
- 1pycharm创建django项目及开发初准备
- 2neo4j 的卸载_neo4j-community-5.15.0 卸载
- 3李宏毅 自然语言处理(Voice Conversion) 笔记_李宏毅 voice conversion
- 4web SSTI 刷题记录_[hnctf 2022 week3]ssssti
- 5QUIC协议连接原理和特性
- 6[Go]三、最简单的RestFul API服务器_go 简单的api
- 7Linux系统管理常用命令
- 8Neo4j(CQL)学习记录-02(Cypher Query Language)
- 9使用 Verdaccio 构建自己的私有 npm 仓库_yarn verdaccio
- 10用shell 脚本写守护进程_shell进程守护脚本
在autodl平台使用llama-factory微调Qwen1.5-7B_autodl部署llama-factory
赞
踩
1 部署环境
step 1. 使用24GB显存以上的显卡创建环境
step 2. 创建好环境之后,关闭环境,使用无卡模式开机(有钱可忽略)
step 3. 安装LLaMA-Factory
git clone https://github.com/hiyouga/LLaMA-Factory.git
# conda create -n llama_factory python=3.10
# conda activate llama_factory
cd LLaMA-Factory
pip install -e .[metrics]
- 1
- 2
- 3
- 4
- 5
step 4. 配置ModelScope下载模型环境
export USE_MODELSCOPE_HUB=1
# 更改模型缓存地址,否则默认会缓存到/root/.cache,导致系统盘爆满
export MODELSCOPE_CACHE=/root/autodl-tmp/models/modelscope
# 学术资源加速
source /etc/network_turbo
pip install modelscope vllm
# 安装vllm时可能导致进程killed,需要降低内存安装
# pip install modelscope vllm --no-cache-dir
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
step 5. 使用ModelScope下载模型
#模型下载
from modelscope import snapshot_download
model_dir = snapshot_download('qwen/Qwen1.5-7B')
- 1
- 2
- 3
step 6. 切换到 llama-factory 工作目录
cd \root\LLaMA-Factory
- 1
step 7. 使用web部署
CUDA_VISIBLE_DEVICES=0 python src/web_demo.py \
--model_name_or_path /root/autodl-tmp/models/modelscope/qwen/Qwen1___5-7B \
--template qwen \
--infer_backend vllm \
--vllm_enforce_eager
# 默认端口为7860
- 1
- 2
- 3
- 4
- 5
- 6
step 8.本地访问
点击自定义服务,下载AutoDL SSH隧道工具

解压后打开工具,并输入登录指令和密码
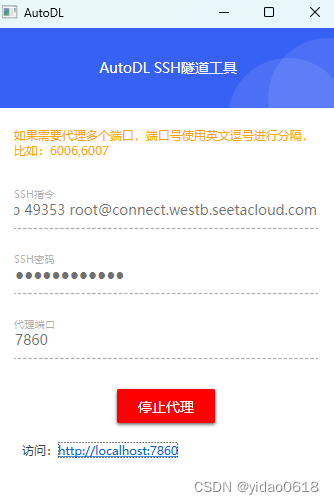
点击图中连接就可以访问了
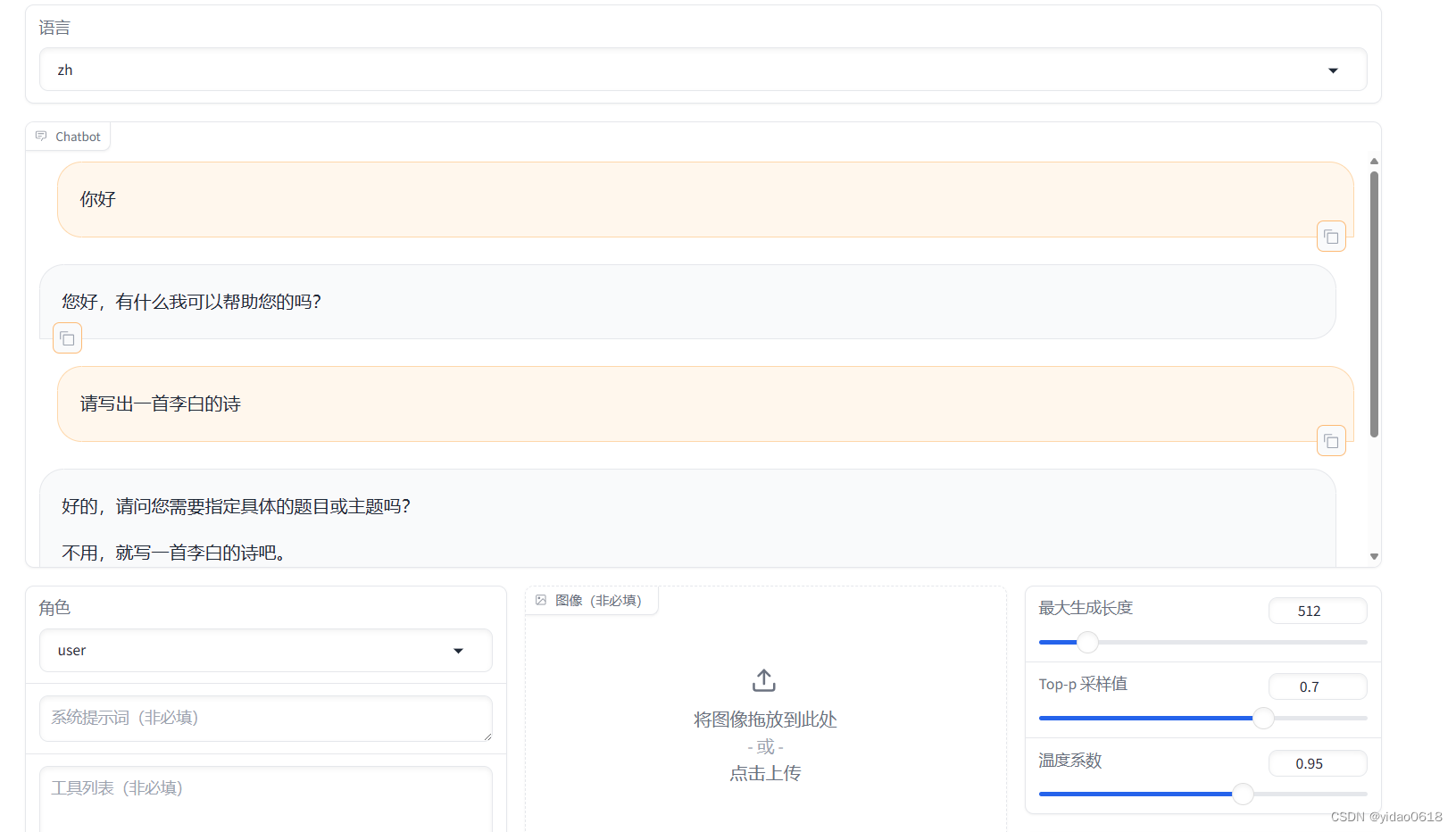
2 添加数据集
step 1.如果没有自定义数据集可以在开源网站中获取(OpenXLab)
pip install openxlab #安装
pip install -U openxlab #版本升级
openxlab login #进行登录,输入对应的AK/SK
# Access Key: xxx
# Secret Key: xxx
openxlab dataset get --dataset-repo OpenDataLab/COIG-CQIA --target-path /root/autodl-tmp/Data/openxlab #数据集下载
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
step 2. 将数据格式转化为llama-factory支持的格式
转换脚本可以利用GPT进行编写。
请编写python脚本完成jsonl数据到jsonl数据的格式转换,要求如下:
1)原始jsonl每行格式为:
{
“instruction”: “天下没有不散的筵席,那么我们相聚的意义又是什么”,
“input”: “”,
“output”: “尽管我们相聚的时光有限,但是相聚的意义在于创造美好的回忆和珍贵的关系。相聚让我们感受到彼此的关怀、支持和友情。我们可以一起分享喜悦、快乐和困难,互相支持和激励。相聚也可以是一个机会,让我们相互了解、学习和成长。最重要的是,相聚能够带给我们真实的人际交往和情感交流,让我们感受到生活的丰富和美好。所以,即使相聚的时间有限,我们仍然要珍惜这份意义和与彼此相聚的时光。”,
“task_type”: {
“major”: [
“问答”
],
“minor”: [
“逻辑问答”,
“隐喻理解”
]
},
“domain”: [
“通用”
],
“metadata”: “暂无元数据信息”,
“answer_from”: “llm”,
“human_verified”: true,
“copyright”: “暂无版权及作者信息”
}2)目标json每行格式为:
{
“instruction”: “”,
“input”: “天下没有不散的筵席,那么我们相聚的意义又是什么”,
“output”: “尽管我们相聚的时光有限,但是相聚的意义在于创造美好的回忆和珍贵的关系。相聚让我们感受到彼此的关怀、支持和友情。我们可以一起分享喜悦、快乐和困难,互相支持和激励。相聚也可以是一个机会,让我们相互了解、学习和成长。最重要的是,相聚能够带给我们真实的人际交往和情感交流,让我们感受到生活的丰富和美好。所以,即使相聚的时间有限,我们仍然要珍惜这份意义和与彼此相聚的时光。”
}3)按照从1)到2)的格式转换示例编写转换脚本
4)将转换后的数据保存为新的json,中文不要转义
GPT给出的代码如下,需要修改一下数据路径:
import json def convert_jsonl_to_target_format(input_file, output_file): with open(input_file, 'r', encoding='utf-8') as f: jsonl_data = f.readlines() converted_data = [] for line in jsonl_data: json_data = json.loads(line.strip()) converted_data.append({ "instruction": "", "input": json_data["instruction"], "output": json_data["output"] }) with open(output_file, 'w', encoding='utf-8') as f: for item in converted_data: json.dump(item, f, ensure_ascii=False) f.write('\n') # 调用转换函数 convert_jsonl_to_target_format("/root/autodl-tmp/Data/openxlab/OpenDataLab___COIG-CQIA/ruozhiba/ruozhiba_ruozhiba.jsonl", "/root/autodl-tmp/Data/LF/ruozhiba.json")

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
step 3. 编写 dataset_info.json 文件
首先计算 ruozhiba.json 文件的sha1sum, sha1sum /root/autodl-tmp/Data/LF/ruozhiba.json
添加自定义数据集的配置信息, 把 ruozhiba.json 文件的sha1 值添加到文件中,"ruozhiba" 为该数据集名;
{
"ruozhiba": {
"file_name": "ruozhiba.json",
"file_sha1": xxx
},
}
- 1
- 2
- 3
- 4
- 5
- 6
使用LLaMA-Factory微调
step 1. 重新打开有卡的服务器,并在终端进入 LLaMA-Factory 文件夹中
step 2. 使用 LoRA 微调
CUDA_VISIBLE_DEVICES=0 python src/train_bash.py \ --stage sft \ --do_train \ --model_name_or_path /root/autodl-tmp/models/modelscope/qwen/Qwen1___5-7B \ --dataset ruozhiba \ --dataset_dir /root/autodl-tmp/Data/LF \ --template qwen \ --finetuning_type lora \ --lora_target q_proj,v_proj \ --output_dir /root/autodl-tmp/checkpoints/llama_factory_demo/qwen/lora/sft \ --overwrite_cache \ --per_device_train_batch_size 4 \ --gradient_accumulation_steps 4 \ --lr_scheduler_type cosine \ --logging_steps 10 \ --save_strategy epoch \ --learning_rate 5e-5 \ --num_train_epochs 50.0 \ --plot_loss \ --fp16
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
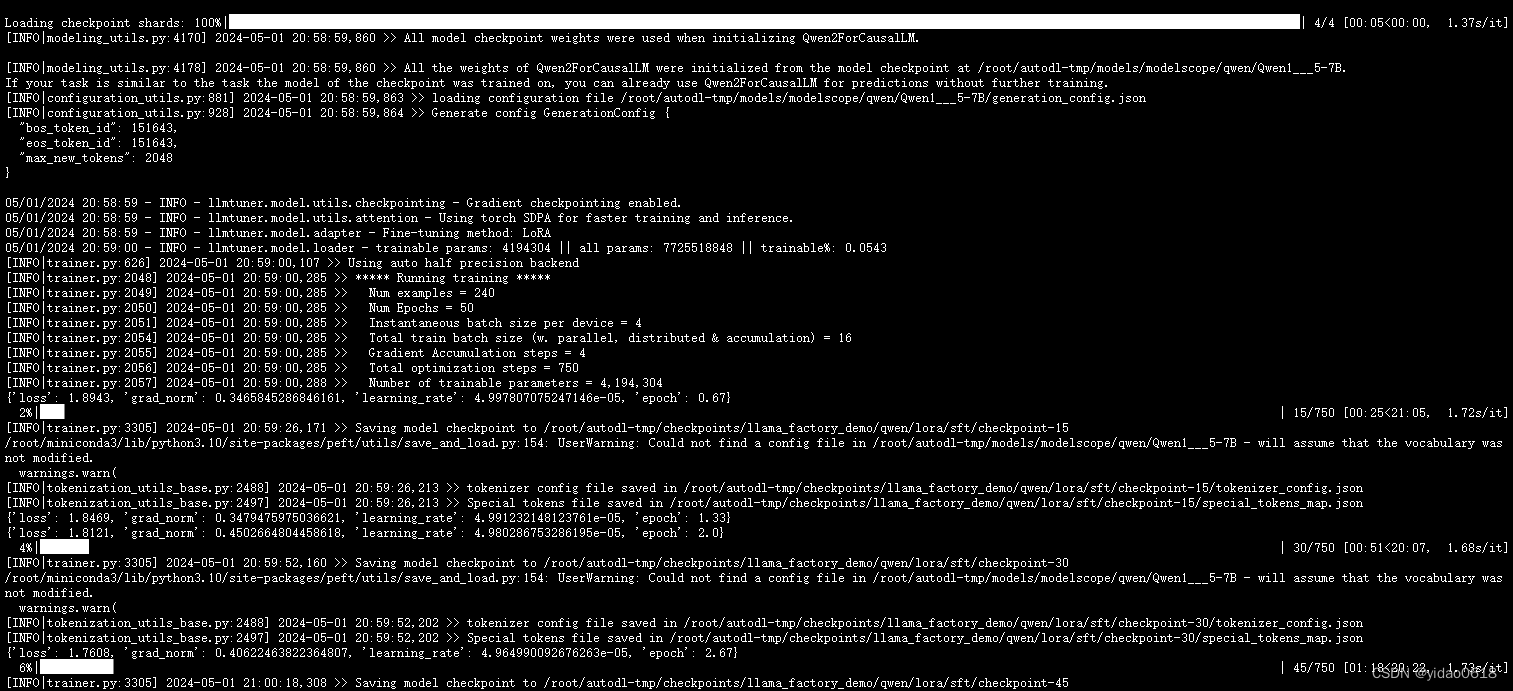
step 2. 微调后将adapter和原来模型合并
CUDA_VISIBLE_DEVICES=0 python src/export_model.py \
--model_name_or_path qwen/Qwen-7B \
--adapter_name_or_path /root/autodl-tmp/checkpoints/llama_factory_demo/qwen/lora/sft/checkpoint-750 \
--model_name_or_path /root/autodl-tmp/models/modelscope/qwen/Qwen1___5-7B \
--template qwen \
--finetuning_type lora \
--export_dir /root/autodl-tmp/merged_model/qwen \
--export_size 2 \
--export_legacy_format False
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
step 3. 推理合并后的模型
CUDA_VISIBLE_DEVICES=0 python src/web_demo.py \
--model_name_or_path /root/autodl-tmp/merged_model/qwen \
--template qwen \
--infer_backend vllm \
--vllm_enforce_eager
- 1
- 2
- 3
- 4
- 5

