
- 1标准DH建模与改进DH建模(三)—— 怎么用改进DH法_工业机器人dh和改进dh
- 2带T带Z的时间字符串使用LocalDateTime类转换成时间/时间戳类型_时间戳 t z
- 3命令行实现FFMpeg拉流推流方法思路_ffmpeg 推流 命令行
- 4数据安全被篡改的风险分析解决方案_信息安全 数据窜改风险监测
- 5解决 macOS 系统向日葵远程控制鼠标、键盘无法点击的问题_macos远程windows桌面键盘锁了
- 6完美收官!字节4面斩下2-2Offer,入职就是30K16薪,全凭这套“面试+架构进阶知识点
- 7python lxml用法
- 8[Linux防火墙]一文学会防火墙概念及常用命令_linux防火墙怎么设置默认区域
- 9Linux环境(Ubuntu)上搭建MQTT服务器(EMQX )_ubuntu怎么开放emqx相关端口
- 10【MATLAB源码-第139期】基于matlab的OFDM信号识别与相关参数的估计,高阶累量/小波算法调制识别,循环谱估计,带宽估计,载波数目估计等等。_ofdm循环谱
SQL 创建索引,语法_sql建立索引
赞
踩
索引介绍,及原理
当数据库表的数据太过庞大,的时候我们可以通过添加索引的形式解决。
聚集索引:数据的实际存储顺序与我们做索引的顺序是一致的,这种索引我们将它成为聚集索引。
非聚集索引: 数据的实际存储顺序与我们做的索引顺序不一致的时候,像这种快速查找数据的索引我们将它成为非聚集索引。
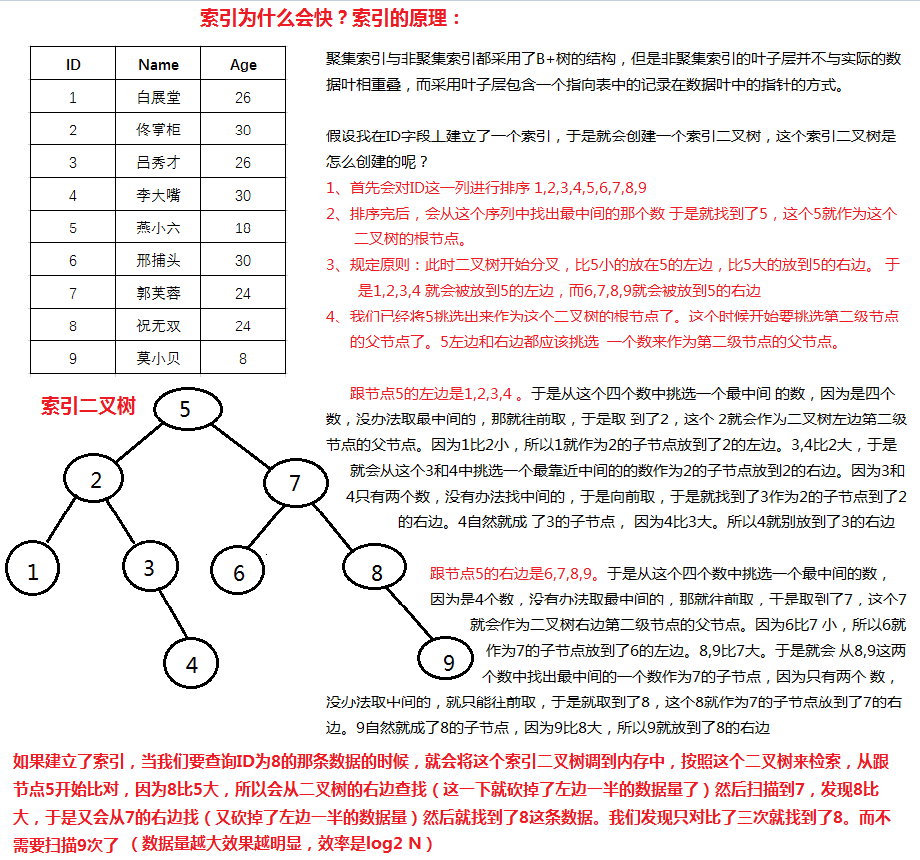
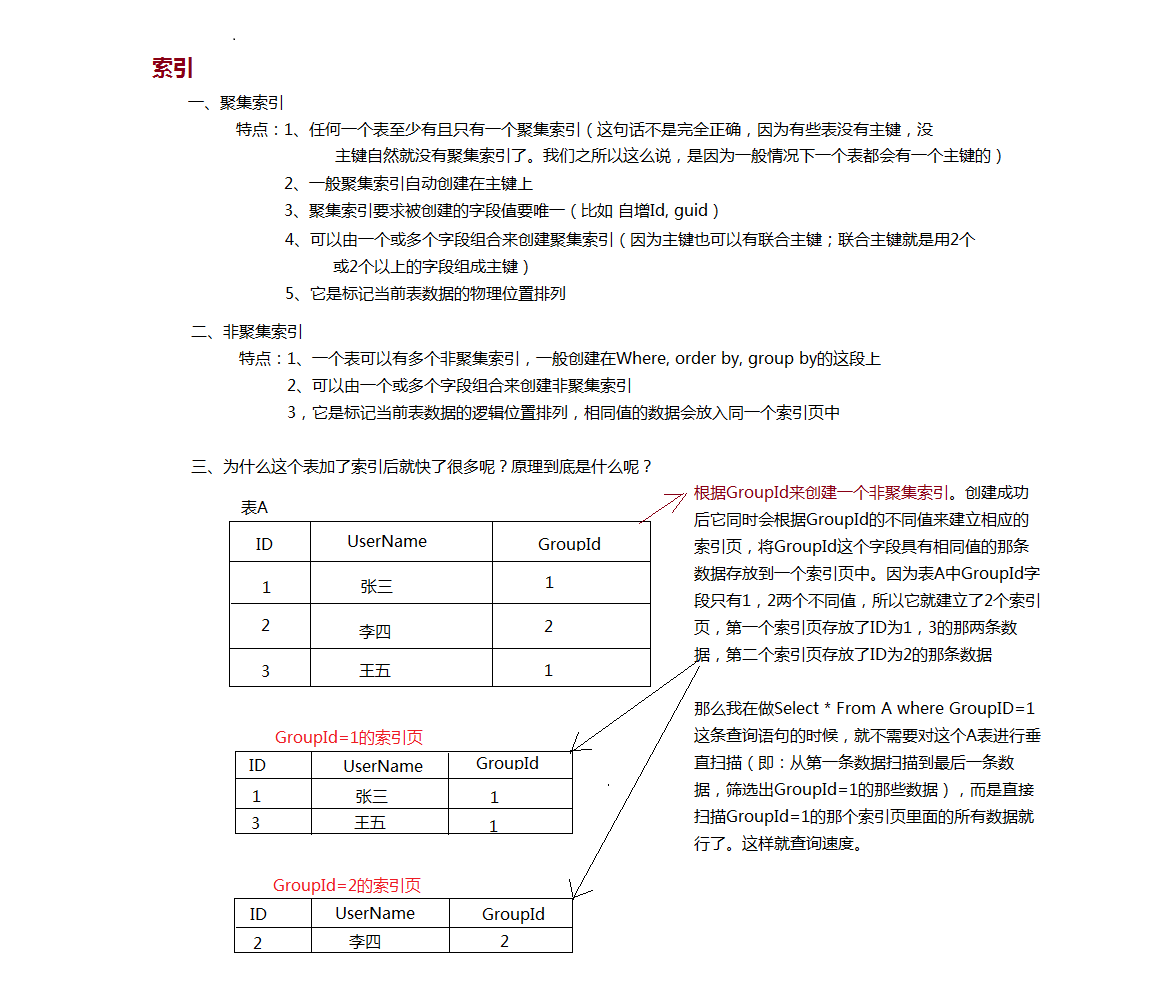


- --unique唯一索引,clustered聚集索引,nonclustered非聚集索引 。主键是唯一的,所以创建了一个主键的同时,也就这个字段创建了一个唯一的索引。SQL SERVER将主键默认定义为聚集索引,事实上,索引是否唯一与是否聚集是不相关的,聚集索引可以是唯一索引,也可以是非唯一索引; 唯一索引实际上就是要求指定的列中所有的数据必须不同
-
- /*
- 主键一唯一索引的区别:
- 1 一个表的主键只能有一个,而唯一索引可以建多个。
- 2 主键可以作为其它表的外键。
- 3 主键不可为null,唯一索引可以为null。
- 聚集索引:将表内的数据按照一定的规则进行排列的目录。正因为如此,一个表中的聚焦索引只有一个。对此我们要注意“主键就是聚焦索引”这是极端错误的,是对聚焦索引的一种浪费。(虽然SQLServer默认主键就是聚焦索引)使用聚焦索引的最大好处就是按照查询要求,迅速缩小查询范围,避免进行全表扫描。其次让每个数目都不相同的字段作为聚焦索引也不符合“大数目不同情况下不应建立聚集索引的原则”。
- */
-
- use sales
- if(exists (select * from sys.indexes where name='IX_TEST_TName'))
-
- drop index T_TESX.TX_TEST_TName --如果IX_TEST_TName存在则删除该索引(注意删除索引的时候是 表名.索引名)
- create nonclustered index IX_TEST_TName --创建一个非聚集索引索引
- on T_Test(name) --为T_Test表的name字段创建索引
- with fillfachor=30 --填充因子为30% 。可以省略with fillfachor=30这一句,省略即默认
- go

创建唯一索引
- CREATE UNIQUE INDEX IX_ApiClients_ClientId --针对ApiClients表的ClientId列做唯一索引
- ON ApiClients (ClientId)
创建唯一索引和非唯一索引案例(非聚集)
- /*
- 判断Users表是否存在,如果不存在则创建表,然后插入列说明,如果存在则插入列说明
- */
- IF NOT EXISTS(SELECT TOP 1 * FROM sysObjects WHERE Id=object_id(N'Users') and xtype='U')
- BEGIN
- CREATE TABLE [dbo].[Users](
- [ID] INT NOT NULL,
- [UserName] [datetime] NOT NULL,
- [Email] [varchar](50) NOT NULL,
- )
- CREATE UNIQUE INDEX [ix_Users_UserName] ON Users --在UserName列上创建唯一索引,非聚集
- (
- [UserName]
- )
- CREATE NONCLUSTERED INDEX ix_Users_Email ON Users --在Email列上创建不唯一索引,非聚集
- (
- [Email]
- )
- EXEC sys.sp_addextendedproperty @name=N'MS_Description', @value=N'主键ID' , @level0type=N'SCHEMA',@level0name=N'dbo', @level1type=N'TABLE',@level1name=N'Users', @level2type=N'COLUMN',@level2name=N'ID'
- EXEC sys.sp_addextendedproperty @name=N'MS_Description', @value=N'用户名' , @level0type=N'SCHEMA',@level0name=N'dbo', @level1type=N'TABLE',@level1name=N'Users', @level2type=N'COLUMN',@level2name=N'UserName'
- EXEC sys.sp_addextendedproperty @name=N'MS_Description', @value=N'邮箱' , @level0type=N'SCHEMA',@level0name=N'dbo', @level1type=N'TABLE',@level1name=N'Users', @level2type=N'COLUMN',@level2name=N'Email'
- END
-
- ELSE
-
- BEGIN
- EXEC sys.sp_addextendedproperty @name=N'MS_Description', @value=N'主键ID' , @level0type=N'SCHEMA',@level0name=N'dbo', @level1type=N'TABLE',@level1name=N'Users', @level2type=N'COLUMN',@level2name=N'ID'
- EXEC sys.sp_addextendedproperty @name=N'MS_Description', @value=N'用户名' , @level0type=N'SCHEMA',@level0name=N'dbo', @level1type=N'TABLE',@level1name=N'Users', @level2type=N'COLUMN',@level2name=N'UserName'
- EXEC sys.sp_addextendedproperty @name=N'MS_Description', @value=N'邮箱' , @level0type=N'SCHEMA',@level0name=N'dbo', @level1type=N'TABLE',@level1name=N'Users', @level2type=N'COLUMN',@level2name=N'Email'
- END
- 唯一索引与主键索引的比较
-
-
- 唯一索引
- 唯一索引不允许两行具有相同的索引值。
- 如果现有数据中存在重复的键值,则大多数数据库都不允许将新创建的唯一索引与表一起保存。当新数据将使表中的键值重复时,数据库也拒绝接受此数据。例如,如果在 employee 表中的职员姓氏(lname) 列上创建了唯一索引,则所有职员不能同姓。
-
- 主键索引
- 主键索引是唯一索引的特殊类型。
- 数据库表通常有一列或列组合,其值用来唯一标识表中的每一行。该列称为表的主键。
- 在数据库关系图中为表定义一个主键将自动创建主键索引,主键索引是唯一索引的特殊类型。主键索引要求主键中的每个值是唯一的。当在查询中使用主键索引时,它还允许快速访问数据。
-
- 它们的一些比较:
- (1)对于主健/unique constraint , oracle/sql server/mysql等都会自动建立唯一索引;
- (2)主键不一定只包含一个字段,所以如果你在主键的其中一个字段建唯一索引还是必要的;
- (3)主健可作外健,唯一索引不可;
- (4)主健不可为空,唯一索引可;
- (5)主健也可是多个字段的组合;
- (6)主键与唯一索引不同的是:
- a.有not null属性;
- b.每个表只能有一个。
-
-
-
- 1、主键
-
- 主键ID,主键既是约束也是索引,同时也用于对象缓存的键值。
-
- 2、索引
-
- *组合或者引用关系的子表(数据量较大的时候),需要在关联主表的列上建立非聚集索引(如订单明细表中的产品ID字段、订单明细表中关联的订单ID字段)
-
- *索引键的大小不能超过900个字节,当列表的大小超过900个字节或者若干列的和超过900个字节时,数据库将报错。
-
- *表中如果建有大量索引将会影响INSERT、UPDATE和DELETE语句的性能,因为在表中的数据更改时,所有的索引都将必须进行适当的调整。需要避免对经常更新的表进行过多的索引,并且索引应保持较窄,就是说:列要尽可能的少。
-
- *为经常用于查询的谓词创建索引,如用于下拉参照快速查找的code、name等。在平台现有下拉参照的查询sql语句中的like条件语句要改成不带前置通配符。还有需要关注Order By和Group By谓词的索引设计,Order By和Group By的谓词是需要排序的,某些情况下为Order By和Group By的谓词建立索引,会避免查询时的排序动作。
-
- *对于内容基本重复的列,比如只有1和0,禁止建立索引,因为该索引选择性极差,在特定的情况下会误导优化器做出错误的选择,导致查询速度极大下降。
-
-
-
- *当一个索引有多个列构成时,应注意将选择性强的列放在前面。仅仅前后次序的不同,性能上就可能出现数量级的差异。
-
- *对小表进行索引可能不能产生优化效果,因为查询优化器在遍历用于搜索数据的索引时,花费的时间可能比执行简单的表扫描还长,设计索引时需要考虑表的大小。记录数不大于100的表不要建立索引。频繁操作的小数量表不建议建立索引(记录数不大于5000条)
一下关于SQL语句的优化
1). 应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描,如:
select id from t where num is null NULL对于大多数数据库都需要特殊处理,MySQL也不例外,它需要更多的代码,更多的检查和特殊的索引逻辑,有些开发人员完全没有意识到,创建表时NULL是默认值,但大多数时候应该使用NOT NULL,或者使用一个特殊的值,如0,-1作为默 认值。
不能用null作索引,任何包含null值的列都将不会被包含在索引中。即使索引有多列这样的情况下,只要这些列中有一列含有null,该列 就会从索引中排除。也就是说如果某列存在空值,即使对该列建索引也不会提高性能。 任何在where子句中使用is null或is not null的语句优化器是不允许使用索引的。
此例可以在num上设置默认值0,确保表中num列没有null值,然后这样查询:
select id from t where num=0 2). 应尽量避免在 where 子句中使用!=或<>操作符
否则将引擎放弃使用索引而进行全表扫描。
MySQL只有对以下操作符才使用索引:<,<=,=,>,>=,BETWEEN,IN,以及某些时候的LIKE。
可以在LIKE操作中使用索引的情形是指另一个操作数不是以通配符(%或者_)开头的情形。例如:
- SELECT id FROM t WHERE col LIKE 'Mich%'; -- 这个查询将使用索引,
- SELECT id FROM t WHERE col LIKE '%ike'; --这个查询不会使用索引。
3). 应尽量避免在 where 子句中使用 or 来连接条件, 否则将导致引擎放弃使用索引而进行全表扫描,如:
select id from t where num=10 or num=20可以 使用UNION合并查询:
select id from t where num=10 union all select id from t where num=20 4). 如果在 where 子句中使用参数,也会导致全表扫描。
因为SQL只有在运行时才会解析局部变量,但优化程序不能将访问计划的选择推 迟到运行时;它必须在编译时进行选择。然而,如果在编译时建立访问计划,变量的值还是未知的,因而无法作为索引选择的输入项。如下面语句将进行全表扫描:
select id from t where num=@num可以改为强制查询使用索引:
select id from t with(index(索引名)) where num=@num5). 应尽量避免在 where 子句中对字段进行表达式操作,这将导致引擎放弃使用索引而进行全表扫描。如:
select id from t where num/2=100应改为:
select id from t where num=100*26). 应尽量避免在where子句中对字段进行函数操作,这将导致引擎放弃使用索引而进行全表扫描。如:
- select id from t where substring(name,1,3)='abc' --name
-
- select id from t where datediff(day,createdate,'2005-11-30')=0 --‘2005-11-30’
生成的id 应改为:
- select id from t where name like 'abc%'
-
- select id from t where createdate>='2005-11-30' and createdate<'2005-12-1'
7). 索引并不是越多越好。
索引固然可以提高相应的 select 的效率,但同时也降低了 insert 及 update 的效率,因为 insert 或 update 时有可能会重建索引,所以怎样建索引需要慎重考虑,视具体情况而定。一个表的索引数最好不要超过6个,若太多则应考虑一些不常使用到的列上建的索引是否有必要。(一个表最多可以建249个索引)
8).用Where子句替换HAVING子句 。
避免使用HAVING子句, HAVING 只会在检索出所有记录之后才对结果集进行过滤. 这个处理需要排序,总计等操作. 如果能通过WHERE子句限制记录的数目,那就能减少这方面的开销. (非oracle中)on、where、having这三个都可以加条件的子句中,on是最先执行,where次之,having最后,因为on是先把不符合条件的记录过滤后才进行统计,它就可以减少中间运算要处理的数据,按理说应该速度是最快的,where也应该比having快点的,因为它过滤数据后才进行sum,在两个表联接时才用on的,所以在一个表的时候,就剩下where跟having比较了。在这单表查询统计的情况下,如果要过滤的条件没有涉及到要计算字段,那它们的结果是一样的,只是where可以使用rushmore技术,而having就不能,在速度上后者要慢如果要涉及到计算的字段,就表示在没计算之前,这个字段的值是不确定的,根据上篇写的工作流程,where的作用时间是在计算之前就完成的,而having就是在计算后才起作用的,所以在这种情况下,两者的结果会不同。在多表联接查询时,on比where更早起作用。系统首先根据各个表之间的联接条件,把多个表合成一个临时表后,再由where进行过滤,然后再计算,计算完后再由having进行过滤。由此可见,要想过滤条件起到正确的作用,首先要明白这个条件应该在什么时候起作用,然后再决定放在那里
创建索引案例:
1、创建非聚集索引(针对User表的Name字段创建名字为Index_User_Name的非聚集索引)
CREATE NONCLUSTERED INDEX Index_User_Name ON User (Name) 2、创建唯一索引(针对User表的Name字段创建名字为Index_User_Name的唯一索引)
CREATE UNIQUE INDEX Index_User_Name ON User (Name) 3、创建唯一索引(针对User表,在DeleteTime字段为空的数据中,为Name字段添加唯一索引)
CREATE UNIQUE INDEX Index_User_Name ON User (Name) WHERE DeleteTime is null举例:User表中有两列两行
Name DeleteTime
张三 2022-02-10
李四 NULL
此时想插入Name为李四的数据,无法插入,但是可以插入Name为张三的数据,因为张三这一行的DeleteTime列数据不为Null
4、创建唯一索引(针对User表,在DeleteTime字段为空的数据中,为Name+Email字段添加唯一索引)
CREATE UNIQUE INDEX Index_User_Name ON User (Name,Email) 举例:User表中有两列两行
Name Email DeleteTime
张三 abc@qq.com NULL
此时想插入一条Name为 张三,Email为 abc@qq.com的数据是不行的 ,但是可以插入一条Name为张三,Email为除abc@qq.com以外的任意值的数据
或者可以插入一条Email为abc@qq.com,Name为除张三以外的任意值的数据
其实就是将Name和Email看成一个字段,两个字段共同组成一个唯一
5、创建唯一索引(针对User表,在DeleteTime字段为空的数据中,为Name+Email字段添加唯一索引,同时排除为DeleteTime不为空的数据添加唯一索引,意思就是只为DeleteTime为空的数据添加唯一索引)
CREATE UNIQUE INDEX Index_User_Name ON User (Name,Email) WHERE DeleteTime is null
