
- 1Numpy数组中数据的排序【sort(),argsort()与 lexsort()】 (Numpy篇-13)_numpy中数组的方法sort,argsort,lexsort
- 2GPU与CPU的性能比较及影响因素_gpu比cpu快多少
- 3【视频文稿】车载Android应用开发与分析 - 走进车载操作系统_adstudy车载测试视频csdn
- 4Llama 3 五一超级课堂 笔记 ==> 第五节、Llama 3 Agent 能力体验与微调_llama3 支持agent吗
- 5如何制作自己的数字人
- 6【MySQL】 锁机制:InnoDB引擎中锁分类以及表锁、行锁、页锁详解
- 7[立创泰山派]RK3566 buildroot添加qt5运行环境_rk3566 qt
- 8【FAQ】解决org.json.JSONException: JSONArray[0] is not a JSONArray._jsonarray[0] is not a jsonobject
- 9一款非常好看好用的Linux操作系统中国发行版_linux好看的版本
- 10【小5聊】Sql Server基础使用之SHOWPLAN permission denied in database_showplan permission denied in database 'cam'.
如何看待 2022 年秋招算法岗人间地狱?
赞
踩
来源:知乎
文章转载自知乎,著作权归属原作者,侵删
Dr.Wu(NLP搬砖师,就职于微软亚研)回答:
结合最近几天的热点,所谓的“AILab”名存实亡,和在工业界Research Lab 实习+工作8年的经历,我好想好好答这个题。
一切的最开始,请明白你自己想成为研究员还是算法工程师,对于junior的同学们两个角色并不互通,对senior是互通的,可能因为主要靠管理技能吧 = =
研究员:追求关键问题突破,希望研究出Resnet、BERT。影响力大于一切。优点:压力小一些,听起来酷一些,有退路去高校。缺点:门槛太高,对公司没啥用,可能会被砍。
算法工程师:追求应用已有算法在业务。业务价值大于一切。优点:岗位门槛低,如果核心业务做的好,上升通道快,带团队机会大。缺点:辛苦,容易拥抱业务变化,业务的运气因素很影响个人发展。
如果选定了,请坚定不移的为之努力,并且尽量避免去业务部门发paper,或者在研究部门做杂活这种角色,那样很拧巴也不持久。也避免来回横跳,职业生涯是一场投资,一步步积攒。如果是研究员要追求业界的同行之间的影响力,算法工程师请选对业务,选对业务成功了一半多。
我其实对中国未来ailab们的发展是有信心的
1、因为国际关系问题,对技术的投资是政治正确的。
2、其实也花不了多少钱养一个research team,相比大公司的营收
3、Research team对公司的广告效应,和吸引人才还是有帮助
4、技术是颗科技树,很多时候摘果子的时候,是因为树干已经足够粗壮了。
所以,新毕业的同学们完全不要听风就是雨,觉得各个公司ailab都黄了。想成为researcher的同学们,完全可以去ailab认真做研究(别灌水)。
千万不要被最近几天AILab都名存实亡的错误舆论影响。虽然有些公司的lab据我所知是发展的不好,但业界还是有很不错的ailab。
最后给大家个工作2年多的感想吧,对于走研究员track的,想挣钱去阿里、字节,很有竞争力;想踏踏实实做做研究,去腾讯和微软。Follow your heart,不要被舆论影响,公司Ailab的兴衰更多的和公司本身的发展相关,如果公司一直盈利,业务没问题,ailab不会挂的。
最后,我不太喜欢ailab这个名字,research lab可能更正确。

谢流远(深度学习优秀答主)回答:
好像没人提一个事:算法部门的人地矛盾越来越激烈了。
ai发展依赖算力增长,但是近年来单卡算力增长放慢,大家开始扩大分布式,结果是调研需要的资源越来越多。同时算法工程师也越招越多,每个人能分到的实验次数越来越少,有的地方一个人平均一个月开不了一次实验,人地矛盾突出,能有多少产出取决于能抢到多少资源。
求职卷,进来了做实验也卷,卷翻天。

郑华滨(商汤CV研究员)回答:
看到解大
@谢流远
的回答提到了算法部门的“人地矛盾”,我也来贡献一个观察到的矛盾点:汇报宣传时高大上的算法模型,与实际干活时主导成败的脏活累活之间的矛盾。理解了这个矛盾,一定程度上就可以解释,为什么一方面很多学生觉得算法岗很难找,另一方面企业又总是吐槽算法岗很难招了。
有很大一部分算法从业人员,在尚未深入一线业务落地的时候,接触到的最多的信息就是各种高大上的算法模型。大家喜欢兴致勃勃地谈论最近又出了一个什么魔改变形金刚,又出了什么即插即用的涨点神器,ImageNet又被刷爆了,XXX又被屠榜了,PapersWithCode某个Leaderboard右上角又冒出一个新的SOTA散点了,超大模型的参数量破万亿了……他们对于AI技术的理解主要来自于一篇篇顶会论文上的漂亮故事,或者是各大公众号上花团锦簇的PR稿。其中功力较为深厚者,对各种网络结构、训练技巧如数家珍,能对某个领域近年来代表模型的演进路线侃侃而谈,各种设计的insight也能阐述一二。
我说的这部分从业人员,不仅仅包括实验室里的学生,还包括一部分已经身在企业、但是偏中后台技术支持的算法工程师。事实上,一两年前的我也是这样的认知。
但是当这部分从业人员深入一线业务之后,就会发现,算法模型在实际工作中可能只占20%,剩下80%的时间都在围绕着数据做很多脏活累活。在一些成熟任务上如简单的图像分类,算法模型占据的比例可能会更少。他们会发现自己熟知的那些”黑科技“其实作用有限,有时候费了很大劲,把三年前的技术换成上个月的技术,性能也就提升了一小截,而且就到此为止了。当然,有野心的算法工程师会想,我上我也行!我也要来魔改网络结构,拼凑训练技巧,在自家业务上提点!不过这种尝试往往不是以失败告终,就是只提升了可怜的零点几个点,也许还不如毫无技术含量地调调几个超参数。
与之相反,对数据的处理往往可以带来大幅度的、持续的提升,可行的手段除了粗暴地标注更多样本,还包括重新审视原有的标注规则是否合理,现有数据集标注质量如何,要不要定义一些细粒度的类别来辅助模型学会更微妙的语义,当前的模型经常在哪些场景下出问题,能不能从其他数据渠道补充这些场景的样本……上面列举的还只是一些粗糙的思路,很多一线干活的算法工程师肯定还能举出更针对具体任务、具体场景的操作,比如做NLP的朋友就告诉我实际工作中”正则表达式yyds“,当然这种经验在CV任务上就没什么大用了。
于是,实事求是的算法工程师开始深入一线之后,顶着业务指标的压力,很快就会用脚投票,不再花费过多精力在算法模型上,而是老老实实把一些数据上的工作做好,因为他们知道,算法模型不关键,follow最新的黑科技只是锦上添花,唯有数据才决定了业务落地的成败。
但是问题就来了,算法工程师做完这些脏活累活,达成了业务指标,等到向上汇报、对外宣传的时候却傻眼了。有些领导并不关心你做了多少实在的工作,只想听到你用了什么最新技术;有些领导尽管明白业务落地的关键在哪里,精力应该放在什么环节,知道但架不住总还有更上面的领导,要求在汇报中体现出「技术水平」;就算上层领导确实很懂行,但又架不住对外宣传的时候,也没办法把那些实际的工作讲出花来,必须包装成花里胡哨的先进技术,才能体现自家的技术壁垒,对群众秀肌肉,对同行放烟雾弹。
这样一层层压力传导下来,一线的算法工程师难免就会动作走形,甚至会慢慢形成「双重思想」:实际干活时用的都是简单粗暴有效的东西,汇报宣传时又要强行包装出一个又一个fancy的故事。
既然形势如此,很多聪明人就会慢慢拥抱这种评价体系,不管实际干活的时候怎么玩,最后一定会想方设法讲故事、发论文,企业会拿着这些「先进技术」出去宣传,各种AI自媒体也乐见其成。于是很多尚未深入一线的从业者每天看到的,就都是各种高大上的算法模型,为了跟上潮流,他们也卯足了力气卷这些东西,凑成一份份光彩夺目的简历送到面试官手上。可是这个时候,一线出身的面试官可能又开始「双重思想」了:业界平常大力鼓吹的是这些东西没错,但你是要来实际干活的,我得考察你实际干活的能力如何,不然来了拖后腿,团队业绩不达标,我们也有压力啊!
于是,招人时实际考察的,与平日里大力鼓吹的,就产生了脱节。
而且这种脱节有愈演愈烈之势,因为追求高大上的业界舆论影响汇报宣传的导向,汇报宣传的压力又反过来诱导出更多高大上的算法模型,会形成一个正反馈的闭环;而另一方面,即使算法工程师从业务中打磨出了简单粗暴有效的方法,也缺乏汇报宣传这两条重要的内外渠道获得足够的激励,形不成正反馈,散落的单点进步无法连成一片,就会被一直雪藏在算法工程师自己的脑中。
可以把上述逻辑总结为这么一张图:
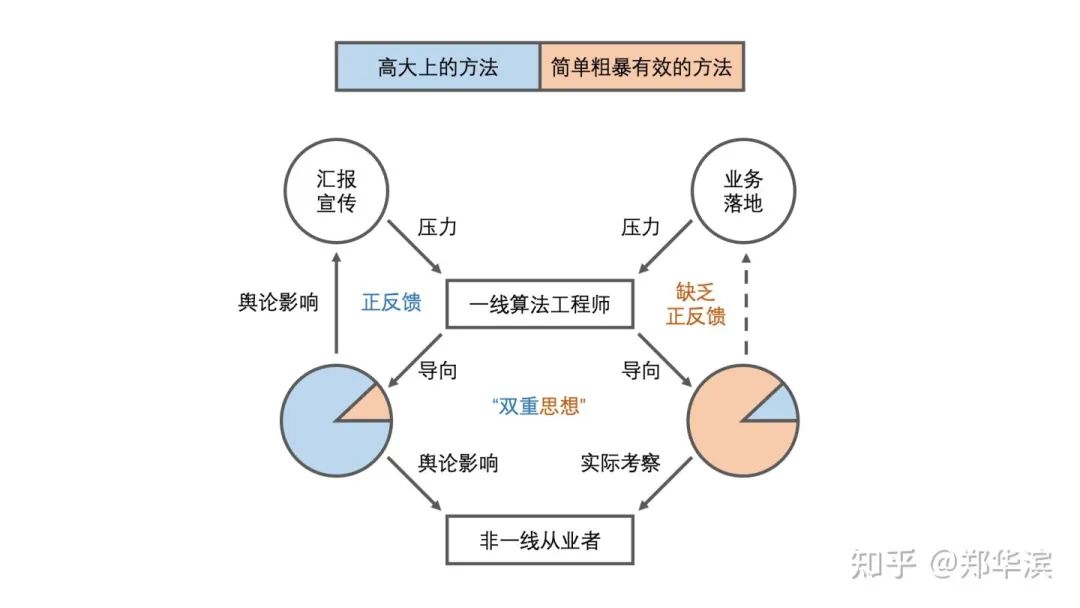
当然,这些只是我的一家之言,有不同观察或意见的话,欢迎在评论区留言。

匿名用户回答:
很快大家就会用脚投票选不选算法。
如今互联网显然已经进入红海期,人快手字节都不大小周了,你以为真是人大发善心吗?是过了无脑增长,处于内部改进增效的时候了。(怎么增效呢?精简机构和人员,我相信你学过。)
算法现在无非就搜广推还有些cv,分单什么的。现在dnn发展到transformer阶段,提升的点其实已经越来越少。之前的算法,随便搞个数据喂一喂就能有很大提升,现在呢?有些人可能会说,高深的算法工程师结合业务,嘻嘻,那跟你发了多少论文,撸模型多强有啥关系?结合业务的,开发工程师就不能做?
现在基本上已经算法开发同酬了。你搞算法,要顶会,要比赛,要清北,要博士,何必陷入这种机致内卷的环境中?算法就业地区也很受限制,你做算法,就意味着以后要在一线买房生活工作。无他,很多二线算法岗都没有。开发哪里都需要,很多业务系统都要有人维护,实实在在的常青树,以后还可以上岸考公对口。
现在ai四小龙都活的很艰难,对于我们普罗大众来说,何必跟这些清北,博士卷来卷去,自讨苦吃?你看着现在小盆友个个顶会难道心中不慌?
看看国外,做算法的属于research scientist,基本就博士做。别的都是做sde的。
再看看今年zhihu热榜,清北博士一年毕业人数,以及各大人工智能班毕业人数,我相信你知道怎么办。
当然,你要是什么icml nips pami随便发,那你选啥都不要紧,因为你是强者,没有的话就另当别论吧。

夕风Twilighty(布朗大学,理学硕士)回答:
算法岗这个东西在国内互联网IT业界不是新事物了,像MSRA和百度这种老牌AI劲旅,从本世纪初就已开始深耕所谓的AI“算法”领域。但是就毕业生市场的“火热”程度而言,2015-2018年算是第一次需求高峰期,这一是得益于DL在全球工业界实打实地创造了一波收益,各大名企纷纷“抢人”以建立技术后备军;二是以AlphaGo, Transformer为代表的一众学术突破刷爆了存在感,从2015年开始,用机器学习和深度学习炒菜几乎就是各大工科细分领域(不限于纯粹的计算机界)的财富密码;三是硬件算力提升以及随之而来的Theano, Tensorflow等DL框架的出现大幅降低了入门学习乃至后续深入研究的时间成本;由此,算法岗以毋庸置疑的高门槛和高待遇,跻身校招技术岗的就业鄙视链顶端,并逐渐成为内卷红海,是自然而必然的事情。
据我观察,自18年之后网上对算法岗“劝退”和祛魅的声音就逐渐多起来了,这一方面是由于工业界的萝卜坑不再大幅增长,15-18年以AI四小龙(主要是搞CV的商汤旷视等)和阿里达摩院为代表的一众“高纯度”萝卜坑提供商,在2021年的今天看来都有些后劲不足的味道[1];另一方面,当下学术界和工业界所看重的能力矩阵也出现了一些不同,一般地说,学术界更看重硕博同学将idea的故事讲好、并将这个idea用严谨专业的实验结论支撑起来的能力,而工业界则愈发注重实际工程中落地、处理“脏”问题的能力。这种能力要求的不同,在前些年是可以忽略的,因为在当时所谓“神经网络”对绝大多数在校生还是个新鲜玩意,一个候选人有基本的代码能力、合格的ML\DL知识储备就已经很了不起了。而现在的同学要去竞争算法岗,要么需要用足够分量的paper来为自己的学术水准背书,要么则需要拿出很有说服力的实习经历、工程项目经历,这些都不是在学校实验室里“按部就班”就能做到的。
但是有必要唱衰算法岗,有必要无脑劝退吗?没有必要。因为岗位的选择说到底都是一个小马过河的事情,科班出身、coding能力过硬、实验室经历丰富、同时也有大厂算法实习经验的同学,面前仍然摆着大量的机会。但对于基础知识不很牢固(比如临时转专业方向)、相关经历比较欠缺,但眼下又面临就业窗口的一些同学而言,建议还是冷静看待算法岗与非算法岗之间的差异。这既不是“劝退”也不是“打鸡血”,只是说要实事求是,稳扎稳打。
其实仔细分析目前的行情,算法岗明显存在着“理论”和“工程”的两极化,“理论”性高(也就是上面所说“高纯度”)的岗位,一是需求基本见顶,二是门槛水涨船高,曾经硕士生卷一把就能来的岗位,现在可能都是在那些手握一众顶会的博士中筛选了。而至于更偏向“工程”的岗位,CV和NLP岗经历了15-18年那个时期的野蛮生长之后,目前可以说处在一个整合和沉淀的阶段,未来一段时间内的岗位增长和内卷下降,恐怕会是很有限的。而更靠近一线业务的搜广推(搜索、广告、推荐)作为互联网的cash cow,还是提供了不少的就业机会,对于那些实际项目经验丰富,同时也具备过硬知识基础的同学而言,仍然是一个值得进入的赛道。
参考
^https://www.jiemian.com/article/5889079.html
地址:
https://www.zhihu.com/question/453325429
——The End——



