- 1如何在个人苹果电脑 MacOS 上运行 Meta 的新模型 SeamlessM4T,进行语音/文本翻译和转录_seamless 安装部署
- 2Keil中添加芯片包_keil芯片包
- 3学习笔记Flink(一)—— Flink简介(介绍、基本概念、应用场景)_flink介绍和基本概念
- 4Java并发编程75道面试题及答案——稳了_new thread 0x7fffe915f700 (lwp 286546)]
- 5专访熊军、冉崇洁:把脉多元数据库生态,云和恩墨就数据库存储和管理给出良方...
- 6spring中@param和mybatis中@param使用区别_spring @param
- 7CC攻击与DDoS攻击有什么区别?如何进行有效防护?_ddos cc攻击区别 协议
- 8分布式领域计算模型及Spark&Ray实现对比
- 9Python爬虫到入门只需要三个月_python爬虫要学多久
- 10actor-critic代码逐行解析(tensorflow版)_actor-critic算法代码
GAN网络:图像生成、图像修复和风格迁移_gan图像修复
赞
踩
声明:参考开源代码
一、总体设计
我们使用python语言在vscode上开发此系统,利用GAN(StyleGAN、CycleGAN等)网络实现图像生成、图像修复和风格迁移。使用此系统,用户可以生成自己想要的图像,帮助生成不同环境或不同需求的图片,同时生成大量数据,为深度学习提供数据集;除此之外,用户可以修复残缺图像中损坏部分的像素特征,可以作用于矩形块掩模修复、不规则掩模修复、目标去除、去噪、水印去除、文字去除、刮痕去除、旧照片着色等领域;最后用户可以将某一风格的图像迁移到一张图片上,可应用于图像处理,视频处理和风格设计,如美图工具中的各类滤镜。
二、功能框图

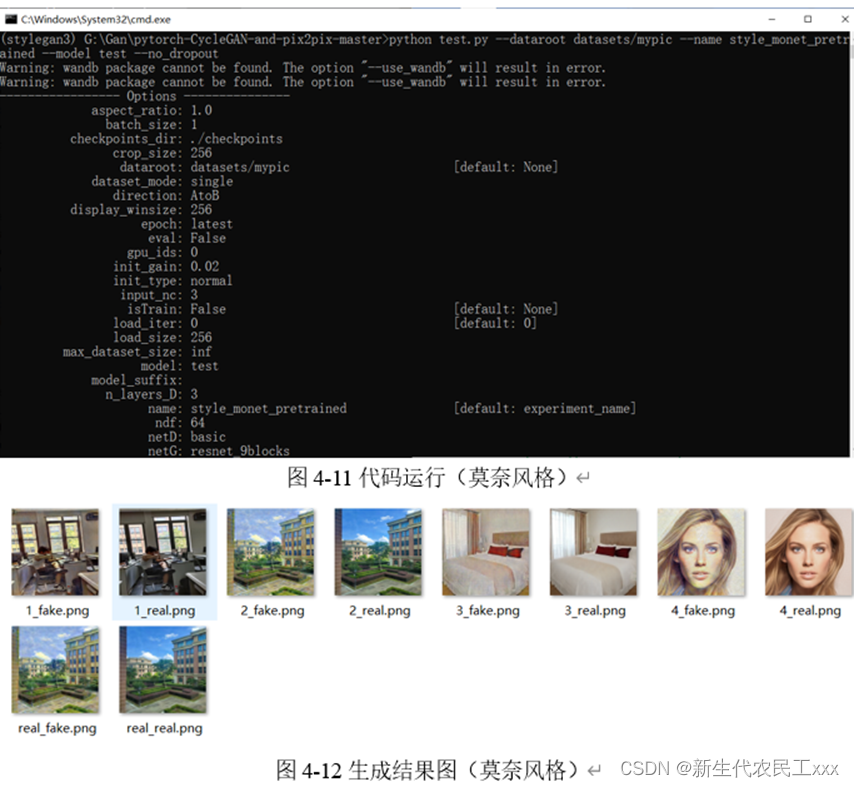
三、风格迁移
首先实例化TrainOptions来接收命令行输入参数,然后加载数据集,接着加载模型(create_model方法中使用find_model_using_name来导入对应的包,例如如果命令行输入参数为cycle_gan则会导入models中的cycle_gan_model.py模块,model = cls 成功将模型类拿到,最后用return返回,再回到create_model中利用opt实例化模型,实例化便会调用所选模型的**_init_()方法 ),生成器的网络架构主要通过models/networks里面的define_G函数进行初始化,G_A与G_B构造一样。判别器的网络架构主要通过define_D函数进行初始化,D_A与D_B也一样。
残差快的构造:以残差生成器为例,单个残差块的构造如下x → padding(reflect | replication | zero)→ conv2d → normalization layer (batch | instance | none) → Relu → conv2d → normalization layer (batch | instance | none) → x’。残差块是带skip connection的卷积块。使用残差结构最大的优点是可以有效地缓解梯度消失的问题。
生成器的构造:如代码所示,输入首先经过reflection padding,再经过一个conv2d, norm layer 和 Rule 的组合,然后进入下采样阶段——先后经过两个下采样模块(conv2d → norm layer → Relu),然后经过若干个残差块(6 | 9),随后进入上采样阶段——先后经过两个上采样模块,只不过将下采样模块中的conv2d换成反卷积操作convtranspose2d,最后在经过一次reflection padding,conv2d, 然后经过tanh得到最后输出。
判别器的构造(NLayerDiscriminator为例):x → n (conv2d → norm_layer → LeakyRelu) → conv2d → norm_layer → LeakyRelu → conv2d → y。
训练函数是利用生成器与判别器计算损失,设置判别器和生成器中的参数是否需要记录梯度,这里生成器不需要记录的原因是,生成器的进化只依赖于判别器给生成器的反馈与判别器的参数无关。损失函数一共由3种,分别为identity loss,GAN loss和Cycle loss。
lambda_A:weight for cycle loss (A -> B -> A) A方向重建损失权重;lambda_B:weight for cycle loss (B -> A -> B) B方向重建损失权重;lambda_identity:identity loss相对于cycle loss的比例;通过判断lambda_idt是否大于0,来判断当前实验是否计算Identity Loss。

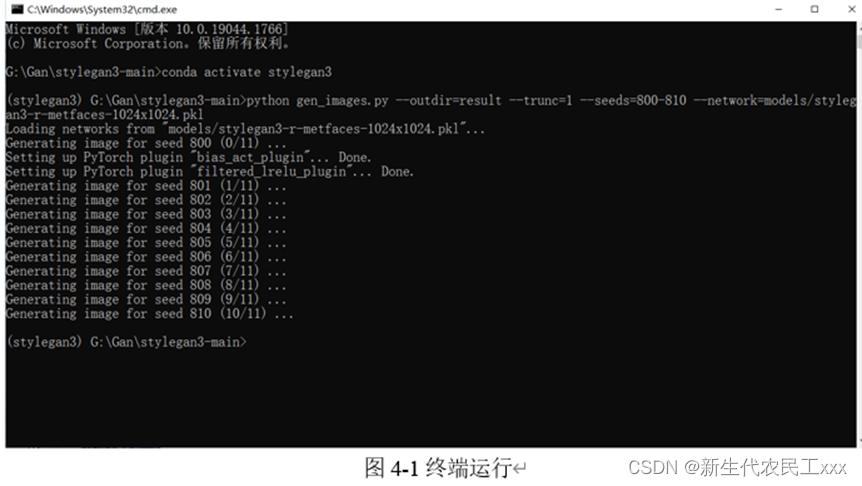
四、图像生成
我们使用一代和三代StyleGAN来实现图像生成,这里我们主要介绍一代StyleGAN。
数据预处理:把原来的像素先缩小到2/255然后减去1,随机产生(batch_size, 1, 1, 1)维度的数组,其值为0到1之间,对前面产生的像素,进行复制,复制之后的维度为[batch_size, 3, 1024, 1024],小于0.5的返回原值,否则返回对第三维进行翻转之后的值(经过一位小伙伴的提醒,进行了修改),把每张(1024, 1024)的图片图片分割成4快区域,每块区域为512*512个像素,每个区域都用他们的平均像素代替,lod越大,则越接近原图,其主要目的就是把原图损失的像素值补回来,当lod围殴10,即2的10次方插值,此时和原图一样。
G_mapping:其主要就是经过八个全连接操作,然后通过dlatent_broadcast进行广播,得到[?, 18, 512]的矩阵,后面与G_synthesis网络搭配使用。
G_synthesis:其网络首先是定义了第一层,然后根据structure参数,对网络结构进行选择,我们的网络使用的是structure == ‘linear’,其实反射变换A就是一个全连接层,这样就能通过网络迭代,学习到自己层相关的权重参数,其实现是在style_mod函数中。
Discriminator网络:输入图片,然后通过一系列的卷积激活,全连接操作,然后得到一个值,这个值就是对应图片图片是否为真是图片的概率值。
loss损失函数:G_logistic_nonsaturating计算的损失,都是生成图片的损失,因为它的目的十分的单纯,就是为了生成逼真的图片,所以只需要对生成的图片进行损失计算即可。但是对于判别网络,它的目的是在于鉴别图片的真假,它不仅要判断出造假的图片,还要判断出真实的图片。无论是造假还是真实他都要进行损失计算。
最后进行图片生成和融合。

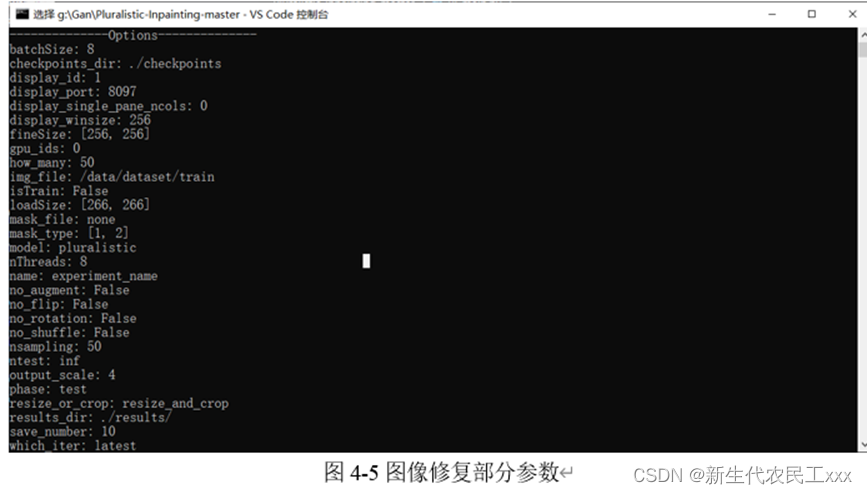
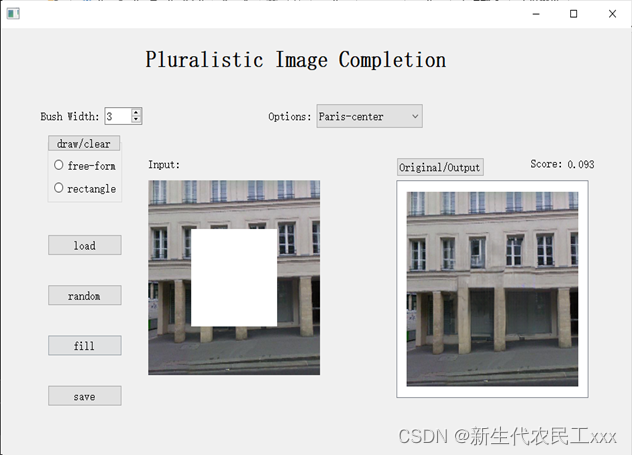
五、图像修复