
- 1YOLOv7改进之二十四:引入量子启发的新型视觉主干模型WaveMLP(可尝试发SCI)_yolosci
- 2ChatGPT的诞生和发展_chatgpt的产生与发展
- 3Hive使用beeline(KERBEROS)_beeline kerberos
- 4Spring框架中访问MongoDB的深入解析*
- 5RocketMQ与Kafka深度对比:特性与适用场景解析_kafka和rocketmq对比
- 6全新桥隧坡安全监测解决方案,24h监测效率提升30%
- 7SercureCRT软件通过SSH连接ubuntb报错:password authentication failed解决方案_passwd authentication failed
- 8基于FPGA的四则运算_fpga除法的小数
- 9高效办公,从几行批处理命令开始,你知道吗?_几个非常高效的办公室批处理命令
- 10TortoiseGit不安全目录解决办法_to add an exception for this directory, call: git
【总结向】MRC 经典模型与技术_mrc模型
赞
踩
MRC 经典模型与技术
未完待续
目录
预备知识
文章和问题表示
文档表示
模型一:RNN表示
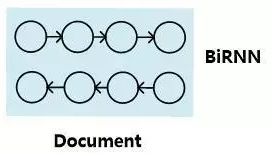
模型二:基于注意力的文档的表示
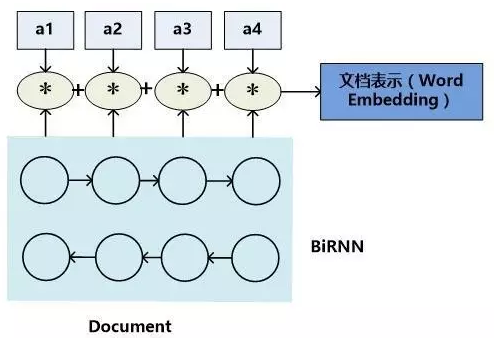
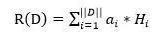
对于文档向量的每一个隐藏维度,乘以一个权重系数,这个系数代表了单词对于整个文章及其上下文的最终语义表达的重要程度,将每个单词的系数调整后的隐层状态累加即可得到文章的Word Embedding语义表达。
权重系数可以用Attention机制计算出来。
问题的表示
模型一:RNN表示
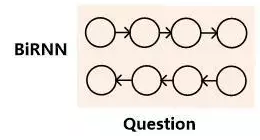
模型二:基于注意力的问题表示(同上文文档表示)
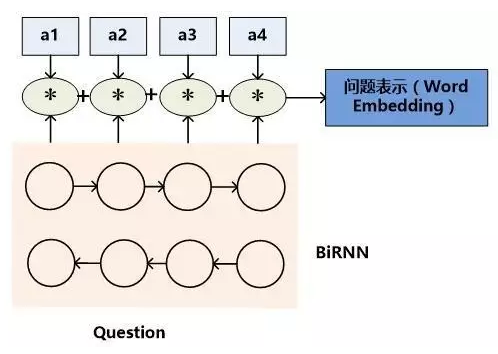
模型三:双向RNN头尾部隐层节点的表示
两个时刻的尾部隐层节点融合了整个句子语义,拼接起来可以表示问题的整体语义。
这种方式也可以用来表达文档,但是一般不会这么用,因为文档比较长,会引起信息丢失。
经典Attention

上图是BahdanauAttention,passage中的第t个词,会根据所有Q的隐向量、P中第t-1时刻的上下文向量来确定对Q每个token的权重。图中Y可以理解为Passage,X理解为question。如果预测的话,将X理解为Passage,Y理解为Answer(也就是当前时刻答案与所有passage向量与上一时刻的a有关)。



也就是说,attention机制的query可以是某个词(比如Query里的某个词),也可以是一个上下文(比如seg2seg里的问题上下文)。
Seg2Seg
RNN Seg2Seg
使用到了注意力机制,预测每个时刻的输出用到的上下文是与当前输出有关的上下文。


卷积Seg2Seg
2017年Facebook发表了NLP领域重要论文《Convolutional Sequence to Sequence Learning》
Positional Encoding
Normalization
Batch normalization
Batch normalization每个batch里面的很接近的样本,都归一成0均值1方差。
随着在神经网络训练深度加深,其整体分布逐渐发生偏移或变动,导致后向传播时神经网络梯度消失,深度网络收敛越来越慢。Batch normalization把越来越偏的分布强行正态分布,梯度变大,减缓梯度消失问题。因此,加Batch normalization是为了使深度神经网络训练速度加快。
LayerNorm
比如transformer Encoder层每个部分的输入都用到了LayerNorm,实现近似独立同分布。
随着神经网络的加深,每一层的输出到下一层的输入,会出现分布偏差越来越大。最后输出的target层的分布和输入的分布差距很大。
match-LSTM

前提premise,假说hypothesis,得到两者的表征。
得到两个表征之后,同样是 Attention 操作,得到 hypothesis 对于 premise 每个词注意力加权输出ak,将注意力加权输出与 hypothesis 对应位置词的隐藏层拼接,mk = [ak; htk],然后通过一个长度为N的LSTM,得到hypothesis整合关于premise的注意力的隐藏表征,然后用最后一个时刻的隐层向量预测结果。
指针网络 Pointer Network
比较好的讲解:https://www.jianshu.com/p/bff3a19c59be
是对attention机制的简化,seg2seq模型有“输出严重依赖输入”的缺点(因此会很依赖输入的长度)。指针网络可以克服这种缺点,使用注意力机制作为指针来选择输入序列的一个成员来作为输出序列(这就不需要给定词汇表,只需要选择输入序列中权重最大的元素)。界定一下,词汇表和输入序列里的词并不是完全包含的。

Pointer Net不像seq2seq将输入信息通过encoder整合成context vector,也就是说没有attention的最后一个公式,即将权重关系a和隐式状态整合为context vector,而是直接进行通过softmax,指向输入序列选择中最有可能是输出的元素。
ptr-net输出序列可以适应输入序列长度变化。Pointer Networks天生具备输出元素来自输入元素这样的特点,于是它非常适合用来实现“复制”这个功能,很多研究者也确实把它用于复制源文本中的一些词汇。
attention vs ptr-net总结:传统attention+seq2seq模型输出的是针对词汇表的概率分布,而ptr-net输出的是针对输入文本序列的概率分布。
Gated
通过GRU来理解门
门我的理解就是通过激活函数(比如sigmoid,它的数值范围是0 ~ 1,tanh激活函数数值范围是-1~1),来充当门信号。如GRU的两个门控(遗忘门、更新门控)。
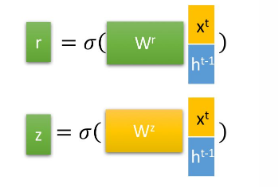

如z门控信号范围为0~1,门控信号越接近1,代表记忆下来的数据越多,反之遗忘的越多。然后由这些门控,构成更新表达式。
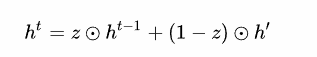
GRU很聪明的一点就在于,使用了同一个门控z就同时可以进行遗忘和选择记忆。
Highway Network
基于门机制,类似于一个Residual,是为了降低信息在传输过程中的损失,y=αf(x)+(1-α)x。
核心思想是将网络前一层的输出,跳着连到更后面的层(Skip Connection),使得模型的深度可以达到上百层。Highway Network使得所有原始信息部分激活进入下一层、部分不激活直接进入下一层,保留了更多原始信息。同时反向传播的时候,可以避免梯度消失。
Highway 结构对词向量以及字符向量的整合
Highway Maxout Networks (HMN)
在传统的MLP(多层感知机)上加入了两个改进,引入了Highway Network中的Skip Connection以及使用Maxout作为激活函数。

上图中,待预测位置ut和r拼接,然后输入到把maxout作为激活函数的三层MLP中,第一层的MLP的输出也传给了第三层,这里用到了skip connection。
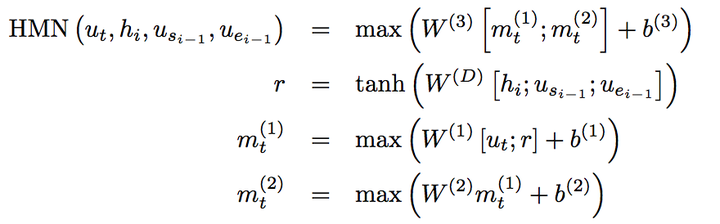
Maxout 是一种可学习的激活函数,其思想在于对每一个神经元的输出,都通过k组可学习的参数进行加权变换,得到k个输出,对k个输出取最大值作为最终输出。该方法理论上可以学习到任何类型的激活函数,缺点是引入了更多的参数,增加了训练成本和过拟合的可能。
Depthwise Separable Convolution
占位
记忆网络(以后补,不太会)
参考:https://blog.csdn.net/u014248127/article/details/84894739
Memory Networks (MemNN)
参考:https://zhuanlan.zhihu.com/p/29590286
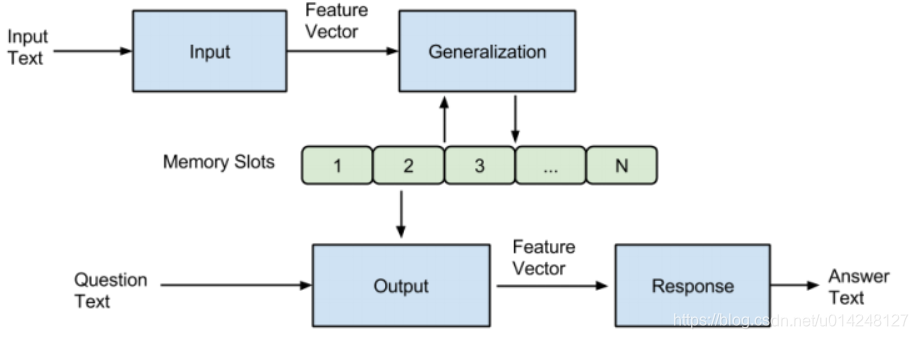
动机:传统的深度学习模型(RNN、LSTM、GRU等)使用hidden states或者Attention机制作为他们的记忆功能,但是这种方法产生的记忆太小了,无法精确记录一段话中所表达的全部内容,也就是在将输入编码成dense vectors的时候丢失了很多信息,所以就提出了一种可读写的外部记忆模块,并将其和inference组件联合训练,最终得到一个可以被灵活操作的记忆模块。
模型主要包含一系列的记忆单元(可以看成是一个数组,每个元素保存一句话的记忆)和I,G,O,R四个模块。
-
I: (input feature map):用于将输入转化为网络里内在的向量。(可以将输入编码为内部特征表示,例如,从文本转换为稀疏或密集特征向量,得到I(x) )
-
G: (generalization):更新记忆。也就是根据I(x)对memory进行读写操作。最简单的G形式是将I(x)存储在 memory slots中。
-
O: (output feature map):结合输入和记忆,把合适的记忆o抽取出来,返回一个向量。o= O(I(x), m)
-
R: (response):将向量o decode为所需的格式,比如文字或者answer。r=R(o)
缺点:没有端到端思想的训练。
End-To-End Memory Networks
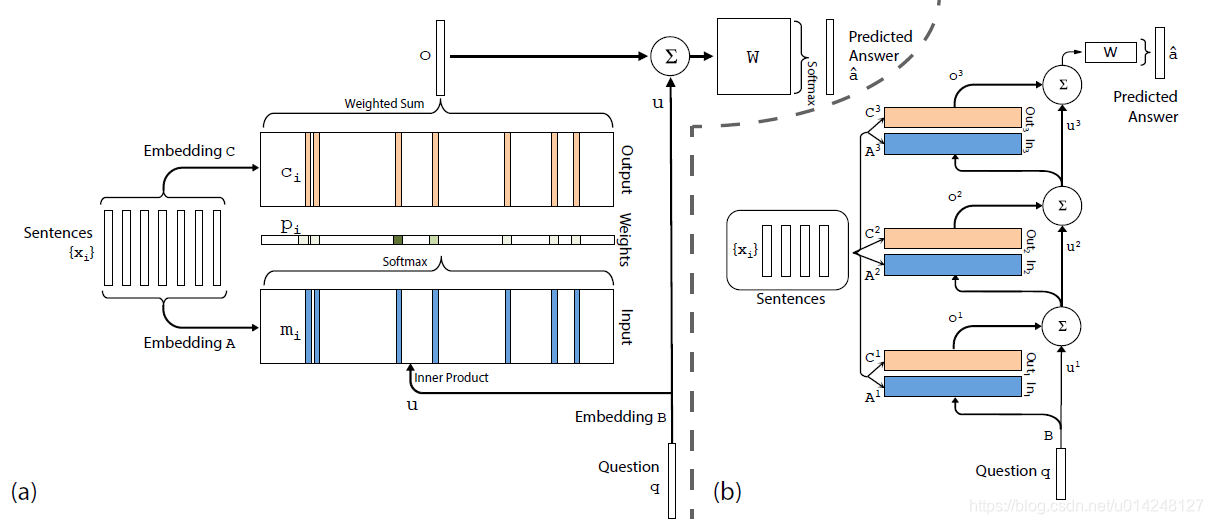
- 单词推理,图a
- 多次推理,图b
Key-Value Memory Networks
参考:https://blog.csdn.net/liuchonge/article/details/78143756

从上图可以看出来key embedding和value embedding两个模块跟end-to-end模型里面input memory和Output memory两个模块是相同的,不过这里记忆是使用key和value进行表示,而且每个hop之间有R矩阵对输入进行线性映射的操作。此外,求每个问题会进行一个key hashing的预处理操作,从knowledge source里面选择出与之相关的记忆,然后在进行模型的训练。在这里,所有的记忆都被存储在Key-Value memory中,key负责寻址lookup,也就是对memory与Question的相关程度进行评分,而value则负责reading,也就是对记忆的值进行加权求和得到输出。二者各自负责自己的功能,相互配合,使得QA过程的记忆和推理各司其职。
Dynamic Memory Network
DMN网络模型包含输入、问题、情景记忆、回答四个模块。
模型首先会计算输入和问题的向量表示,然后根据问题触发Attention机制,使用门控的方法选择出跟问题相关的输入。然后情景记忆模块会结合相关的输入和问题进行迭代生成记忆,并且生成一个答案的向量表示。
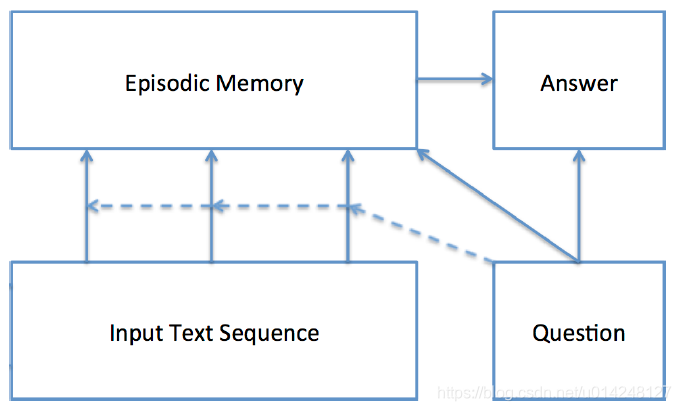

Episodic Memory Module,这部分主要有三部分:注意力机制、记忆更新、多次迭代。
这里使用一个门控函数作为Attention;计算出门控函数的值之后,根据其大小对记忆进行更新,更新方法就是GRU算出的记忆乘以门控值,再加上原始记忆乘以(1-门控值);每次迭代关注不同的内容,这样传递推导,检索不同的信息。
Answer Module:根据memory模块最后的输出向量(将其作为初始隐层状态),然后输入使用的是问题和上一时刻的输出值连接起来(每个时刻都是用q向量)。并使用交叉熵损失函数作为loss进行反向传播训练。
Gated End-To-End Memory Networks
一维匹配模型
一维匹配模型之间的最大区别主要是匹配函数的定义不同。
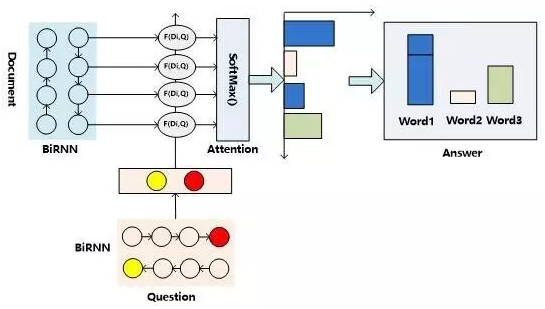
核心
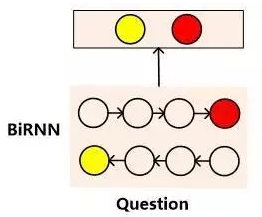
用双向RNN的头尾部节点RNN隐层状态拼接作为问题的语义表示,通过某种匹配函数F来计算文章中每个单词Di语义和问题Q整体语义的匹配程度,再对每个单词的匹配函数值通过SoftMax函数进行归一化。
整个过程可以理解为Attention操作,相同单词Attention概率值累加,作为答案可能性。
匹配函数:前向神经网络的形式,
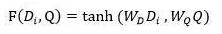
Attentive Reader

非累加的模式进行预测单词。
数据集:CNN, Daily Mail
Attention Sum Reader(ASReader)

匹配函数:点积,
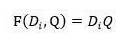
预测判断:Pointer Sum Attention机制,即累加模式(同一个词的attention在softmax之后累加),得分最高的是答案。这里受到了Pointer Networks(Ptr-Nets)的启发。
数据集:CNN, Daily Mail,CBT
Stanford Attentive Reader(Stanford AR)

Stanford Attentive Reader模型encoding步骤与AS Reader模型encoding步骤基本一致。
匹配函数:双线性(Bilinear)函数,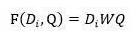
预测:直接用注意力加权输出作为进行分类预测。
数据集:CNN, Daily Mail
Gated-Attention Reader(GA Reader)
参考:https://blog.csdn.net/sinat_34611224/article/details/82899163

-
Lookup Table就是输出tokens的向量表示,用全连接训练词向量。
E是Document每个词项过Bi-GRU后每个隐藏层状态 ,q是每个词项过Bi-GRU后每个隐藏层状态串起来
-
Gated-Attention是E, q输入进行两两相乘,得到下一层的输入X;
-
Multi-hop结构:带着问题重读文章k次,从而增量式地重新得到tokens的表示,可以进一步帮助锁定答案。第k层的时候,公式是:
sK=exp<qK, eK>/∑exp<qK, eK>,得到概率最大的answer是最终输出
累加模式

数据集:CNN, Daily Mail
二维匹配模型
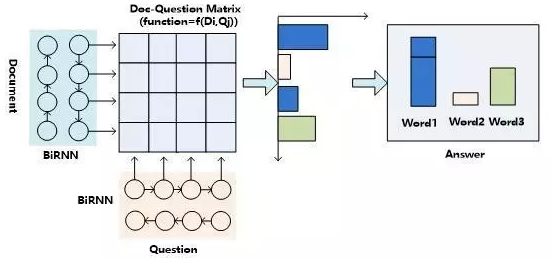
在计算问题和文章匹配的步骤中,就形成了||D||*||Q||的二维矩阵,就是说文章中任意单词Di和问题中的任意单词Qj都应用匹配函数来形成矩阵的位置的值。
二维矩阵,所以可以有多种Attention计算机制。
- 按行计算表达的是文档单词Di和问题中各个单词的语义相似程度
- 按列计算表达的是问题单词Qi和文档序列中各个单词的语义相似程度
Impatient Reader
像是一维和二维匹配模型的结合

将Q中的每个单词当做单独的query,从而计算该单词对于文档中每个词的注意力加权表征(常用!文档这里是模型二),非线性变换将所有的 r (二维匹配)进行反复累积(单词的重阅读能力)。
将最后一个文档表示r(文档模型一)和问题表示u(问题的模型三),一维匹配,进行非线性组合用于预测答案
数据集:CNN, Daily Mail
Consensus Attention(CAReader)
Attention计算方式:按列计算,然后对每一行文档单词对应的针对问题中每个单词的Attention向量,采取一些启发规则的方式比如取行向量中最大值或者平均值等方式获得文档每个单词对应的概率值。
Attention-over-Attention(AoA Reader)

匹配函数: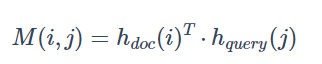
Attention计算方式:对CA Reader进行了改进,同时结合按照列和按照行的方式进行Attention计算,按列计算形成 query-to-document attention, 按行计算形成 document-to-query attention (AoA亮点)后做平均得到query-level attention,然后两个attention做点乘,得到document中的每个词的score。按行与按列,类似于人阅读文档的过程,先看问题,分析问题中的词的重要性,再去文档中定位相关性最高的词作为答案。
预测:类似AS Reader,同类型的词累加
数据集:CNN&Daily Mail、CBT;
match-LSTM and Answering Point(经典)
该论文的主要贡献在于
-
将指针网络Pointer Net中指针的思想首次应用于阅读理解任务中。
-
在 Match-LSTM 提出之后,question-aware 表征的构造方式开始出现在各个论文之中。
可参考博客:https://blog.csdn.net/u012892939/article/details/80186590
把question当做premise,passage当作hypothesis。

match-LSTM与Attention应用方式
-
计算Attention:对段落P中每个词,计算其关于问题Q的注意力分布α(这个向量维度是question词长度,故而这种方法也叫做question-aware attention passage representation),并使用该注意力分布汇总拟合出整个问题的总和语义表示(按列);
-
将attention向量与原问题编码向量点乘(按行),得到p中第i个token的Q关联信息,并与段落中该词的隐层表示合并为一个向量- ;
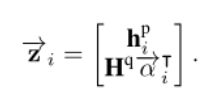
- 最后输入到LSTM中。在这个LSTM结构基础上去预测哪个或者那些单词应该是正确答案。
预测结果:两种 Answer Point Layer 模型,Sequence Model 和 Boundary Model。
- Sequence Model考虑到答案在passage中不是连续存在的,因此预测的是答案标记序列,βk,j是从段落中选择第 j 个字符作为第 k 个答案字符的概率- 。
p ( a k = j ∣ a 1 , a 2 , . . . , a k − 1 , H r ) = β k , j p(a_k=j|a_1,a_2,...,a_{k-1},H^r)=\beta _{k,j} p(ak=j∣a1,a2,...,ak−1,Hr)=βk,j
p ( a ∣ H r ) = ∏ k p ( a k ∣ a 1 , a 2 , . . a k − 1 , H r ) p(a|H^r)=\prod _kp(a_k|a_1,a_2,..a_{k-1},H^r) p(a∣Hr)=k∏p(ak∣a1,a2,..ak−1,Hr)
- Boundary Model 默认生成的答案在 passage 中是连续存在的,因此只需要预测开始位置,且在已知开始位置的基础上预测一个结束位置即可,实验表明,此方法更好。即:
p ( a ∣ H r ) = p ( a s ∣ H r ) p ( a e ∣ a s , H r ) p(a|H^r)=p(a_s|H^r)p(a_e|a_s,H^r) p(a∣Hr)=p(as∣Hr)p(ae∣as,Hr)
数据集:SQuAD
BiDAF (Bidirectional Attention Flow)
在 Match-LSTM 提出之后,question-aware 表征的构造方式开始出现在各个论文之中。
这篇论文的贡献在于双向注意力机制的提出,这种双向注意力机制在QA任务中充当编码器或者推理单元中的一环对后续的性能产生更大的影响。
很好的参考:https://www.zybuluo.com/songying/note/1441941
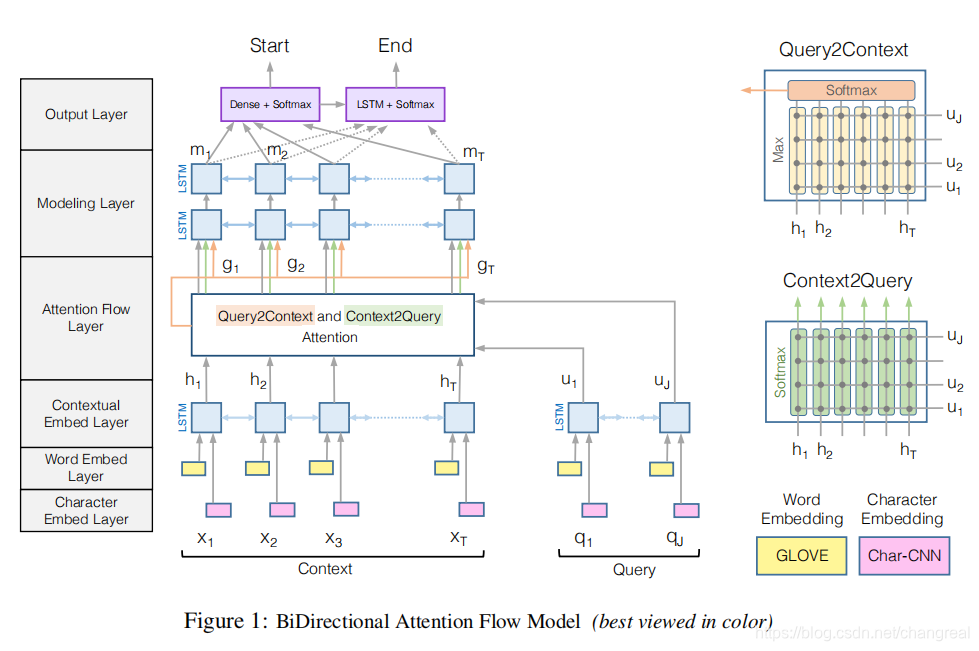
嵌入:word embedding, character embedding (在Bert之后都不够看了)
Attention:注意力流层负责链接与融合query和context的信息。query-to-context, context-to-query 两个方向的Attention信息,最后再与Context上下文信息融合,构造出 query-aware 的Context表示。
-
两种attention构造的方法,详细学习上面链接
Context-to-query (C2Q),就是对于 Context 中的第t个单词,计算 Query 中的每个单词与该词的相关度,然后通过这些相关度信息来计算Context每个词(行)的新表示。
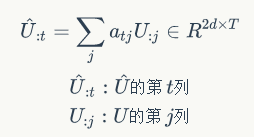
Query-to-context Attention(Q2C):其本质是计算对于 Query 中的词, context 中的每个词与它的相关度。 而此段中的计算与上述有所不同。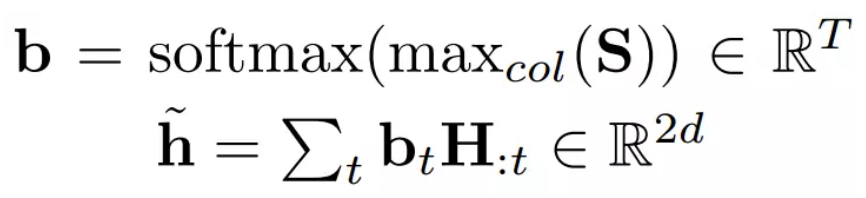
- 使用了 memory-less attention mechanism,就是说每个time step的注意力是当前时间步的问题和上下文段落的函数,不依赖于之前time step的注意力(match-LSTM ptr-net就依赖)!
数据集:SQuAD
BiDAF ++(待更)
在BiDAF基础上,引入了多段机器阅读理解的模型。基于BiDAF,BiDAF ++增加了自我注意力层以增加模型容量。(Simple and Effective Multi-Paragraph Reading Comprehension (ACL 2018))
DCN (Dynamic Co-Attention Networks)
DCN和BiDAF都使用了query-to-context attention,DCN也是生成双向注意力,给p注意力权重,也给q注意力权重。
该方法采用了最基本的seq2seq框架来对答案片段的起始和终止位置进行预测。在seq2seq框架的Encoder部分,加入Co-Attention机制去融合问句和文档信息,再将融合信息和文档信息通过双向LSTM再次融合;Decoder部分使用HMN对结果进行预测,通过一个LSTM保存历史预测信息。
参考:https://zhuanlan.zhihu.com/p/27151397
协同注意力 Co-Attention有两种:
- parallel co-attention
- alternating co-attention(本文)
动态迭代 dynamic iteration: 对于模型输出的结果,我们不直接将它作为最终的结果,而是将它继续输入到模型中迭代出新一轮的输出,经过多次迭代,直到输出不再变化或超过迭代次数阈值。

模型
Coattention Encoder:可以概括为通过Co-Attention结合文档和问句的特征信息,用双向LSTM对结合后的特征信息和文档信息进行融合。
- 先分别获得文档和问句的每一时刻LSTM表示矩阵,记为D和Q,然后相乘获得两个矩阵的信息L,然后对矩阵L按行和按列softmax或者对文档和对问句的Attention,即AQ 和 AD;
- 然后利用Alternating Co-attention的思想,先得到加入了Attention之后的问句信息CQ ,然后再和文档进行attention得到文档信息和文本信息的结合CD ;
- 然后将D和CD 连接通过双向LSTM在时序上融合,最后得到输出矩阵U- 。

Dynamic Pointer Decoder:由Coattention Encoder的输出矩阵U,利用该矩阵,通过 动态迭代 来预测答案在文档的起始位置指针和终止位置指针。用到了HMN,HMN模型对文档中的每一个字,都分别从【将它作为起始位置】或【终止位置】两个方面进行打分。

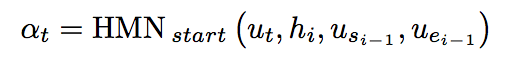
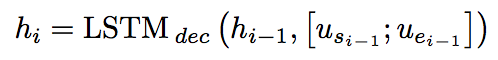
用HMN根据历史预测信息(LSTM存储的hi,可以将每一次的预测位置结果us,ue输入到一个LSTM中去保存该历史预测信息)、上一次预测位置(us,ue),对文档中的当前字ut作为起始位置(或终止位置)的可能性进行打分,将最后一次迭代得分最高的作为起始位置(或终止位置),得到文档片段作为最终答案。
数据集:SQuAD
DrQA(待更)
在解决开放域问题解答。 DrQA 使用文字嵌入、基本语言特征和简单的注意机制,证明了没有复杂结构设计的简单模型也可以在机器阅读理解中获得好的结果。(Reading Wikipedia to Answer Open-Domain Questions (ACL 2017))
FusionNet(待更)
基于对以往工作中注意力方法的分析,Huang 等人提出了FusionNet,从三个方面扩展了注意力。他们提出使用词的历史和 fully aware attention,这使得模型结合了来自不同语义层的信息流。此外,这个想法也适用于自然语言推理。(Fusing via Fully-aware Attention with Application to Machine Comprehension (ICLR 2018))
R-NET(还是不太懂)
R-Net主要是在 Match-LSTM 的基础上进行的,但是也受到attention is all you need的影响,预测上用了pointer-network。
R-Net的主要贡献是自我匹配的注意机制。在上下文和问题的门控匹配之后,引入了段落自匹配来汇总整个段落的证据并改进段落表示。
参考:https://blog.csdn.net/jyh764790374/article/details/80247204

Question and Passage Encoder:该层将Word Embedding 以及 Character Embedding 拼接,在输入一个双向GRU对 Question 以及 Passage 进行编码
Gated Attention-based Recurrent Networks
-
计算QP的注意力得到问题的匹配信息ct ,然后得到Sentence-pair的表征,vtP = RNN(vt-1P , ct ),每一个Sentence-Pair 向量都动态整合了整个问题的匹配信息(上图的3个黄色块)。
-
借鉴 Match-LSTM 的思想,将 Passage 的表征输入到最后的RNN中,得到 Question-aware Passage 表征 :
vtP = RNN(vt-1P , [ utP ,ct ])(上图黄色块上面的红色块)
-
为了动态判断输入向量与 Question 的相关性,还额外加入一个门机制,对RNN的输入进行控制,因此将其称为 Gated Attention-based Recurrent Networks。(通过门机制,模型根据段落与问题的相关程度,赋予了段落中不同词的重要程度,掩盖了段落中不相关的部分。)
Self-Matching Attention:上一层输出的 Question-aware 表征确定了段落中与问题相关的重要部分,但这种表征的一个重要问题是其很难包含上下文信息,然而一个答案的确定很多时候都是很依赖于上下文的。
-
因此这层动态地收集整个段落的信息给段落当前的词语(pp-attention,是整个passage的自注意力池化)
-
把与当前段落词语相关的信息和其匹配的问题信息编码成段落表示
h t P = B i R N N ( h t − 1 P , [ v t P , c t ] ) h^P_t = BiRNN(h_{t-1}^P, [v_t^P, c_t]) htP=BiRNN(ht−1P,[vtP,ct])
Output Layer:该模型同样利用 Point Network 的结构来直接预测答案的起始位置和输出位置。对问题进行attention-pooling得到rQ 作为起始键,对文章进行attention-pooling得到ct,然后进行一个seg2seg循环,hta=RNN(ht-1a, ct),其中ha是pointer-network的隐层。然后得到答案,即起始位置和终止位置。(不太懂)
所以这其实是一个seq2seq的过程,只不过最终得到的seq中只有两项,即起始位置和终止位置。(不太懂)
数据集:SQuAD
QANet(集大成者)
融合了2017~2018年NLP的重要突破(各种炫技),集大成者。
启发和融合(BiDAF, transformer, 深度可分离卷积等)
- CNN seg2seg 代替LSTM (把self-attention和convolution结合起来)
- multi-head attention,positional encoding,并且每个块中都用了LayerNorm + residual connection,mask(很受attention is all you need启发)
- depthwise separable conv,( 处处都在用!不止encoder里,嵌入后也会通常conv一下)
- highway network
- data augmentation: back-translation
感慨一下,QANet真是集大成者,并且文章好读易懂,优秀的模型就应该这样。
QANet结构广泛使用convolutions和self-attentions作为encoders的building blocks,然后分别encode query和context,然后使用standard attentions学习到context和question之间的interactions,结果的representation再次被encode,然后最后decode出起始位置的probability。

结构
Input embedding layer:词嵌入依旧是word embedding和character embedding(这和BiDAF相似),字符嵌入是用卷积训练的固定长度词向量,然后拼接两者嵌入,在上面再接一个2层的highway network
Embedding encoder layer:Encoder block见图,卷积使用的是 深度可分离卷积,有更好的泛化能力、更少的参数和计算量
Context-Query Attention Layer:常用组件,相似度计算方法也类似BiDAF,二维匹配,得到context中每个词对Question所有词的注意力,归一化后得到矩阵S,再对问题表征Q加权,从而得到context-to-query attention表征(这收到DCN的启发)。总之,这些是十分高效的模型编码方式:
A
=
S
⋅
Q
T
∈
R
n
×
d
A=S⋅QT ∈Rn×d
A=S⋅QT∈Rn×d
其中相似度矩阵的计算方法也是比较传统的方法:f(q,c)=W0[q; c; q·c],输出是[c, a, c·a, c·b]
Model Encoder Layer :类似BiDAF的结构,输入为context的query-aware表征[c, a, c·a, c·b],a和b代表着attention矩阵的行。这三个encoder可以理解为对问题与答案匹配的特征做一层一层的高级提取。QANet最后需要算起始位置的概率分布,因此可以认为第一层encoder提取答案全局特征,第二层提取答案开头特征,第三层提取答案结束的特征。
Output Layer:答案的起始位置的概率计算,也类似BiDAF,Pointer Network预测位置 ,span score是起始位置概率的乘积,损失函数为交叉熵
以上公式:
 ,
,
实验

数据集:SQuAD
多伦迭代策略
一种常见的推理策略往往是通过多轮迭代,不断更新注意力模型的注意焦点来更新问题和文档的Document Embedding表达方式,即通过注意力的不断转换来实现所谓的“推理过程”。
记忆网络(Memory Networks)
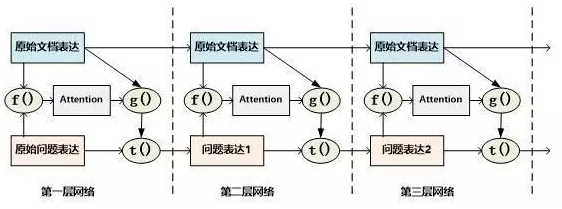
Layer-Wise RNN模式:首先根据原始问题的Word Embedding表达方式以及文档的原始表达,通过f函数计算文档单词的Attention概率,然后g函数利用文章原始表达和Attention信息,计算文档新的表达方式(这里一般g函数是加权求和函数)。t函数则根据文档新的表达方式以及原始问题表达方式,推理出问题和文档最终的新表达方式(通过两者Word Embedding的逐位相加实现的)。t函数的输出更新下一层网络问题的表达方式。这样就通过隐式地内部更新文档和显示地更新问题的表达方式实现了一次推理过程。
AMRNN推理过程
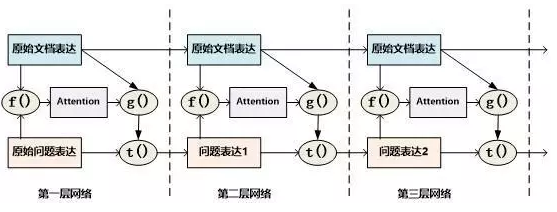
AMRNN模型可以近似理解为AS Reader的基础网络结构加上记忆网络的推理过程。
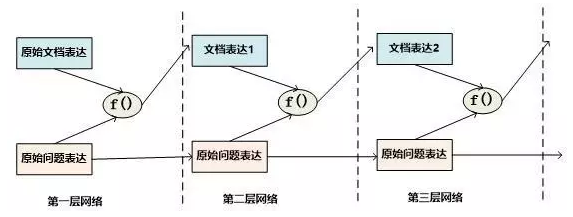
GA Reader
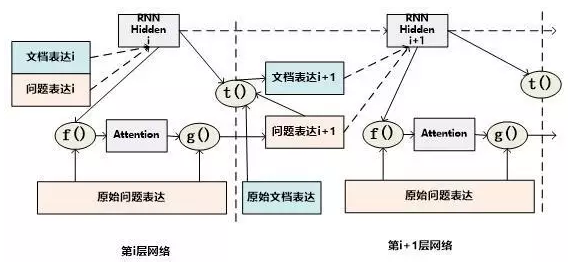
IA Reader
全文参考
张俊林大神关于一维二维匹配的解读:https://blog.csdn.net/malefactor/article/details/52832134
西多士NLP博主总结:https://www.cnblogs.com/sandwichnlp/p/11811396.html#model-1-attentive-reader-and-impatient-reader

