
- 1Neo4j入门(二)批量插入节点、关系_neo4j批量创建关系
- 2hadoop高可用集群搭建_高可用 hadoop 集群的搭建
- 3基于LLaMA Factory,单卡3小时训练专属大模型 Agent_llama factory windos
- 4API安全的学习手册_api安全完全手册
- 5使用Docker部署开源项目FreeGPT35来免费调用ChatGPT3.5 API_vercel免费版有什么限制
- 6【花雕动手做】ASRPRO语音识别(35)---串口0#十六进制数打开继电器_asrpro串口
- 7YOLOX安装、测试,自定义coco数据集进行测试_yolox安装教程
- 8Java-高级技术(二)_java取钱模型小明
- 9蓝桥杯笔记-2023年第十四届省赛真题-松散子序列_蓝桥杯松散子序列c++
- 10C语言--数据结构:单链表
关于instruct GPT和llama2中强化学习的笔记
赞
踩
instruct GPT 中的RLHF:
奖励模型RM的训练:
损失函数如下:

初始奖励模型为6B的一个语言模型修改掉最后一层的输出头,由概率输出改为标量分数,输入是人类对于k个答案的排序。
损失函数采用logistic loss,以达到最大化奖励分数的目的。
奖励模型的作用是,拥有对模型输出结果的排序能力(模拟人类的偏好),用于后续强化学习的训练。
强化学习方式:

: 需要学习的强化学习策略,初始为
:奖励模型的输出
:经过SFT后的预训练模型
1.将x丢进初始,产生y,然后将(x,y)输入
,得到奖励分数,我们希望这一项最大。由于在模型更新过程中,采样到的y会随之发生变化,因此奖励模型的作用在这一步就是模拟人类对新生成的y的排序,不断用最高分的y去优化模型本身。
要标排序而不是直接标y的原因:一是保证灵活性,二是减小人工成本,直接标y那就成了SFT。
2.开头的那一项是惩罚项,用KL散度来约束两个分布的相似性。训练
的y来自于
(尽管模型比较小),训练
的y来自于它本身,随着模型迭代,与SFT相差会变大,因此作为约束条件。
3.前两项即为PPO算法的主要思想,最后一项是引入一些预训练时候的数据,分配一些权重,防止模型过于依赖SFT后的模型。
llama2中的强化学习:
关于奖励模型:
The model architecture and hyper-parameters are identical to those of the pretrained language models, except that the classification head for next-token prediction is replaced with a regression head for outputting a scalar reward
译:模型架构和超参数与预训练语言模型相同,除了用于下一个标记预测的分类头被用于输出标量奖励的回归头所取代。
注:与gpt3做法一致。
损失函数:
![]()
为被选择的,
为被拒绝的。
m(r)是关于y的评级的离散函数,gpt3使用了k=9个答案对排序总后取期望的做法,llama2使用了两个不同模型生成的回复中选一个拒绝一个的做法。原文如下:
We ask annotators to first write a prompt, then choose between two sampled model responses, based on provided criteria. In order to maximize the diversity , the two responses to a given prompt are sampled from two different model variants, and varying the temperature hyper-parameter. In addition to giving participants a forced choice, we also ask annotators to label the degree to which they prefer their chosen response over the alternative: either their choice is significantly better, better, slightly better, or negligibly better/ unsure.
译:我们要求注释者首先编写提示,然后根据提供的标准在两个抽样模型响应之间进行选择。为了使多样性最大化,对给定提示的两个响应从两个不同的模型变量中采样,并改变温度超参数。除了给参与者一个强制选择之外,我们还要求注释者标记他们对选择的答案的偏好程度:他们的选择是明显更好,更好,稍微更好,或者可以忽略的更好/不确定。
最终的奖励函数:
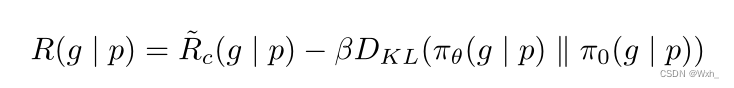
注:同样是PPO算法。

