
- 1开源大数据工具整理_最全大数据组件整理
- 2Android的四种监听事件处理方式_简述 android 系统基于监听的事件处理机制的 4 种实现方式。
- 3面向文档的代理:矢量数据库、chatgpt、Langchain、FastAPI 和 Docker 之旅,利用 ChromaDB、Langchain 和 ChatGPT:增强大型文档数据库的响应和引用来_docker chromadb
- 4git合并远程库并将代码合并完提交到自己的分支的流程_合并其他人的代码后提交自己的代码
- 5spark概述和scala的安装部署
- 6找到服务器系统日志,查看服务器系统日志
- 7数据结构学习——树形结构之递归遍历二叉树
- 8消费级显卡轻松跑AI,英伟达RTX领跑AI PC竞争
- 9Hive 常用函数_hive lpad
- 10android自定义选年控件,Android精美日历控件CalendarView自定义使用完全解析
llama3 史上最强开源大模型,赶超GTP-4,逼宫OpenAI
赞
踩
2024年4月18日,Meta公司推出了开源大语言模型Llama系列的最新产品—Llama 3,包含了80亿参数的Llama 3 8B和700亿参数的Llama 3 70B两个版本。Meta称其为“迄今为止最强的开源大模型”。
怪兽级性能
LLaMA3 提供了不同参数规模的版本,以适应不同的计算资源和应用需求:
- Llama3 8B:适用于消费级 GPU 上的高效部署和开发,适合对计算资源有约束但需要良好语言处理能力的场景。
- Llama3 70B:专为大规模 AI 应用设计,具备更强的处理复杂语言任务的能力,适用于需要顶级性能的研究和工业级项目。
8B模型在多项指标中超越了Gemma 7B和Mistral 7B Instruct,而70B模型则超越了闭源的Claude 3 Sonnet,和Gemini Pro 1.5。
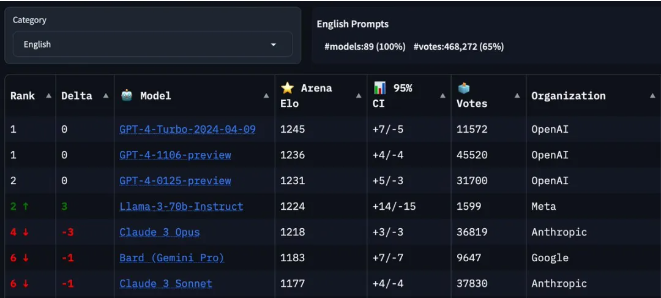
没想到,70B都这么能打,此外Meta还有一个still training的400B+参数版本,它和GPT-4以及Claude 3的超大杯版本Opus性能差不多,最重要的是,它即将开源!
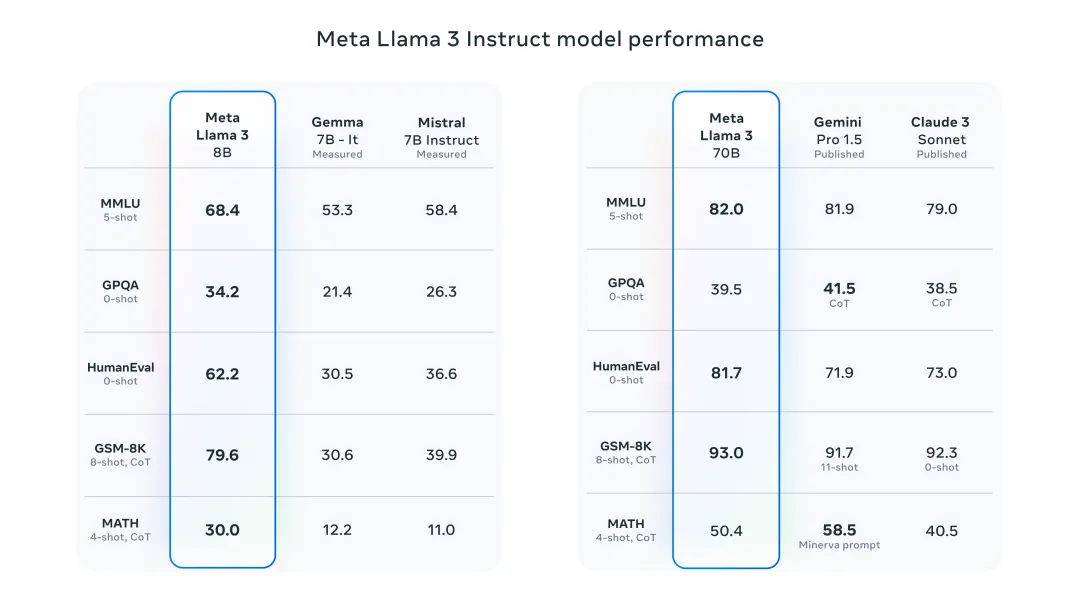
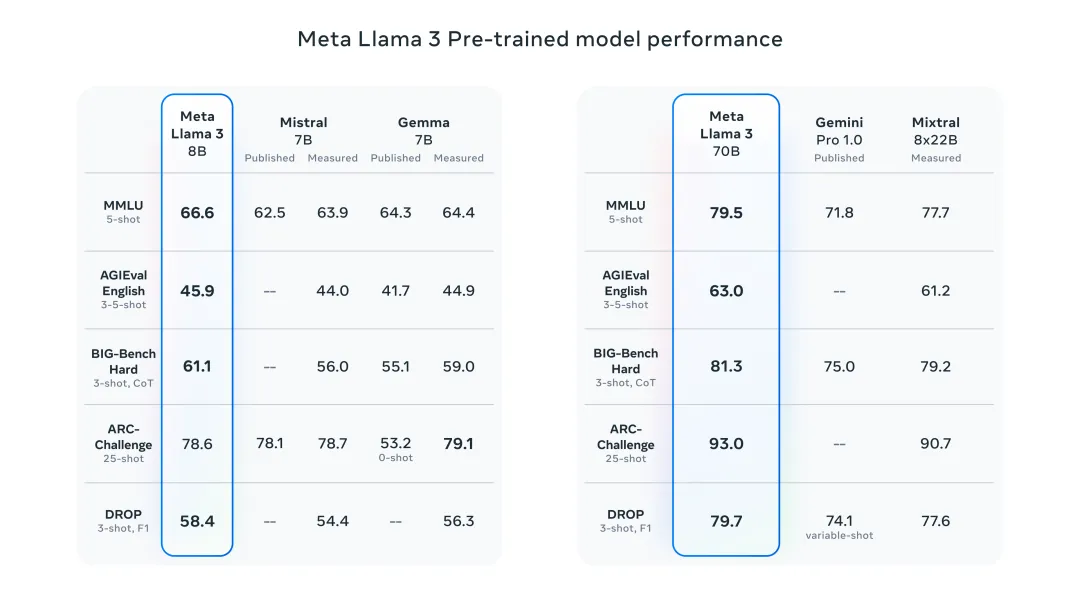
之所以说Llama3是“最强开源”,是因为它在模型架构,预训练数据,扩大预训练规模以及指令微调方面都做出了重要的调教。
**在模型架构方面,Llama 3 选择了经典的Decoder-only的Transformer架构。**与Llama 2相比,Llama 3做了几个关键的改进,包括:
- 使用具有128K token词汇表的tokenizer,可以更有效地对语言进行编码。
- 在 8B 和 70B 大小的模型上采用了分组查询注意力 (GQA),提高了Llama 3的推理效率。
- 在8192个token的序列上训练模型,使用掩码确保自注意力不会跨越文档边界。这也是美中不足的一点,8k的上下文窗口依然有点过时,不过随着开源社区的努力,这个问题可能很快就会被解决。
**训练数据方面,Meta 表示,要训练出最佳的语言模型,最重要的是策划一个大型且高质量的训练数据集。**根据数据现实,Llama 3 在超过 15T 的 token 上进行了预训练,训练数据集是 Llama 2 的7倍,包含的代码数量达到了Llama 2 的4倍。**为了应对多语言使用情况,Llama 3 的预训练数据集中有超过5%的部分是高质量的非英语数据,涵盖 30 多种语言。**而为了确保Llama 3始终在最高质量的数据上进行训练,Meta还开发了一系列数据过滤管道,诸如启发式过滤器,NSFW 过滤器,语义重复数据删除方法,文本分类器等,以便更好的预测数据质量。与此同时,Meta还进行了大量实验,确保 Llama 3 在各种使用情况下都能表现出色,包括琐事问题,STEM,编码,历史知识等。
**在扩大预训练规模方面,为了让Llama 3 模型有效利用预训练数据,Meta 为下游基准评估制定了一系列详细的 scaling laws。**这些 scaling laws 使他们能够选择最佳的数据组合,并就如何更好地使用训练计算做出最佳决定。更重要的是,在实际训练模型之前,scaling laws允许他们预测最大模型在关键任务上的性能,这有助于 Llama 3 在各种用例和功能中都能发挥强大的性能。
在指令微调方面,为了在聊天用例中充分释放预训练模型的潜力,Meta 对指令微调方法进行了创新,在后期训练方法中结合了监督微调(SFT),拒绝采样,近似策略优化(PPO)以及直接策略优化(DPO)。
令人期待的400B+参数版本
此次Llama3的发布,还有一点惹人瞩目,那就是Meta官方表示,即将在不久的未来推出400B+版本。
Meta 官方表示,Llama 3 8B 和 70B 模型只是 Llama 3 系列模型的一部分,他们后续还将推出更多版本,其中就包括模型参数超过 400B 的 Llama 3 版本,这一版本目前仍在训练中。

在接下来的几个月中,Meta会持续推出新功能:届时会有更多的模态;更长的上下文窗口;更多不同大小版本的模型;更强的性能等。关于Llama 3研究论文也一应推出。
另外,Llama 3 模型将很快会在AWS,Databricks,Google Cloud,Hugging Face,Kaggle,IBM WatsonX,Microsoft Azure,NVIDIA NIM 以及Snowflake 上提供,并得到 AMD,AWS,Dell,Intel,NVIDIA 以及Qualcomm 硬件平台的支持。
当然,大家最期待的,还是即将推出的,参数超过400B+的版本。目前Llama3模型的最强参数是70B。这个数据已经十分优秀了,完全有能力和GPT-4-Turbo,Mistral-Large,Claude3-Opus相媲美。不过,相较于巨头的最强模型,仍旧存在不小的差距。这也是大家如此期待400B+版本的重要原因。
400B+的版本仍在训练中,单就目前释放出的评测结果来看已经非常强了,堪称Llama开源size中的“超大杯选手”。据悉,该模型的训练成本会达到1亿美元。 目前我们还不清楚Meta是否会开源“超大杯”。一旦开源,对于国内的大模型公司来说无疑是个重大利好。相信在此之后,也会有很多公司争先跟上,推出后续的应用。但凡事都有两面,对于OpenAI,Anthropic,Mistral,Google这些巨头而言,这未必是个好消息。


