- 1Python发送邮件报错 smtplib.STMPDataError_smtplib.smtpdataerror: (550, b'the "from" header i
- 2Tensorflow---使用Tensorflow初步进行卷积层的基本使用_tensorflow如何让数据直接进入卷积层
- 3【OpenCV】 基础入门(一)初识 Mat 类 | 通过 Mat 类显示图像_cv::mat显示图片
- 4【测试开发八股文】算法
- 5浅谈DNS和HOSTS文件的区别和关系_dns和hosts的区别
- 6打破深度学习局限,强化学习、深度森林或是企业AI决策技术的“良药”
- 7抖音直播带货如何做好抖音直播间数据,提升权重?_直播带货流量比例搜索比例大
- 8EasyCVR打造基于人工智能和增强现实技术的智能运检系统“AR巡检”_ar眼镜巡检 csdn
- 9Vivado之实现(布局布线)流程浅析_vivado布局布线
- 10Devin:一位半吊子程序员,还是即将成为编程超级特工?
redis_akkeys-ttl
赞
踩
redis笔记
借鉴大牛的文章,原出处:尚硅谷
借鉴大牛的教程,原出处:https://www.cnblogs.com/rjzheng/p/9041659.html
缓存雪崩,击穿,穿透
对于这三种情况,1.将redis和数据库部署成高可用集群
2.及时进行服务降级与限流
3.持久化数据库,宕机后及时恢复数据
缓存雪崩
redis存储了很多key-value数据,意外情况下,这些数据同一时间过期,此时服务器收到很多查询这些key的请求,由于redis过期了,只能去数据库查,大的ops下,数据库炸了
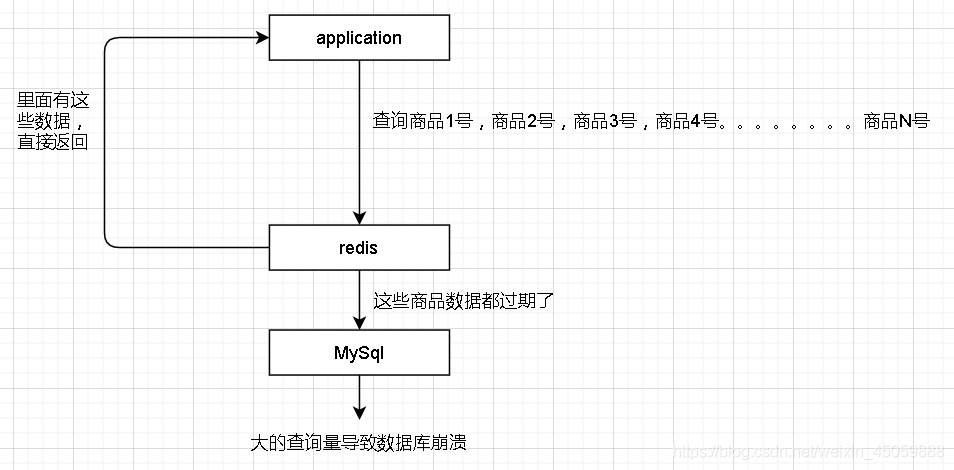
解决方法:1.给redis数据设置不同的过期时间
2.不设置过期时间
3.做个定时任务,时间过期前再赋值下过期时间
4.假如redis崩了,做个限流
缓存击穿
如有一个热门商品,id=6688,每天很多人查询,就把他放在redis里面,就不用查询数据库,意外情况下这个数据在redis过期了,导致大量ops访问数据库,数据库炸了
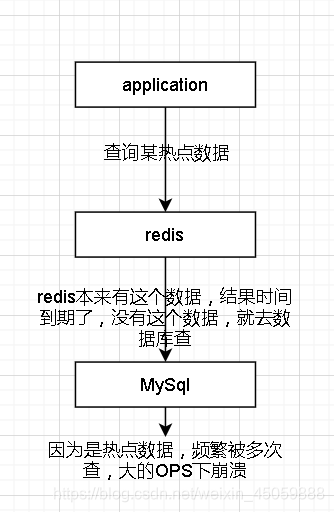
解决方法:1.不设置过期时间
2.分布式锁(多个线程访问这个数据,先上锁让其中一个线程访问数据库并把得到的数据放入redis,其它线程就可以访问redis而不访问数据库)
缓存穿透
假如数据的id都是大于1的值,此时频繁访问id不存在的数据,导致redis去查数据库,大的ops导致数据库炸了
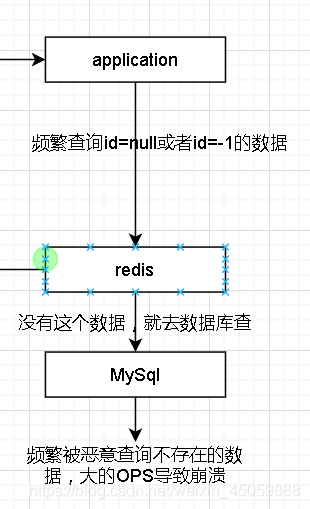
解决方法:1.给不存在的key值设置null值返回空
2.布隆过滤器
3.访问参数校验(访问id<1直接pass)
布隆过滤器
一个类似map结构由非常多个key是bit的k-v型结构,value是1或者0,key是下标。基本思想是:过来一个需要被过滤的值,布隆过滤器会使用多个特殊的算法来得到多个结果不同的值,并将这些结果(比如1,4,7)所对应的下标的value赋值1(下标为1,4,7的value置为1)。当下次这个需要被过滤的值进来时,布隆过滤器经过特殊算法得到这个值所对应的下标,如果发现都为1则通过,如果有一处为0则不通过。
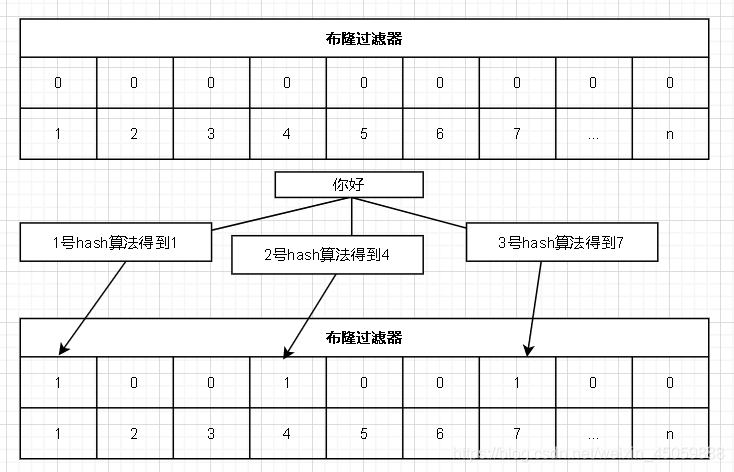
缺点
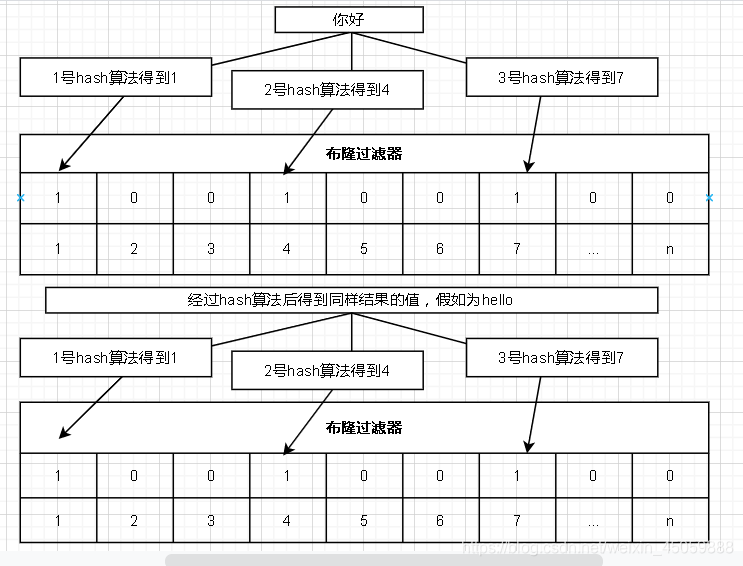
如下图所示,假如“你好”和“hello”经过布隆过滤器的算法后得到同样的值,则处理过“你好”后,下次来了“hello”过滤器依旧会放行
缓存与数据库一致性问题
这里借鉴大牛的文章,原出处:https://www.cnblogs.com/rjzheng/p/9041659.html
大概有下面两种方法。
1.先更新数据库,再更新缓存
2.先更新数据库,再删除缓存
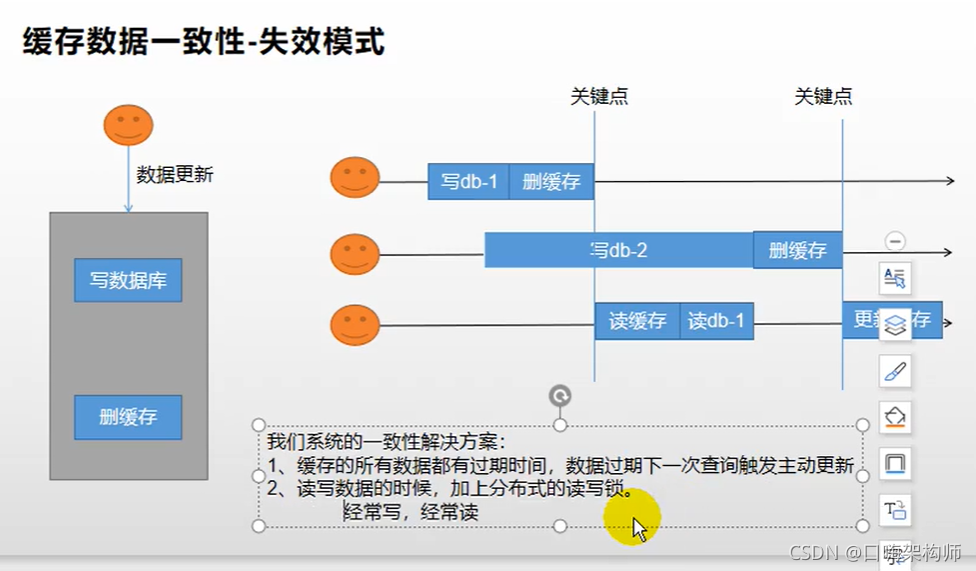
结论:先更新数据库,再删除缓存
先更新数据库,再删除缓存(Facebook公司在用)
这种也会出现并发问题,但是几率很小!!!如下所示
一般来讲读操作要比写操作快,所以这种情况应该不会发生,如果非要杜绝这种情况,也要操作延迟删除策略(消息队列)。也就是二次删除
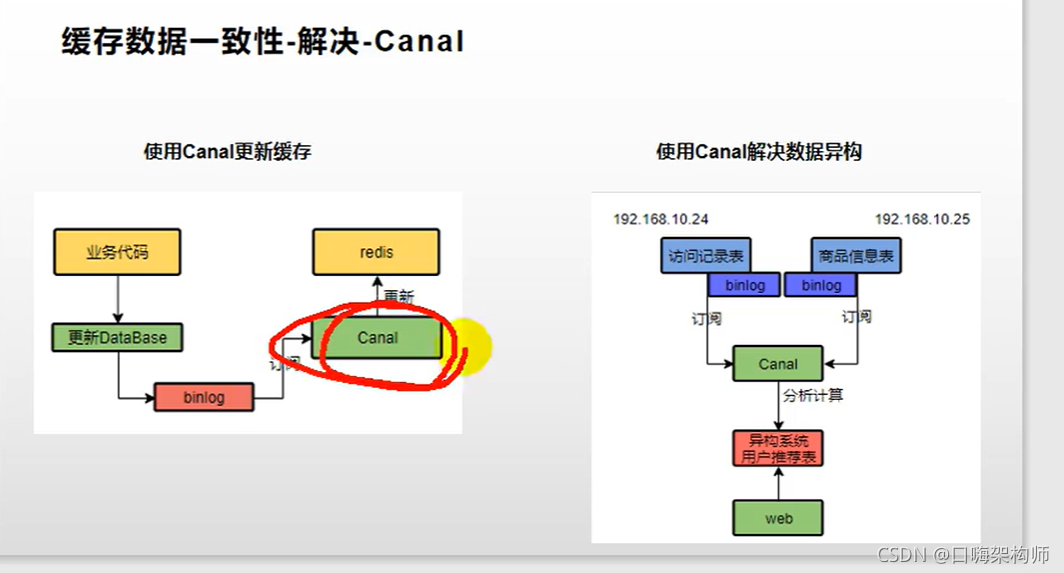
2.也可以使用阿里的canle解决缓存一致性
redis的过期策略和淘汰机制
过期策略:
1.定期删除:每隔100ms随机检查一些Key是否过期,如果是,将删除这些key
2.懒惰删除:当查询此key时查看该key是否过期,如果是则删除key并返回null
淘汰机制:
当内存到达一定量时,进行删除key的操作,这个量可在Redis配置文件中设置maxmemory。
noeviction:默认配置,当数据量满了就不能添加数据。
volatile-lru:从设置过期时间的key中挑选最近最少使用的删除
volatile-ttl:从设置过期时间的key中挑选快过期的key删除
volatile-lfu:从设置过期时间的key中挑选使用次数最少的删除
volatile-random:从设置过期时间的key中随机挑选一个删除
allkeys-random:从设置过期时间的key中随机挑选一个删除
allkeys-lru:从所有的key中挑选最近最少使用的删除
allkeys-ttl:从所有的key中挑选快过期的key的删除
allkeys-lfu:从所有的key中挑选使用次数最少的删除
分布式锁
1.redis可以解决的问题
性能与并发
1.性能:当一个sql的结果很长一段时间不会更改且查询耗费时间时,将查询结果放入缓存
2.并发:成千上万的请求直接找数据库,数据库支撑不了
redis作为一款非关系型数据库,属于NoSql(not-only-sql)数据库,因为其存储结构为key-value形式,所以可以被当作缓存数据库来使用,在分布式系统下,可以有效的解决高并发及数据不一致等问题。比如售卖场景,秒杀场景,热搜场景,登录场景等等。。。。
2.redis的概述
redis特点
1.简单的存储结构,key-value型存储结构
2.不遵循sql标准,不支持acid,效率远超sql
redis适用与非适用场景
1.高并发,大数据下的读写可以使用
2.需要事务,需要条件查询时不可使用
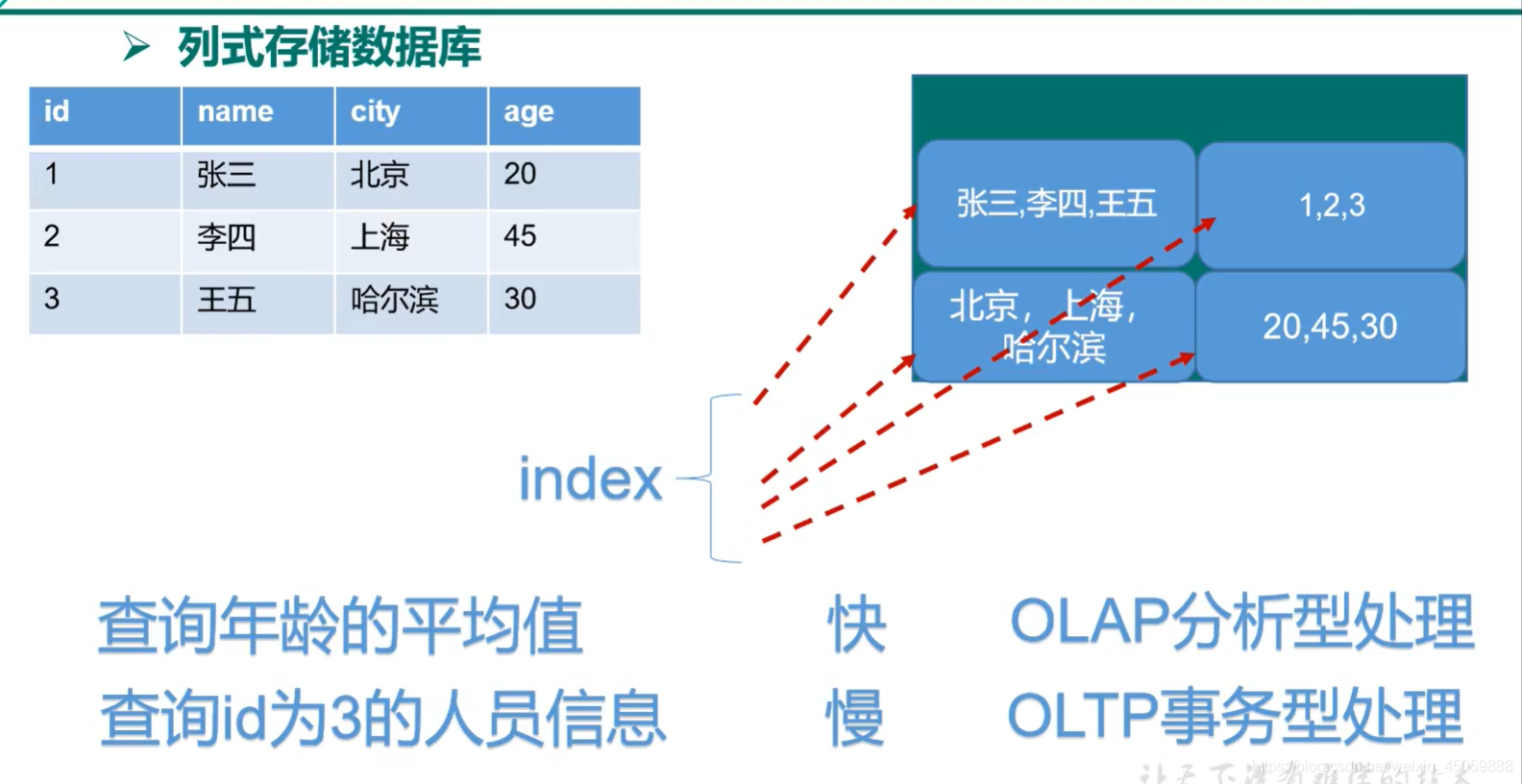
题外话:列式数据库与行式数据库的区别
比如有三行人员数据,有两个需求
1.查询id=1的人员信息
2.查询三行人员信息的年龄的平均值
查1时用行式快,因为列式需要把所有列都查询一遍拿出其中所需要的值,查2时用列快,因为行式需要把所有行都查一下拿出需要的值。
3.安装redis
Linux的centos7下安装
以3.2.5版本为例子
1.进入系统下的/opt目录
执行wget http://download.redis.io/releases/redis-3.2.5.tar.gz
2.当下载压缩包完成时
执行tar -zxvf redis-3.2.5.tar.gz
3.解压好后下载gcc和gcc-c++
yum install gcc
yum install gcc-c++
4.进入解压好的redis目录中编译
cd /redis-3.2.5
make
5.最后一步
make install
4.启动redis
redis的工具
1.首先如下图所示,先进入redis的文件夹中,复制redis.conf文件
我的命令:
①:cd /opt/redis-3.2.5 (进入redis文件夹中)
②:mkdir /opt/myRedis (在opt文件夹创建一个myRedis的文件夹)
③:cp redis.conf /opt/myRedis/redis.conf (把本目录下的redis.conf复制到/opt/myRedis目录下,起名叫redis.conf)
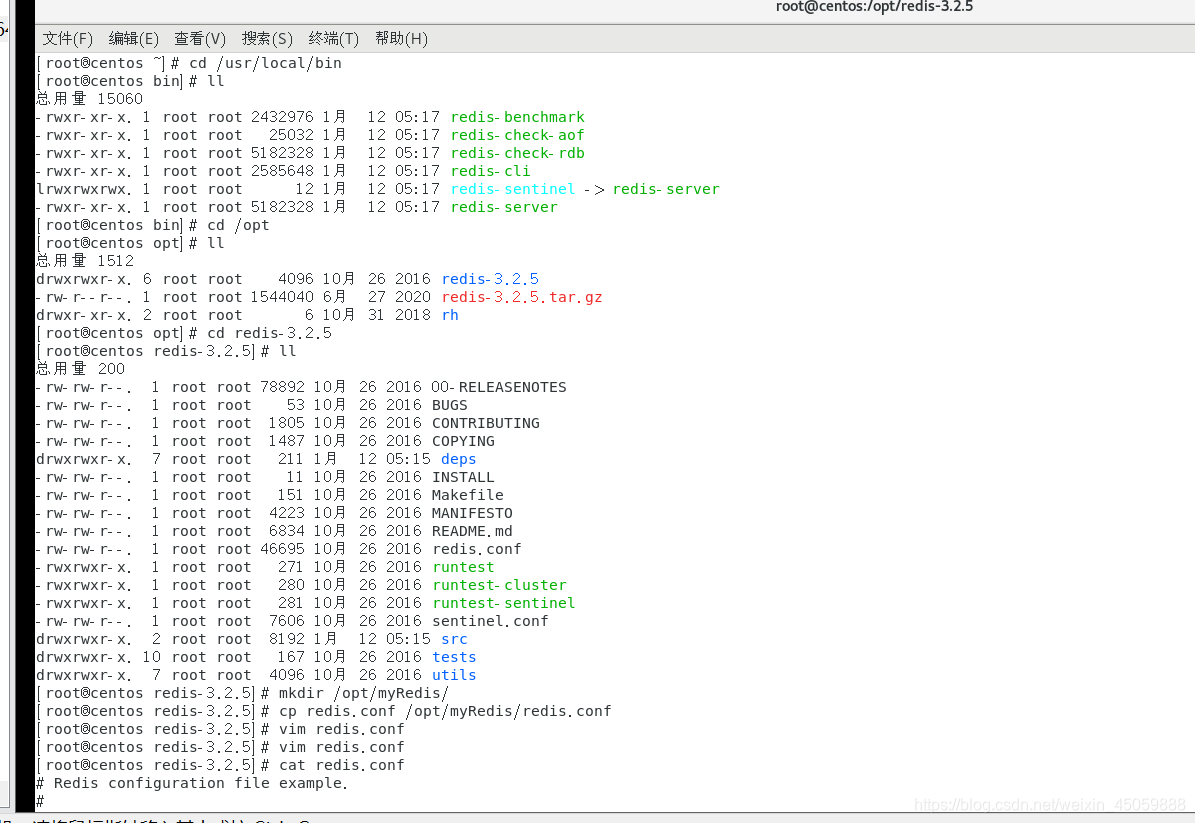
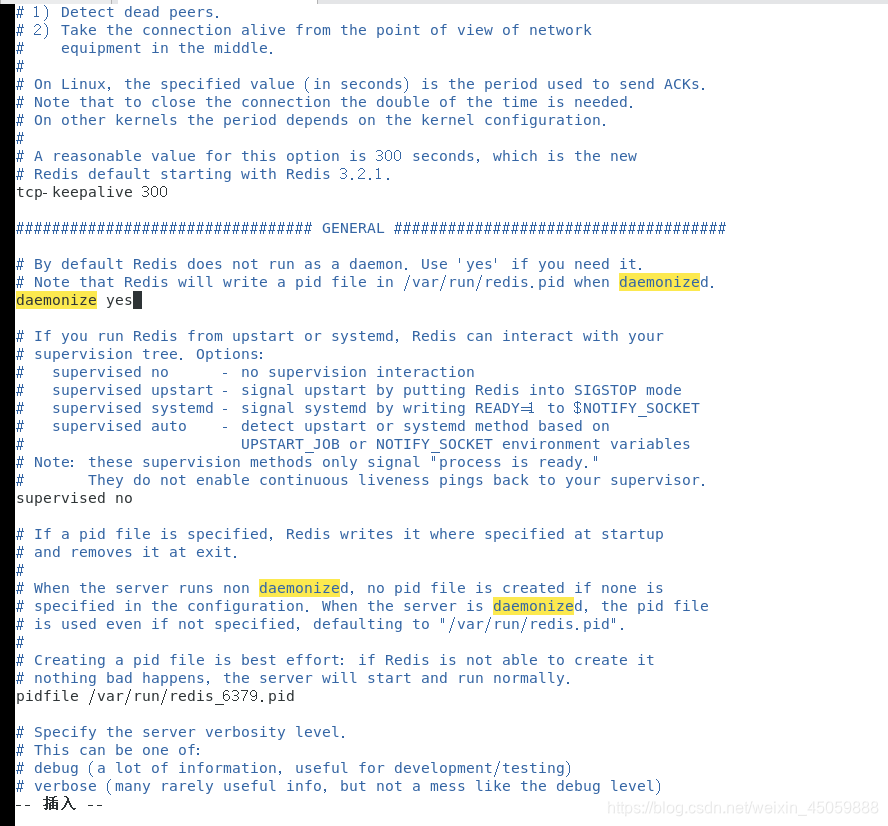
2:更改本目录下redis.conf,修改如下图 daemonize 后面的No改成yes
3:启动redis服务
命令:redis-server redis.conf (启动时保证本目录下有redis.conf)
输入 ps -ef | grep redis,如果出现redis-server 127.0.0.1:6379则说明开启成功
输入 redis-cli 启动redis客户端,完整写法为:redis-cli -h 127.0.0.1 -p 6379,-h与-p分别为地址与端口
客户端启动成功后,输入ping如果出现pong就是成功了
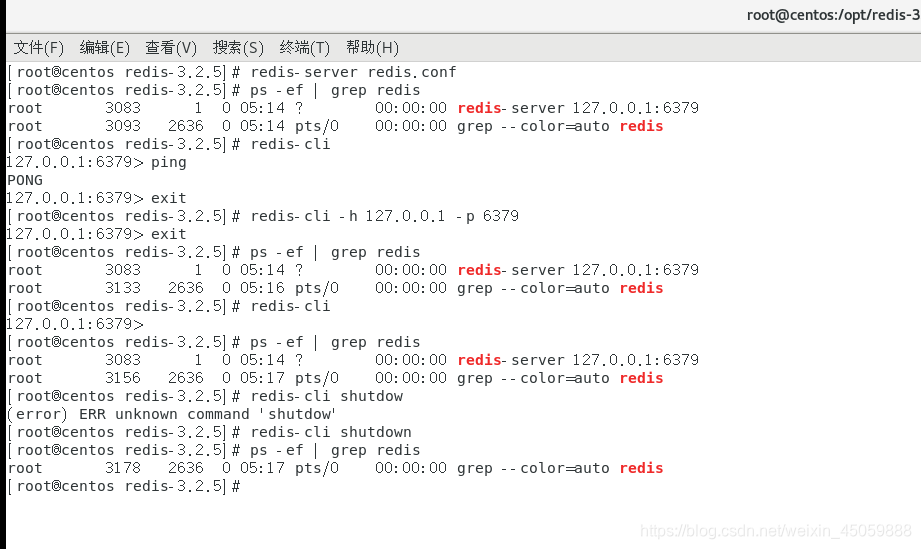
4:redis的关闭:redis-cli shutdown
5.redis的多路复用
redis默认有16个库,可以用select x(具体数字)来选择要用的库
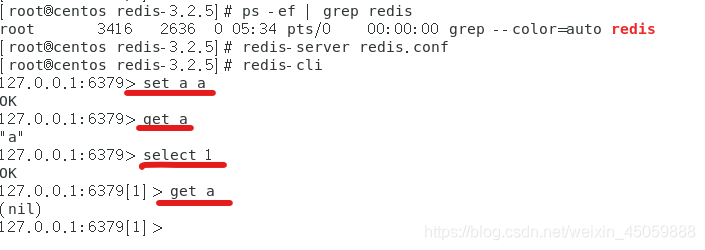
引用逼乎用户“柴小喵”的回答,redis采用IO多路复用模型,虽然采用的是单线程,但是这个单线程可随时监视socket的活动,哪个socket可以处理就去处理哪个

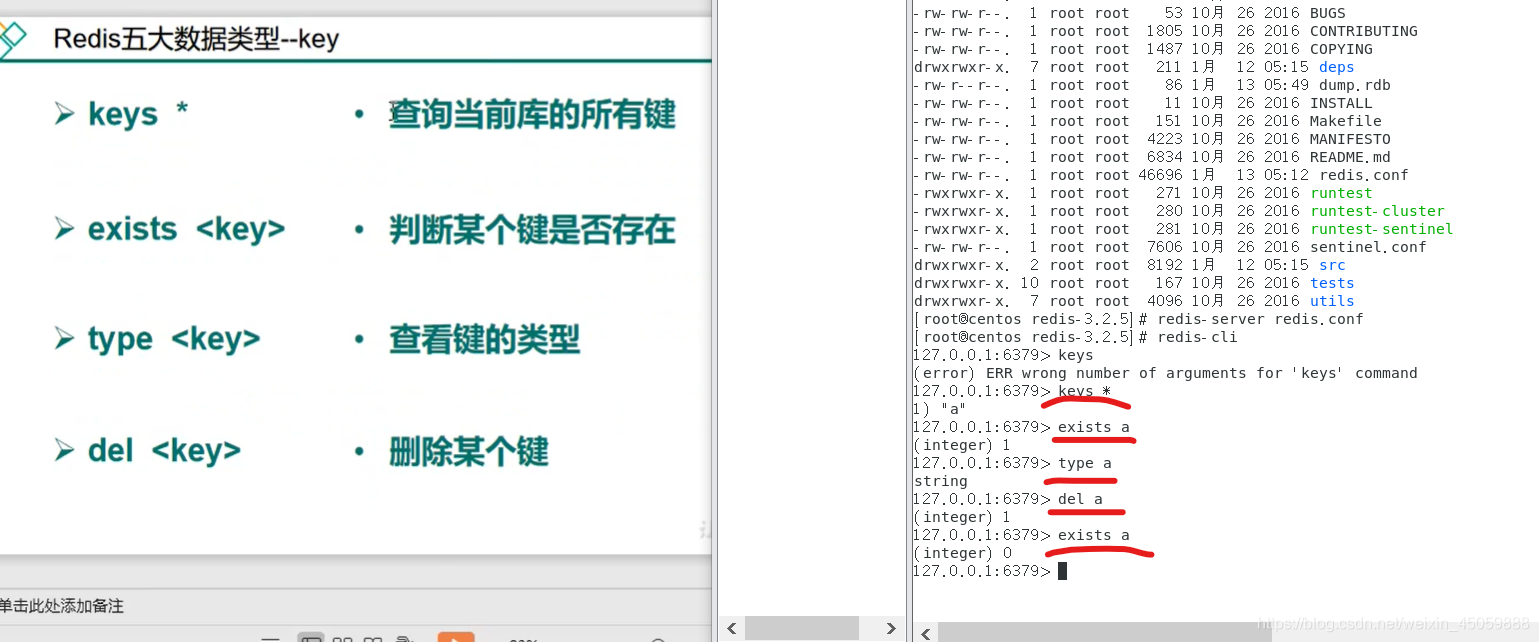
6.redis基本指令
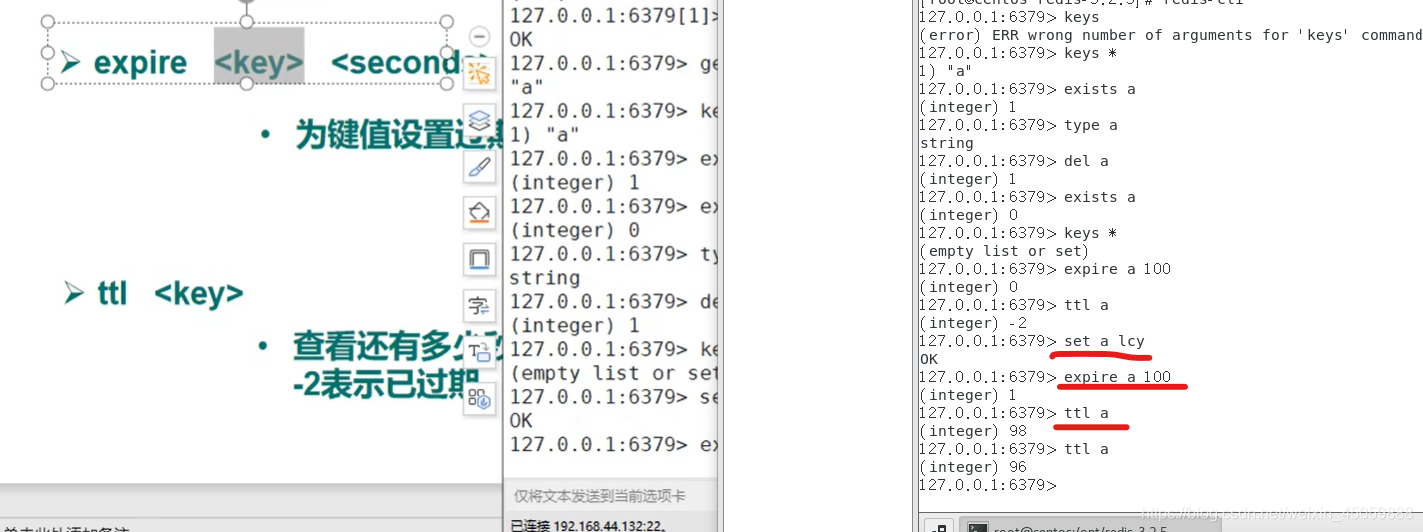
设置键的过期时间,ttl 键 时,-2代表已过期,-1代表永不过期

string类型





LIST类型
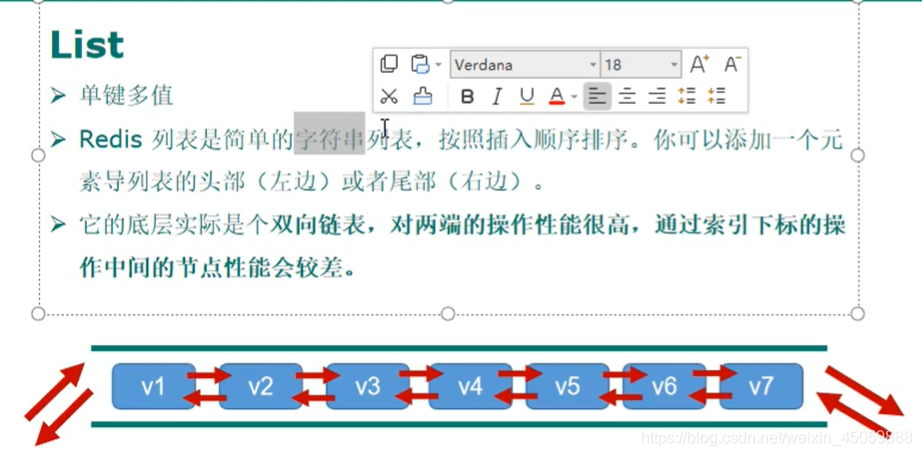

list的lpush是头插法,rpush是尾插法,所以lpush插入的数据是倒序的
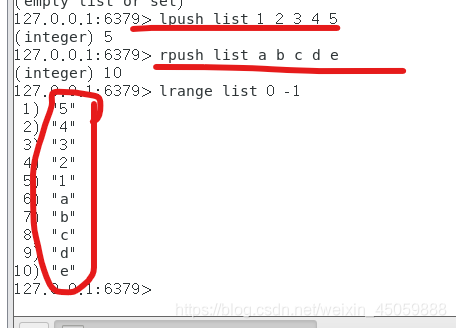
list获取所有数据:lrange 0 -1,-1表示右边最后一个

linsert 的after可写成before,意为在value的前面插入
lrem中的n如果是正整数代表从左往右删除n个,如果是负整数代表从右往左删除n个,如果是0代表删除全部。

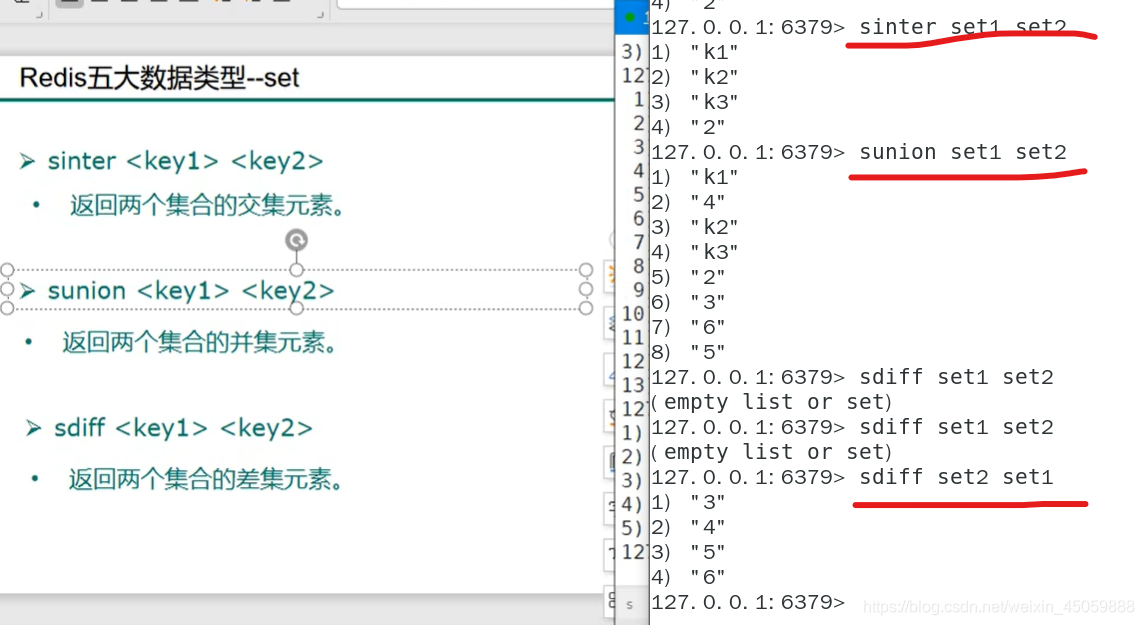
set类型



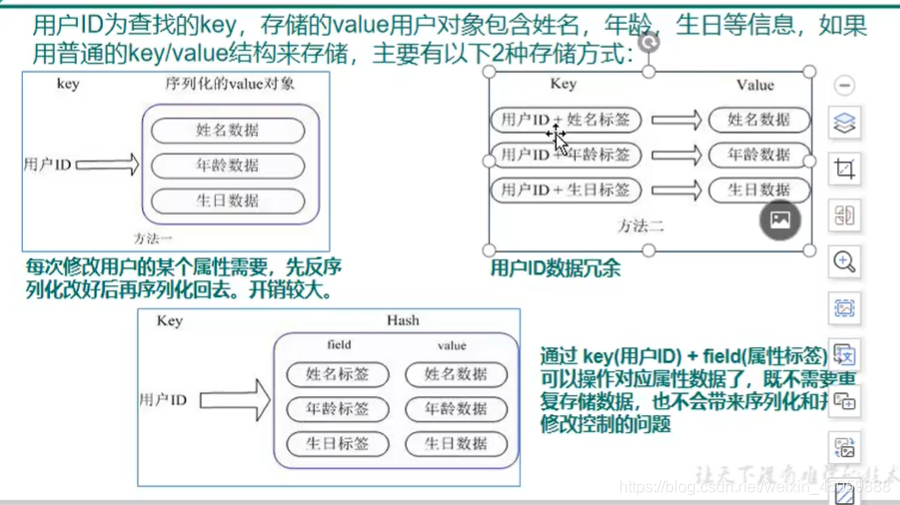
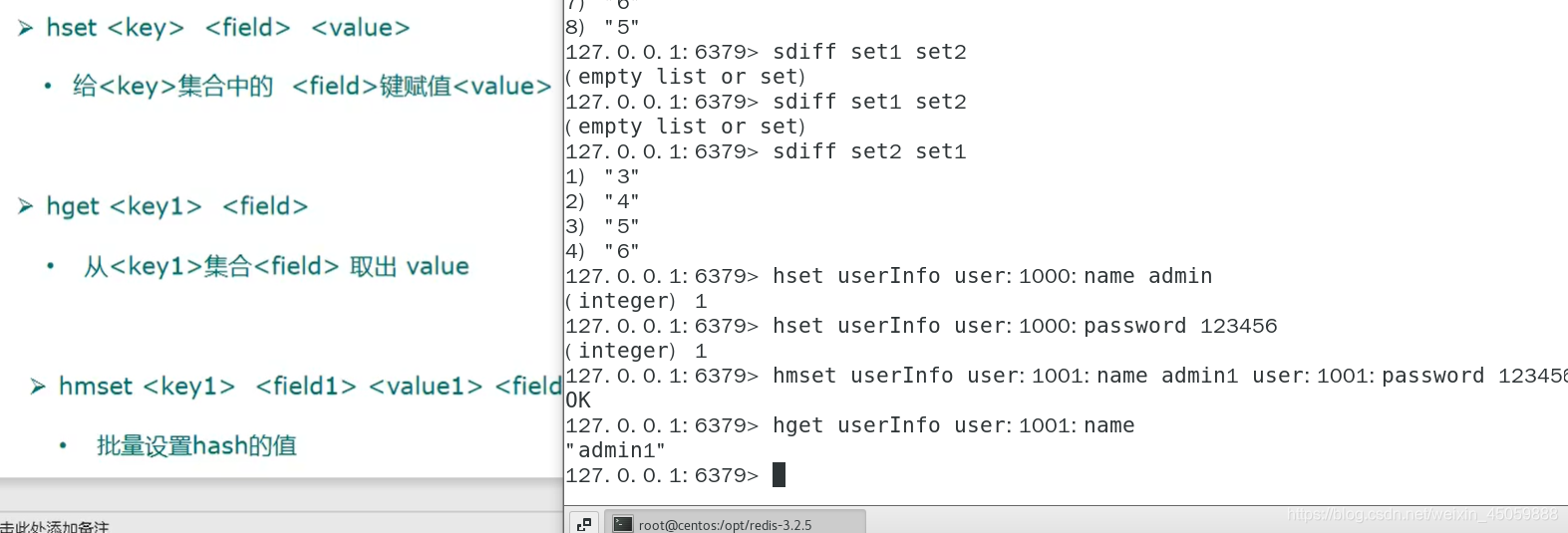
hash类型
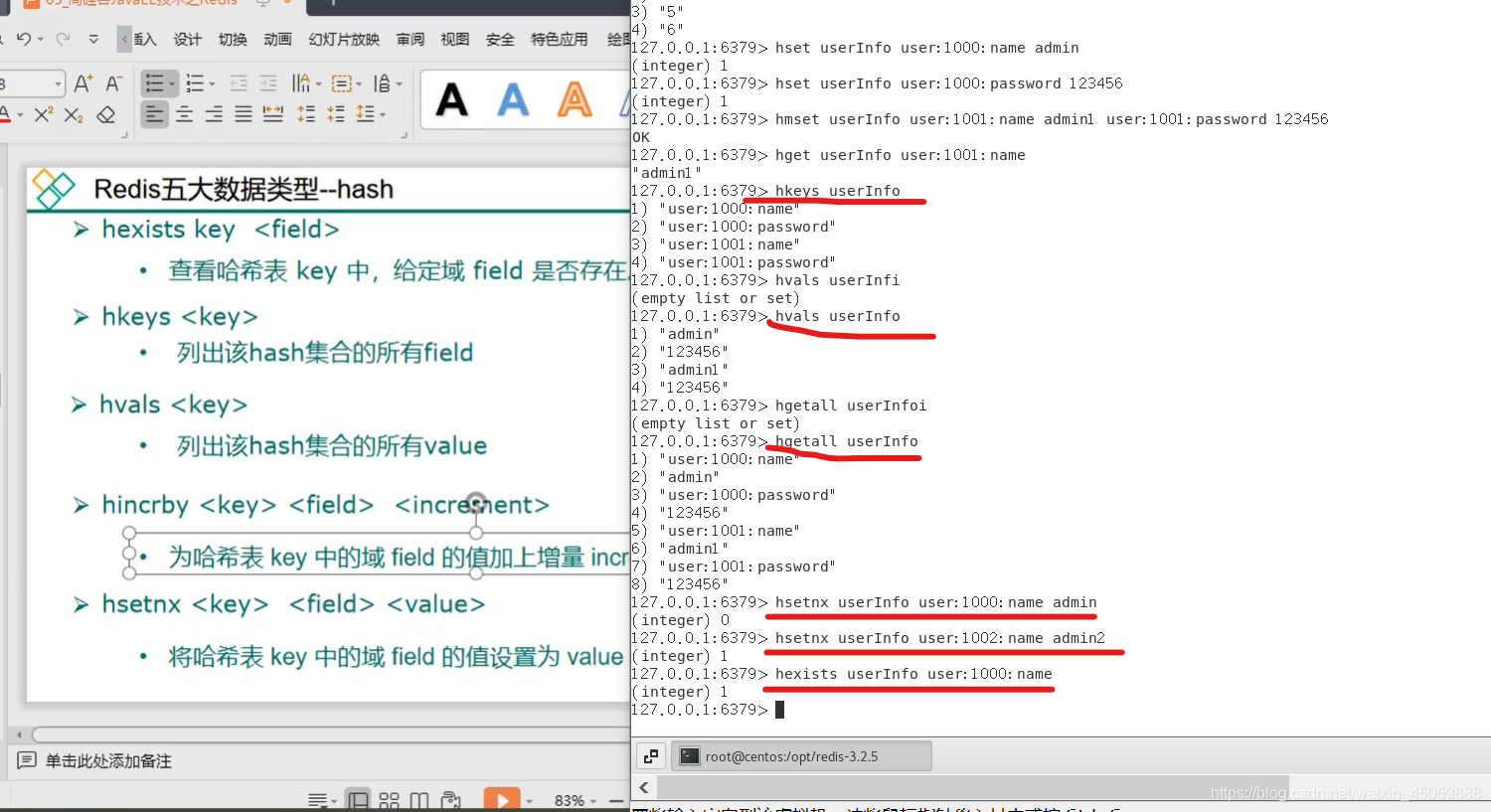
zset类型
zrange可以使用下标0 -1来查询全部
zadd 如果分数不同,值相同则原来的值会覆盖
如果分数相同,值不同则正常插入正常排序


使用zset模拟文章访问量排名
使用score做点击量,使用value做标题。
然后使用ZREVRANGEBYSCORE做从小到大的排序,可以指定点击量,如下图筛选点击量3000-5000的,ZREVRANGEBYSCORE的score需要从大到小写

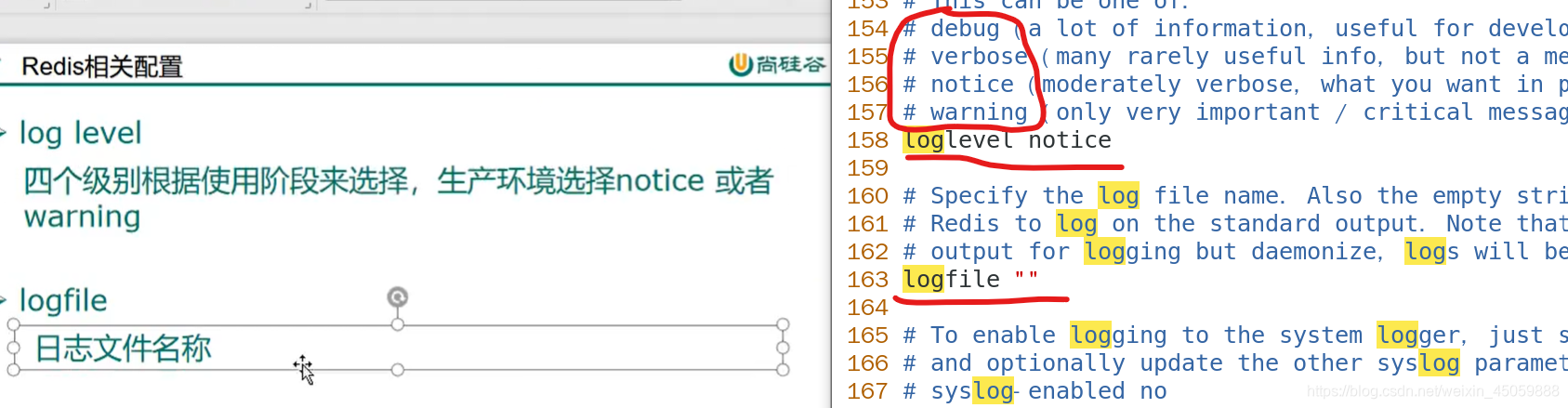
7.redis配置相关

vim redis.conf编辑配置文件,
按冒号进入命令行模式,set nu显示行号,shift+g跳转最后,
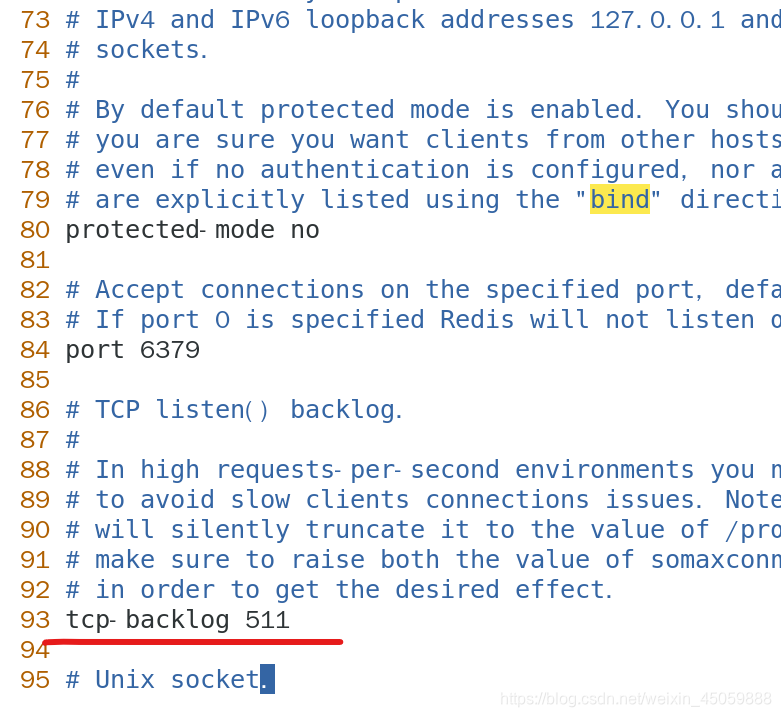
/bind查询bind,按n查找下一个,这里表示只能127.0.0.1访问,想别的主机访问此redis,要注释这句话

然后找到protected-mode yes,这里的yes表示只允许127.0.0.1访问,需要改成no
下图表示吞吐量


下图是临时密码

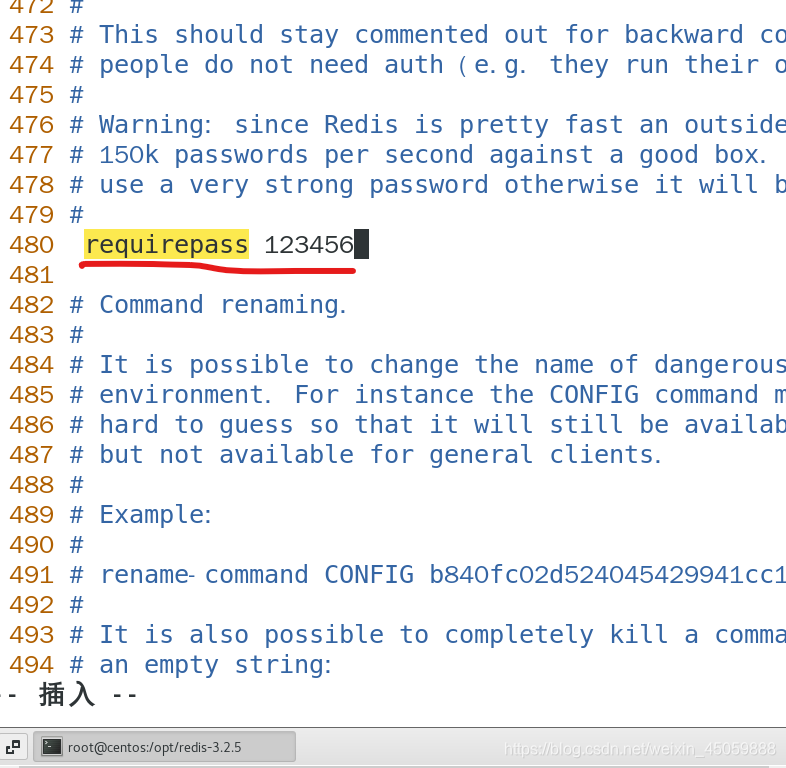
下图是永久密码,比如下图我将redis密码设置成123456
8.spring整合redis
在前面有介绍,将redis.conf的只允许本地访问关闭,然后在linxu连接上网络,然后百度下关闭防火墙
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.9.0</version>
</dependency>
- 1
- 2
- 3
- 4
- 5
@org.junit.Test
public void test(){
Jedis jedis = new Jedis("192.168.1.9",6379);
String ping = jedis.ping();
System.out.println(ping);
}
- 1
- 2
- 3
- 4
- 5
- 6
模拟手机验证码
发送验证码
@RestController public class sendController { //连接redis Jedis jedis = new Jedis("192.168.1.9",6379); //单日不可超过次数,可从数据库获得 private String count="3"; //验证码过期时间,可从数据库获得 private int time=120; @RequestMapping("/getCode/{phone}") public String getCode(@PathVariable("phone") String phone){ //1.校验手机号 if(StringUtils.isEmpty(phone)){ return "手机号不可为空"; } //2.手机号正确判断次数 String Verify_count="Verify:"+phone+":count"; String phone_count = jedis.get(Verify_count); //为空说明第一次发送,小于等于2说明没有超过次数 if(phone_count==null){ jedis.setex(Verify_count,24*60*60,"1"); }else if(Integer.parseInt(phone_count)<=2){ jedis.incr(Verify_count); }else if(Integer.parseInt(phone_count)>2){ return "单日发送验证码超过3次"; } //3.设置验证码 String Verify_code="Verify:"+phone+":code"; //假设4位验证码 jedis.setex(Verify_code,time,getCode(4)); jedis.close(); return "发送成功"; } public String getCode(int length){ String Verify=""; for (int i = 0; i < length; i++) { Random random = new Random(); int i1 = random.nextInt(10); Verify+=i1; } return Verify; } }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
验证验证码
@RestController public class verifyController { //连接redis Jedis jedis = new Jedis("192.168.1.9",6379); @RequestMapping("/verify/{phone}/{code}") public String verify(@PathVariable("phone")String phone, @PathVariable("code")String code) { String Verify_code = "Verify:" + phone + ":code"; String phone_code = jedis.get(Verify_code); if (!StringUtils.isEmpty(phone_code)) { if(phone_code.equals(code)){ return "验证成功"; }else{ return "验证码错误"; } }else{ return "验证码无效"; } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
9.redis的事务
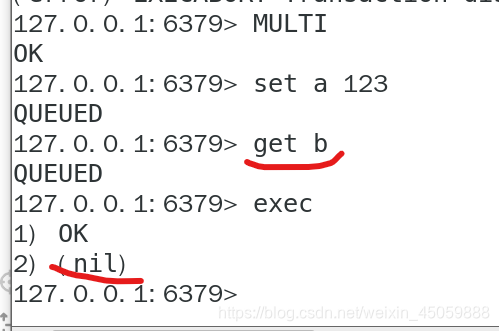
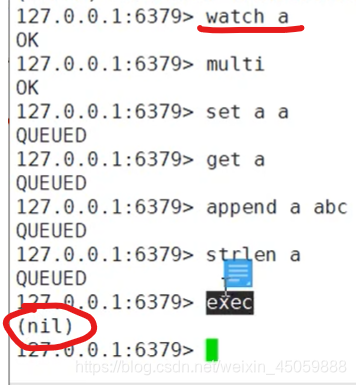
redis只会因为“编译异常”回退,不会因为“运行异常”回退,“运行异常”时其他命令继续执行

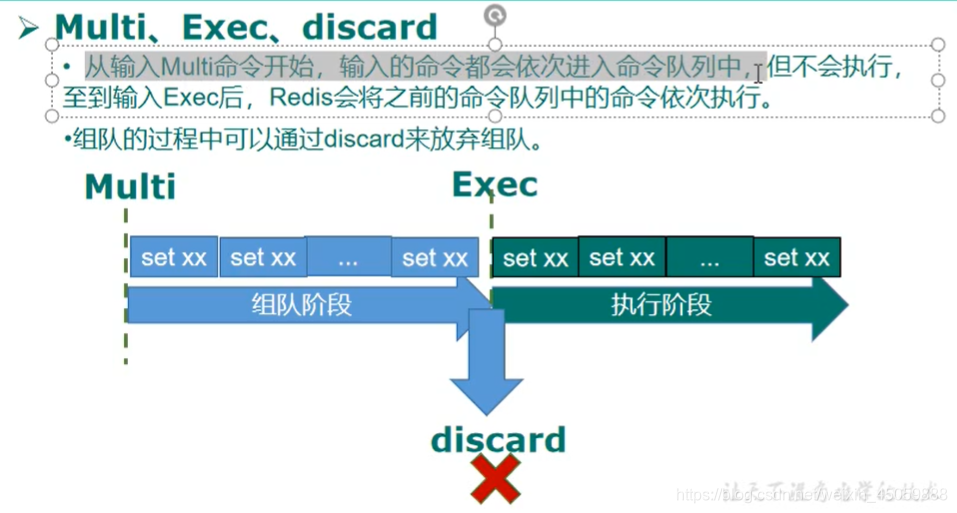
正常操作如下
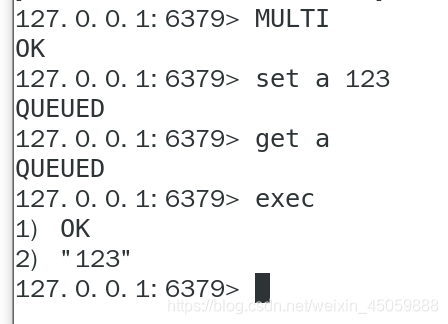
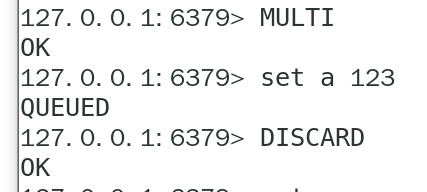
中途取消事务
出现“编译时异常”操作如下
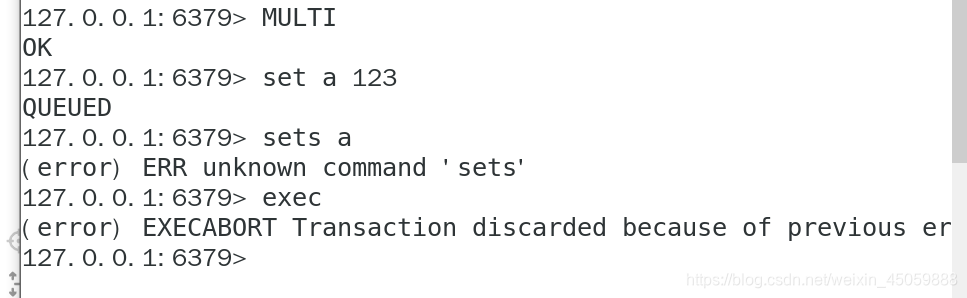
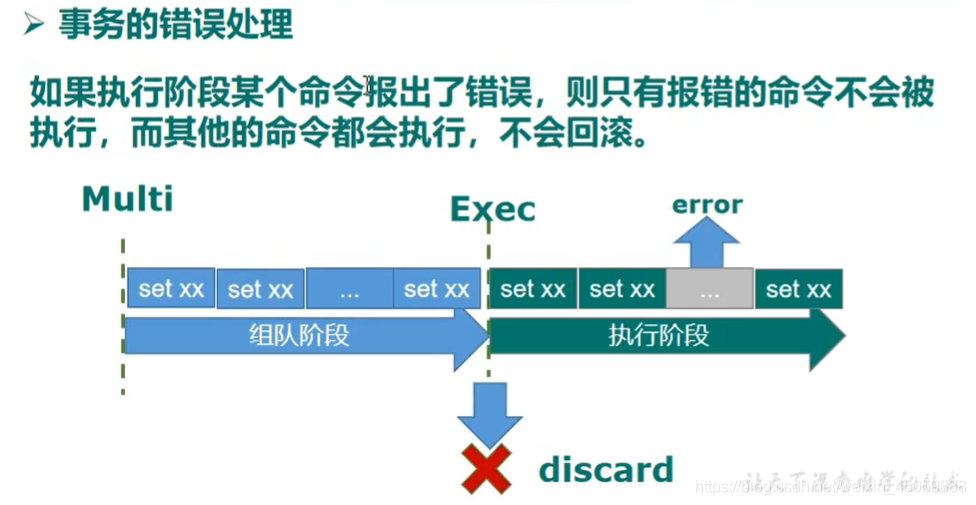
出现“运行时异常”如下
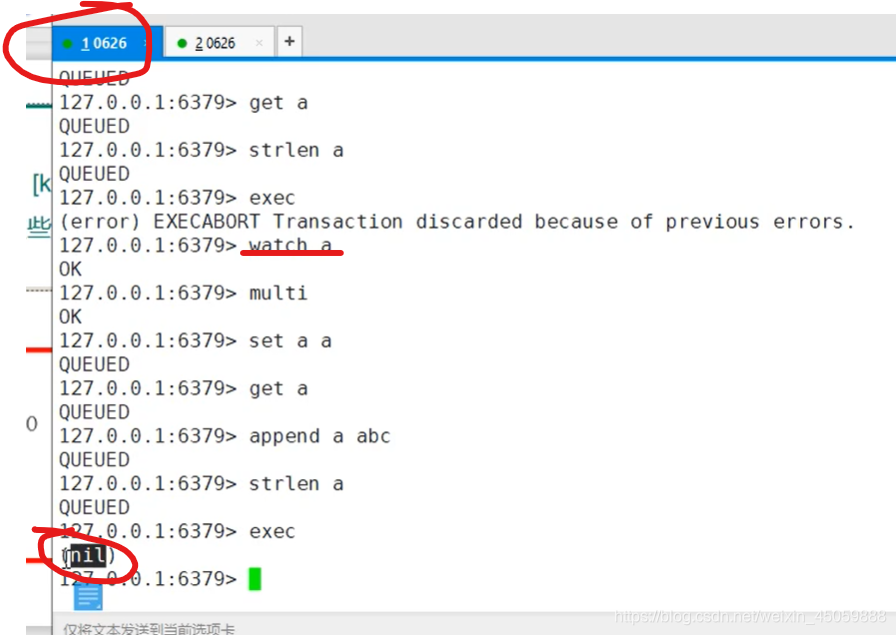

秒杀案例
出现超卖,少卖现象的代码,如下,会出现并发问题
@RestController public class killController { //连接redis Jedis jedis = new Jedis("192.168.1.9",6379); //假设秒杀的商品id是0001,可以从数据库得到 private String productId="0001"; @RequestMapping("/kill") public String kill(@RequestParam("Uid")String userId){ //秒杀商品的key String pid="saleKill:"+productId+":pid"; //已经秒杀成功的用户id集合 String success_pid="saleKill:"+productId+":uid"; //1.判断秒杀是否开始,库存是否还有 String pid_count = jedis.get(pid); if(pid_count==null){ System.out.println("秒杀尚未开始或已经抢光"); jedis.close(); return "秒杀失败"; } //2.判断该用户是否已经秒杀成功 if(jedis.sismember(success_pid,userId)){ System.out.println("该用户已经秒杀成功"); jedis.close(); return "秒杀失败(已秒杀)"; } //3.秒杀成功,减少库存,秒杀列表加人 jedis.decr(pid); jedis.sadd(success_pid,userId); jedis.close(); System.out.println("秒杀成功"); return "秒杀成功"; } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
利用lua脚本解决问题
@RestController public class killController { //连接redis Jedis jedis = new Jedis("192.168.1.9",6379); static String luaScript ="local userid=KEYS[1];\r\n" + "local prodid=KEYS[2];\r\n" + "local qtkey='sec:'..prodid..\":count\";\r\n" + "local usersKey='sec:'..prodid..\":user\";\r\n" + "local userExists=redis.call(\"sismember\",usersKey,userid);\r\n" + "if tonumber(userExists)==1 then \r\n" + " return 2;\r\n" + "end\r\n" + "local num = redis.call(\"get\" ,qtkey);\r\n" + "if tonumber(num)<=0 then \r\n" + " return 0;\r\n" + "else \r\n" + " redis.call(\"decr\",qtkey);\r\n" + " redis.call(\"sadd\",usersKey,userid);\r\n" + "end\r\n" + "return 1" ; //假设秒杀的商品id是0001,可以从数据库得到 private String productId="0001"; @RequestMapping("/kill") public String kill(@RequestParam("Uid")String userId){ //秒杀商品的key String pid="saleKill:"+productId+":pid"; //已经秒杀成功的用户id集合 // String success_pid="saleKill:"+productId+":uid"; //秒杀成功,减少库存,秒杀列表加人 String sha1 = jedis.scriptLoad(luaScript); Object result= jedis.evalsha(sha1, 2, userId,pid); String reString=String.valueOf(result); if ("0".equals( reString ) ) { System.err.println("已抢空!!"); }else if("1".equals( reString ) ) { System.out.println(userId + "抢购成功!!!!"); }else if("2".equals( reString ) ) { System.err.println("该用户已抢过!!"); }else{ System.err.println("抢购异常!!"); } jedis.close(); return "秒杀成功"; } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
10.redis的持久化
rdb与aof区别
rdb优点:相对于aof来说1.节省磁盘空间2.恢复速度快
rdb缺点:1.当某个时间点写入数据量很大的时候,会占用很多资源2.意外宕机导致最后一次操作的数据丢失
aof优点:1.备份数据更加的完整2.可读的备份操作,可以处理误操作
aof缺点: 1.占用数据大2.可能误操作无法恢复
使用场景: 最好都开启,若是对数据不敏感,则用rdb。不建议使用aof,因为可能会出现bug,如果只是当缓存使用则不建议开启
rdb保存模式(默认)
在操作redis的过程中,当满足了某些操作条件时或者正常关闭redis时还有手动save vs bgsave,redis都会进行持久化,持久化的文件名叫dump.rdb,满足持久化的条件通常是某些时间段里更改了多次数据,如 save 60 10 代表60秒内更改了数据10次就会进行持久化,dump.rdb的存放位置默认是放在redis的启动目录下,但是也可以自行更改。

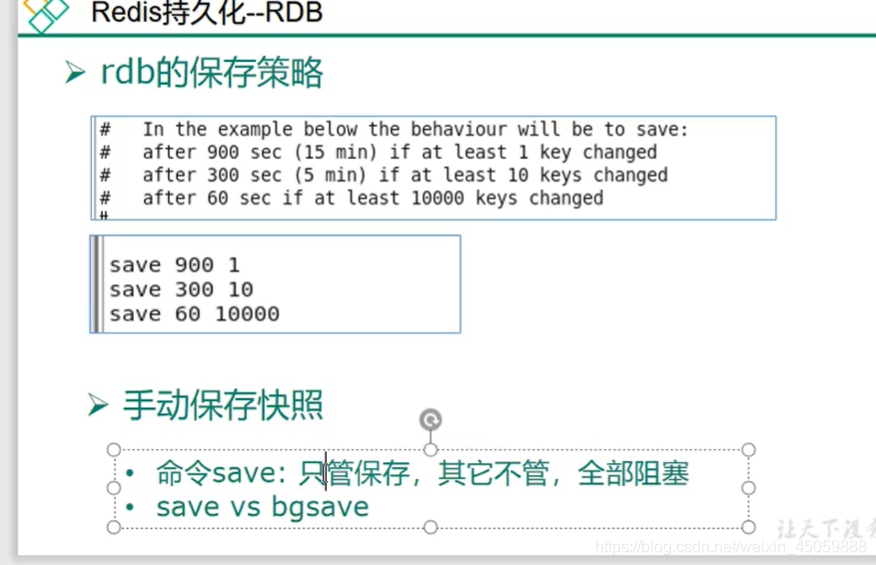
如下图:rdb的一些配置

如下图:rdb文件的恢复

如下图所示:我在1月29号(现在时间是1月30日)在此目录启动过redis,所以有dump.rdb文件
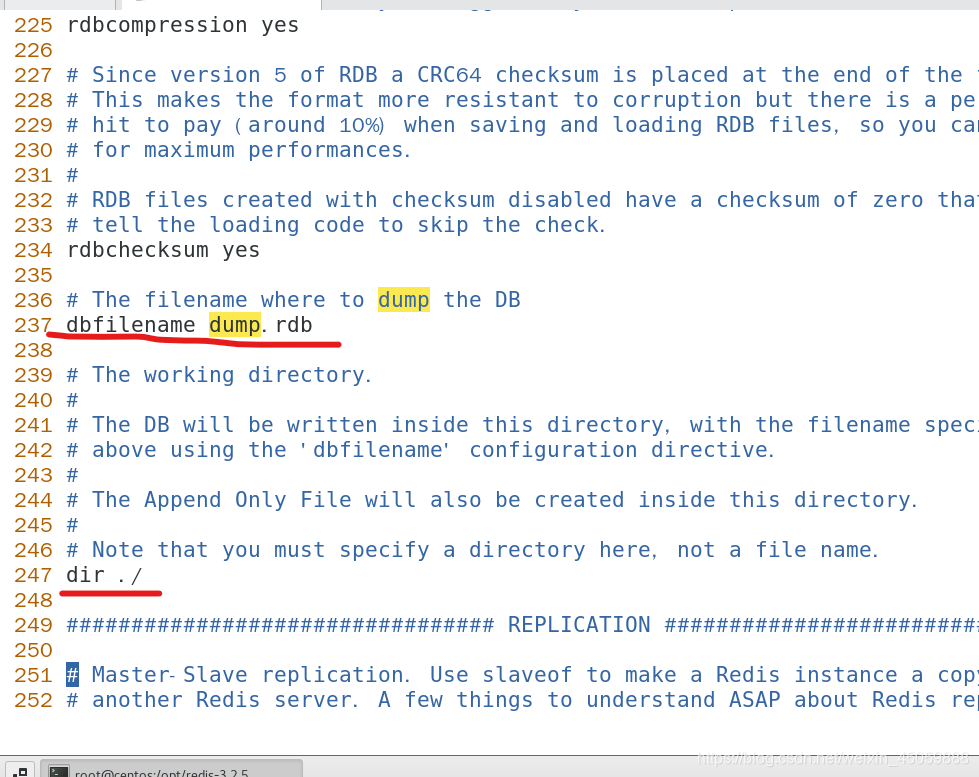
在redis.conf的文件里面,dbfilename可以改变rdb持久化的文件名,247行可以更改存放路径,如第二张图我做一些更改
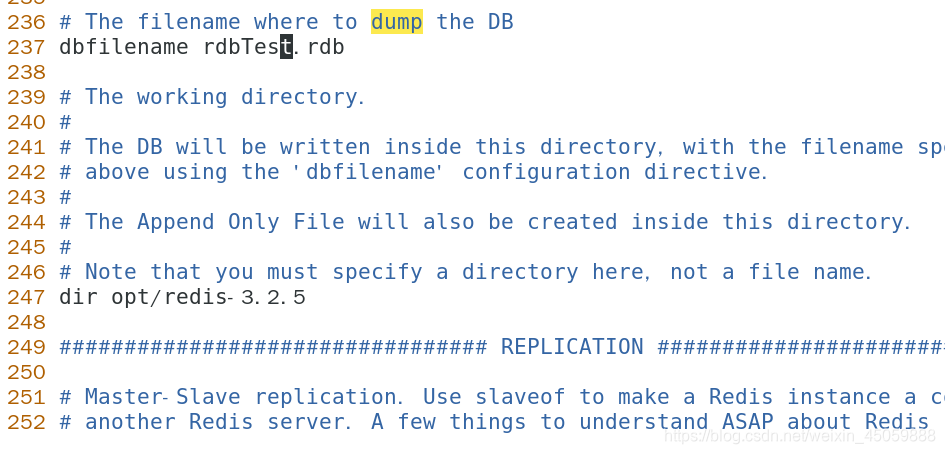
如下图:可以设置根据多长时间内操作次数来决定是否持久化

如下图:删除原来的rdb文件
aof持久模式

如下图:开启

如下图:aof和rdb同时开启时,默认使用aof

如下图:aof同步的频率

如下图:当aof文件太大时,可以重写,比如set 1 1,set 2 2,则只会保存set 2 2

如下图:重写也需要有一个合适的条件,当redis启动时或者重写完毕时,aof文件的大小超过了设置的值(默认是64m)时,就会重写

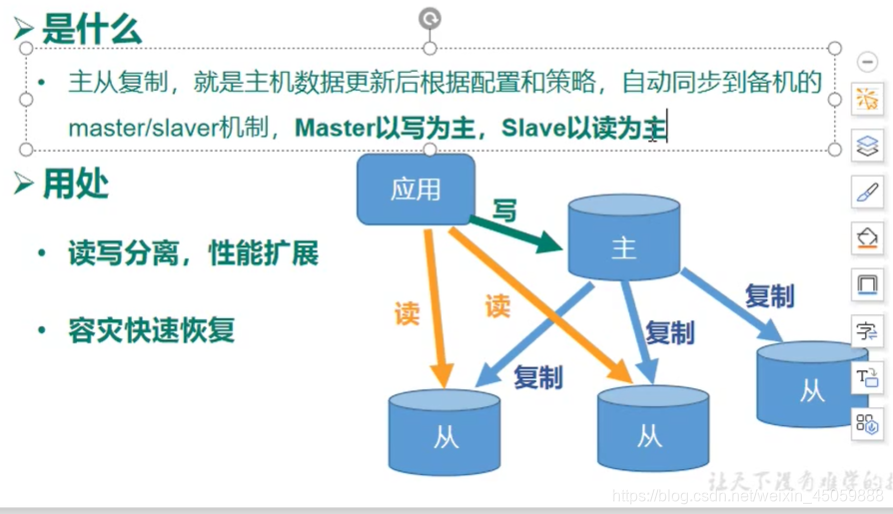
11.主从复制
主从复制的几个关键点
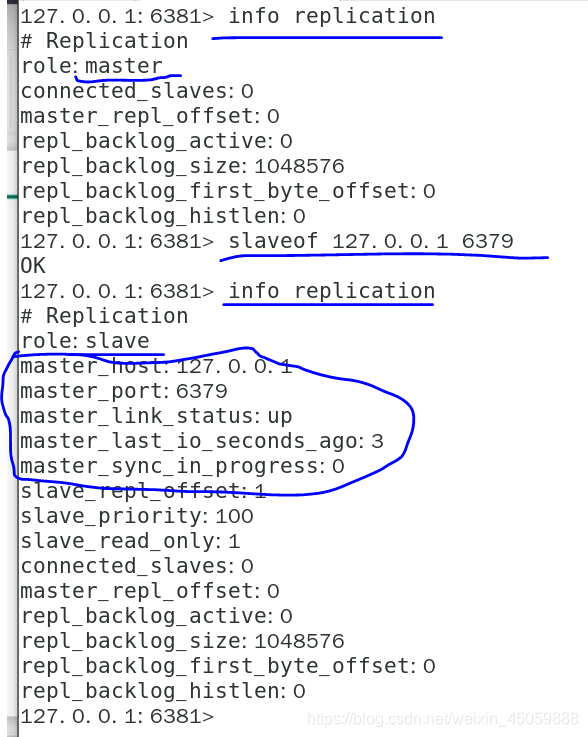
** 1.主库挂了再连接还是主库,从库挂了就不是从库了
2.主库挂了,从库会等着主库上线
3.当一个缓存库变成从库(挂了重新连接)后,自动复制主库的所有内容
**
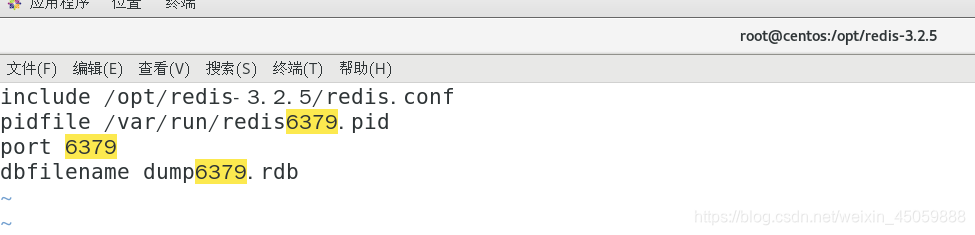
如下图:从库要配置的东西

三个缓存间的配置
include:引用最初的redis.conf的文件内容
pidfile:进程文件名
port:端口号
dbfilename: 持久化下的文件名
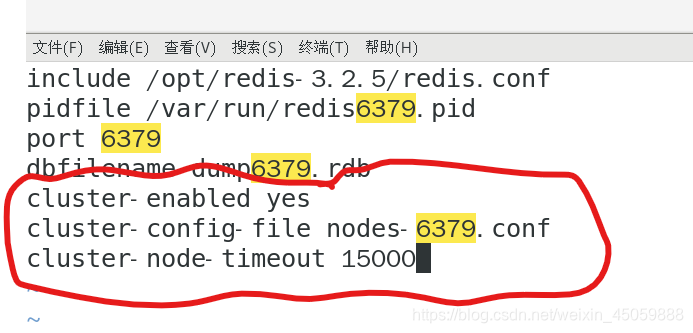
假如主缓存库端口号是6379,从缓存库的端口号是6380,6381,则把下面的数字改成相应的端口号,文件名改成redis+端口号.conf就行
在vim里,%s/被替换的数值/替换成什么,表示替换

新建的3个redis.conf
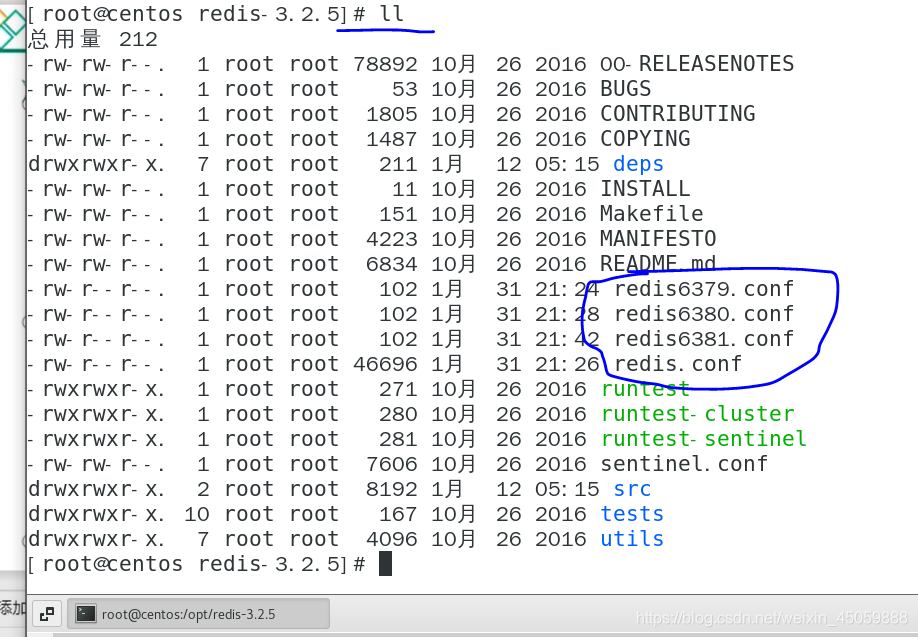
可以看到redis不同端口的conf文件

启动并查看进程
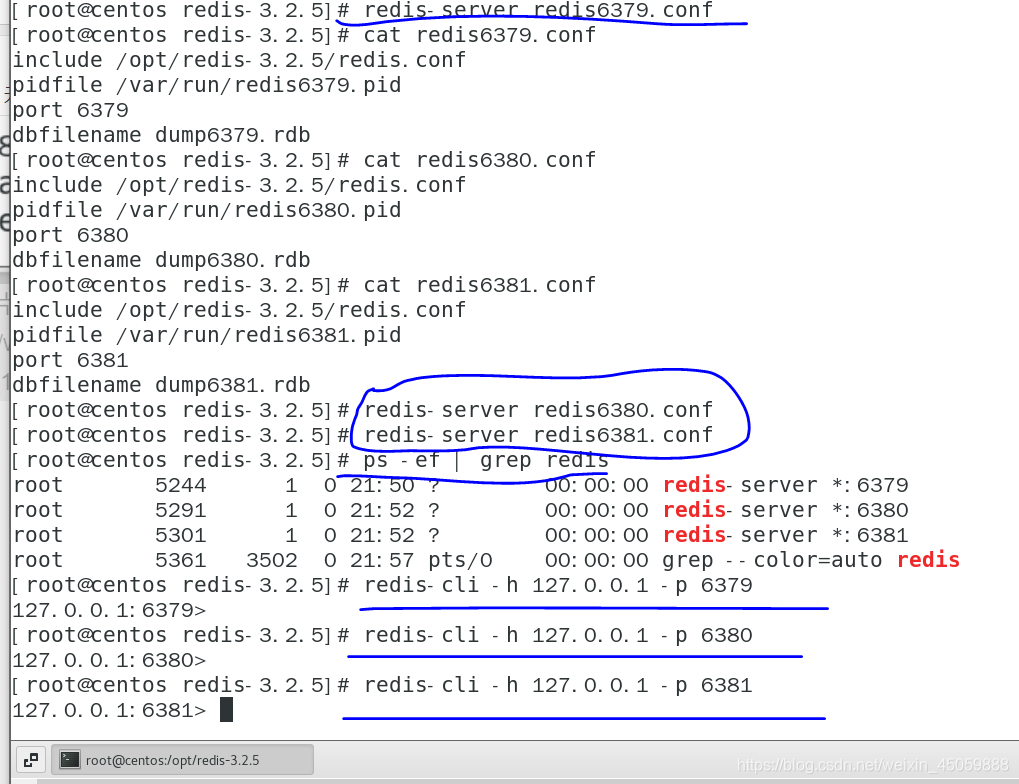
如下图,可以查看当前缓存数据库的信息,以及是不是从库

如下图:让6381变成6379的从库
主从复制之薪火相传
假如有三台服务器6379,6380,6381,薪火相传的做法:6379不动,6380成为6379的从,6381成为6380的从。当6379宕机后,可以在6380服务器中执行slaveof no one命令成为主服务器。

主从复制之哨兵模式
sentinel monitor mymaster(随便写) 127.0.0.1(第一次设置的主服务器的ip地址) 6379(第一次设置主服务器的端口号)1(当有多少个哨兵认为主服务器挂了,才开始选举新的主服务器)
当主从服务器都启动后,使用 redis-sentinel /目录下的sentinel.conf启动哨兵,哨兵本身就是一个redis实例

选举新的主服务器:1.优先级高的(启动时自己独有的redis.conf文件里面,设置slave-priority值小一点)
2.数据量多的
3.随机生成uuid小的(系统决定)
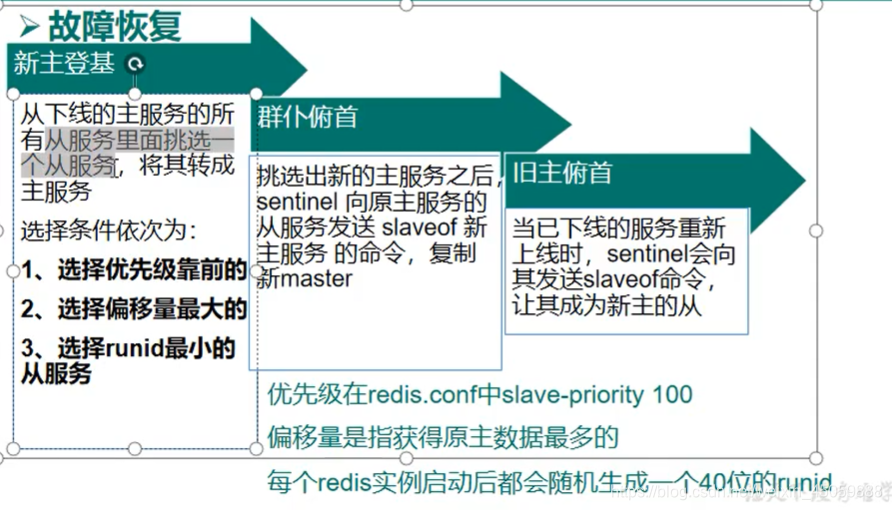
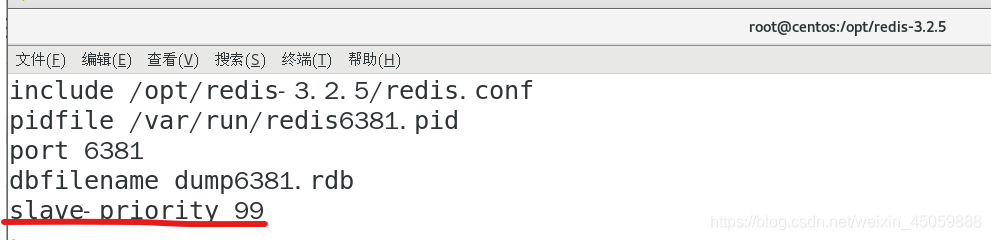
如下图所示:将6381的优先级靠前一点,主机宕机后,6381就能成为主机
12.redis集群
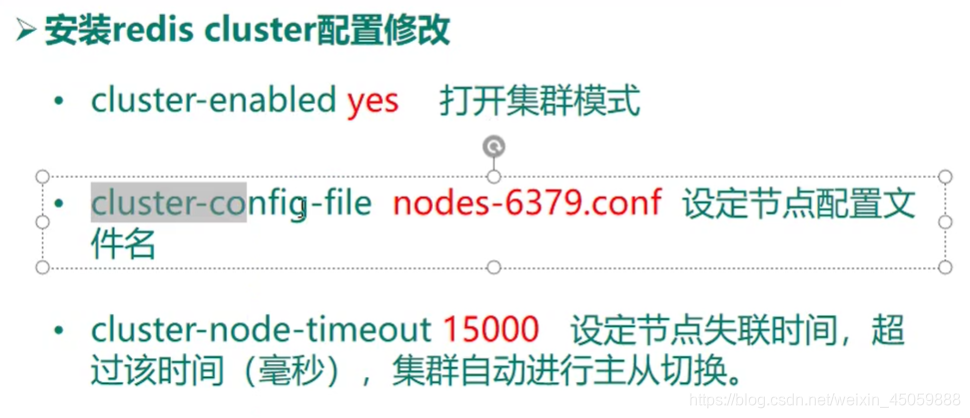
其他端口的redis.conf文件也加上以下信息,将6379改成自己的端口号即可