
- 1VSCode远程连接Gitee_vscode gitee
- 2Flutter多环境部署配置(二)_flutter中测试环境和正式环境
- 3pandas之pd.read_parquet()和pd.to_parquet()介绍
- 4【学习】Android动画解析——类型、使用场景与解析_属性动画使用的地方
- 5PMP项目管理证书是什么?_项目管理证书 csdn
- 6快速使用 vscode 进行 Java 编程_java vscode format
- 7javascript函数作用域_js函数的三种作用域
- 8【转】【MySQL】运行原理(四):重做日志(redo log),回滚日志(undo log),二进制日志(binlog)_数据库回滚和重做例子
- 9c++ stat函数获取文件状态(包括修改时间等)_c++ 获取文件的最后修改时间
- 10【精选实战】改进GFPGAN:模糊人脸修复系统(源码&教程)_gfpgan 修复视频
【文末附gpt升级4.0方案】FastGPT详解_fastgpt 文件处理模型
赞
踩
FastGPT知识库结构讲解
FastGPT是一个基于GPT模型的知识库,它的结构可以分为以下几个部分:
1. 数据收集:FastGPT的知识库是通过从互联网上收集大量的文本数据来构建的。这些数据可以包括维基百科、新闻文章、论坛帖子等各种类型的文本。
2. 数据预处理:在将数据输入到GPT模型之前,需要对数据进行一些预处理操作。这包括分词、去除停用词、标记化等步骤,以便将文本转换为模型可以理解的形式。
3. 模型训练:使用预处理后的数据,将其输入到GPT模型中进行训练。GPT模型是一个基于Transformer架构的神经网络模型,通过多层的自注意力机制来学习文本之间的关系和语义信息。
4. 知识库构建:在模型训练完成后,可以使用该模型生成文本。通过输入一个问题或者关键词,FastGPT可以生成与之相关的文本回答。这些回答可以是从知识库中提取的信息,也可以是模型根据训练数据生成的新内容。
5. 问题回答:当用户提出问题时,FastGPT会根据问题的内容和上下文生成相应的回答。回答的准确性和逻辑性取决于模型的训练和知识库的质量。
FastGPT是如何构建知识库的?
FastGPT是一个基于大规模预训练语言模型的AI助手,它的知识库是通过对大量的文本数据进行预训练得到的。在预训练阶段,FastGPT使用了大规模的无监督学习,通过对互联网上的海量文本进行学习,从中提取出语言的统计规律和语义信息。
具体而言,FastGPT使用了Transformer模型进行预训练。Transformer模型是一种基于自注意力机制的神经网络模型,它能够有效地捕捉文本中的上下文信息和语义关联。通过多层的自注意力和前馈神经网络结构,FastGPT能够对输入的文本进行编码,并生成对应的语义表示。
在预训练过程中,FastGPT使用了大量的无标签文本数据,例如维基百科、新闻文章、论坛帖子等。通过对这些数据进行自监督学习,FastGPT学习到了丰富的语言知识和语义关系。这些知识被编码在FastGPT的参数中,形成了其知识库。
当用户提出问题时,FastGPT会根据其预训练得到的知识库进行推理和回答。它能够理解问题的语义,并根据自身的知识库提供准确的回答。同时,FastGPT还可以根据用户的问题生成相关的问题,以进一步深入探索和交流。
附升级ChatGPT4.0失败的解决方案
ChatGPT 4.0科普

ChatGPT 4.0的一些关键特点和科普内容:
- 多模态:ChatGPT 4.0具备处理不同类型输入和输出的能力。这意味着它不仅可以接收文字信息,还能处理图片、视频等多媒体内容,并根据这些内容进行回答或生成相关内容。
- 推理能力:ChatGPT 4.0具有更强大的推理能力,能够根据上下文和常识进行逻辑推断和判断。它可以回答需要分析、比较、评估或解释的问题,并给出合理且准确的答案。
- 安全性:ChatGPT 4.0通过人类反馈来训练模型,这意味着它会考虑用户对其输出内容的满意度,并根据反馈进行调整或改进。这种机制有助于确保模型的输出更加符合用户的期望和需求。
- 对话能力:ChatGPT 4.0致力于提高对话的自然度和流畅性,使用户能够更加自然地表达自己的想法和感受。同时,它还支持更广泛的语言,使得全球用户都能方便地使用它进行对话。
- 推荐功能:ChatGPT 4.0通过分析用户的对话内容和背景信息,提供智能推荐。这包括推荐符合用户兴趣和需求的商品、服务等,为用户提供个性化的建议。
- 学习和推理效率:ChatGPT 4.0通过高效的学习和推理算法,提高了自己的学习速度和对话质量。这使得用户能够更快速地获得满意的答案。
- 隐私保护:ChatGPT 4.0重视用户的隐私和数据安全,采用先进的加密和安全技术来保护用户的个人信息。
总的来说,ChatGPT 4.0在对话自然度、多模态处理、推理能力、安全性和隐私保护等方面都有着显著的提升,为用户提供了更加智能、便捷和安全的交互体验。随着技术的不断发展,ChatGPT 4.0将在更多领域发挥重要作用,推动人工智能技术的进一步应用和发展。
常见解决方案
如果升级ChatGPT4.0失败,您可以尝试以下解决方案:
- 检查网络连接:确保您的计算机或设备已经连接到互联网,并且网络连接稳定。有时候,网络连接问题可能会阻止软件更新。
- 清除缓存和下载文件夹:有时软件更新会因为缓存文件或下载文件夹中的错误而失败。您可以使用杀毒软件等工具清除缓存和下载文件夹,并重新尝试进行升级。
- 关闭防火墙和杀毒软件:有时候防火墙或杀毒软件会阻止软件更新,导致升级失败。您可以暂时关闭防火墙或杀毒软件,然后尝试进行升级。
- 重置浏览器缓存和Cookie:有些浏览器会在升级过程中使用Cookie或缓存文件来存储升级所需的文件。如果您发现升级失败,可以尝试清除浏览器的缓存和Cookie,并重新启动浏览器进行升级。
- 卸载并重新安装:如果以上方法都无法解决问题,您可以考虑卸载旧版本的ChatGPT,并重新安装最新版本的ChatGPT。在卸载之前,请确保您已经备份了重要的数据。
如果以上方案仍然无法解决问题,建议您联系ChatGPT的客服团队寻求帮助和支持。他们将能够提供更具体的指导和解决方案。
一站式解决方案
在前面的文章我们介绍过了:WildCard | 一分钟注册,轻松订阅海外软件服务
通过链接注册可以减免虚拟卡2美元年费。可以通过该平台来实现升级。发送两个内容。
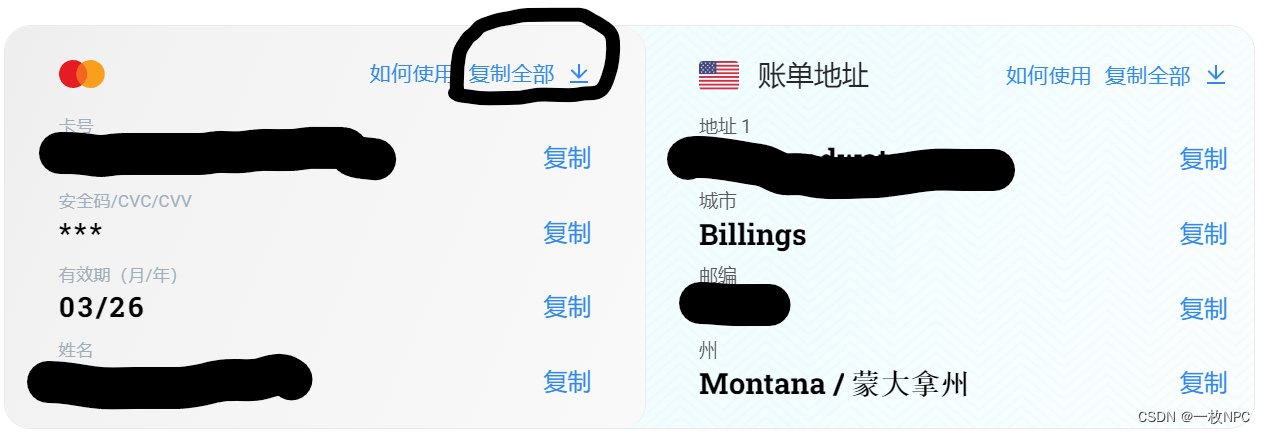
一个是支**付页面的网址,返回上一步,然后重新点击 Upgrade 进入一下 chatgpt 的支**付页面,什么内容都不要填,直接把复制一下 pay.openai.com 开头的那个全部网址,发给他。

另一个是卡片信息,点击卡片右上角的复制全部即可
总费用:虚拟卡年费11.99-2=9.9美元(通过链接注册减免2美元年费)+gpt月费

