
- 1好看实用的六个html登录页面_登录页面代码
- 2计算机网络复习题(含答案)_某中小型企业包含4个部门,每个部门不超过60台计算机。该企业申请使用私有ip地址19
- 3Linux驱动开发(蜂鸣器,LED驱动)(pinctil、gpio子系统)_粤嵌蜂鸣器
- 4MYSQL ON DELETE CASCADE ON UPDATE CASCADE 外键的级联删除和级联更新_mysql delete cascade on update cascade
- 5【鸿蒙应用ArkTS开发系列】-自定义底部菜单列表弹窗_鸿蒙列表制作
- 6UnicodeDecodeError: 'utf8' codec can't decode byte 0xa5 in position 0: invalid start byte_unicodedecodeerror: 'utf-8' codec can't decode byt
- 7高防IP的技术实现
- 8数字IC/芯片岗位实习面经-2021暑假实习_数字ic项目经历
- 9javaweb:域对象的属性操作setAttribute(),getAttribute()及其作用范围_object 变量 = 作用域对象.getattribute(属性名变量类型
- 10为什么写flash之前需要先擦除_flash写入前为啥一定要擦除
AI NIP人工智能 用LLM(大模型)进行关系抽取_怎么利用大模型的理解能力实现关系抽取
赞
踩
就现在来说,在NLP领域,大模型(Large Language Models,LLM)已成主导地位,它在很多任务上已经彰显其优势,尤其在传统的生成类任务上。而今天说下LLM在关系抽取任务上的表现。
来自2023 ACL会议的一篇paper<Revisiting Relation Extraction in the era of Large Language Models>,在4个数据集上验证了大模型在关系抽取的效果,并提出LLM+CoT+fine-tuning方式来做关系抽取,能带来更好的效果。下面说下LLM做关系抽取的形式,实验结果,以及LLM+CoT+fine-tuning方法。这里面CoT是指Chain-of-Thought,是GPT3模型中的一种学习推理范式。
抽取形式还是保持传统的三元组形式,只是抽取方法变成生成式,而不是序列标注或者span识别的方式;生成式的方式如下:
Input: Bill Nelson, NASA administrator announced the mars mission today.
output: [(Bill Nelson:Per, Work_For, NASA:Org)...]
结果形式为:[(entity_1:entity_1_type, relation_type, entity_2:entity_2_type),...],若数据集中只有一种关系,也可以不要relation_type,变成两元组;
在CONLL、ADE、NYT三个关系抽取数据集验证结果如下:
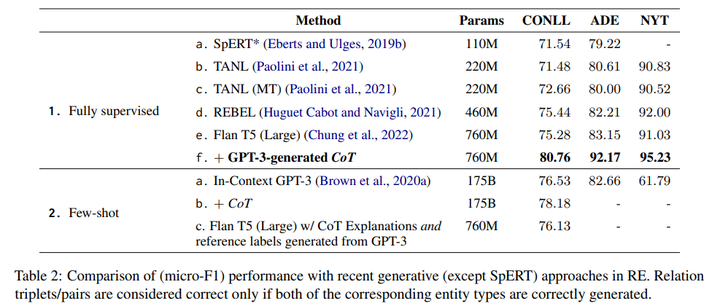
图片
(1)在监督学习下,Flan T5(large)+GPT3-generated CoT 微调方式表现效果最好,在CONLL和NYT数据集都有约4个点的提升,在ADE数据集有近9个点的提升,效果还是非常的明显;
(2)在监督学习下,大模型 Flan T5(large)相比其他小模型,TANL、REBEL等带来的效果并不明显,甚至在有些数据集还不如;
(3)在few-shot,GPT3的结果也很惊艳,在CONLL数据集上,超过传统的模型;ADE数据集上已是很接近,只是在NYT数据集上表现有些差距。原因是NYT数据集相对前两个更复杂些;
(4)最重要的是,不论监督还是few-shot,论文发现带上CoT方式,都能带来很明显的增益。
备注 :可能有人觉得论文把760M大小的Flan T5(large)当做大模型不妥,这是时间差原因,论文写作时,像LLaMA,ChatGLM这类大模型也没开源,也没法用这些来验证;最重要是论文提出用CoT方式来微调增强关系抽取,这点还是值得借鉴。下面详细说下这个思路。
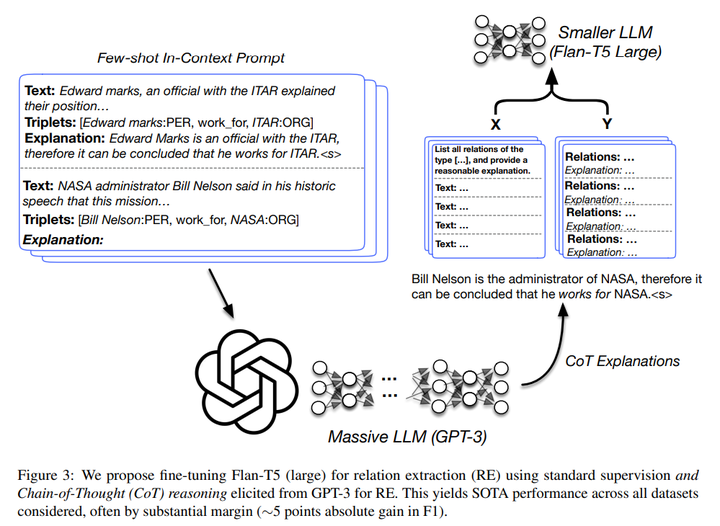
图片
其做法是在上述的学习范式中,加上一个Explanation,对抽取的结果进行下解释说明,形式如下:
Input: In Colorado , 13 inches of snow in Denver Wednesday prompted officials to close Interstate 270 temporarily.
Target: [(Denver, Located In, Colorado)]
Explanation: -Denver officials closed Interstate 270 in Colorado, consequently we can see that Denver is located in Colorado.
在操作时,人为给一些这样完整的样例,交个GPT3模型,然后其去补充其他数据中的Explanation,这样就收集一版新的数据集,可认为是增强的数据集,接着交给Flan-T5小一点的模型去微调学习。在学习中,输入还是Input,输出Output为:Target+Explanation。
其实Expanation里的内容是对关系类型起着一种解释的作用,尤其当任务中关系类型比较多时,应该帮助更明显。
利用大模型做关系抽取,也出现不一样的错误:

图片
(1)ADE数据集上的,显示客实体识别错误,这是传统模型也会出现测错误;
(2)CoNLL04数据集上,显示关系识别错误,且对主实体进行了多识别,并对单词Ambassador进行了缩写——可理解为生成了不在原文的字符,这是传统抽取方法不会出现的;
(3)在NYT数据集上,出现识别出错误的三元组;
(4)在Out-of-Domain(CoNLL04)数据上,显示关系类型“Shot_By”识别成了“kill”,但整体语义逻辑是对的,这种错误也是传统方法不会出现的;
这里结合个人的观点,说下大模型做关系抽取的优劣:
优势:
(1)泛化能力强,不需要太多监督数据,就能达到不错的效果;
(2)能处理更长的序列,尤其长依赖关系,文档级的关系抽取;
(3)可以同时处理多个任务,关系抽取、NER识别、分类等,减少多个模型维护;
劣势:
(1)训练和推理成本都较高,抽取效率也没传统方法高;
(2)会识别出不在原文里的token或不在关系集合中类似关系;
目前来说,在关系抽取等任务上,大模型还没到完全取代的地步。效率还是目前主要限制因素,个人认为,NLP传统任务融合成一个模型来完成是发展趋势,而这更适合大模型来做。

