
- 1浅析Java虚拟机的垃圾回收机制(GC)_java gc垃圾回收机制
- 2软件行业 职位 英文简称_软测职位职称英文简称
- 3Mac如何安装brew_mac brew安装
- 4java二叉树的深度_Java实现二叉树的深度计算
- 5项目实战:一套基于SpringBoot+Vue+App的智能家居系统(含源码)_spring boot wifi模块 app
- 6【Docker】Docker Network(网络)
- 7win10创建python虚拟环境-virtualenv_virtualenvwrapper-win
- 8hive 、spark 、flink之想一想_hive spark flink
- 9Uniapp和原生aar混合使用初体验_uniapp aar
- 10TCP、UDP客户端
作业(3)——微调_在 oasst1 数据集上微调 internlm-7b-chat
赞
踩
基础作业:
构建数据集,使用 XTuner 微调 InternLM-Chat-7B 模型, 让模型学习到它是你的智能小助手。
效果图,微调前与微调后:
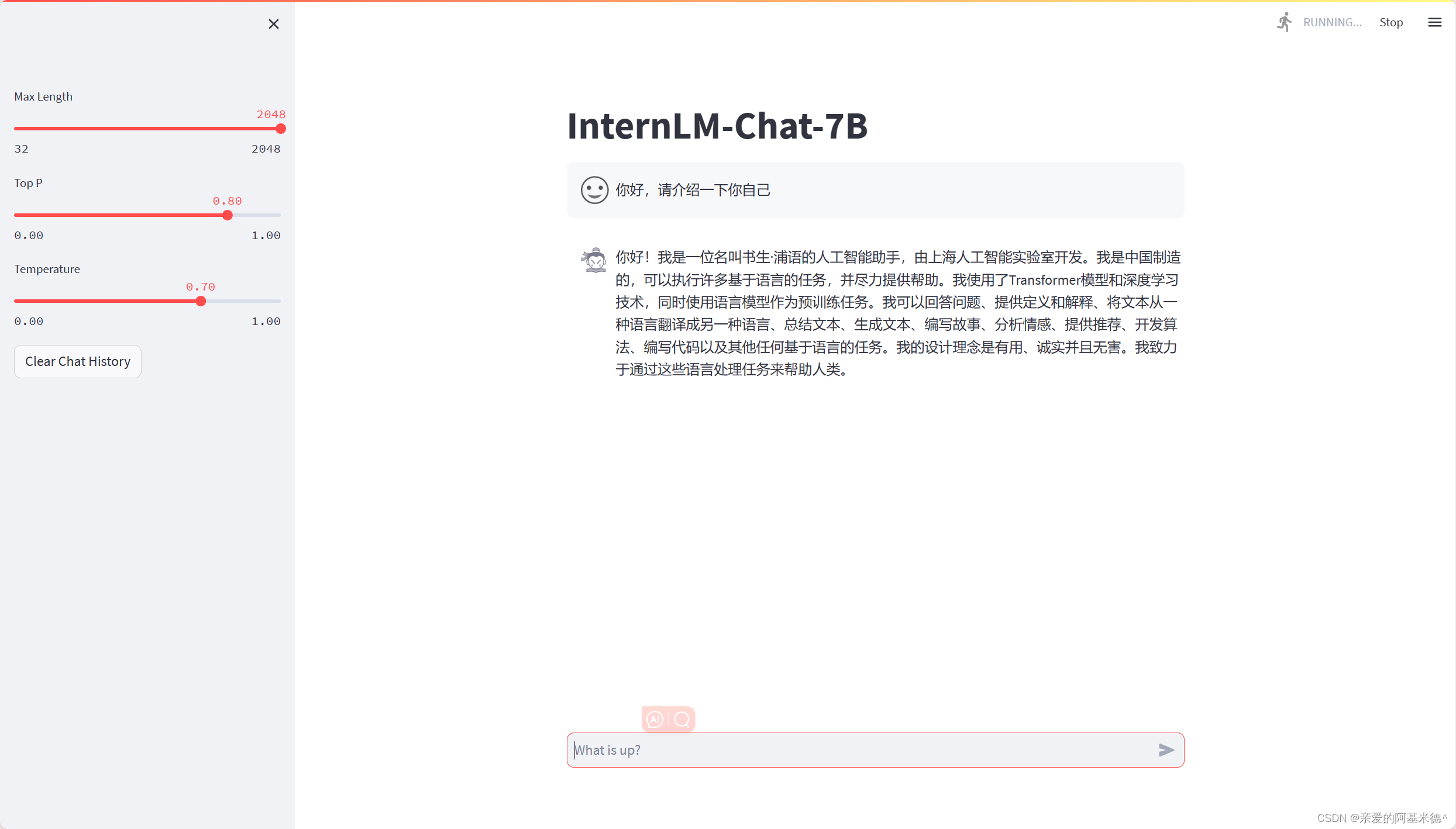
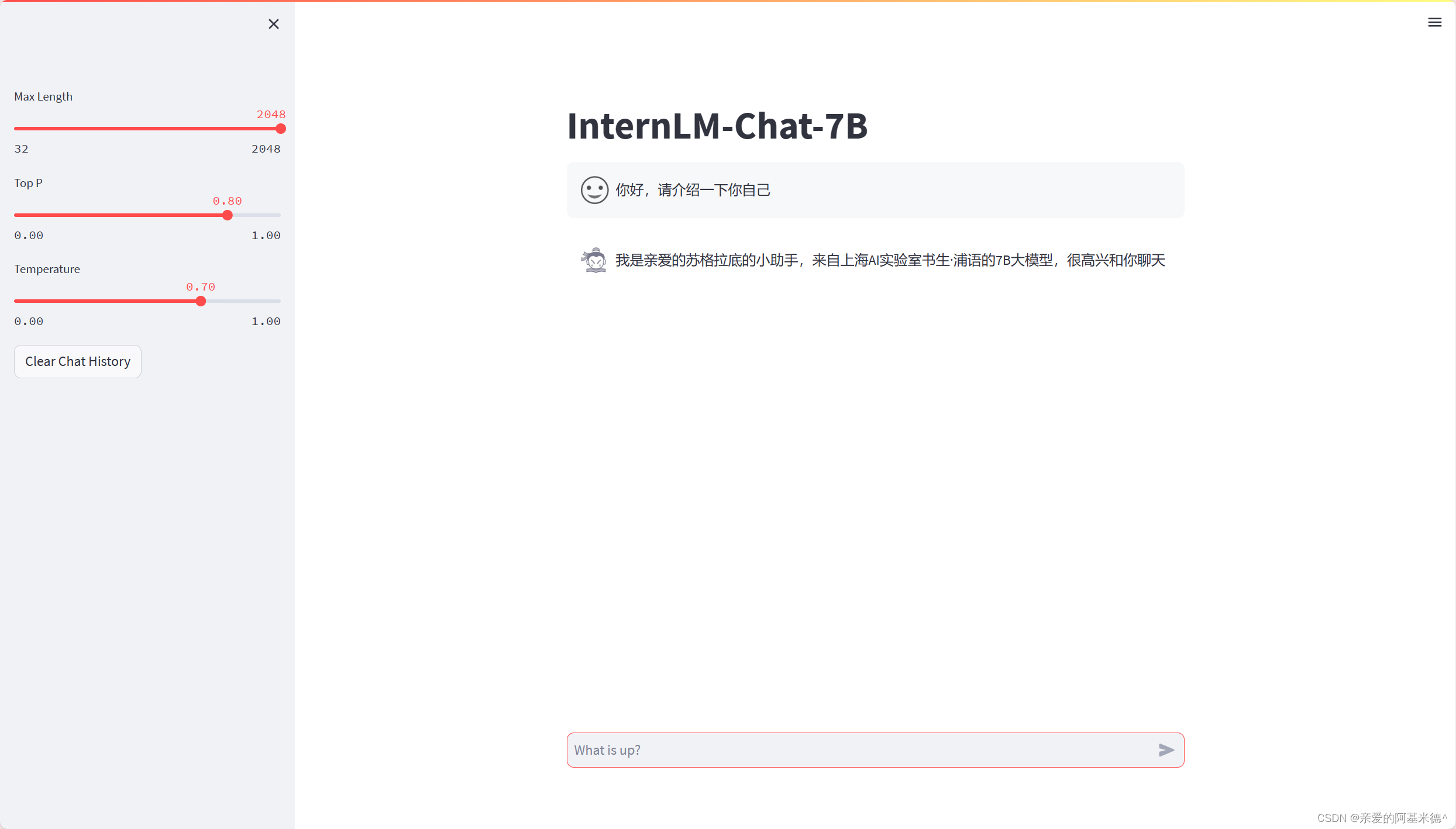
XTuner——一个大语言模型微调工具箱。由 MMRazor 和 MMDeploy 联合开发。
支持的开源LLM (2023.11.01)
- InternLM ✅
- Llama,Llama2
- ChatGLM2,ChatGLM3
- Qwen
- Baichuan,Baichuan2
- Zephyr
- …
平台:Ubuntu + Anaconda + CUDA/CUDNN + 8GB nvidia显卡(实际选用了服务器的A100(1/4))
1 环境配置
# 如果你是在 InternStudio 平台,则从本地 clone 一个已有 pytorch 2.0.1 的环境: /root/share/install_conda_env_internlm_base.sh xtuner0.1.9 # 如果你是在其他平台: conda create --name xtuner0.1.9 python=3.10 -y # 激活环境 conda activate xtuner0.1.9 # 进入家目录 (~的意思是 “当前用户的home路径”) cd ~ # 创建版本文件夹并进入,以跟随本教程 mkdir xtuner019 && cd xtuner019 # 拉取 0.1.9 的版本源码 git clone -b v0.1.9 https://github.com/InternLM/xtuner # 无法访问github的用户请从 gitee 拉取: # git clone -b v0.1.9 https://gitee.com/Internlm/xtuner # 进入源码目录 cd xtuner # 从源码安装 XTuner pip install -e '.[all]'

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
安装完后,就开始搞搞准备工作了。(准备在 oasst1 数据集上微调 internlm-7b-chat)
# 创建一个微调 oasst1 数据集的工作路径,进入
mkdir ~/ft-oasst1 && cd ~/ft-oasst1
- 1
- 2
2 微调
准备配置文件:是用什么算法 在什么数据集上 跑几轮训练 (会自动生成对话模板)
下载模型
下载数据集
修改配置文件
开始微调
2.1 准备配置文件
XTuner 提供多个开箱即用的配置文件,用户可以通过下列命令查看:
#列出所有内置配置
xtuner list-cfg
- 1
- 2
报错显示bash: xtuner: command not found
在终端输入 export PATH=$PATH:'/root/.local/bin ' 注意要加上后面的 '
后面还列出了许多内置配置,截图部分内容。
拷贝一个配置文件到当前目录: # xtuner copy-cfg ${CONFIG_NAME} ${SAVE_PATH}
本次课程中选择:(注意最后有个英文句号,代表复制到当前路径)
cd ~/ft-oasst1
xtuner copy-cfg internlm_chat_7b_qlora_oasst1_e3 .
- 1
- 2
配置文件名的解释:
xtuner copy-cfg internlm_chat_7b_qlora_oasst1_e3 .
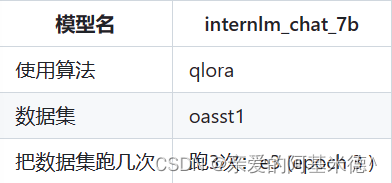
*无 chat比如 internlm-7b 代表是基座(base)模型
2.2 模型下载
方法一:有教学平台话可以直接复制模型。
cp -r /root/share/temp/model_repos/internlm-chat-7b ~/ft-oasst1/
- 1
方法二:自己下载模型,步骤如下:
不用 xtuner 默认的从 huggingface 拉取模型,而是提前从 OpenXLab ModelScope 下载模型到本地
#创建一个目录,放模型文件,防止散落一地
mkdir ~/ft-oasst1/internlm-chat-7b
#装一下拉取模型文件要用的库
pip install modelscope
#从 modelscope 下载下载模型文件
cd ~/ft-oasst1
apt install git git-lfs -y
git lfs install
git lfs clone https://modelscope.cn/Shanghai_AI_Laboratory/internlm-chat-7b.git -b v1.0.3
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
2.3 数据集下载
https://huggingface.co/datasets/timdettmers/openassistant-guanaco/tree/main
(无教学平台可以在上述网站下载数据集)
由于 huggingface 网络问题,教学平台提前下载好了,可以复制到正确位置即可:
cd ~/ft-oasst1
#...-guanaco 后面有个空格和英文句号啊
cp -r /root/share/temp/datasets/openassistant-guanaco .
- 1
- 2
- 3
2.4 修改配置文件
修改其中的模型和数据集为本地路径
cd ~/ft-oasst1
vim internlm_chat_7b_qlora_oasst1_e3_copy.py
- 1
- 2
在vim界面完成修改后,请输入:wq退出。假如认为改错了可以用:q!退出且不保存。当然我们也可以考虑打开python文件直接修改,但注意修改完后需要按下Ctrl+S进行保存。
减号代表要删除的行,加号代表要增加的行。
# 修改模型为本地路径
- pretrained_model_name_or_path = 'internlm/internlm-chat-7b'
+ pretrained_model_name_or_path = './internlm-chat-7b'
# 修改训练数据集为本地路径
- data_path = 'timdettmers/openassistant-guanaco'
+ data_path = './openassistant-guanaco'
- 1
- 2
- 3
- 4
- 5
- 6
- 7
常用超参

2.5 开始微调
训练:
xtuner train ${CONFIG_NAME_OR_PATH}
也可以增加 deepspeed 进行训练加速:
xtuner train ${CONFIG_NAME_OR_PATH} --deepspeed deepspeed_zero2
例如,我们可以利用 QLoRA 算法在 oasst1 数据集上微调 InternLM-7B:
# 单卡
## 用刚才改好的config文件训练
xtuner train ./internlm_chat_7b_qlora_oasst1_e3_copy.py
# 多卡
NPROC_PER_NODE=${GPU_NUM} xtuner train ./internlm_chat_7b_qlora_oasst1_e3_copy.py
# 若要开启 deepspeed 加速,增加 --deepspeed deepspeed_zero2 即可
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
由于加上deepspeed之后的训练时间明显减少,所以最后采用的指令为:
xtuner train ./internlm_chat_7b_qlora_oasst1_e3_copy.py --deepspeed deepspeed_zero2
- 1
如果有中断或者需要重新开始训练,记得检查自己的ft-oasst1文件夹下多出来一个工作目录,重新训练乾需要把它删掉。
守护进程
如果在服务器端训练时间较长,为了防止网络连接出错与本地电脑关机而打扰中断我们的训练。我们可以开启守护进程。
apt update -y
apt install tmux
tmux new -s <self_defined_name>
- 1
- 2
- 3
进入了全新的界面中,继续进行想要的操作
想要切回原来的界面 ctrl + B,松开后再按下D
回到tmux窗口,则继续输入
tmux attach -t <self_defined_name>
- 1
在tmux页面重新开始训练
2.6 将得到的PTH模型转换为HuggingFace模型
也就是生成Adapter文件。
xtuner convert pth_to_hf ${CONFIG_NAME_OR_PATH} ${PTH_file_dir} ${SAVE_PATH}
- 1
在本示例中,为:
mkdir hf
export MKL_SERVICE_FORCE_INTEL=1
# 此处MKL_SERVICE_FORCE_INTEL是由于跟随课程训练为了节省时间只训练了一轮
xtuner convert pth_to_hf ./internlm_chat_7b_qlora_oasst1_e3_copy.py ./work_dirs/internlm_chat_7b_qlora_oasst1_e3_copy/epoch_1.pth ./hf
- 1
- 2
- 3
- 4
3 部署与测试
3.1 将 HuggingFace adapter 合并到大语言模型:
xtuner convert merge ./internlm-chat-7b ./hf ./merged --max-shard-size 2GB
# xtuner convert merge \
# ${NAME_OR_PATH_TO_LLM} \
# ${NAME_OR_PATH_TO_ADAPTER} \
# ${SAVE_PATH} \
# --max-shard-size 2GB
- 1
- 2
- 3
- 4
- 5
- 6
3.2 与合并后的大模型对话
# 加载 Adapter 模型对话(Float 16)
xtuner chat ./merged --prompt-template internlm_chat
- 1
- 2
如果使用其他可以使用 xtuner chat --help 来帮助查看,如果更换了模型--prompt-template 一定要更换,这是一个更加重要的参数
# 4 bit 量化加载 (推理更加快速)
# xtuner chat ./merged --prompt-template internlm_chat --bits 4
- 1
- 2
3.2 Demo
xtuner chat ./internlm-chat-7b/ --prompt-template internlm_chat --bits 4
- 1
xtuner chat 的启动参数
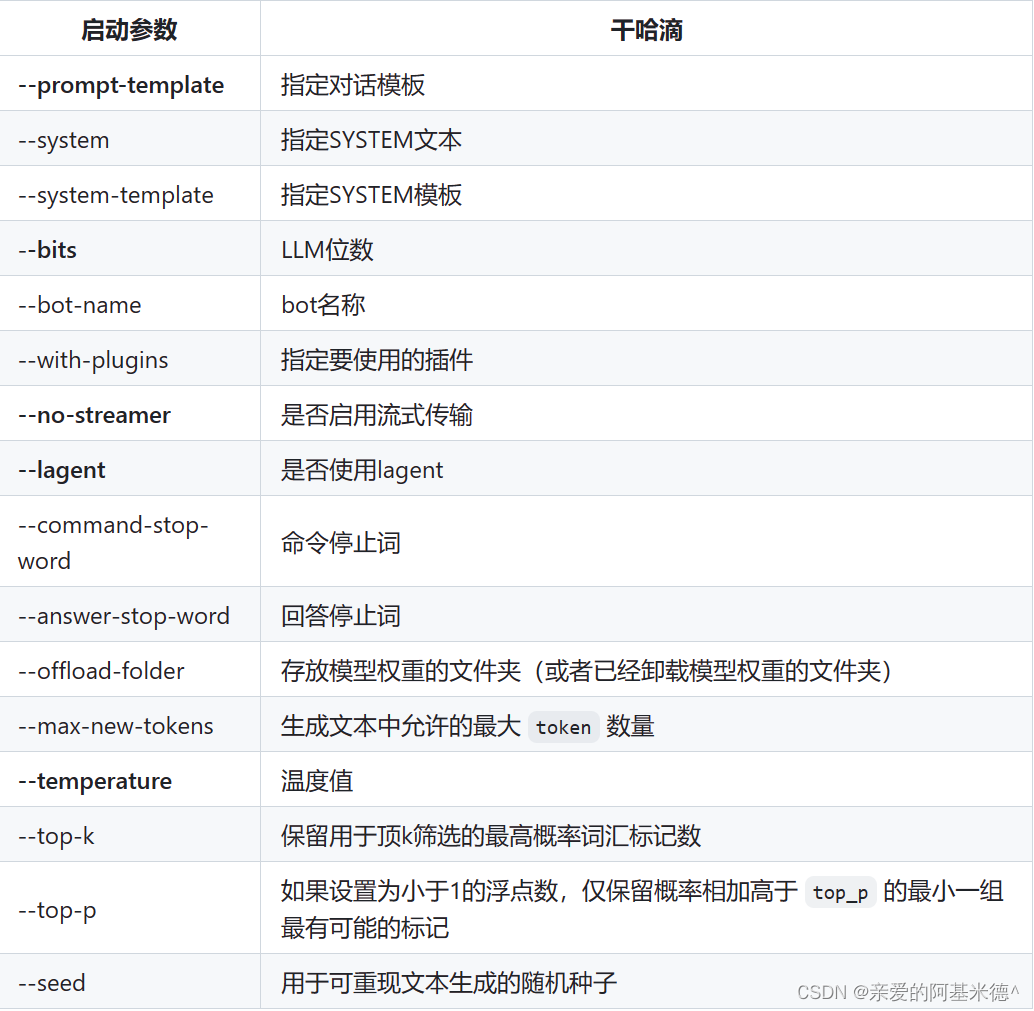
实现的效果如下图:

4 自定义微调
在personnal_assistant(自建)目录下,需要:
- 数据集:./data/personal_assistant.json(数据集 .json文件格式)
可以使用python脚本来生成训练数据集格式。 - 模型:./model (该目录下存放需要的模型)
- 配置文件:./config/internlm_chat_7b_qlora_oasst1_e3_copy.py
xtuner copy-cfg internlm_chat_7b_qlora_oasst1_e3
- 1
最终文件构成如下:(未训练前没有work_dirs)

然后按照例子修改配置文件:
https://github.com/InternLM/tutorial/blob/main/xtuner/self.md
开始训练
xtuner train /root/personal_assistant/config/internlm_chat_7b_qlora_oasst1_e3_copy.py --deepspeed deepspeed_zero2
- 1
重复上面微调后参数转换/合并
# 创建用于存放Hugging Face格式参数的hf文件夹
mkdir /root/personal_assistant/config/work_dirs/hf
export MKL_SERVICE_FORCE_INTEL=1
# 配置文件存放的位置
export CONFIG_NAME_OR_PATH=/root/personal_assistant/config/internlm_chat_7b_qlora_oasst1_e3_copy.py
# 模型训练后得到的pth格式参数存放的位置
export PTH=/root/personal_assistant/config/work_dirs/internlm_chat_7b_qlora_oasst1_e3_copy/epoch_3.pth
# pth文件转换为Hugging Face格式后参数存放的位置
export SAVE_PATH=/root/personal_assistant/config/work_dirs/hf
# 执行参数转换
xtuner convert pth_to_hf $CONFIG_NAME_OR_PATH $PTH $SAVE_PATH
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
export MKL_SERVICE_FORCE_INTEL=1 export MKL_THREADING_LAYER='GNU' # 原始模型参数存放的位置 export NAME_OR_PATH_TO_LLM=/root/personal_assistant/model/Shanghai_AI_Laboratory/internlm-chat-7b # Hugging Face格式参数存放的位置 export NAME_OR_PATH_TO_ADAPTER=/root/personal_assistant/config/work_dirs/hf # 最终Merge后的参数存放的位置 mkdir /root/personal_assistant/config/work_dirs/hf_merge export SAVE_PATH=/root/personal_assistant/config/work_dirs/hf_merge # 执行参数Merge xtuner convert merge \ $NAME_OR_PATH_TO_LLM \ $NAME_OR_PATH_TO_ADAPTER \ $SAVE_PATH \ --max-shard-size 2GB
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
在网页中查看
#安装网页Demo所需依赖
pip install streamlit==1.24.0
# 创建code文件夹用于存放InternLM项目代码
mkdir /root/personal_assistant/code && cd /root/personal_assistant/code
git clone https://github.com/InternLM/InternLM.git
- 1
- 2
- 3
- 4
- 5
将 /root/code/InternLM/web_demo.py 中 29 行和 33 行的模型路径更换为Merge后存放参数的路径 /root/personal_assistant/config/work_dirs/hf_merge
运行 /root/personal_assistant/code/InternLM 目录下的 web_demo.py 文件,输入以下命令后,将端口映射到本地。在本地浏览器输入 http://127.0.0.1:6006 即可。
streamlit run /root/personal_assistant/code/InternLM/web_demo.py --server.address 127.0.0.1 --server.port 6006
- 1
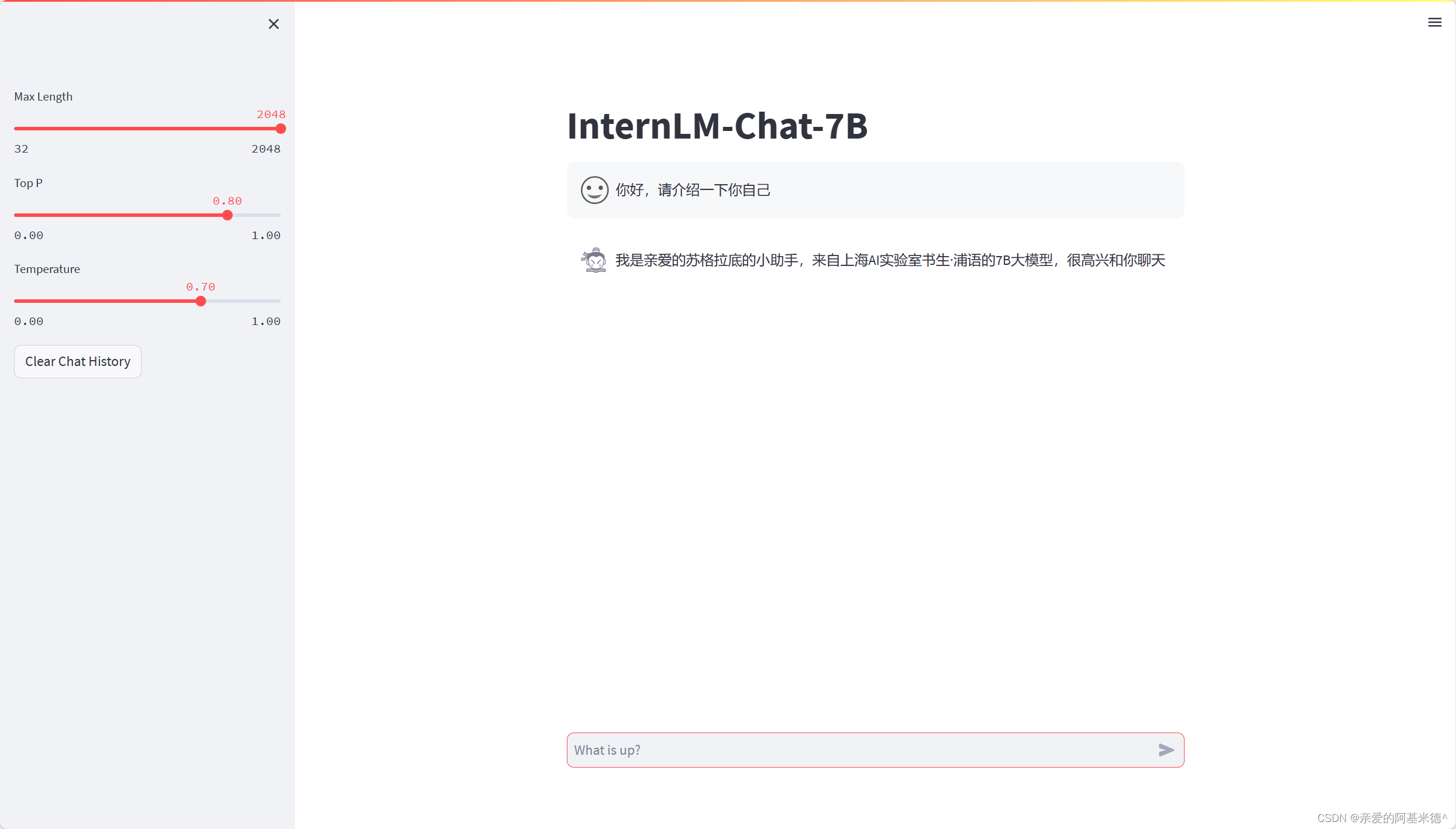
注意:要在浏览器打开 http://127.0.0.1:6006 页面后,模型才会加载。 在加载完模型之后,就可以与微调后的 InternLM-Chat-7B 进行对话了
最后的效果如图:
进阶作业:
将训练好的Adapter模型权重上传到 OpenXLab、Hugging Face 或者 MoelScope 任一一平台。
将训练好后的模型应用部署到 OpenXLab 平台,参考部署文档请访问:https://aicarrier.feishu.cn/docx/MQH6dygcKolG37x0ekcc4oZhnCe

