
- 1NLP 基础知识大集合,java面试题最新
- 2[Xilinx]在JTAG下载器连接时FPGA不加载flash里的程序
- 3Git命令配置_git 编辑配置文件
- 4AI取名神器,让你的文章起名更轻松
- 5安卓TV开发(前言)— AndroidTV模拟器初识与搭建_安卓电视模拟器
- 6遥感图像计算机分类论文,(毕业设计论文)《遥感图像几种分类方法的比较》.doc...
- 7DSPC-PEG-聚丙烯酰胺/聚丁二烯/聚乙烯基咪唑/聚苯丙乳胶/聚醋酸乙烯酯_peg-dspc
- 8[iOS]Charles工具_charles ios
- 9将图片添加描述批量写入excel
- 10在vs code中使用git_visual studio code怎么配置git
Flash Attention稳定吗?Meta、哈佛发现其模型权重偏差呈现数量级波动
赞
踩
ChatGPT狂飙,世界已经不是之前的样子。
新建了免费的人工智能中文站https://ai.weoknow.com
新建了收费的人工智能中文站ai人工智能工具
每天给大家更新可用的国内可用chatGPT资源


更多资源欢迎关注

Meta FAIR 联合哈佛优化大规模机器学习时产生的数据偏差,提供了新的研究框架。
众所周知,大语言模型的训练常常需要数月的时间,使用数百乃至上千个 GPU。以 LLaMA2 70B 模型为例,其训练总共需要 1,720,320 GPU hours。由于这些工作负载的规模和复杂性,导致训练大模型存在着独特的系统性挑战。
最近,许多机构在训练 SOTA 生成式 AI 模型时报告了训练过程中的不稳定情况,它们通常以损失尖峰的形式出现,比如谷歌的 PaLM 模型训练过程中出现了多达 20 次的损失尖峰。
数值偏差是造成这种训练不稳定性的潜在原因,由于大语言模型训练运行成本极高,如何量化数值偏差俨然成为关键问题。
在最新的一项工作中,来自 Meta、哈佛大学的研究者开发了一个原则性定量方法来理解训练优化中的数值偏差,以此评估不同的最新优化技术,并确定它们在用于训练大模型时是否可能引入意外的不稳定性。

-
论文标题:Is Flash Attention Stable?
-
论文链接:https://arxiv.org/pdf/2405.02803
结果发现,在一次单独的前向传递过程中,Flash Attention 的数值偏差比 BF16 的 Baseline Attention 大一个数量级。
具体而言,该方法包括两个阶段,包括:
(1)开发一个微基准来扰动给定优化中的数值精度;
(2)通过基于 Wasserstein 距离的数据驱动分析评估数值偏差如何转化为模型权重的变化。
研究者分析了 SOTA 优化技术 Flash Attention ,并量化了可能引入的数值偏差。Flash Attention 是一种广泛用于加速注意力机制的技术,通常被认为是 Transformer 模型中的系统瓶颈。Flash Attention 在提高速度和减少内存访问量的同时,也依赖于算法优化,而算法优化有可能导致数值偏差的增加。
研究者假设添加重新缩放因子(rescaling factors )可能会引入无意的近似,导致数值折衷,这可能会在后续影响训练稳定性。
他们在多模态文本到图像工作负载的背景下分析了 Flash Attention,以确定 Flash Attention 与其基线之间数值偏差的潜在重要性。最终,他们引入了一个框架来量化训练优化的数值偏差及其下游影响。
研究者在数值偏差量化上主要作出了以下两点贡献:
(1)设计了一个微基准来分离数值精度对数值偏差的影响。
研究者所设计的微基准作为一种技术,用于衡量和量化传统黑盒优化(如 Flash Attention)所导致的数值偏差。通过扰动通常在提供的内核中不可用的方面,他们开创性地发现在低数值精度(BF16)下,与 Baseline Attention 相比,Flash Attention 的数值偏差大约高出一个数量级。
(2)基于 Wasserstein Distance 度量进行了数据驱动的分析。
通过该分析,研究者将观察到的数值偏差置于上下文,并为其对下游模型属性的影响形成一个上限(upper bound)。在研究者的案例研究中,他们能够限制观察到的数值偏差的影响,并发现:「Flash Attention 引入的模型权重偏差大约为低精度训练的 1/2 至 1/5 倍。」
这项研究强调了开发一种原则性方法的重要性:「不仅要量化,而且要将训练优化对数值偏差的影响置于上下文中。」通过构建代理(proxies)来将数值偏差置于上下文中,旨在推断通常难以衡量的下游模型效果(即训练不稳定性)的可能性。
实验方法
研究者首先开发了一个微基准来分离并研究 Flash Attention 引起的数值偏差。如图 2 所示,他们通过对 Flash Attention 进行数值上的重新实现,以分析不同的数值精度,并在算法的每个步骤应用潜在的优化措施。
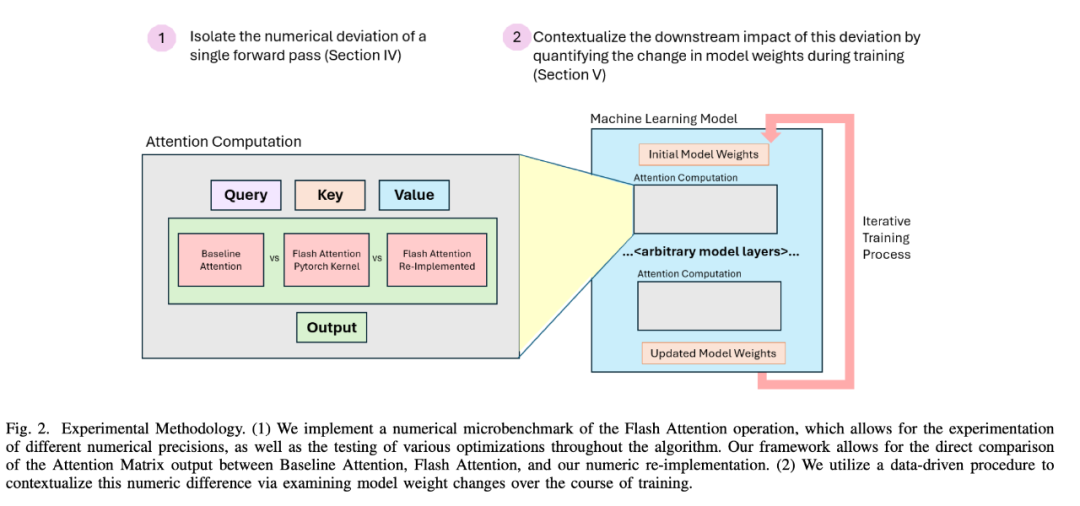
图 2: 微基准设计摘要。
这是必要的,因为 Flash Attention 内核目前仅支持 FP16 和 BF16 数值格式。该内核还是 CUDA 代码的包装 API 调用,这使得扰动算法以检查数值偏差的影响变得具有挑战性。
相比之下,他们的微基准设计允许在算法内部进行精度输入和修改。研究者将微基准与原始的 Flash Attention kernel 进行了验证。
他们进一步设计了一种技术,以比较模型执行过程中每个步骤的 Attention 矩阵的输出。并修改了模型代码,每次调用注意力时都计算 Baseline Attention 和 Flash Attention,这允许对相同的输入矩阵进行精确的输出矩阵比较。
为了将其置于上下文中,研究者还通过相同和独立的训练运行,使用 Max difference 和 Wasserstein Distance 度量来量化模型权重在整个训练过程中的差异。
对于训练实验,研究者则使用一种将文本输入转换为图像的生成式 AI workload(即文本到图像模型)。他们使用 Shutterstock 数据集重新训练模型,并在一组英伟达 80GB A100 GPU 集群上运行此实验。
通过微基准量化数值偏差
研究者首先分析了 Flash Attention 在前向传递过程中的影响。他们利用微基准测试,在随机初始化查询、键、值向量相同的情况下,检验不同数值精度对 Attention 计算的输出矩阵的影响。
正如图 3 所示,当研究者使用从 BF16 到 FP64 变化的不同数值格式时,Flash Attention 和 Baseline Attention 之间的数值偏差随着尾数位数的增加而减小。这表明数值差异是由于较少的尾数位数所固有的近似造成的。
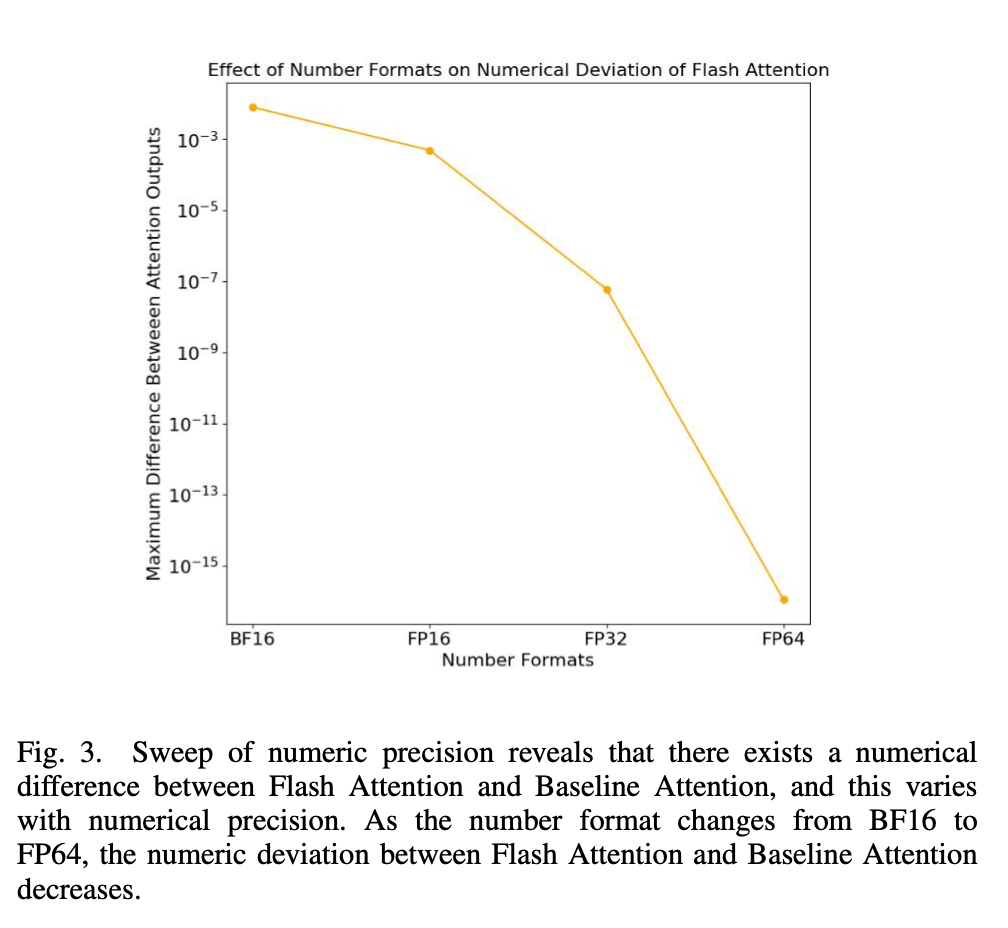
图 3:数值格式对于 Flash Attention 的数值偏差所产生的效果。
之后,研究者为进行标准比较,在 FP64 数值格式下的 Baseline Attention 设置了「黄金值」,然后将不同数值格式下的 Attention 输出与该值进行了比较(如图 4 所示)。

图 4:FP64 下 Baseline Attention「黄金值」的比较。
结果表明,Flash Attention 的数值偏差大约是在 BF16 下 Baseline 的 10 倍。
为了进一步分析这种观察到的数值偏差,研究者保持 tile 大小和 SRAM 大小不变的同时,扫描了矩阵的序列长度(如图 5 所示)。
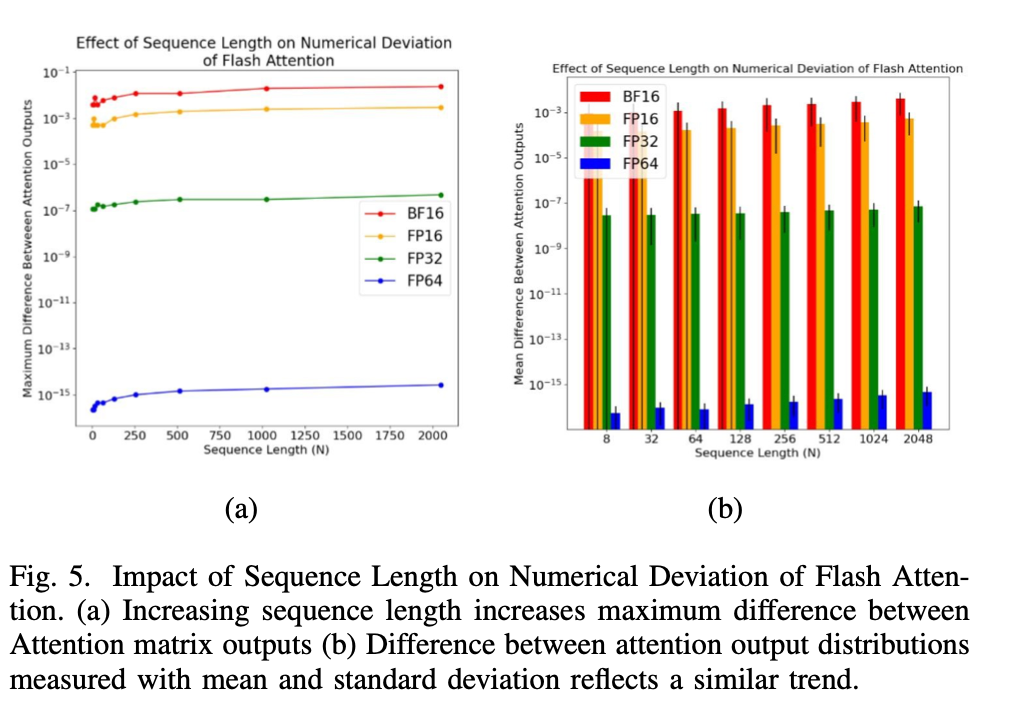
图 5: 序列长度对 Flash Attention 数值偏差的影响。
如图所示,随着序列长度的增加,无论是通过(a)最大差异上限的测量,还是通过(b)差异的平均值和标准差的测量,Flash Attention 和 Baseline Attention 之间的数值偏差都在增加。
除此之外,研究者还利用微基准设计进行不同优化的实验,以便更好地了解数值偏差的影响(如图 6 所示)。
图 6a 显示了调换 block 维数的顺序如何导致 Flash Attention 和 Baseline Attention 之间的数值差异增大。图 6b 中的其他扰动,比如限制 tile 大小为正方形,不会对数值偏差产生影响。图 6c 表明了 block/tile 大小越大,数值偏差越小。
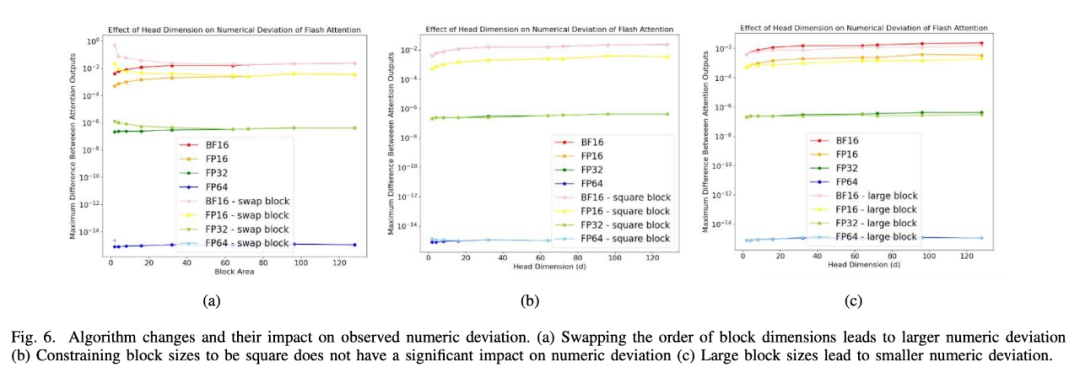
图 6: 算法的改变及其对观察到的数值偏差的影响。
通过权重差异来了解数值偏差
虽然在前向传递过程中,Flash Attention 可能会导致 Attention 输出的数值偏差,但这项研究的最终目标是确定这是否会在模型训练过程中产生任何影响,以研究它是否会导致训练的不稳定性。
因此,研究者希望量化 Flash Attention 是否在训练过程中改变了模型,即上文观察到的 Attention 输出差异是否反映在训练过程中更新的模型权重中。
研究者利用两个指标来衡量使用 Baseline Attention 训练的模型与使用 Flash Attention 训练的模型之间的模型权重差异。首先计算最大差异,即找出权重矩阵之间差异的绝对值并取最大值,从而得出偏差的上限,如下所示:
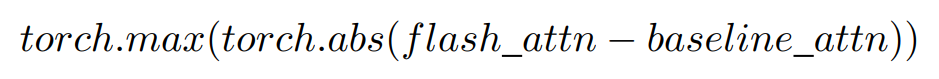
虽然最大差值提供了数值偏差的上限,但它没有考虑到每个矩阵的分布情况。因此,研究者通过 Wasserstein Distance 来量化权重差异,这是衡量张量之间相似性的常用度量。虽然在计算上稍显复杂,但 Wasserstein Distance 包含了张量分布的形状信息以衡量相似性。计算公式概述如下:
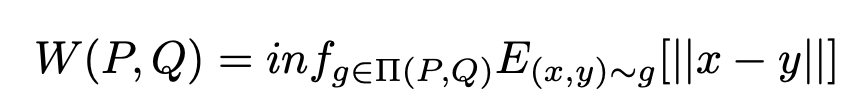
数值越低,表明矩阵之间的相似度越高。
利用这两个指标,研究者随后量化了在整个训练过程中与 Baseline Attention 相比,Flash Attention 的模型权重是如何变化的:
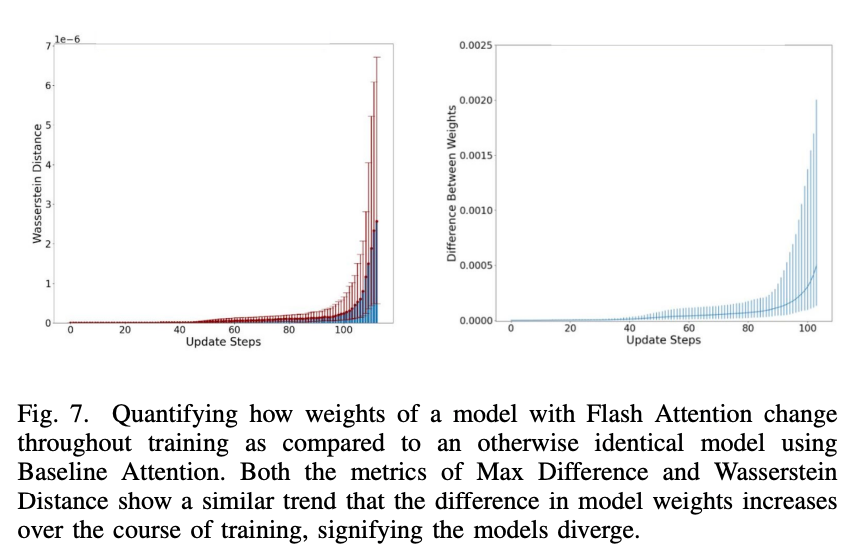
根据 Wasserstein Distance 和 Max Difference 这两个指标,在整个训练过程中,Flash Attention 的加入确实改变了模型权重,而且随着训练的继续,这种差异只会越来越大,这表明了使用 Flash Attention 训练的模型与使用 Baseline Attention 训练的相同模型收敛到了不同的模型。
然而,训练是一个随机过程,某些模型结构的改变可能会在下游效应和准确性方面产生相似的结果。即使使用 Flash Attention 和 Baseline Attention 训练的模型权重不同,这也是值得关注的。
完全训练模型并评估准确性是一项成本昂贵且资源密集的任务,特别是对于训练需要数月的大模型来说。
研究者通过配置一个 proxy 来探寻:
(a) 这些权重变化的意义有多大?
(b) 能否将其与其他广泛采用的训练优化中的标准权重变化联系起来?
为了实现这一目标,研究者设计了一系列实验来比较在不同场景下,训练过程中的权重差异是如何变化的。
除了对比使用 Flash Attention 和 Baseline Attention 的训练过程外,他们还量化了在训练开始时权重被初始化为不同随机值的相同训练过程中的权重差异。这提供了一个界限,因为随机权重初始化是一种常用的技术,并且通常会产生等效的结果。
此外,研究者还测量了使用不同精度训练的模型权重的变化。数值精度(即 FP16 与 FP32)有可能导致下游变化,这作为确定了 Flash Attention 权重重要性的一个上限。
如图 8 所示,可以发现,使用 Flash Attention 的模型权重偏差变化率与不同模型初始化的权重偏差变化率相当或更小(注意红色和蓝色曲线的斜率)。
此外,使用 FP16 与 FP32 时的权重变化率比不同模型初始化时的权重变化率更高,变化也更大。
这些结果提供了一个 proxy,并表明:「虽然 Flash Attention 会出现数值偏差,但它会被随机模型初始化和低精度训练所限制。而且所引入的模型权重偏差大约是低精度训练时的 1/2 至 1/5 倍。」
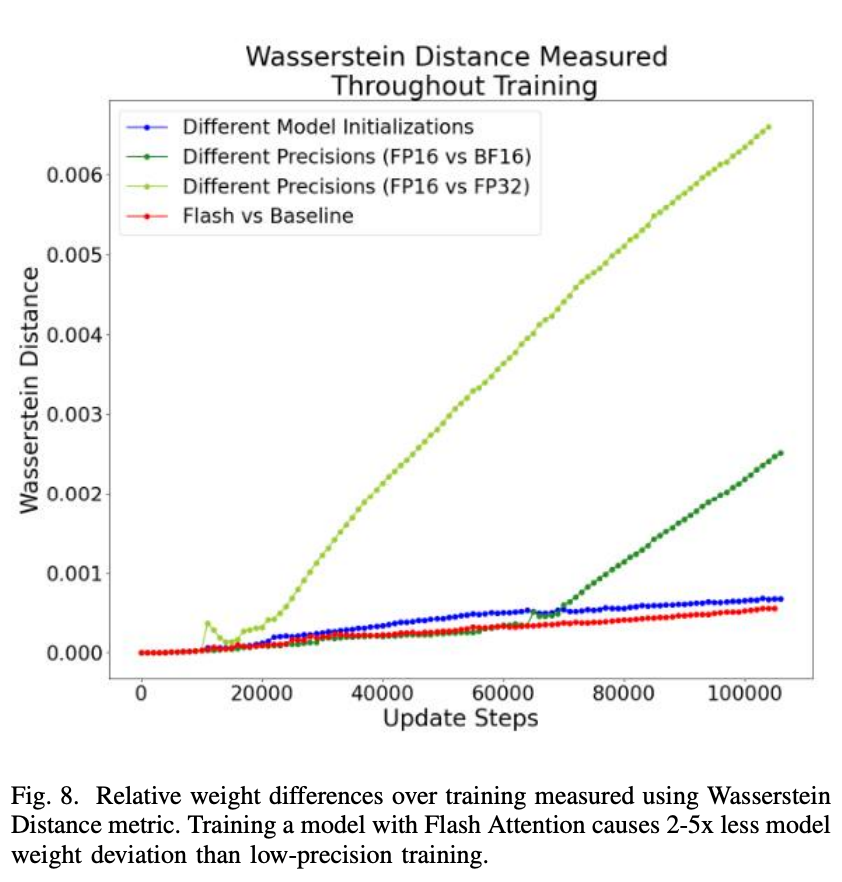
图 8: 使用 Wasserstein Distance metric 测量的训练过程中的相对权重差异。
更多研究细节,可
ChatGPT狂飙,世界已经不是之前的样子。
新建了免费的人工智能中文站https://ai.weoknow.com
新建了收费的人工智能中文站ai人工智能工具
每天给大家更新可用的国内可用chatGPT资源
更多资源欢迎关注

