
热门标签
热门文章
- 1vue基础02_vue向上取整
- 2如何保证线程安全?synchronized,ReentrantLock,Atomic使用场景_synchronized renntrantlock 应用场景举例
- 3解决:Direct local .aar file dependencies are not supported when building an AAR._previous versions of the android gradle plugin pro
- 4无人反制系统基础理论概述
- 5PyTorch学习笔记——PyTorch模块和基础实战_pytorch pywt.dwt2
- 63d gaussian splatting介绍整理_colmap+3dgs的具体流程是什么?
- 7php检测数据库是否连接,测试数据库是否连接成功
- 8云服务器搭建配置以及服务器开发相关_cloub server development
- 9第四课:IP核调用之计数器
- 10C/C++数据结构:时间复杂度_c++时间复杂度
当前位置: article > 正文
基于各种机器学习和深度学习的中文微博情感分析
作者:小小林熬夜学编程 | 2024-05-25 23:05:43
赞
踩
微博情感评论语料库在哪

- 来源:机器学习AI算法工程
- 本文约600字,建议阅读5分钟
- 本文中,我们介绍了中文微博情感分析的情况。
中文微博情感分类语料库
"情感分析"是我本科的毕业设计,也是我入门并爱上NLP的项目hhh,当时网上相关语料库的质量都太低了,索性就自己写了个爬虫,一边标注一边爬,现在就把它发出来供大家交流。因为是自己的项目,所以标注是相当认真的,还请了朋友帮忙校验,过滤掉了广告/太短/太长/表意不明等语料,语料质量是绝对可以保证的。
带情感标注的微博语料数量: 10000(train.txt)+500(test.txt)
数据格式
文档的每一行代表一条语料。
每条语料的第一个数据为微博对应的mid,是每条微博的唯一标签,可以通过"https://m.weibo.cn/status/" + mid 访问到该条微博的网页(部分微博可能已被博主删除)。
第二个数据为情感标签,0表示负面,1表示正面。
项目说明
训练集10000条语料,测试集500条语料。
使用朴素贝叶斯、SVM、XGBoost、LSTM和Bert,等多种模型搭建并训练二分类模型。
前3个模型都采用端到端的训练方法。
LSTM先预训练得到Word2Vec词向量,在训练神经网络。
Bert使用的是哈工大的预训练模型,用Bert的[CLS]位输出在一个下游网络上进行finetune。预训练模型需要自行下载。
下载后将文件夹放在./model文件夹下,并将bert_config.json改名为config.json。
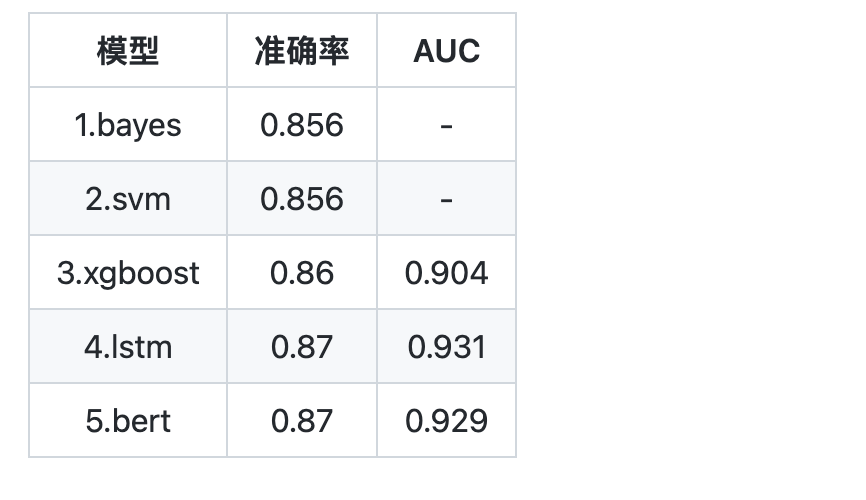
实验结果
各种分类器在测试集上的测试结果:
项目资料:
基于情感词典、k-NN、Bayes、最大熵、SVM的情感分析
https://github.com/chaoming0625/SentimentPolarityAnalysis
风险事件文本分类(达观杯Rank4)
https://github.com/DA-southampton/DaguanFengxian
- 编辑:王菁
- 校对:林亦霖
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/小小林熬夜学编程/article/detail/624077
推荐阅读
相关标签

