
- 1centos部署前后端项目
- 2定义图书类Book(有四个属性),图书馆Library类(一个hashset集合,可增加新书,查看添加的书)........详细题目可看内容_编写一个图书馆藏书的书籍类book2,类中有4个成员变量,分别存放书编号(isbn)、书名
- 3盲人出行安全保障:科技革新助力无障碍生活新纪元
- 4内网穿透工具zerotier的安装及使用
- 5python(简单制作注册登录系统)
- 69.12 具名函数表达式
- 7uniapp踩坑 uni.showToast 和 uni.showLoading_uni.hideloading();和uni.showtoast冲突
- 8界面开发(2)--- 使用PyQt5制作用户登陆界面_python使用pyqt5做一个登录注册界面
- 9Apk逆向反编译_反编译apk
- 10机器学习算法之k-近邻算法(python实现)_python最近邻算法
2021-10-19 nlp_1 nltk的基本应用_如何在nltk中用外界的文本
赞
踩
Anaconda环境下nltk的应用
1.nltk包的引入
最开始的时候,如果用如下的命令去下载的话,下载速度会很慢甚至下载不动
import nltk
nltk.download()
- 1
- 2
所以我们需要自己去github上下载nltk_data语料库或者找其他分享的网盘链接:
如果是github上下载,在D:\下 git bash here输入:
git clone https://github.com/nltk/nltk_data.git
用git clone好的应该如下图所示:
实际上有用的(要用的)是pachages这个文件夹,将其复制到指定的路径下。可以用如下命令查看路径:
from nltk.book import *
- 1
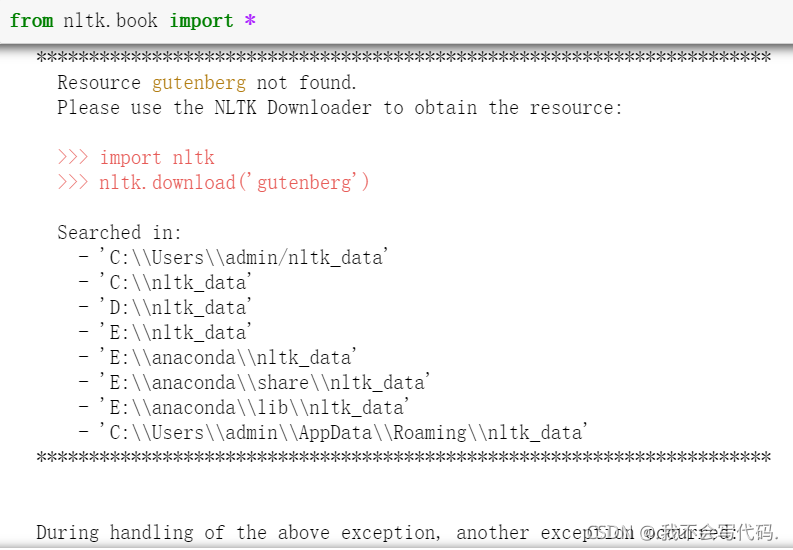
这里我放在E:\\anaconda\\ 目录下,并且需要将目录名改为nltk_data
再执行from nltk.book import *还是会报相同的错误,但是明明已经将nltk_data放到了指定的目录下。
原来是需要将nltk_data下各个目录里的压缩文件解压缩,不然在jupyter上还是不能找到这几个相应的内容包。(下面图片以corpora这个文件夹为例)
再执行·from nltk.book import *命令
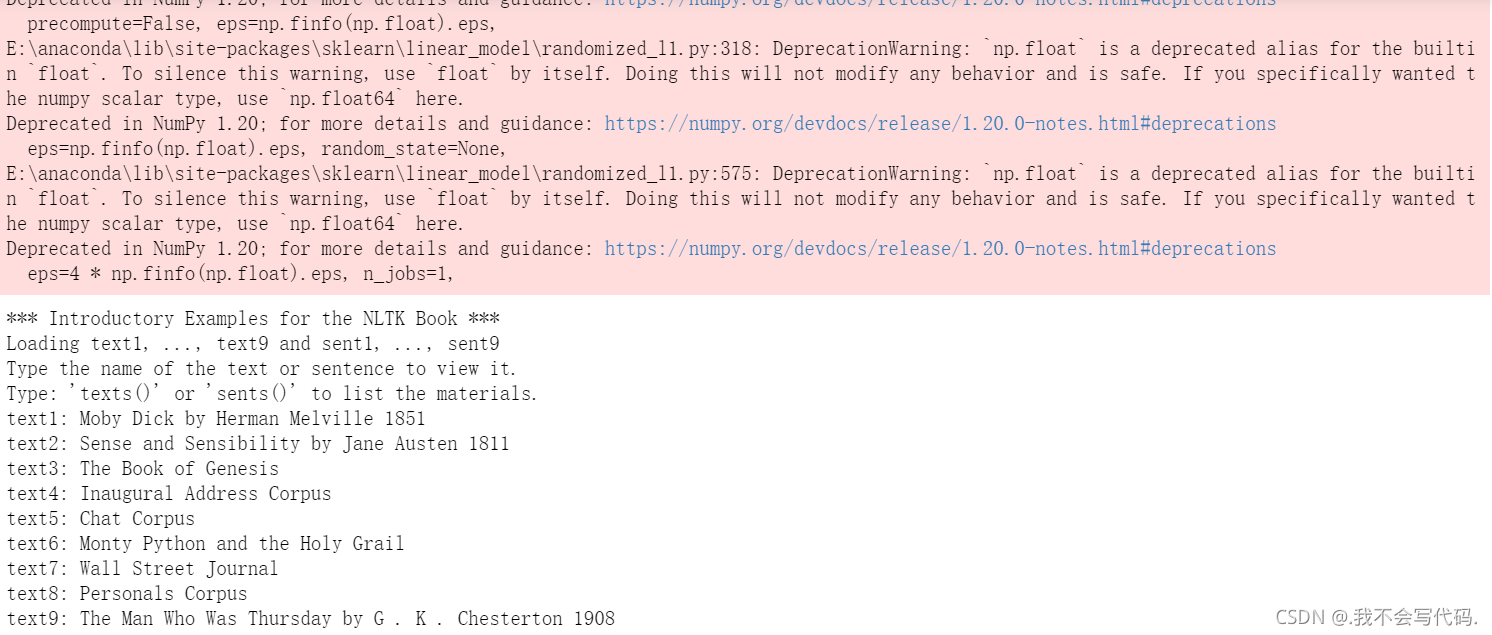
上面的虽然是红色,但是只是warning不是errors,所以只需要看下面的内容,当出现text9这九条数据语料库的时候,说明已经安装成功nltk了。
2.nltk包的简单应用
nltk简单题目应用
①载入自己的英文语料库(也可选取或者切片截取NLTK语料库中的部分文字)进行词搜索和词频统计(自行选择单词和单词个数),计算词汇在文本中出现的频率。绘制文本中高频词频率分布图(词个数任意)
''' 选取的英文语料库为text1:Moby Dick by Herman Melville 1851的截取片段 此搜索选取的词为prety,affection,happy,good ''' #导入nltk.book里的text1文本 from nltk.book import text1 #选取搜索的词为prety,affection,happy,good text1.concordance("pretty") text1.concordance("affection") text1.concordance("happy") text1.concordance("good") #选取统计的词也为prety,affection,happy,good print("\ntext1文本中单词pretty出现的次数为:",text1.count("pretty")) print("\ntext1文本中单词affection出现的次数为:",text1.count("affection")) print("\ntext1文本中单词happy出现的次数为:",text1.count("happy")) print("\ntext1文本中单词good出现的次数为:",text1.count("good")) #找出文本中的最高频的十个词汇并且去掉频率最高的几个标点符号 fdist1 = FreqDist(text1) fdist1.pop(",") fdist1.pop(".") fdist1.pop(";") fdist1.pop("'") fdist1.pop("-") fdist1.plot(10) #作出频率图像

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
词搜索的结果如下:


指定词频统计结果如下:

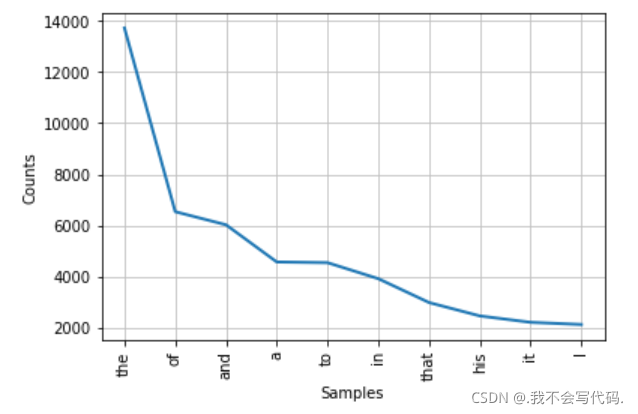
高频词汇的统计结果制成图像结果如下:
②找出上一题的语篇中长度大于5的高频词汇和文中常用的双联词固定搭配
#导入nltk.book里的text1文本
from nltk.book import text1
fdist1 = FreqDist(text1) #先将text1文本里的词汇和出现频率作为键值对写出
#认定高频词汇为出现次数大于等于100次的词汇
#先找出长度大于5的词汇,然后判定该词出现频率是否大于100
result=sorted([word for word in set(text1) if len(word) > 5 and fdist1[word] >= 100])
result
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
在编写找出文中常用的双联词固定搭配的代码的时候出现了问题。我在使用collocation_list()这个方法的时候会报错 AttributeError: ‘Text’ object has no attribute ‘collocation_list’
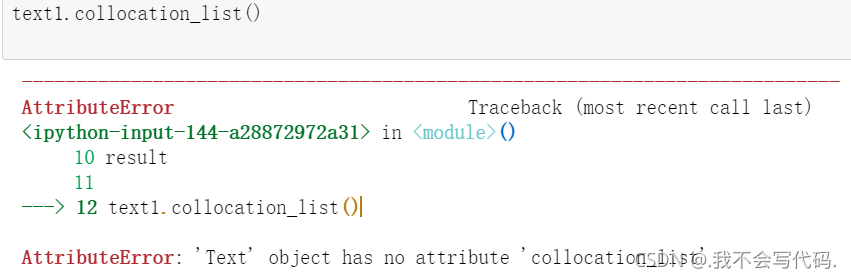
但是老师给的例子以及百度出来的结果都没有能解决问题的,基本上都是只介绍collocation_list()的以及报错报的是collocations()的。后来去StackOverflow上找问题,看到一个解答是I needed to initialize my corpus (see: http://www.nltk.org/api/nltk.html#nltk.text.Text).即需要初始化语料库,然后附上了他解决的例子:
>>> from nltk.text import Text
>>> text458 = Text(eng_corpus.words())
>>> text458.collocation_list()
['Hong Kong', 'United States', 'Getty Images', 'European Union', 'Northern Ireland', 'Boris Johnson', 'Prime Minister', 'Islamic State', 'Extinction Rebellion', 'Cape Dorset', 'extradition bill', 'Recep Tayyip', 'HONG KONG', 'Mike Pence', 'New York', 'Tayyip Erdogan', 'Democratic Forces', 'Vice President', 'Anthony Kwan', 'Kurdish fighters']
- 1
- 2
- 3
- 4
但是在我使用的过程中,即使是用了Text去初始化它还是会报相同的错误,所以只能直接用类似的collorations()方法,并且在查看源码的时候发现collorations()方法里就有colloration_list()方法。
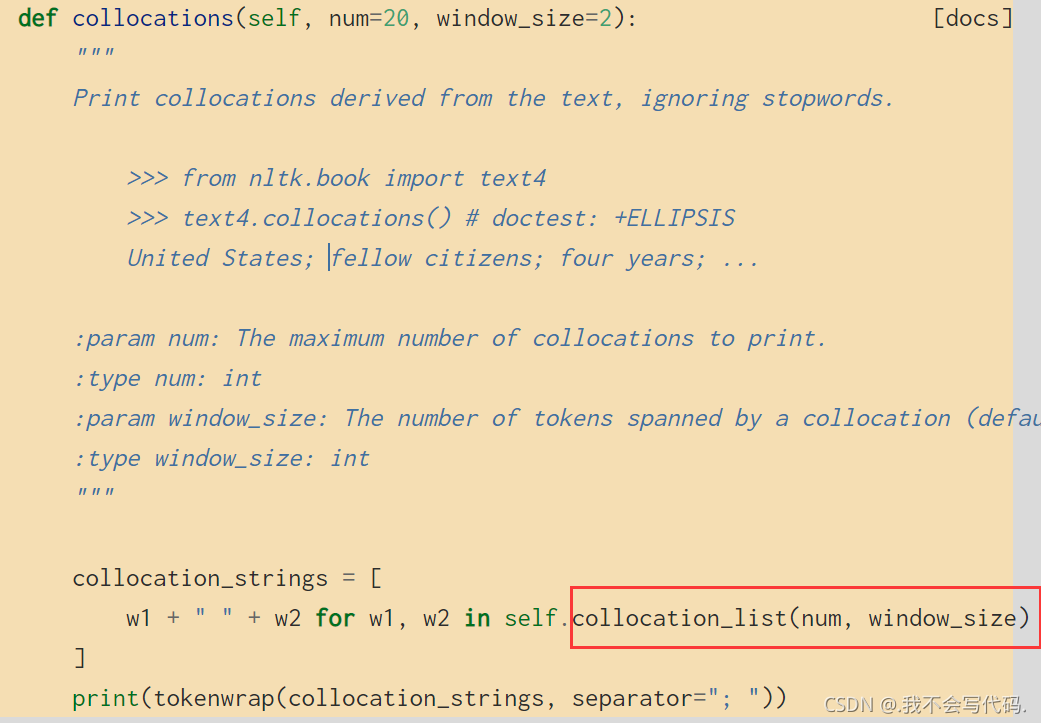
所以就直接用collocations()方法。
text1.collocations()
- 1
但是collocations()相对于collocation_list()方法是不能选取前多少个的,它输出的数据类型是Nonetype

③选取NLTK语料库中的某个类别,统计给定单词出现的频率;然后统计该词在该语料库的不同类别文体中出现的频率
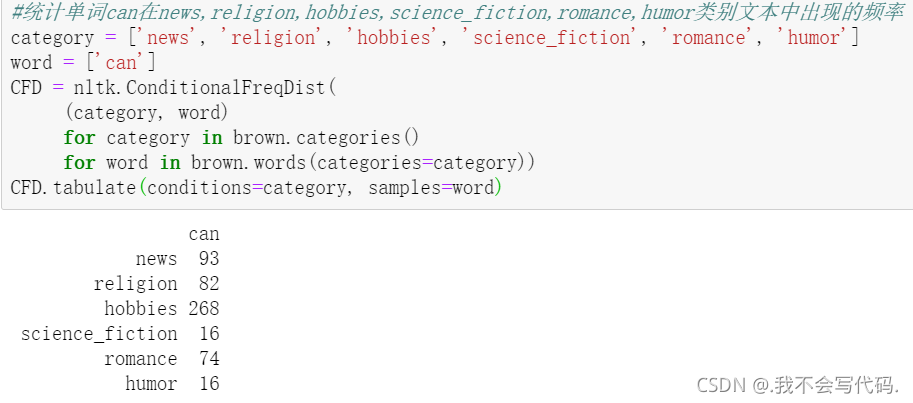
#载入布朗语料库 from nltk.corpus import brown brown.categories() #查看布朗语料库包含的类别 # brown.words(categories='news') #选定单词为can,选定类别为adventure words = brown.words(categories='adventure') #将adventure里按单词形式存储 fdist = FreqDist(words) #对words进行词频统计 fdist['can'] #查看单词can出现的频率 #统计单词can在news,religion,hobbies,science_fiction,romance,humor类别文本中出现的频率 category = ['news', 'religion', 'hobbies', 'science_fiction', 'romance', 'humor'] word = ['can'] CFD = nltk.ConditionalFreqDist( (category, word) for category in brown.categories() for word in brown.words(categories=category)) CFD.tabulate(conditions=category, samples=word)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
categories()方法可以查看语料库的类别,比如在brown语料库中使用该方法:

words(categories=‘news’)对news类文本进行分词查看:

统计can在adventure类型文本里的出现频率:

ConditionalFreqDist()函数是一种返回值为条件频率分布的函数,条件频率分布需要处理的是配对列表,每对的形式是(条件,事件),conditions()函数会返回这里的条件。
④自己选择一段中文语料,利用NLTK的words和sents函数获取其中的词和句子结果,观察结果说明其中存在着哪些问题
import nltk
from nltk.corpus import sinica_treebank
print(sinica_treebank.words())
print(sinica_treebank.sents())
- 1
- 2
- 3
- 4
- 5
先看下取出的词和句子的结果:

在这个例子当中,我使用的是nltk语料库中自带的sinica_treebank作为中文语料,用words函数获取的结果可以看到,结果是按照一个词一个词来分的,并不能看出句子的区别;但是通过sents函数获取的结果可以发现,不仅是有词的分别,并且能够看到获取的句子的结果,每个句子和句子之间都有明显的分隔的。

