
- 1【配置环境】VS Code中C#环境搭建_vscode c#
- 2“AI+视频”新模式下城市安全的探索与落实
- 3单点登录实现的几种方式及原理【单点登录】_单点登录实现方案
- 4顺序表的实现(迈入数据结构的大门)(2)
- 5无源蜂鸣器 verilog FPGA 基础练习9_如何让fpga的verilog试验箱蜂鸣器发出不同音调
- 6MySQL中information_schema详解_information schema表
- 7sqlcoder_defog sqlcoder
- 8软考(软件设计师)考点总结 -- 数据结构与算法基础,2024年最新高级java软件工程师面试题库
- 9FAST-LIO2代码解析_fast lio2 lasermapping
- 102024上半年软考中级《系统集成项目管理工程师》报名考试全攻略_系统集成项目管理中项考试时间2024
基于llvm自制编译器(4)——代码优化器、JIT编译器_llvm jit
赞
踩
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
概述
前面几章我们介绍了如何实现一门简单的编程语言,同时支持了LLVM IR代码生成。本文,我们将介绍并实现两类技术:
- 代码优化器
- JIT编译器
1. 常量优化合并
在第3章中,我们实现了LLVM IR代码生成的能力。不过,生成的代码仍然具有很大的优化空间。当然,我们所使用的的IRBuilder对代码也进行了一定程度的优化,如下所示。
ready> def test(x) 1+2+x;
Read function definition:
define double @test(double %x) {
entry:
%addtmp = fadd double %x, 3.000000e+00
ret double %addtmp
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
其中,IRBuilder对代码进行了常量合并优化。如果根据输入内容进行AST构建,基于字面含义生成的代码将如下所示。
ready> def test(x) 1+2+x;
Read function definition:
define double @test(double %x) {
entry:
%addtmp = fadd double 2.000000e+00, 1.000000e+00
%addtmp1 = fadd double %addtmp, %x
ret double %addtmp1
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
常量合并化(Contants Folding)是一种非常常见且重要的优化方法,几乎所有编程语言都在其AST中实现了常量合并化。
在使用LLVM时,我们无须显示地开启常量合并优化功能,因为LLVM IR构造器内部会自动检测并执行常量化合并。
事实上,我们通常建议使用IRBuilder来生成代码。IRBuilder在构建过程中没有语法开销(Syntactic Overhead),即无需显式指定编译器进行常量化检查。此外,还能够显著减少某些情况下的LLVM IR代码量。
当然,IRBuilder也有一定的限制,其在生成代码时将所有分析的代码进行内联,从而会导致无法探测到某些优化点。比如:
ready> def test(x) (1+2+x)*(x+(1+2))
ready>Read function definition:
define double @test(double %x){
entry:
%addtmp = fadd double 3.0000, %x
%addtmp1 = fadd double %x, 30000
%multmp = fmul double %addtmp, %addtmp1
ret double %multmp
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
在上述这种情况下,乘法操作LHS和RHS是相同的值。我们期望生成的代码时tmp = x+3; res = tmp*tmp,而不是计算两次x+3.
遗憾的是,本地分析很难探测并纠正类似的优化点。这里,我们需要两种优化方式才能消除例子中冗余的fadd指令,分别是:
- 表达式重连(Reassociation Of Expression)
- 公共子表达式消除(Common Subexpression Elimination)
对此,LLVM以**通道(Pass)**的形式提供了各种类型的优化,其中就包含了上述两种优化方式。
2. 代码优化器
LLVM为各种类型的优化提供了对应的优化通道(下文中简称Pass)。与其他系统不同,LLVM并没有错误滴认为某一组优化适用于所有编程语言和所有情况。相反,LLVM允许编译器开发者自定义选择哪些优化、以哪种顺序优化、在哪种情况下优化。
比如,LLVM提供了whole module Pass,其能够尽可能多地查看代码体(通常是整个文件,如果在链接时执行,那么它可能是整个程序的很大一部分)。LLVM还支持per-functionPass,其一次只对一个函数或者方法进行操作,而不查看其他函数。关于Pass的更多细节,可以查看官方文档——How to Write a Pass、LLVM’s Analysis and Transform Passes。
现阶段,当用户输入代码时,我们会实时生成LLVM IR。在实时解析过程中,我们会在用户输入代码时运行per-functionPass进行优化。如果我们想实现一个“静态编译器”,我们可以完全使用现有的代码,不同的是,我们只会在整个文件被解析完成后,才运行优化器。
为了执行per-functionPass,我们需要设置一个FunctionPassManager来管理我们希望运行的LLVM优化通道。当FunctionPassManager设置完成后,我们可以向其注册一组优化通道来执行。对于每一个Module,需要创建一个对应的FunctionPassManager,因此我们可以实现一个函数来完成创建并初始化模块和通道管理器,如下所示。
void InitializeModuleAndPassManager(void) { // Open a new module. TheModule = std::make_unique<Module>("my cool jit", TheContext); // Create a new pass manager attached to it. TheFPM = std::make_unique<legacy::FunctionPassManager>(TheModule.get()); // Do simple "peephole" optimizations and bit-twiddling optzns. TheFPM->add(createInstructionCombiningPass()); // Reassociate expressions. TheFPM->add(createReassociatePass()); // Eliminate Common SubExpressions. TheFPM->add(createGVNPass()); // Simplify the control flow graph (deleting unreachable blocks, etc). TheFPM->add(createCFGSimplificationPass()); TheFPM->doInitialization(); }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
上述代码中,首先初始化了全局模块TheModule和通道管理器TheFPM,后者被附加到了TheModule中。当通道管理器初始化完毕,我们通过调用add方法来添加一系列LLVM优化通道。
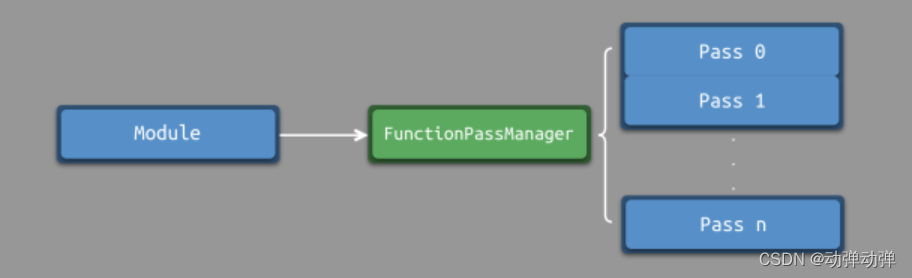
这里,我们添加了4种优化通道,包括:窥孔优化、表达式重联、公共子表达式消除、控制流图简化等。这是一组非常标准的代码清理优化,可用于各种代码。
当通道管理器初始化完毕后,我们会在FunctionAST::codegen()方法的末尾来调用并执行通道管理器,最终将优化结果返回,如下所示。
if (Value *RetVal = Body->codegen()) {
// Finish off the function.
Builder.CreateRet(RetVal);
// Validate the generated code, checking for consistency.
verifyFunction(*TheFunction);
// Optimize the function.
TheFPM->run(*TheFunction);
return TheFunction;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
从代码中可以看出,通道管理器的执行非常简单。FunctionPassageMange直接对LLVM Function* 进行优化和更新。我们可以对它进行简单的测试,如下所示。
ready> def test(x) (1+2+x)*(x+(1+2));
ready> Read function definition:
define double @test(double %x) {
entry:
%addtmp = fadd double %x, 3.000000e+00
%multmp = fmul double %addtmp, %addtmp
ret double %multmp
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
相比之前,生成的LLVM IR代码得到了预期的优化,去掉了冗余的fadd指令。
LLVM为不同的场景提供了各种类型的优化。官方文档 LLVM’s Analysis and Transform Passes列出了一部分优化相关的通道,但不是非常完整。此外,我们也可以查看Clang启动时所执行的通道,还可以通过opt工具来试验通道。
3. JIT编译器
LLVM提供了非常多的工具,一直吃操作LLVM IR。例如:我们可以对LLVM IR执行各种类型的优化(如上文所示),可以将LLVM IR转换成文本 形式或二进制形式,可以将LLVM IR编译成特定架构的汇编代码,可以对LLVM IR进行即时编译(JIT,just in time)。LLVM IR的核心作用是作为编译器不同部分之间的通用传递形式。
在这一节中,我们将为Kaleidoscope实现JIT编译器。JIT的基本思想是:当用户输入代码时,及时分析并评估其顶层表达式。比如:当用户输入1+2;时,我们将输出3。
对此,我们首先准备相关环境,包括:
- 初始化本机目标(Native Target):通过调用
InitializeNativeTarget相关方法实现。 - 初始化JIT:通过设置
KaleidoscopeJIT类型的TheJIT全局变量实现。
static std::unique_ptr<KaleidoscopeJIT> TheJIT; ... int main(){ InitializeNativeTarget(); InitializeNativeTargetAsmPrinter(); InitializeNativeTargetAsmParser(); //Install standard binary operators. //1 is lowest precedence. BinopPrecedence['='] = 2; BinopPrecedence['<'] = 10; BinopPrecedence['+'] = 20; BinopPrecedence['-'] = 20; BinopPrecedence['*'] = 40; //highest. //Prime the first token. fprintf(stderr, "ready> "); getNextToken(); TheJIT = exitOnErr(KaleidoscopeJIT::Create()); InitializeModuleAndPassManager(); //Run the main "interpreter loop" now. MainLoop(); return 0; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
此外,我们还需要为JIT设置数据内存布局,如下所示:
void InitializeModuleAndPassManager(void){
//open a new module.
TheContest = std::make_unique<LLVMContext>();
TheModule = std::make_unique<Module>("my cool jit", *TheContext);
TheModule->setDataLayout(TheJIT->getDataLayout());
//Create a new pass manager attached to it.
TheFPM = std::make_unique<legacy::FunctionPassManager>(TheModule.get());
...
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
KaleidoscopeJIT类表示针对Kaleidoscope语言的JIT。在后续的文章中,我们将介绍它是如何工作的,并使用新功能对其进行扩展。它的API非常简单,包括:
addModule:用于向JIT注册LLVM IR module,使其函数可用于执行。lookup:允许我们查找指向已编译代码的指针。
我们在顶层表达式解析函数中调用KaleidoscopeJIT的API,如下所示:
static void HandleTopLevelExpression() { // Evaluate a top-level expression into an anonymous function. if (auto FnAST = ParseTopLevelExpr()) { if (FnAST->codegen()) { // Create a ResourceTracker to track JIT'd memory allocated to our // anonymous expression -- that way we can free it after executing. auto RT = TheJIT->getMainJITDylib().createResourceTracker(); auto TSM = ThreadSafeModule(std::move(TheModule), std::move(TheContext)); ExitOnErr(TheJIT->addModule(std::move(TSM), RT)); InitializeModuleAndPassManager(); // Search the JIT for the __anon_expr symbol. auto ExprSymbol = ExitOnErr(TheJIT->lookup("__anon_expr")); // Get the symbol's address and cast it to the right type (takes no // arguments, returns a double) so we can call it as a native function. double (*FP)() = (double (*)())(intptr_t)ExprSymbol.getAddress(); fprintf(stderr, "Evaluated to %f\n", FP()); // Delete the anonymous expression module from the JIT. ExitOnErr(RT->remove()); } } else { // Skip token for error recovery. getNextToken(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
在上述代码中,如果解析成功且代码生成,那么会将包含顶层表达式的module注册至JIT中。我们通过调用addModule方法实现,该方法会为module中的所有函数生成代码,并将module与一个资源追踪器进行绑定,以用于后续从JIT中移除module。当module注册完成后,将无法对其进行修改,因此我们需要创建一个新的module用于持有后续的代码,通过调用InitializeModuleAndPassManager()方法实现。
当module注册完毕后,我们需要获取一个指向最终生成代码的指针。为此,我们调用JIT的lookup方法,并传递顶层表达式函数的名称:__anon_expr。
接下来,我们通过该符号调用getAddress()来获取__anon_expr函数的内存地址。回想一下,我们将顶层表达式编译成一个自包含的LLVM函数,该函数不接收任何参数并返回计算的双精度值。由于LLVM JIT编译器与本机平台ABI匹配,因此我们可以将结果指针转换为该类型的函数指针并直接调用它。这意味着,JIT编译代码和静态链接到应用程序的本机机器码之间没有区别。
最后,由于我们不支持重新评估顶层表达式,所以当我们完成释放相关内存时,我们会从JIT中 删除module。然而,我们之前创建的module(通过InitializeModuleAndPassManager)仍然打开并等待添加新代码。
如下所示,我们对JIT的测试代码。顶层表达式使用无参函数进行表示,返回了一个double类型的值。
ready> 4+5;
Evaluated to 9.000000
- 1
- 2
下面,我们再来测试JIT下的函数的定义与调用,如下所示:
ready> def testfunc(x y) x + y*2;
Read function definition:
define double @testfunc(double %x, double %y) {
entry:
%multmp = fmul double %y, 2.000000e+00
%addtmp = fadd double %x, %multmp
ret double %addtmp
}
ready> testfunc(4, 10);
Evaluated to 24.000000
ready> testfunc(5, 10);
ready> Error: Unknown function referenced
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
上述代码中,在第二次调用testfunc函数时,LLVM提示找不到testfunc函数,这是怎么回事?从前面介绍JIT的API中我们可以知道,module是JIT的分配单元,testfunc的定义与testfunc的调用(匿名表达式)处于同一个module中,当我们从JIT中删除module以释放匿名表达式时的内存时,module中testfunc的定义也被删除了。因此,当我们再次尝试调用testfunc时,JIT提示找不到该函数。
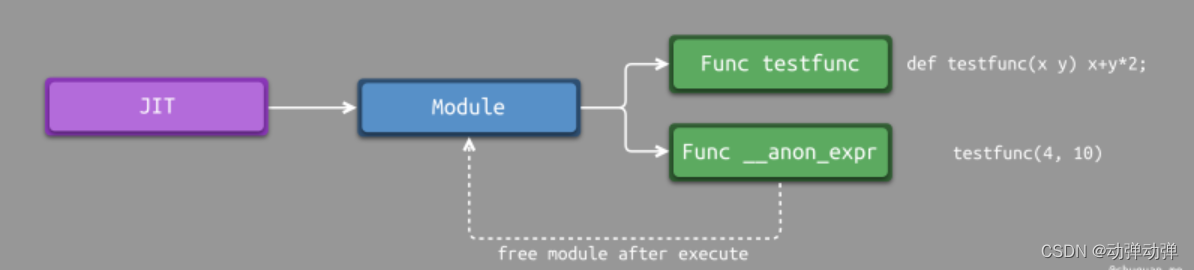
一种简单的解决方法是:将匿名表达式与函数定义放在不同的module中。每个函数原型都会提前注册至JIT中,当执行函数调用时,JIT会进行跨module查找。通过将匿名表达式放在不同的module中,我们可以在不影响其他功能的情况下将其释放。如下所示,为该解决方法的示意图。
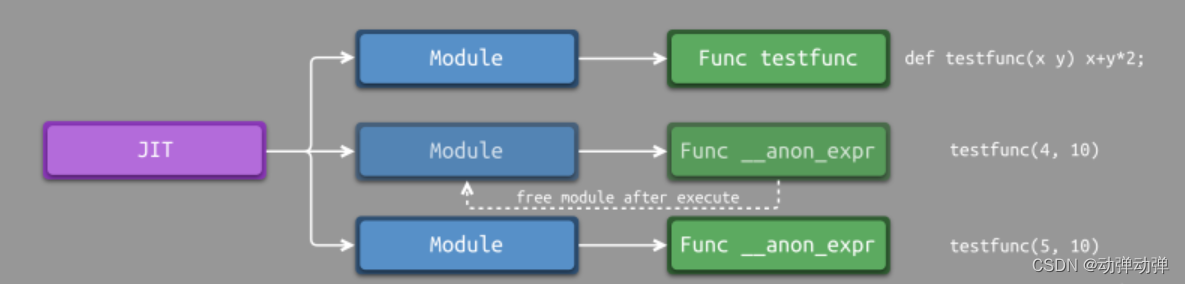
事实上,可以进一步进行优化,将每个函数定义存储在对应的module中。这样的话,我们可以实现更加真是的PEPL环境:同名函数可以多次添加至JIT中。当通过KaleidoscopeJIT查找符号时,它将返回最新的函数定义,最终达到如下所示的效果。
ready> def foo(x) x + 1; Read function definition: define double @foo(double %x) { entry: %addtmp = fadd double %x, 1.000000e+00 ret double %addtmp } ready> foo(2); Evaluated to 3.000000 ready> def foo(x) x + 2; define double @foo(double %x) { entry: %addtmp = fadd double %x, 2.000000e+00 ret double %addtmp } ready> foo(2); Evaluated to 4.000000
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
为了让每个函数定义能够存储在其对应的module中,我们需要一种方法来重新生成函数声明,并将它们存储至新的module中。具体实现,如下所示:
static std::unique_ptr<KaleidoscopeJIT> TheJIT; ... Function *getFunction(std::string Name) { // First, see if the function has already been added to the current module. if (auto *F = TheModule->getFunction(Name)) return F; // If not, check whether we can codegen the declaration from some existing // prototype. auto FI = FunctionProtos.find(Name); if (FI != FunctionProtos.end()) return FI->second->codegen(); // If no existing prototype exists, return null. return nullptr; } ... Value *CallExprAST::codegen() { // Look up the name in the global module table. Function *CalleeF = getFunction(Callee); ... Function *FunctionAST::codegen() { // Transfer ownership of the prototype to the FunctionProtos map, but keep a // reference to it for use below. auto &P = *Proto; FunctionProtos[Proto->getName()] = std::move(Proto); Function *TheFunction = getFunction(P.getName()); if (!TheFunction) return nullptr;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
如下所示,为调整后的设计原理示意图。由于每个函数定义都对应一个模块,而TheModule仅仅指向当前模块。因此,无法通过TheModule查找其他模块中是否存在特定的函数定义。为了解决这个问题,引入了FunctionProtos来存储所有模块定义的函数原型,方便进行查找。
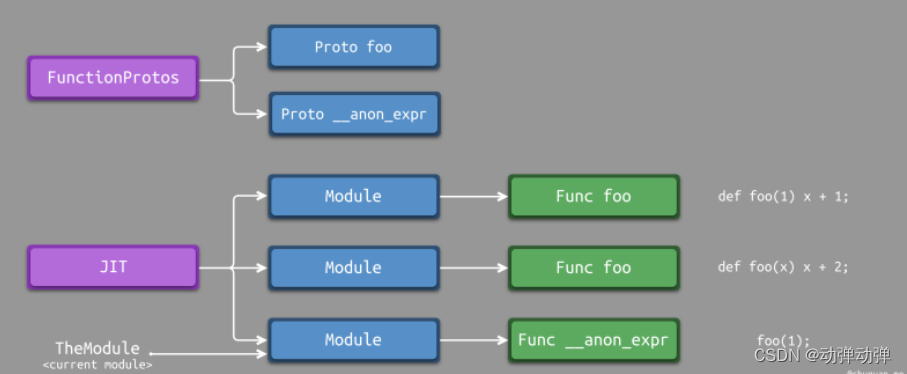
我们首先设置一个全局FunctionProtos,用于存储每个函数的原型,支持覆盖。此外,我们还定义一个便利方法getFunction()用于替换TheModule->getFunction() getFunction()的核心逻辑如下所示。
- 首先,在
TheModule中查找函数声明。 - 如果存在,则返回。
- 如果不存在,则在
FunctionProtos中继续查找函数声明。
在CallExprAST::codegen()中,我们只需要将TheModule->getFunction()替换成getFunction()即可。
在FunctionAST::codegen(),我们首先更新FunctionProtos,然后调用getFunction()即可。
之后,我们就可以在当前module中查找并调用之前声明的函数。
为此,我们还需要做如下改造。
static void HandleDefinition() { if (auto FnAST = ParseDefinition()) { if (auto *FnIR = FnAST->codegen()) { fprintf(stderr, "Read function definition:"); FnIR->print(errs()); fprintf(stderr, "\n"); ExitOnErr(TheJIT->addModule(ThreadSafeModule(std::move(TheModule), std::move(TheContext)))); InitializeModuleAndPassManager(); } } else { // Skip token for error recovery. getNextToken(); } } static void HandleExtern() { if (auto ProtoAST = ParseExtern()) { if (auto *FnIR = ProtoAST->codegen()) { fprintf(stderr, "Read extern: "); FnIR->print(errs()); fprintf(stderr, "\n"); FunctionProtos[ProtoAST->getName()] = std::move(ProtoAST); } } else { // Skip token for error recovery. getNextToken(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
在HandleDefinition函数中,我们新增了两行代码:将定义的函数注册至JIT中并初始化一个新的模块与通道管理器。
在HandleExtern函数中,我们新增了一行代码:将函数原型添加至FunctionProtos中。
完成上述修改后,我们再来测试一下,如下所示。此时,函数重复定以后,能够自动匹配最新定义的函数。注意:由于LLVM9.0及以后版本不支持不同模块定义相同的符号,因此LLVM9.0及以后版本并不支持本文所示的覆盖函数定义的能力。
ready> def foo(x) x + 1;
ready> foo(2);
Evaluated to 3.000000
ready> def foo(x) x + 2;
ready> foo(2);
Evaluated to 4.000000
- 1
- 2
- 3
- 4
- 5
- 6
- 7
最后,我们再来测试一下能否调用外部函数。
ready> extern sin(x); Read extern: declare double @sin(double) ready> extern cos(x); Read extern: declare double @cos(double) ready> sin(1.0); Evaluated to 0.841471 ready> def foo(x) sin(x)*sin(x) + cos(x)*cos(x); Read function definition: define double @foo(double %x) { entry: %calltmp = call double @sin(double %x) %multmp = fmul double %calltmp, %calltmp %calltmp2 = call double @cos(double %x) %multmp4 = fmul double %calltmp2, %calltmp2 %addtmp = fadd double %multmp, %multmp4 ret double %addtmp } ready> foo(4.0); Evaluated to 1.000000
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
从上述执行结果来看,JIT 是能够查找到外部函数 sin 和 cos。这是如何做到的?事实上,KaleidoscopeJIT 内部有一个简单的符号解析规则,用于查找所注册 module 中不存在的符号:首先搜索已添加到 JIT 的所有 module,找到函数定义。如果 JIT 中没有找到定义,那么它将到 Kaleidoscope 进程自身上调用 dlsym("sin")。由于 sin 是在 JIT 的地址空间中定义的,它将 module 中对 sin 函数的调用转换成对 libm 版本的 sin 函数的调用。在某些情况下,它会更进一步,因为 sin 和 cos 是标准的数学函数名称,当使用上面的 sin(1.0) 时,常量合并优化器能够直接返回其计算结果。
后续,我们将介绍如何调整 KaleidoscopeJIT 中的这套符号解析规则,从而启用各种功能,从安全性(限制 JIT 代码可用的符号集)到基于符号名称的动态代码生成、以及懒编译(Lazy Compilation)。
4.总结
至此,我们完成了对 Kaleidoscope 的 JIT 和优化器的支持。我们可以实现一门非图灵完备的编程语言,以用户驱动的方式对齐进行优化和 JIT 编译。后续,我们将研究使用控制流结构扩展编程语言,并在此过程中解决一些 LLVM IR 相关的问题。
5.参考
Kaleidoscope: Adding JIT and Optimizer Support
How to Write a Pass
LLVM’s Analysis and Transform Passes

