概念,特别是在自然语言处理和计算机视觉领域。通过Zero-Shot、One-Shot和Few-Shot学习,模型可以更好地处理未知的情况和新任务,减少对大量标注数据的依赖,提高模型的适应性和灵活性。这对于推动人工智能在现实世界中的应用具有重要意义,尤其是在面对数据稀缺、标注成本高昂或需要快速适应新环境的场景下。
二、术语
2.1. Zero-shot
在零样本学习中,模型可以从未见过的类别中进行推理或分类。这意味着模型可以使用在其他类别上学到的知识来推广到新的类别,而无需在新类别上进行训练。
2.2. One-shot
在单样本学习中,模型根据非常有限的样本进行学习。通常情况下,模型只能从每个类别中获得一个样本,并且需要从这个样本中学习如何进行分类。
2.3. Few-shot
在少样本学习中,模型可以通过很少的样本进行学习,并且能够推广到新的类别。虽然少样本学习的定义没有具体的样本数量限制,但通常指的是模型只能从每个类别中获得很少的样本(例如,几个或几十个)。
三、前置条件
3.1. windows or linux操作系统均可
3.2. 下载chatglm3-6b模型
从huggingface下载:https://huggingface.co/THUDM/chatglm3-6b/tree/main

3.3. 创建虚拟环境&安装依赖
- conda create --name chatglm3 python=3.10
- conda activate chatglm3
- pip install protobuf transformers==4.30.2 cpm_kernels torch>=2.0 sentencepiece accelerate
四、技术实现
4.1.Zero-Shot
- # -*- coding = utf-8 -*-
- from transformers import AutoTokenizer, AutoModelForCausalLM
- import time
- import traceback
-
- modelPath = "/model/chatglm3-6b"
-
- def chat(model, tokenizer, message, history, system):
- messages = []
- if system is not None:
- messages.append({"role": "system", "content": system})
-
- if history is not None:
- for his in history:
- user,assistant = his
- messages.append({"role": "user", "content": user})
- messages.append({"role": "assistant", 'metadata': '', "content": assistant})
-
- try:
- for response in model.stream_chat(tokenizer,message, messages, max_length=2048, top_p=0.9, temperature=0.45, repetition_penalty=1.1,do_sample=True):
- _answer,_history = response
- yield _answer
-
- except Exception:
- traceback.print_exc()
-
- def loadTokenizer():
- tokenizer = AutoTokenizer.from_pretrained(modelPath, use_fast=False, trust_remote_code=True)
- return tokenizer
-
-
- def loadModel():
- model = AutoModelForCausalLM.from_pretrained(modelPath, device_map="auto", trust_remote_code=True).cuda()
- model = model.eval()
- # print(model)
- return model
-
-
- if __name__ == '__main__':
- model = loadModel()
- tokenizer = loadTokenizer()
-
- start_time = time.time()
-
-
- message = '''
- 我希望你根据关系列表从给定的输入中抽取所有可能的关系三元组,并以JSON字符串[{'head':'', 'relation':'', 'tail':''}, ]的格式回答,relation可从列表['父母', '子女', '祖孙', '配偶']中选取,注意不需要返回不相关的内容。
- 给定输入:2023年,张三和王五结婚生了个女儿,叫王雨菲
- '''
- system = '你是一个人工智能助手,很擅长帮助人类回答问题'
- history = None
-
- response = chat(model, tokenizer, message,history,system)
- for answer in response:
- print(answer)
-
- end_time = time.time()
- print("执行耗时: {:.2f}秒".format(end_time - start_time))

调用结果:

4.2.One-Shot
- # -*- coding = utf-8 -*-
- from transformers import AutoTokenizer, AutoModelForCausalLM
- import time
- import traceback
-
- modelPath = "/model/chatglm3-6b"
-
- def chat(model, tokenizer, message, history, system):
- messages = []
- if system is not None:
- messages.append({"role": "system", "content": system})
-
- if history is not None:
- for his in history:
- user,assistant = his
- messages.append({"role": "user", "content": user})
- messages.append({"role": "assistant", 'metadata': '', "content": assistant})
-
- try:
- for response in model.stream_chat(tokenizer,message, messages, max_length=2048, top_p=0.9, temperature=0.45, repetition_penalty=1.1,do_sample=True):
- _answer,_history = response
- yield _answer
-
- except Exception:
- traceback.print_exc()
-
- def loadTokenizer():
- tokenizer = AutoTokenizer.from_pretrained(modelPath, use_fast=False, trust_remote_code=True)
- return tokenizer
-
-
- def loadModel():
- model = AutoModelForCausalLM.from_pretrained(modelPath, device_map="auto", trust_remote_code=True).cuda()
- model = model.eval()
- # print(model)
- return model
-
-
- if __name__ == '__main__':
- model = loadModel()
- tokenizer = loadTokenizer()
-
- start_time = time.time()
-
-
- message = '''
- 我希望你根据关系列表从给定的输入中抽取所有可能的关系三元组,并以JSON字符串[{'head':'', 'relation':'', 'tail':''}, ]的格式回答,relation可从列表['父母', '子女', '祖孙', '配偶']中选取,注意不需要返回不相关的内容。
- 你可以参照以下示例:
- 示例输入:在三十年前的一个风雨交加的夜晚,张三生了个儿子李四。
- 示例输出:{"head": "张三","relation": "父子","tail": "李四"}。
- 给定输入:2023年,张三和王五结婚生了个女儿,叫王雨菲
- '''
- system = '你是一个人工智能助手,很擅长帮助人类回答问题'
- history = None
-
- response = chat(model, tokenizer, message,history,system)
- for answer in response:
- print(answer)
-
- end_time = time.time()
- print("执行耗时: {:.2f}秒".format(end_time - start_time))
调用结果:

4.3.Few-Shot
- # -*- coding = utf-8 -*-
- from transformers import AutoTokenizer, AutoModelForCausalLM
- import time
- import traceback
-
- modelPath = "/model/chatglm3-6b"
-
- def chat(model, tokenizer, message, history, system):
- messages = []
- if system is not None:
- messages.append({"role": "system", "content": system})
-
- if history is not None:
- for his in history:
- user,assistant = his
- messages.append({"role": "user", "content": user})
- messages.append({"role": "assistant", 'metadata': '', "content": assistant})
-
- try:
- for response in model.stream_chat(tokenizer,message, messages, max_length=2048, top_p=0.9, temperature=0.45, repetition_penalty=1.1,do_sample=True):
- _answer,_history = response
- yield _answer
-
- except Exception:
- traceback.print_exc()
-
- def loadTokenizer():
- tokenizer = AutoTokenizer.from_pretrained(modelPath, use_fast=False, trust_remote_code=True)
- return tokenizer
-
-
- def loadModel():
- model = AutoModelForCausalLM.from_pretrained(modelPath, device_map="auto", trust_remote_code=True).cuda()
- model = model.eval()
- # print(model)
- return model
-
-
- if __name__ == '__main__':
- model = loadModel()
- tokenizer = loadTokenizer()
-
- start_time = time.time()
-
-
- message = '''
- 我希望你根据关系列表从给定的输入中抽取所有可能的关系三元组,并以JSON字符串[{'head':'', 'relation':'', 'tail':''}, ]的格式回答,relation可从列表['父母', '子女', '祖孙', '配偶']中选取,注意不需要返回不相关的内容。
- 你可以参照以下示例:
- 示例输入1:在三十年前的一个风雨交加的夜晚,张三生了个儿子李四。
- 示例输出1:{"head": "张三","relation": "父子","tail": "李四"}。
- 示例输入2:小明和小李上个月结婚了。
- 示例输出2:{"head": "小明","relation": "配偶","tail": "小李"}。
- 给定输入:2023年,张三和王五结婚生了个女儿,叫王雨菲
- '''
- system = '你是一个人工智能助手,很擅长帮助人类回答问题'
- history = None
-
- response = chat(model, tokenizer, message,history,system)
- for answer in response:
- print(answer)
-
- end_time = time.time()
- print("执行耗时: {:.2f}秒".format(end_time - start_time))

五、附带说明
5.1.测试结果
ChatGLM3-6B模型规模相对较小,在关系抽取测试任务中表现一般,在同样的模型参数和测试数据下,QWen1.5-7B-Chat的表现会更加优异,在Zero-Shot场景下,也有较好的表现。具体测试情况如下:
Zero-Shot:基本能识别出关系三元组,同时返回较多无效内容

One-Shot:能准确识别出关系三元组,且无返回无效内容
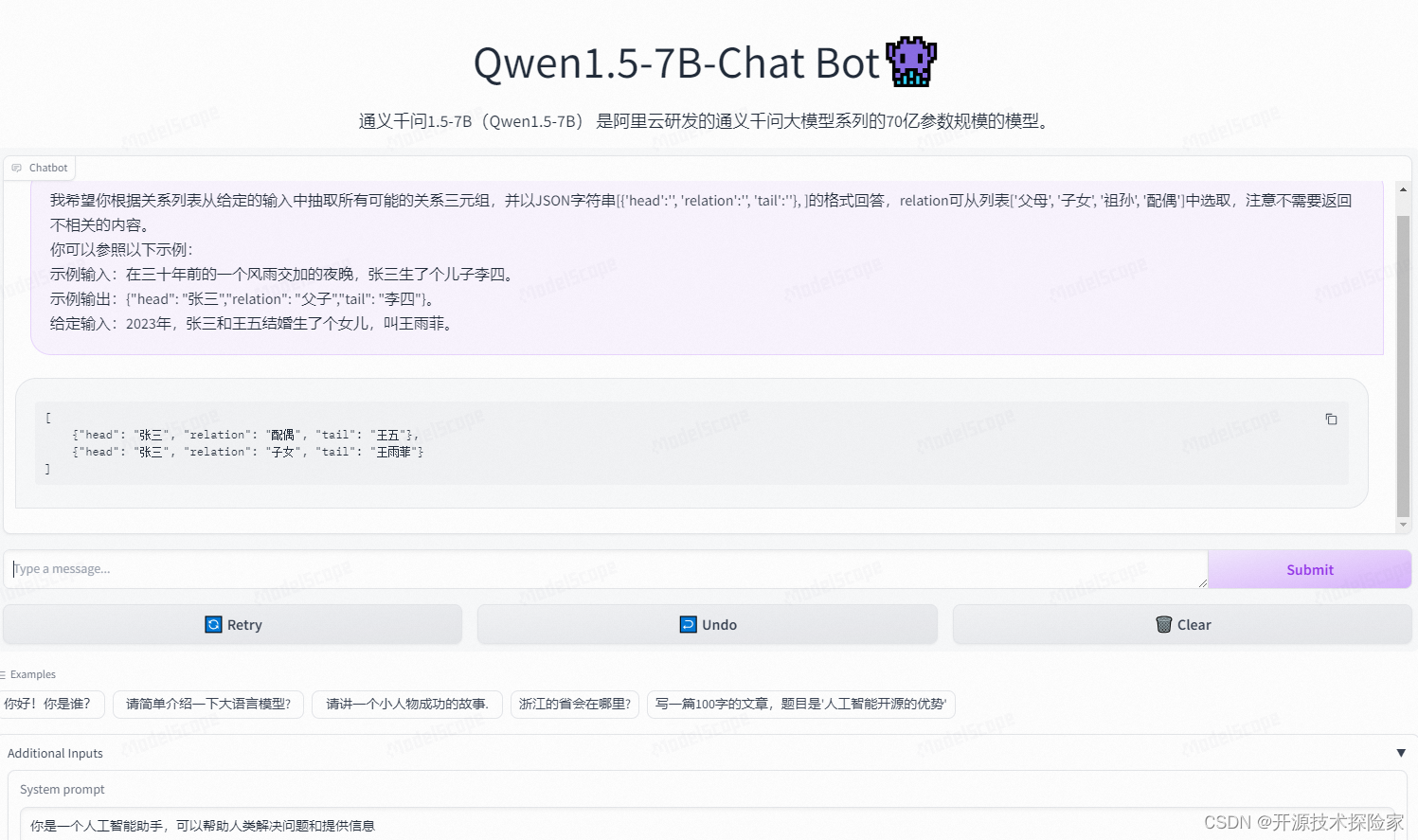
Few-Shot:能准确识别出关系三元组,且无返回无效内容
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/盐析白兔/article/detail/409648
推荐阅读
相关标签

