
热门标签
热门文章
- 1从大咖视角窥探Sora六大技术创新_sora的创新 贴片
- 2IDEA中无法识别到Yaml/Yml文件的最简单解决方法
- 3安卓截屏监听_android 监听截屏
- 4Python故障诊断与异常检测_故障诊断与python学习 csdn
- 5M4C精读:融合多种模态到公共语义空间,使用指针增强多模态变形器来迭代应答TextVQA任务 Iterative Answer Prediction Pointer-Augmented_多模态语义空间
- 6[论文笔记]ROFORMER: ENHANCED TRANSFORMER WITH ROTARY POSITION EMBEDDING(上)
- 7俄罗斯 Android 系统受限,或将转用 HarmonyOS!
- 8数据结构-线性表_学生表抽象成一个线性表,每个学生(包括姓名、学号、成绩)作为线性表中的一个元素,
- 9java计算机毕业设计人才公寓管理系统源码+数据库+系统+lw文档+mybatis+运行部署_php人才公寓管理软件系统开发文档
- 10AD(Altium Designer) / AD16设置铺铜过孔连接方式、焊盘连接方式(四层板)_ad铺铜怎么设置过孔全连接
当前位置: article > 正文
Kafka生产者的一个Bug会导致部分消息一直无法发送_kafka发送消息失败常见原因
作者:小小林熬夜学编程 | 2024-04-17 05:08:44
赞
踩
kafka发送消息失败常见原因
最近在看Kafka生产者源码的时候, 感觉有个地方可以改进一下, 具体的问题和解决方案都在下面。
问题代码
RecordAccumulator#drainBatchesForOneNode
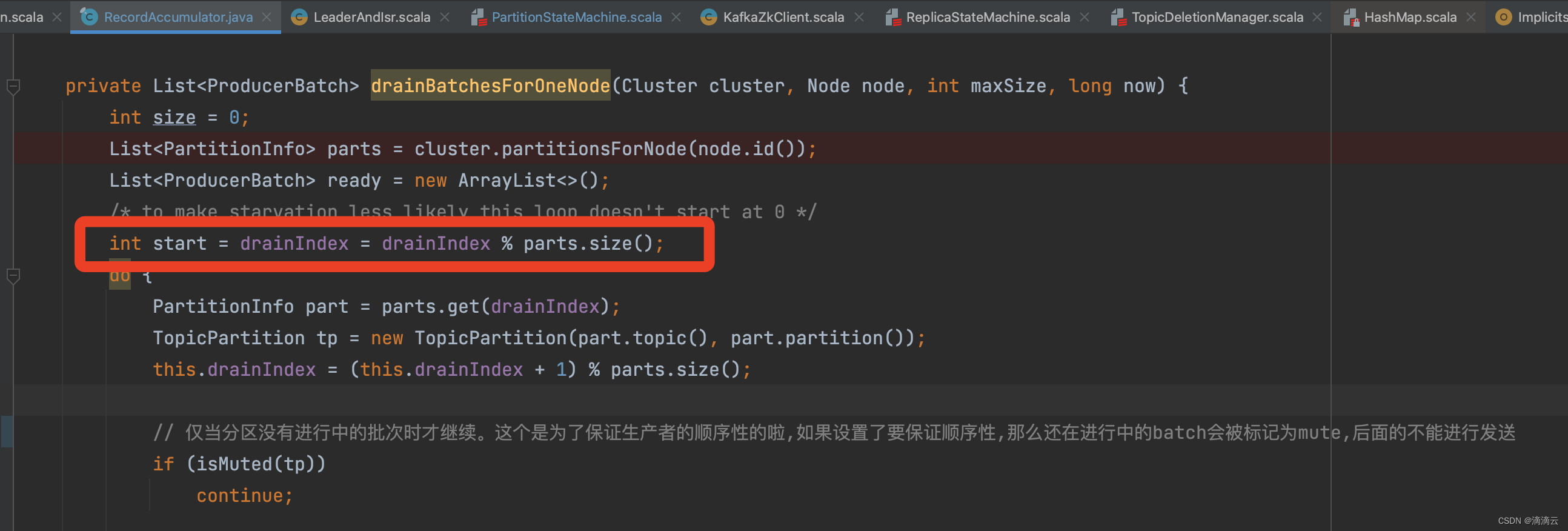
问题出在这个, private int drainIndex;
代码预期
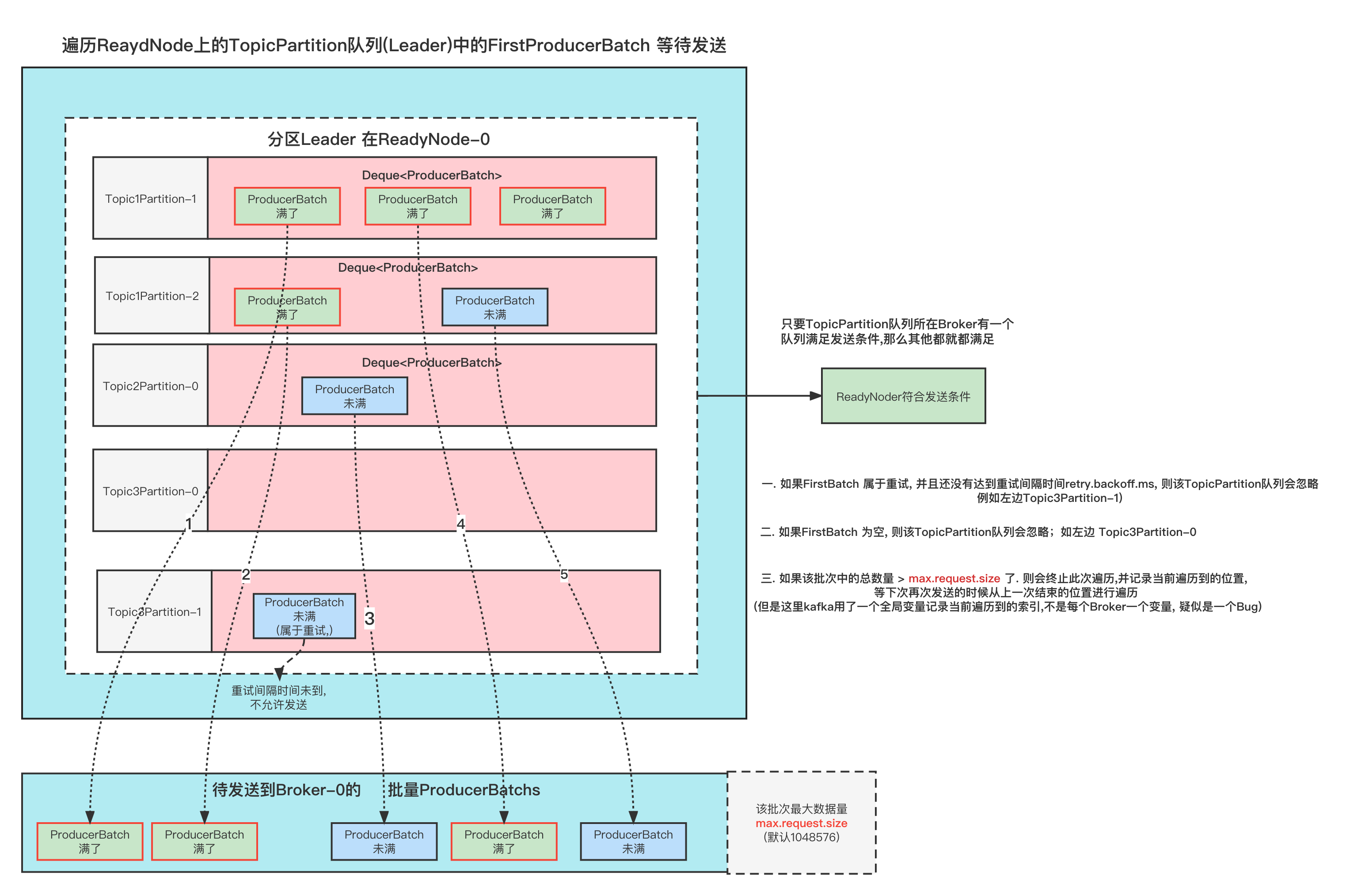
这端代码的逻辑, 是计算出发往每个Node的ProducerBatchs,是批量发送。
因为发送一次的请求量是有限的(max.request.size), 所以一次可能只能发几个ProducerBatch. 那么这次发送了之后, 需要记录一下这里是遍历到了哪个Batch, 下次再次遍历的时候能够接着上一次遍历发送。
简单来说呢就是下图这样
实际情况
但是呢, 因为上面的索引drainIndex 是一个全局变量, 是RecordAccumulator共享的。
那么通常会有很多个Node需要进行遍历, 上一个Node的索引会接着被第二个第三个Node接着使用,那么也就无法比较均衡合理的让每个TopicPartition都遍历到.
正常情况下其实这样也没有事情, 如果不出现极端情况的下,基本上都能遍历到。
怕就怕极端情况, 导致有很多TopicPartition不能够遍历到,也就会造成一部分消息一直发送不出去。
造成的影响
导致部分消息一直发送不出去、或者很久才能够发送出去。
触发异常情况的一个Case
该Case场景如下:
生产者向3个Node发送消息
每个Node都是3个TopicPartition
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/小小林熬夜学编程/article/detail/438350
推荐阅读
相关标签

