
- 1STM32F103用IO口和DS1302模块通信_ds1302z i2c stm32
- 2React EasyUI插件 学习笔记(基础)详细版
- 3Android 开发中的SSL pinning_ssl pinning 抓包
- 4i春秋ctf练习_c7d888-36f66bfc_d2edc4f0-23def191a3
- 5fastdfs部署详解
- 6PTA 估值一亿的AI核心代码 正则表达式 regex_replace_ai正则表达式 开源
- 7第46届世界技能大赛网络系统管理项目江苏省选拔赛赛题-模块B样题v1.4——Windows功能模块配置(部分解析)_离线后自动切换为主要dns服务器
- 8寒武纪面试——数字IC,数字逻辑岗_寒武纪都是电话面试嘛
- 9uniapp里面tabbar自定义的方法_uniapp 自定义tabbar
- 10【CANFD详细介绍与CAN区别】
安装OpenPCDet遇到的问题_modulenotfounderror: no module named 'av2
赞
踩
一、前言
1、本文遇到的问题分为两个章节:云平台安装遇到的问题和本地安装遇到的问题。
2、云平台和本地:云平台有些解决方案放在本地不一定适用,本地放在云平台亦是如此,大家需要尝试一下。
3、版本问题:如果遇到奇奇怪怪的问题,应该首先检查是不是因为版本的问题,我推荐是装高不装低,除非程序硬性要求。(主要是低版本问题太多,太难安装了)
4、环境搭建
九天毕昇云平台安装Openpcdet:九天毕昇”云平台:python3.7+CUDA10.1+torch1.6.0+spconcv1.2.1安装OpenPCDet全流程![]() https://blog.csdn.net/weixin_44013732/article/details/126030624
https://blog.csdn.net/weixin_44013732/article/details/126030624
本地安装Openpcdet:
二、云平台安装遇到的问题:
以下是在九天毕昇云平台中安装出现的问题,采用低版本安装:
CUDA10.1+torch1.6.0+spconv1.2.1+pcdet0.5.2
1.遇到问题:OSError: libcuhash.so: cannot open shared object file: No such file or directory
解决方法:
sudo find / -name libcuhash.so
输入:export LD_LIBRARY_PATH=/root/.local/lib/python3.7/site-packages/spconv:"${LD_LIBRARY_PATH}"
参照:OSError: libcuhash.so: cannot open shared object file: No such file or directory
2.遇到问题:TypeError: expected str, bytes or os.PathLike object, not NoneType
解决方法:
python train/test/demo.py时,后面没有加路径,可以改为:
- python train.py --cfg_file cfgs/kitti_models/pv_rcnn.yaml
-
- python test.py --cfg_file cfgs/kitti_models/pv_rcnn.yaml --batch_size 1 --ckpt /root/PointCloudDet3D/output/kitti_models/pv_rcnn/default/ckpt/checkpoint_epoch_51.pth --save_to_file
-
- python demo.py --cfg_file cfgs/kitti_models/pv_rcnn.yaml --ckpt /root/PointCloudDet3D/output/kitti_models/pv_rcnn/default/ckpt/checkpoint_epoch_51.pth --data_path /root/PointCloudDet3D/data/kitti
train.py:train.py 文件后面需要加上需要训练模型的位置.(即yaml)
test.py:除了yaml路径外,还需要加入pth数据的位置,一般都放在output中(train后才会生成,否则木有文件数据)
demo.py:运行代码,除了需要加上ckpt中训练的pth路径外,还需要加上data的路径,即 /root/PointCloudDet3D/data/kitti,否则也会报错。
如果加上仍然报错,可能是程序本身的问题。
3.遇到问题:RuntimeError: The detected CUDA version (10.1) mismatches the version that was used to compile PyTorch (10.2). Please make sure to use the same CUDA versions.
解决方法:删除高版本torch,找到适合CUDA的torch低版本,对应好torchvision。
4.遇到问题:Unable to locate package xxx
解决方法:apt-get update升级乌班图
5.遇到问题:用apt-get出现以下错误:
Failed to fetch http://archive.ubuntu.com/ubuntu/pool/universe/p/p7zip/p7zip_16.02+dfsg-6_amd64.deb Temporary failure resolving 'archive.ubuntu.com'
解决方法:
①如果是网络问题:
用vim编辑器进行添加DNS
(1)使用sudo vi /etc/resolv.conf
(2)按i插入:
(3)nameserver 202.96.134.133
(4)nameserver 8.8.8.8
(5)按Esc退出,并输入:wq!强制退出并保存。
(6)用vim /etc/apt/sources.list进入镜像源界面
(7)再用sudo apt-get update进行更新。
②如果不是网络问题:
不要在指令前加sudo,例如: sudo apt-get update改为 apt-get update。
6.遇到问题:Linux出现“E45: ‘readonly‘ option is set (add ! to override)”
解决方法:
该错误为当前用户没有权限对文件作修改,如果是root权限,可以:wq! 强行保存退出;
7.遇到问题:Linux修改文件出现[O]pen Read-Only、(E)dit anyway、(R)ecover解决方法
解决方法:
[O]pen Read-Only: 打开此档案成为只读档, 可以用在你只是想要查阅该档案内容并不想要进行编辑行为时。
(E)dit anyway:还是用正常的方式打开你要编辑的那个档案, 并不会载入暂存盘的内容。不过很容易出现两个使用者互相改变对方的档案等问题!
( R )ecover: 就是加载暂存盘的内容,用在你要救回之前未储存的工作。 不过当你救回来并且储存离开 vim 后,还是要手动自行删除那个暂存档喔!
(D)elete it: 你确定那个暂存档是无用的!那么开启档案前会先将这个暂存盘删除! 这个动作其实是比较常做的!因为你可能不确定这个暂存档是怎么来的,所以就删除掉他吧!
(Q)uit: 按下 q 就离开 vim ,不会进行任何动作回到命令提示字符。
(A)bort: 忽略这个编辑行为
8.遇到问题:unzip解压不了KITTI大数据压缩包
解决方法:使用jar命令进行解压,jar xvf xxxx.zip,xvf前不要加-
9.遇到问题:Unable to locate package错误解决
解决方法:
apt-get update (不要加sudo)
apt-get upgrade
10.压缩解压缩zip
解决方法:
安装:apt-get install zip
zip xxx.zip xxx
或者pip install zip
11.遇到问题:Failed to build mayavi
解决方法:
pip install vtk==8.1.2
将VTK版本降级
12.安装yum
解决方法:apt-get install yum
13.遇到问题:
Undifined symbol: _ZN6caffe28TypeMeta21_typeMetaDataInstanceIN3c107complexINS2_4HalfEEEEEPKNS_
解决方法:
可能1:torch版本太高,cuda10.1适合安装torch1.5.0-torch1.7.0。推荐使用torch1.6.0,目前没有出错,其他两个版本依旧报错。
可能2:其他第三方库版本太高或太低,例如安装mmdet时,mmcv-full安装1.6.2就会报出这样的错误,而mmcv-full==1.6.1时就不会。
14.遇到问题:
TypeError: load() missing 1 required positional argument: ‘Loader‘?
解决方法:
Yaml 5.1版本之后就弃用了不安全的load加载方式,需要在load方法中加入指定的加载器,或者使用安全加载api, 通过默认加载器使load函数的安全得到加强。
直接安装指定版本下的 yaml 包即可
pip uninstall pyyaml
pip install pyyaml==5.1
15.遇到问题:libtorch_cpu.so找不到
解决方法:
安装torch1.8.0 以上版本,否则torch/lib里没有该文件,所以采用find命令进行查找。
sudo find / -name libtorch_cpu.so
查到相应的路径用下列代码
export LD_LIBRARY_PATH=文件路径:"${LD_LIBRARY_PATH}"
例如:
- export LD_LIBRARY_PATH=/usr/local/lib/python3.6/dist-packages/torch/lib:"${LD_LIBRARY_PATH}"
- export LD_LIBRARY_PATH=/opt/conda/envs/pytorch1.8/lib/python3.9/site-packages/torch/lib:"${LD_LIBRARY_PATH}"
16. 遇到问题:
python: symbol lookup error: /root/.local/lib/python3.7/site-packages/torch/_C.cpython-37m-x86_64-linux-gnu.so: undefined symbol: _Z10initModulev
解决方法:
pytorch版本太低,需要用torch1.5及以上的。
17.遇到问题
OSError: /root/.local/lib/python3.7/site-packages/spconv/libspconv.so: undefined symbol: _ZN6caffe28TypeMeta21_typeMetaDataInstanceISt7complexIdEEEPKNS_6detail12TypeMetaDataEv
解决方法:
spconv虽然安装上了,但是安装有缺口,需要重新配置。
或者是由于版本不适配的问题。
18.遇到问题
ImportError: libcudart.so.10.0: cannot open shared object file: No such file or directory
解决方法:
这是CUDA10.0版本的东西,
通过find找到该文件:
sudo find / -name libcudart.so.10.0
找到文件路径,/usr/local/lib/python3.6/dist- packages/cntk/libs/libcudart.so.10.0
将上面的路径添加到临时路径
export LD_LIBRARY_PATH=/usr/local/lib/python3.6/distpackages/cntk/libs:"${LD_LIBRARY_PATH}"
find查找后,发现文件是在python3.6的cntk文件夹下,我的环境是python3.7,不能安装cntk(cntk最高版本只支持python 3.6),只能通过export 临时加入环境变量。
19.本地安装cmake但pip查不到
解决方法:
这是cmake安装命令(在本地安装):
- #解压
- tar -xvzf cmake-3.15.3.tar.gz
- cd cmake-3.15.3
- ./bootstrap #执行引导文件
- #该命令执行需要一定时间,请耐心等待。成功执行结束之后,末尾提示:CMake has bootstrapped. Now run make.
- make
- sudo make install
- cmake --version
- cd ..
- rm -rf cmake-3.15.3 #清理安装源代码
- pip install cmake==3.15.3
前面时建立安装环境,最后还需要加上pip install cmake==3.15.3否则还是显示没安装上。
20.安装spconv时运行python setup.py bdist_wheel出错
问题如下:
subprocess.CalledProcessError: Command '['cmake', '/home/zdj/spconv', '-DCMAKE_PREFIX_PATH=/home/zdj/anaconda3/envs/pytorch/lib/python3.7/site-packages/torch', '-DPYBIND11_PYTHON_VERSION=3.7', '-DSPCONV_BuildTests=OFF', '-DPYTORCH_VERSION=10600', '-DCMAKE_CUDA_FLAGS="--expt-relaxed-constexpr" -D__CUDA_NO_HALF_OPERATORS__ -D__CUDA_NO_HALF_CONVERSIONS__', '-DCMAKE_LIBRARY_OUTPUT_DIRECTORY=/home/zdj/spconv/build/lib.linux-x86_64-3.7/spconv', '-DCMAKE_BUILD_TYPE=Release']' returned non-zero exit status 1.
解决方法1:
此问题说明spconv安装缺文件,从官方下载下来的spconv1.2.1,文件夹下的third_party/pybind11是空的,需要自己手动去下载。
pybind11链接:
[https://github.com/pybind/pybind11/tree/3b1dbebabc801c9cf6f0953a4c20b904d444f879](https://github.com/pybind/pybind11/tree/3b1dbebabc801c9cf6f0953a4c20b904d444f879)
解决方法2:电脑是30系列显卡时,需要安装CUDA11.x,属于高版本,spconv需要安装2.x。
每台主机问题多种多样,出现这种问题很多情况下是版本不适配。
解决方法3:今天又碰着了一回,是安装spconv1.0时候,以下给出一个github的解决方案:
conda create --name spconv python=3.7 pytorch=1.4 cudatoolkit=10.1 cudatoolkit-dev=10.1 cmake --channel pytorchconda activate spconv
conda install cudnn
git clone https://github.com/traveller59/spconv --recursive
cd spconv
git checkout 8da6f967fb9a054d8870c3515b1b44eca2103634
git am <path_to_hotfixes>/0001-fix-problem-with-torch-1.4.patch
git am <path_to_hotfixes>/0001-Allow-to-specifiy-CUDA_ROOT-directory-and-pick-corre.patch
CUDA_ROOT=<path_to_your_conda_installation>/envs/spconv python setup.py bdist_wheel
cd dist/
pip install *
解决方法4:
把/spconv/build/文件夹里面的环境都删除,重新安装一遍,有可能是之前某个电脑安装的残留,导致现在安装不了。
解决方法5:
不乏有文件错误的可能,这里提供一个我亲测有效的文件:
用于spconv1.2.1的安装,目前亲测有效
以后遇到其他方案还会更新。。。
参考:https://lightrun.com/answers/traveller59-spconv-cuda-path-seems-to-be-hard-coded
21.遇到问题:
ImportError: cannot import name 'spconv_utils' from 'spconv' (/root/spconv-1.2.1/spconv/__init__.py)
解决方法:
方案1:
卸载了重新装,就是这么神奇。
方案2:更新2023-9-3
今天又碰着了一回,发现我方案1的描述可能没说清楚,你编译完后还需要安装spconv.whl,这个文件在spconv/dist文件夹中,输入以下指令执行pip安装:
cd ./dist && pip install *
22.遇到问题:TypeError: zip argument #1 must support iteration
解决方法:
程序本身有问题,用pcdet0.3.0运行时出现的错误,转用pcdet0.5.2就可以运行。
23.遇到问题:装过一次pcdet,仍然还出现ModuleNotFoundError: No module named 'pcdet'
解决方法:
再次执行pyhton setup.py develop进行安装。
24.遇到问题:
FileNotFoundError: [Errno 2] No such file or directory: '/media/hpc/FED242EAD242A6AD/data/kitti/kitti_dbinfos_train.pkl
解决方法:
①更改数据生成路径:
来到/pcdet/pcdet/datasets/kitti/kitti_dataset.py文件:
倒数第三行和倒数第四行修改data_path和save_path,修改为
data_path=ROOT_DIR / 'pcdet' / 'data' / 'kitti',
save_path=ROOT_DIR/ 'pcdet' / 'data' / 'kitti'。
②更改数据索引路径
来到/pcdet/tools/cfgs/datasets_configs/kitti_dataset.yaml文件:
修改第二行路径DATA_PATH为DATA_PATH: '/root/pcdet/data/kitti'。
25.遇到问题:TypeError: Caught TypeError in DataLoader worker process 0.
该错误是关于DataLoader进行训练数据的存取工作线程的问题
解决方法:
在/pcdet/pcdet/datasets/__init__.py:存着build_dataloader,里面有DataLoader函数——数据加载器,64行,将num_workers=works中的works直接改为0。
切忌将上面的works改为0(上面的输入参数),否则仍然没有用,直接删掉改为0就好。
26.遇到问题:TypeError: cannot unpack non-iterable NoneType object
解决方法:
程序有问题,请换一个程序包尝试。用pcdet0.3.0运行时出现的错误,转用pcdet0.5.2就可以运行。
27.遇到问题:TypeError: stat: path should be string, bytes, os.PathLike or integer, not NoneType
解决方法:
训练test.py时后面需要加上cfgs的访问地址和ckpt的访问地址,如下:
python test.py --cfg_file cfgs/kitti_models/pv_rcnn.yaml --batch_size 1 --ckpt /root/PointCloudDet3D/output/kitti_models/pv_rcnn/default/ckpt/checkpoint_epoch_51.pth --save_to_file这个地址就是训练模型yaml的地址和训练好的pth的地址,pth只有在train过后才会自动生成。
28.遇到问题:ImportError: cannot import name 'iou3d_nms_cuda' from 'pcdet.ops.iou3d_nms'
解决方法:
可能1:
pcdet安装版本太低,问题中提到的错误是高版本的东西。如果用pcdet0.3.0安装,却运行了pcdet0.5.2的东西,则会出现这种错误。
需要再次安装高版本的pcdet,即python pcdet.py develop。
可能2:
程序包本身错误。
29.遇到问题:ModuleNotFoundError: No module named 'spconv.pytorch'
解决方法:这个是spconv2.x的东西,spconv原本的函数全部封装到一个叫做pytorch的文件夹下,如果你使用的是1.2.1及以下版本,那么把import spconv改成:
import spconv.pytorch as spconv
就行了。
30.遇到问题:FileNotFoundError: [Errno 2] No such file or directory: '/root/PointCloudDet3D/data/kitti_big/kitti_dbinfos_train.pkl'
解决方法:
data里头没数据,需要生成数据或者拷贝数据,或者缺少某些文件。
我提供给大家一个生成好的data文件:
小型kitti数据集
三、本地安装pcdet出现的问题
本地安装的版本比较高:
CUDA11.1+ ‘torch1.9.1+cu111’ + spconv-cu111 2.1.25+pcdet0.6.0
以上是在云平台上安装过程中出现的问题,下面是在本地遇到的问题:
31. 安装cuda时遇到的问题:Failed to verify gcc version. See log at /var/log/cuda-installer.log for details.
解决方法:
加入--override即可,例如:
sudo sh cuda_10.2.89_440.33.01_linux.run --override
32.安装pcdet时报错:subprocess.CalledProcessError: Command '['which', 'g++']'returned non-zero exit status 1.
问题描述:这个问题其实是gcc/g++编译时,出现版本不匹配的问题,最终会导致编译不出build文件夹下的.o文件。
解决方法1:
缺少g++编译器,可以用以下指令去安装g++:
sudo apt-get install build-essential
参考:报错subprocess.CalledProcessError: Command ‘[‘which‘, ‘g++‘]‘ returned non-zero exit status 1.
解决方法2:
用上面的方法有可能出现以下情况(反正我电脑是没用):
unsupported GNU version! gcc versions later than 10 are not supported! The nvcc flag -allow-unsupported-compiler can be used to override this version check; however, using an unsupported host compile...

也就是说,你的gcc和g++版本过高啦,这个指令sudo apt-get install build-essential
会自动安装与系统匹配的最新g++版本,需要手动降版本安装(略麻烦,但是有用):
安装过程如下:
①检查版本
首先查看下你之前安装的gcc版本:
gcc -v
如果显示:

说明你安装的是高版本:11.30
②手动降版本
根据问题描述:gcc versions later than 10 are not supported!
说明我们要安装gcc10版本以下的,这里我们选择安装gcc-9
先卸载之前的:
卸载原来高版本的gcc
sudo apt-get remove gcc

通过autoremove指令卸载高版本g++:
sudo apt autoremove

安装gcc-9
sudo apt-get install gcc-9
安装g++-9
sudo apt-get install g++-9
③添加软连接
但是这样还没有安装完,你使用gcc -v指令仍然不能看到你的gcc版本

是因为我们还需要手动加入软链接,用来链接我们的gcc和g++。
具体操作如下:
输入指令,删除之前的软连接:
sudo rm /usr/bin/gcc
sudo rm /usr/bin/g++
构建新的软连接:
sudo ln -s /usr/bin/gcc-9 /usr/bin/gcc
sudo ln -s /usr/bin/g++-9 /usr/bin/g++
这时我们再看看我们的gcc版本:
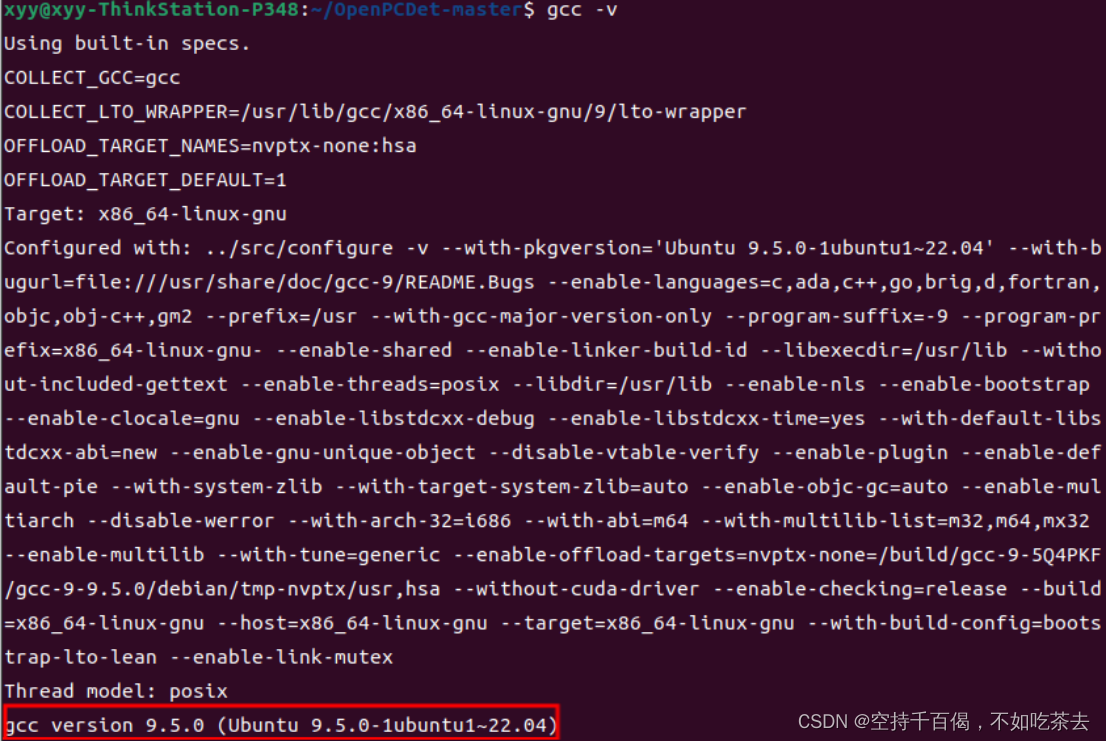
9.5.0版本,没错,接下来跑一下python setup.py develop

好了,原来gcc编译的位置没报错,解决啦!剩下就是漫长的build环节~
33、subprocess.CalledProcessError: Command ‘[‘ninja‘, ‘--version‘]‘ returned non-zero exit status 1
解决方法:
将/OpenPCDet-master/setup.py下的这段代码:
cmdclass={'build_ext': BuildExtension}更改为:
cmdclass={'build_ext': BuildExtension.with_options(use_ninja=False)}该步骤是为了pytorch禁用ninja。
解决方法参考:
博主真牛比。
--------------------------------------------------------------------------------------------------------------------------------
如果上述方法不能解决,可能是由于其他错误引起的,不要死盯着这个看,可以向上翻一翻,是不是哪个文件太老了没法编译。(我猜的,因为之前遇到过)
34、 raise RuntimeError(message) from e
RuntimeError: Error compiling objects for extension
解决方法:
以下解决方法仅适用于pcdet:
你往上面翻一翻,看看是不是有个这样的问题:

如果是,恭喜你,参照33号问题,问题解决。
如果不是,抱歉我还没遇到::>_<::,有些博客说是pytorch版本的问题:
35、报错:iou3d_nms_kernel.o: 没有那个文件或目录
问题:
/home/xyy/anaconda3/compiler_compat/ld: cannot find /home/xyy/OpenPCDet-master/build/temp.linux-x86_64-3.7/pcdet/ops/iou3d_nms/src/iou3d_nms_kernel.o: 没有那个文件或目录
collect2: error: ld returned 1 exit status
error: command 'g++' failed with exit status 1
问题描述:应该是根据网上的方法,将cpp_extention.py文件中的['ninja','--v'] 改成['ninja','--version'],这样的方法治标不治本,导致build文件夹下的.o文件根本编译不出来。
解决方法:
把['ninja','--version']改回['ninja','--v'],接着会报33号错误,查看上面的解决方法。
36、报错:
/home/xyy/OpenPCDet-master/pcdet/ops/iou3d_nms/src/iou3d_cpu.cpp:12:10: fatal error: cuda.h: 没有那个文件或目录
12 | #include <cuda.h>
| ^~~~~~~~
compilation terminated.

解决方法:
缺少cuda环境变量设置,主要是缺少CUDA_HOME变量设置。
①检查Linux下的环境变量中有没有将cuda添加上去
vim ~/.bashrc #打开环境变量脚本
②添加下面几行代码
export CUDA_HOME=/usr/local/cuda
export PATH=$PATH:/usr/local/cuda/bin
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda/lib64
export LIBRARY_PATH=$LIBRARY_PATH:/usr/local/cuda/lib64
③记得更新:source ~/.bashrc。
④再运行一下python setup.py develop就没问题啦:明显看到到building的时候没有卡。
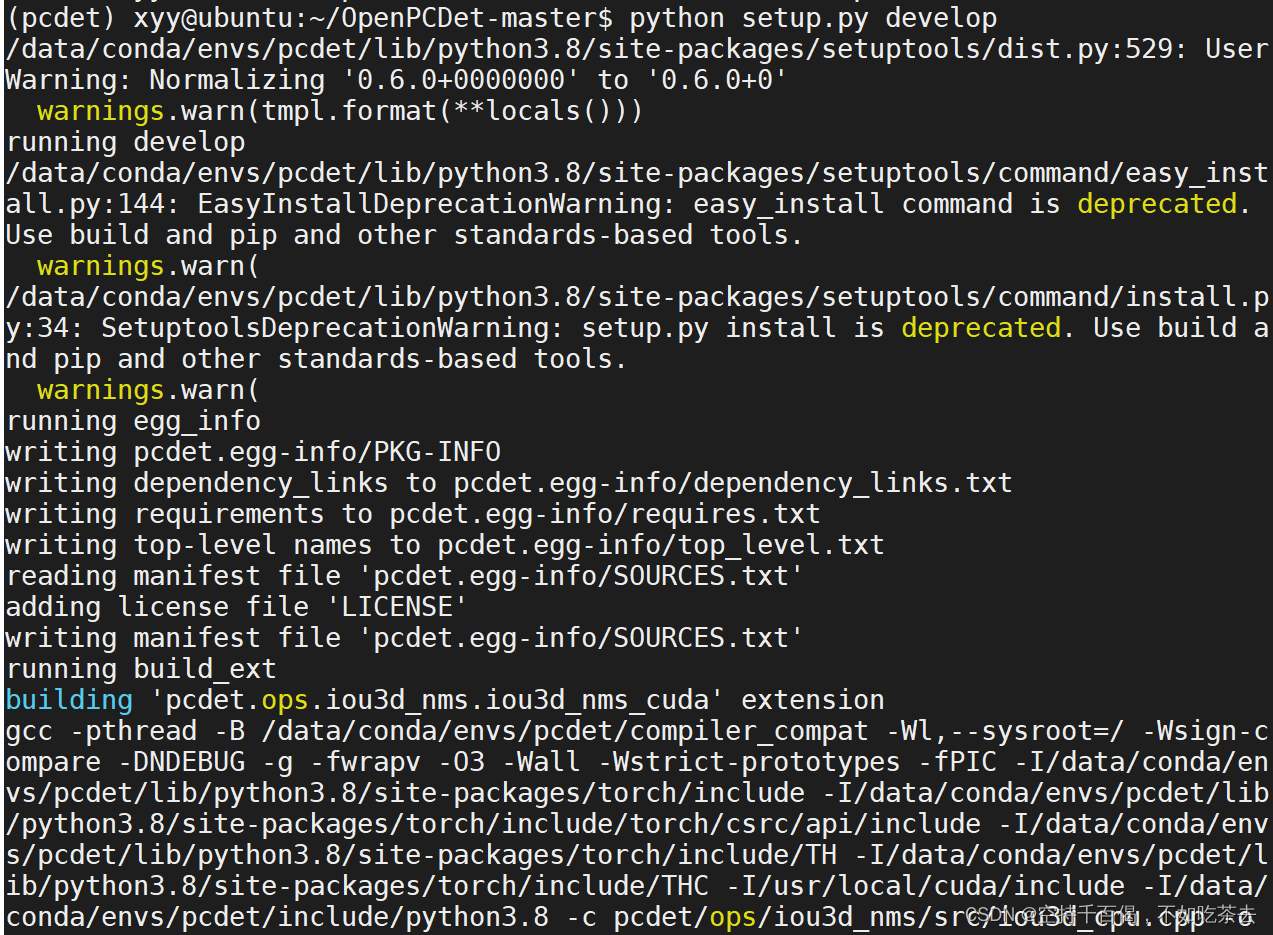
37、报错:
No local packages or working download links found for SharedArray
error: Could not find suitable distribution for Requirement.parse('SharedArray')
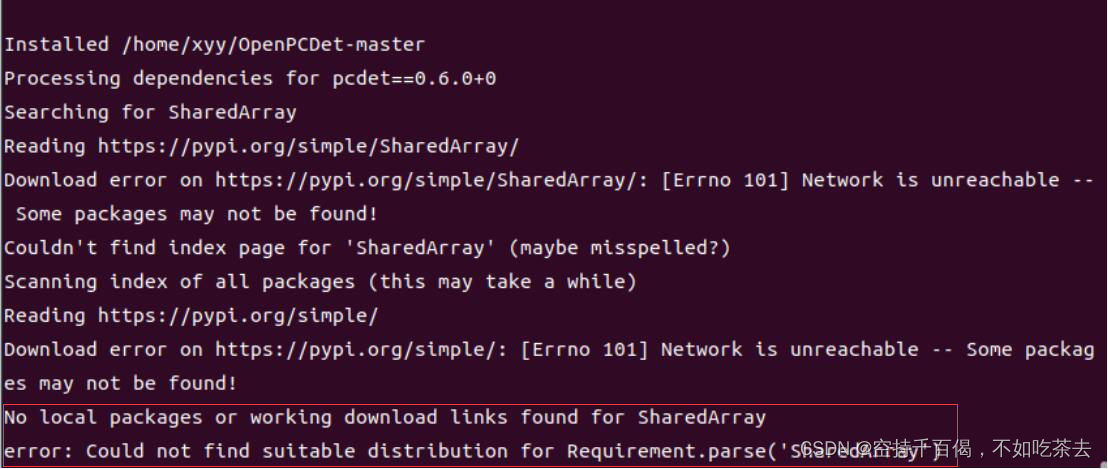
解决方法:
按照以下指令安装:
pip install sharedarray==3.1.0
安装的版本尽量不要太高,否则可能会影响后续安装,因人而异。
38、报错:ImportError: numpy.core.multiarray failed to import
解决方法1:
原因:sharedarray和numpy版本不匹配。
出现这个错误(ImportError: numpy.core.multiarray failed to import)往往是因为numpy版本过低,但是numpy=1.19.5显然已经很高。追溯错误发现是import SharedArray导致报错,经查是因为sharedarray库版本过高,所以对其进行降级处理:
pip install sharedarray==3.1.0
原文链接:关于Numpy的版本错误_numpy版本过高_炒饭小哪吒的博客-CSDN博客
解决方法2: 使用sharedarray==3.2.0搭配numpy==1.23.5,目前测试可行的
39、报错: ImportError: cannot import name '_validate_lengths' from 'numpy.lib.arraypad' (/home/xyy/anaconda3/lib/python3.7/site-packages/numpy/lib/arraypad.py)
问题描述:该问题与38类似,都有可能是因为sharedarray版本导致的。
解决方法:
出现这个问题,有博主说是numpy版本太高,scikit-image版本太低了,我觉得可以一试:
①升级skimage包可解决问题:
pip install --upgrade scikit-image
②更改sharedarray版本
如果还有问题,可以参照38号报错,有可能是sharedarray版本太高,导致numpy和skimage在互相拉扯,你升级哪一个都会报错。
40、ModuleNotFoundError: No module named 'cv2'
解决方法:
pip install opencv-python
pip install opencv-contrib-python
41、ModuleNotFoundError: No module named 'av2'
解决方法:
使用指令:
pip install av2
python3.7安装av2时会报错:
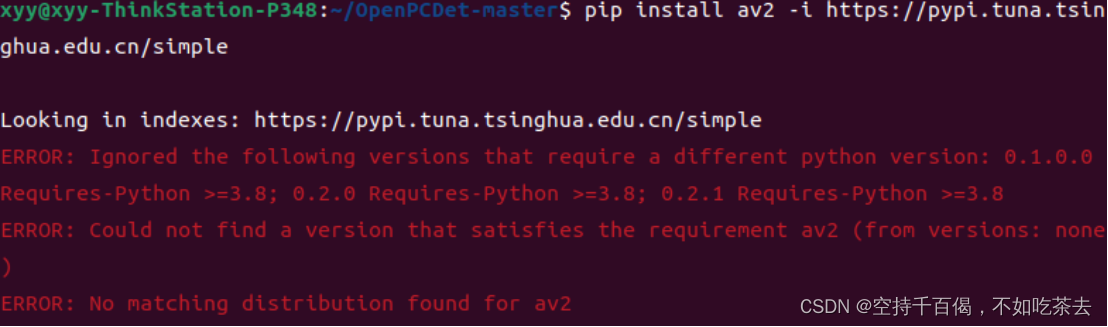
提示到:Requires-Python >=3.8,说明没有适配python3.7的‘av2’。
因此,安装av2时尽量保持python>=3.8版本。
42、报错:ModuleNotFoundError: No module named 'kornia'
解决方法:
使用指令
pip install kornia
不能使用torch1.9.1以下的版本安装,否则安装korina时会遇到如下提示:
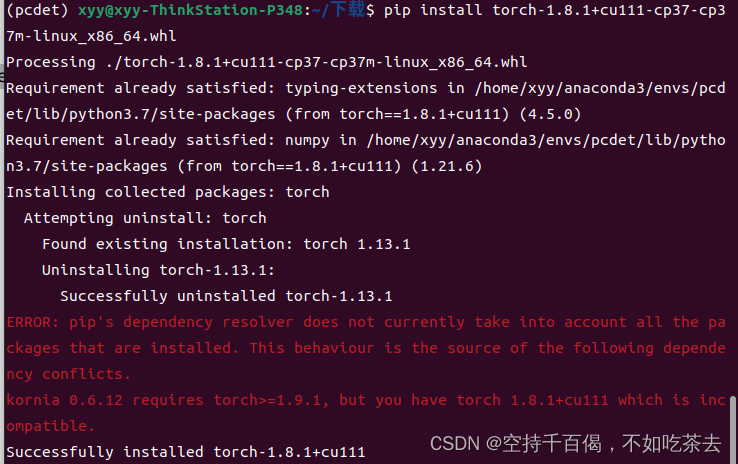
上面是安装完torch1.8.1的提示:kornia 0.6.12 requires torch>=1.9.1。是因为它的requirement.txt文件中要求torch>=1.9.1。
当然,你也可以选择安装低版本的kornia进行安装,我没有尝试过。
43、解决PermissionError: [Errno 13] Permission denied
答:
sudo chmod -R 777 文件夹名称
参考:jenkins:PermissionError [Errno 13] Permission denied 权限问题解决
四、其他环境安装时出现的问题
1、安装deformbale convolution时出现的错误:subprocess.CalledProcessError: Command '['ninja', '-v']' returned non-zero exit status 1.
问题详细描述:
- /home/xd/xyy/CenterPoint-master/det3d/ops/dcn/src/deform_conv_cuda.cpp:579:3: note: suggested alternative: ‘DCHECK’
- AT_CHECK(input.is_contiguous(), "input tensor has to be contiguous");
- ^~~~~~~~
- DCHECK
- ninja: build stopped: subcommand failed.
- Traceback (most recent call last):
- File "/home/xd/anaconda3/envs/centerformer/lib/python3.8/site-packages/torch/utils/cpp_extension.py", line 1666, in _run_ninja_build
- subprocess.run(
- File "/home/xd/anaconda3/envs/centerformer/lib/python3.8/subprocess.py", line 516, in run
- raise CalledProcessError(retcode, process.args,
- subprocess.CalledProcessError: Command '['ninja', '-v']' returned non-zero exit status 1.
这个其实是个坑,真的恶心人,后面紧跟着报错:
- File "/home/xd/anaconda3/envs/centerformer/lib/python3.8/site-packages/torch/utils/cpp_extension.py", line 1355, in _write_ninja_file_and_compile_objects
- _run_ninja_build(
- File "/home/xd/anaconda3/envs/centerformer/lib/python3.8/site-packages/torch/utils/cpp_extension.py", line 1682, in _run_ninja_build
- raise RuntimeError(message) from e
- RuntimeError: Error compiling objects for extension
其实关键问题在于前半段,有一个AT_CHECK报错:
这个AT_CHECK是老版本的东西,如果您使用的 torch>1.5,则需要将 代码里面的AT_CHECK 替换为 AT_ASSERT。
需要替换该字符的文件,包括但不限于:
ball_query.cpp,utils.h,group_points.cpp,interpolate.cpp,sampling.cpp等
-----------------------------------------------------------------------------------------------------------------------
注意要看报错的位置,一个一个打开改这么改就行,具体操作如下:
例如:
我这个报错的位置是:ops/dcn/src/deform_conv_cuda.cpp
/home/xd/xyy/CenterPoint-master/det3d/ops/dcn/src/deform_conv_cuda.cpp:579:3: note: suggested alternative: ‘DCHECK’
AT_CHECK(input.is_contiguous(), "input tensor has to be contiguous");
那么打开cpp,Ctrl+F直接搜:
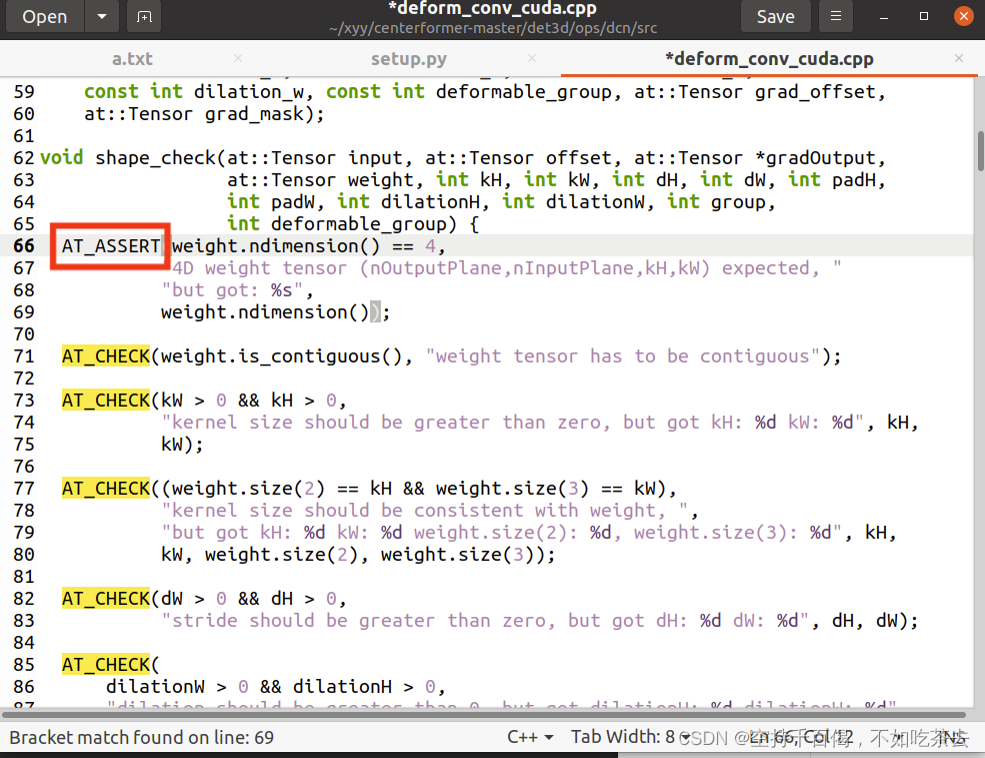
请参阅
https://github.com/facebookresearch/votenet/issues/97
2、OSError: libc++.so.1: cannot open shared object file: No such file or directory
问题详述:这个问题是我在变更anconda路径时遇到的,主要是由于open3d不能用了。我们可以尝试输入以下指令:
python
import open3d
观察会不会报以下错误:
- (vircompletion) xd@xd-HP-Z8-G4-Workstation:~$ python
- Python 3.8.15 (default, Nov 24 2022, 15:19:38)
- [GCC 11.2.0] :: Anaconda, Inc. on linux
- Type "help", "copyright", "credits" or "license" for more information.
- >>> import open3d
- Traceback (most recent call last):
- File "<stdin>", line 1, in <module>
- File "/home/xd/anaconda3/envs/vircompletion/lib/python3.8/site-packages/open3d/__init__.py", line 64, in <module>
- _CDLL(next((_Path(__file__).parent / 'cpu').glob('pybind*')))
- File "/home/xd/anaconda3/envs/vircompletion/lib/python3.8/ctypes/__init__.py", line 373, in __init__
- self._handle = _dlopen(self._name, mode)
- OSError: libc++.so.1: cannot open shared object file: No such file or directory
解决方法:我们可以把open3d删了重新装一次:
pip uninstall open3d
pip install open3d
3、setup.py时遇到问题:arch_list[-1] += '+PTX' IndexError: list index out of range
解决方法:
export TORCH_CUDA_ARCH_LIST="6.1;7.0;7.5;8.0+PTX"参考:磕岩日记 | arch_list[-1] += '+PTX' IndexError: list index out of range - 知乎
4、spconv编译成功,但是dist文件夹下生成的whl文件却是spconv-1.2.1-py3-none-any.whl 的问题
解决方法:将build文件夹删除,然后输入环境变量:
export SPCONV_DISABLE_JIT="1"接着再进行编译即可:
- python setup.py bdist_wheel
-
- pip install dists/xxx.whl
最后生成好的whl是有名字的,例如:
spconv-1.2.1-cp38-cp38-linux_x86_64.whl5、nvcc fatal : Unsupported gpu architecture 'compute_89'
问题详述:在spconv编译时出现以下问题:
- [ 4%] Building CUDA object src/cuhash/CMakeFiles/cuhash.dir/hash_functions.cu.o
- [ 8%] Building CUDA object src/utils/CMakeFiles/spconv_nms.dir/nms.cu.o
- [ 12%] Building CUDA object src/cuhash/CMakeFiles/cuhash.dir/hash_table.cu.o
- nvcc fatal : Unsupported gpu architecture 'compute_89'
- nvcc fatal : Unsupported gpu architecture 'compute_89'
- nvcc fatal : Unsupported gpu architecture 'compute_89'
- make[2]: *** [src/cuhash/CMakeFiles/cuhash.dir/build.make:63:src/cuhash/CMakeFiles/cuhash.dir/hash_functions.cu.o] 错误 1
- make[2]: *** 正在等待未完成的任务....
- make[2]: *** [src/utils/CMakeFiles/spconv_nms.dir/build.make:63:src/utils/CMakeFiles/spconv_nms.dir/nms.cu.o] 错误 1
- make[1]: *** [CMakeFiles/Makefile2:240:src/utils/CMakeFiles/spconv_nms.dir/all] 错误 2
- make[2]: *** [src/cuhash/CMakeFiles/cuhash.dir/build.make:89:src/cuhash/CMakeFiles/cuhash.dir/hash_table.cu.o] 错误 1
- make[1]: *** 正在等待未完成的任务....
- make[1]: *** [CMakeFiles/Makefile2:159:src/cuhash/CMakeFiles/cuhash.dir/all] 错误 2
- make: *** [Makefile:130:all] 错误 2
- Traceback (most recent call last):
- File "setup.py", line 96, in <module>
- setup(
- File "/home/xd/anaconda3/envs/pointpainting/lib/python3.8/site-packages/setuptools/__init__.py", line 107, in setup
- return distutils.core.setup(**attrs)
- File "/home/xd/anaconda3/envs/pointpainting/lib/python3.8/site-packages/setuptools/_distutils/core.py", line 185, in setup
- return run_commands(dist)
- File "/home/xd/anaconda3/envs/pointpainting/lib/python3.8/site-packages/setuptools/_distutils/core.py", line 201, in run_commands
- dist.run_commands()
- File "/home/xd/anaconda3/envs/pointpainting/lib/python3.8/site-packages/setuptools/_distutils/dist.py", line 969, in run_commands
- self.run_command(cmd)
- File "/home/xd/anaconda3/envs/pointpainting/lib/python3.8/site-packages/setuptools/dist.py", line 1234, in run_command
- super().run_command(command)
- File "/home/xd/anaconda3/envs/pointpainting/lib/python3.8/site-packages/setuptools/_distutils/dist.py", line 988, in run_command
- cmd_obj.run()
- File "/home/xd/anaconda3/envs/pointpainting/lib/python3.8/site-packages/wheel/bdist_wheel.py", line 364, in run
- self.run_command("build")
- File "/home/xd/anaconda3/envs/pointpainting/lib/python3.8/site-packages/setuptools/_distutils/cmd.py", line 318, in run_command
- self.distribution.run_command(command)
- File "/home/xd/anaconda3/envs/pointpainting/lib/python3.8/site-packages/setuptools/dist.py", line 1234, in run_command
- super().run_command(command)
- File "/home/xd/anaconda3/envs/pointpainting/lib/python3.8/site-packages/setuptools/_distutils/dist.py", line 988, in run_command
- cmd_obj.run()
- File "/home/xd/anaconda3/envs/pointpainting/lib/python3.8/site-packages/setuptools/_distutils/command/build.py", line 131, in run
- self.run_command(cmd_name)
- File "/home/xd/anaconda3/envs/pointpainting/lib/python3.8/site-packages/setuptools/_distutils/cmd.py", line 318, in run_command
- self.distribution.run_command(command)
- File "/home/xd/anaconda3/envs/pointpainting/lib/python3.8/site-packages/setuptools/dist.py", line 1234, in run_command
- super().run_command(command)
- File "/home/xd/anaconda3/envs/pointpainting/lib/python3.8/site-packages/setuptools/_distutils/dist.py", line 988, in run_command
- cmd_obj.run()
- File "setup.py", line 48, in run
- self.build_extension(ext)
- File "setup.py", line 92, in build_extension
- subprocess.check_call(['cmake', '--build', '.'] + build_args, cwd=self.build_temp)
- File "/home/xd/anaconda3/envs/pointpainting/lib/python3.8/subprocess.py", line 364, in check_call
- raise CalledProcessError(retcode, cmd)
- subprocess.CalledProcessError: Command '['cmake', '--build', '.', '--config', 'Release', '--', '-j4']' returned non-zero exit status 2.

解决方法:
这个是显卡框架太高了40系列,因此需要降算力:
- export TORCH_CUDA_ARCH_LIST="8.0"
- source ~/.bashrc
6、RuntimeError: Cannot re-initialize CUDA in forked subprocess. To use CUDA with multiprocessing, you must use the 'spawn' start method
解决方法1:torch.multiprocessing.set_start_method('spawn')
缺点:启动真的特别慢,不适合 调代码。
解决方法2:将num_workers设置为0
7、ImportError: cannot import name 'compare_ssim' from 'skimage.measure'
解决方法:
scikit-image降级:
pip install scikit-image==0.16.28、CUDA kernel errors might be asynchronously reported at some other API call,so the stacktrace below might be incorrect.
问题分析:网上其他方法给出的策略都是:
- import os
- os.environ['CUDA_LAUNCH_BLOCKING'] = '1' # 下面老是报错 shape 不一致
但是没用,既不是torch的问题,也不是cuda的问题,最后我发现是我数据索引越界了。
例如,我在改之前:
- # relative coords to absolute coords
- # feat_2d是bev特征:[batch, channels , H, W]
- # pc_norm_list是pc的相对坐标:[batch,num_points,2]
-
- # 创建了一个zeros矩阵
- sampling_abs_coords = torch.zeros(pc_norm_list[batch_id].shape[0], 2).to(feat_2d.device).long()
- # 图像索引的x, pc_norm是归一化后的相对坐标[0,1],这一步是转换为绝对坐标
- sampling_abs_coords[:, 0] = pc_norm_list[batch_id][:, 0] * feat_2d[batch_id].shape[1]
- # 图像索引的y
- sampling_abs_coords[:, 1] = pc_norm_list[batch_id][:, 1] * feat_2d[batch_id].shape[2]
- # 利用索引赋值
- feat_2d[batch_id, :, sampling_abs_coords[:, 0], sampling_abs_coords[:, 1]] = feat_2d_cross.t()
相对坐标转换为绝对坐标的时候,没有考虑到如果相对坐标是1,那么乘以特征图大小就会导致索引变成H或W,但是索引最大只能取到H-1,W-1,因此我最后加入了torch.clamp限制住了大小:
- # relative coords to absolute coords
- # feat_2d是bev特征:[batch, channels , H, W]
- # pc_norm_list是pc的相对坐标:[batch,num_points,2]
-
- # 创建了一个zeros矩阵
- sampling_abs_coords = torch.zeros(pc_norm_list[batch_id].shape[0], 2).to(feat_2d.device).long()
- # 图像索引的x, pc_norm是归一化后的相对坐标[0,1],这一步是转换为绝对坐标
- sampling_abs_coords[:, 0] = torch.clamp(pc_norm_list[batch_id][:, 0] * feat_2d[batch_id].shape[1], 0,feat_2d[batch_id].shape[1] - 1)
- # 图像索引的y
- sampling_abs_coords[:, 1] = torch.clamp(pc_norm_list[batch_id][:, 1] * feat_2d[batch_id].shape[2], 0, feat_2d[batch_id].shape[2] - 1)
- # 利用索引赋值
- feat_2d[batch_id, :, sampling_abs_coords[:, 0], sampling_abs_coords[:, 1]] = feat_2d_cross.t()

