
- 1ChatGPT深度科研应用、数据分析及机器学习、AI绘图与高效论文撰写_人工智能(包括chatgpt)文案编写、自动化编程、数据分析与ai绘画技巧应用实践
- 2[CentOS]离线安装gcc/gcc-c++-_gcc-c++-4.8.5-44 下载
- 3陶哲轩:AI让业余数学家也能做出贡献
- 4NameError: name xxxxxx is not defined
- 5解决nginx到后端服务器Connection: close问题_nginx connection close
- 6PaddleOCR 实现车牌识别----利用PaddleOCR训练车牌识别数据_未完待续_paddleocr车牌识别训练
- 7python编写函数add求和_Python进阶之函数式编程
- 8Java面向对象 - 类与对象_据提示,在右侧编辑器begin-end处补充代码: 声明一个dog类,给dog类添加三个string
- 9达梦数据库安装和实例创建_达梦8如何创建数据库
- 10SQL的主键和外键约束_不能更改列学号用于表1选课的外键约束学号‘’
redis深入学习_深入redis
赞
踩
Redis持久化
官方文档:
https://redis.io/topics/persistence
- 1.RDB和AOF优缺点
- RDB: 可以在指定的时间间隔内生成数据集的时间点快照,把当前内存里的状态快照到磁盘上
- 优点: 压缩格式/恢复速度快,适用于备份,主从复制也是基于rdb持久化功能实现
- 缺点: 可能会丢失数据
-
- AOF: 类似于mysql的binlog,重写,、每次操作都写一次/1秒写一次,文件中的命令全部以redis协议的格式保存,新命令会被追加到文件的末尾
- 优点: 安全,有可能会丢失1秒的数据
- 缺点: 文件比较大,恢复速度慢
-
-
- 2.配置RDB
- #900秒内有一个更改,300秒内有10个更改,.......
- save 900 1
- save 300 10
- save 60 10000
- dir /data/redis_6379/
- dbfilename redis_6379.rdb
-
- 结论:
- 1.执行shutdown的时候,内部会自动执行bgsave,然后再执行shutdown
- 2.pkill kill killall 都类似于执行shutdown命令.会触发bgsave持久化
- 3.恢复的时候,rdb文件名称要和配置文件里写的一样
- 4.如果没有配置save参数,执行shutdown不会自动bgsave持久化
- 5.如果没有配置save参数,可以手动执行bgsave触发持久化保存
- 6.kill -9 redis 不会出发持久化
- 常用命令:
- ll /data/redis_6379/
- cat /opt/redis_6379/conf/redis_6379.conf
- vim /opt/redis_6379/conf/redis_6379.conf
- pkill redis
- redis-server /opt/redis_6379/conf/redis_6379.conf
- redis-cli -h db01
- redis-cli -h db01 shutdown
- bash for.sh
-
-
- 3.配置AOF
- appendonly yes #是否打开aof日志功能
- appendfsync always #每1个命令,都立即同步到aof
- appendfsync everysec #每秒写1次
- appendfsync no #写入工作交给操作系统,由操作系统判断缓冲区大小,统一写入到aof.
-
- appendfilename "redis_6379.aof"
- appendonly yes
- appendfsync everysec
-
- 实验:
- 如果aof和rdb文件同时存在,redis会如何读取:
-
- 实验步骤:
- 1.插入一条数据
- aof: 有记录
- rdb: 没有记录
- 2.复制到其他地方
- 3.把redis停掉
- 4.清空数据目录
- 5.把数据文件拷贝过来
- aof: 有记录
- rdb: 没有记录
- 6.启动redis
- 7.测试,如果有新插入的数据,就表示读取的是aof,如果没有,就表示读取的是rdb
-
- 实验结论:
- 如果2种数据格式都存在,优先读取aof
-
- 如何选择:
- 好的,那我该怎么用?
- 通常的指示是,如果您希望获得与PostgreSQL可以提供的功能相当的数据安全性,则应同时使用两种持久性方法。
- 如果您非常关心数据,但是在灾难情况下仍然可以承受几分钟的数据丢失,则可以仅使用RDB。
- 有很多用户单独使用AOF,但我们不建议这样做,因为不时拥有RDB快照对于进行数据库备份,加快重启速度以及AOF引擎中存在错误是一个好主意。
- 注意:由于所有这些原因,我们将来可能会最终将AOF和RDB统一为一个持久性模型(长期计划)。
- 以下各节将说明有关这两个持久性模型的更多详细信息。
-

Redis用户认证
redis默认开启了保护模式,只允许本地回环地址登录并访问数据库
禁止protected-mode
protected-mode yes/no (保护模式,是否只允许本地访问)
- 1.Bind :指定IP进行监听
- vim /opt/redis_cluster/redis_6379/conf/redis_6379.conf
- bind 10.0.0.51 127.0.0.1
- #增加requirepass {password}
- vim /opt/redis_cluster/redis_6379/conf/redis_6379.conf
- requirepass 123456
-
-
- 2.使用密码登录
- 两种方式:
- 第一种:
- redis-cli -h db01
- AUTH 123456
-
-
- 第二种:
- redis-cli -h db01 -a 123456 get k_1
- ========================================
-
- #禁用危险命令
- 配置文件里添加禁用危险命令的参数
-
- 1)禁用命令
-
- rename-command KEYS ""
- rename-command FLUSHALL ""
- rename-command FLUSHDB ""
- rename-command CONFIG ""
- 2)重命名命令
-
- rename-command KEYS "XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX"
- rename-command FLUSHALL "XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX"
- rename-command FLUSHDB "XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX"
- rename-command CONFIG "XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX"
-
Redis主从复制
主从复制介绍
在分布式系统中为了解决单点问题,通常会把数据复制多个副本到其他机器,满足故障恢复和负载均衡等求.
Redis也是如此,提供了复制功能.
复制功能是高可用Redis的基础,后面的哨兵和集群都是在复制的基础上实现高可用的.
配置复制的方式有三种
- 1.在配置文件中加入slaveof {masterHost} {masterPort} 随redis启动生效.
- 2.在redis-server启动命令后加入—slaveof {masterHost} {masterPort}生效.
- 3.直接使用命令:slaveof {masterHost} {masterPort}生效.
-
- #查看复制状态信息命令
- Info replication
- 快速创建第二台redis节点命令:
-
- rsync -avz db01:/opt/* /opt/
- rm -rf /data (先备份)
- mkdir /data/redis_6379/ -p
-
- cd /opt/redis
- make install
- sed -i 's#51#52#g' /opt/redis_6379/conf/redis_6379.conf
- redis-server /opt/redis_6379/conf/redis_6379.conf
-
- 配置方法:
- 方法1: 临时生效
- [root@db-02 ~]# redis-cli -h 10.0.0.52
- 10.0.0.52:6379> SLAVEOF 10.0.0.51 6379
- OK
-
- 方法2: 写入配置文件
- SLAVEOF 10.0.0.51 6379
-
-
- 取消主从复制
- SLAVEOF no one
-
- 注意!!!
- 1.从节点只读不可写
- 2.从节点不会自动故障转移,它会一直同步主
- 10.0.0.52:6379> set k1 v1
- (error) READONLY You can't write against a read only slave.
- 3.主从复制故障转移需要人工介入
- - 修改代码指向REDIS的IP地址
- - 从节点需要执行SLAVEOF no one
- 注意!!!
- 1.从节点会清空自己原有的数据,如果同步的对象写错了,就会导致数据丢失
- 2.主库有密码从库的配置
- masterauth 123456
- 安全的操作:
- 1.无论是同步,无论是主节点还是从节点
- 2.先备份一下数据
- 3.配置持久化(为了重新载入数据)
- 4.重启
- 从节点请求同步:
- 2602:S 09 Nov 15:58:25.703 * The server is now ready to accept connections on port 6379
- 2602:S 09 Nov 15:58:25.703 * Connecting to MASTER 10.0.1.51:6379
- 2602:S 09 Nov 15:58:25.703 * MASTER <-> SLAVE sync started
- 2602:S 09 Nov 15:58:25.703 * Non blocking connect for SYNC fired the event.
- 2602:S 09 Nov 15:58:25.703 * Master replied to PING, replication can continue...
- 2602:S 09 Nov 15:58:25.704 * Partial resynchronization not possible (no cached master)
- 2602:S 09 Nov 15:58:25.705 * Full resync from master: be1ed4812a0bd83227af30dc6ebe36d88bca5005:1
-
- 主节点收到请求之后开始持久化保存数据:
- 12703:M 09 Nov 15:58:25.708 * Slave 10.0.1.52:6379 asks for synchronization
- 12703:M 09 Nov 15:58:25.708 * Full resync requested by slave 10.0.1.52:6379
- 12703:M 09 Nov 15:58:25.708 * Starting BGSAVE for SYNC with target: disk
- 12703:M 09 Nov 15:58:25.708 * Background saving started by pid 12746
- 12746:C 09 Nov 15:58:25.710 * DB saved on disk
- 12746:C 09 Nov 15:58:25.710 * RDB: 6 MB of memory used by copy-on-write
-
-
- 从节点接收主节点发送的数据,然后载入内存:
- 2602:S 09 Nov 15:58:25.805 * MASTER <-> SLAVE sync: receiving 95 bytes from master
- 2602:S 09 Nov 15:58:25.805 * MASTER <-> SLAVE sync: Flushing old data
- 2602:S 09 Nov 15:58:25.805 * MASTER <-> SLAVE sync: Loading DB in memory
- 2602:S 09 Nov 15:58:25.806 * MASTER <-> SLAVE sync: Finished with success
-
-
- 主节点收到从节点同步完成的消息:
- 12703:M 09 Nov 15:58:25.809 * Background saving terminated with success
- 12703:M 09 Nov 15:58:25.809 * Synchronization with slave 10.0.1.52:6379 succeeded
-
- 主从复制流程:
- 1.从节点发送同步请求到主节点
- 2.主节点接收到从节点的请求之后,做了如下操作
- - 立即执行bgsave将当前内存里的数据持久化到磁盘上
- - 持久化完成之后,将rdb文件发送给从节点
- 3.从节点从主节点接收到rdb文件之后,做了如下操作
- - 清空自己的数据
- - 载入从主节点接收的rdb文件到自己的内存里
- 4.后面的操作就是和主节点实时的了
Redis哨兵
Redis Sentinel 是一个分布式系统, Redis Sentinel为Redis提供高可用性。可以在没有人为干预的情况下阻止某种类型的故障。
Redis 的 Sentinel 系统用于管理多个 Redis 服务器(instance)该系统执行以下三个任务:
1.监控(Monitoring):
Sentinel 会不断地定期检查你的主服务器和从服务器是否运作正常。
2.提醒(Notification):
当被监控的某个 Redis 服务器出现问题时, Sentinel 可以通过 API 向管理员或者其他应用程序发送通知。
3.自动故障迁移(Automatic failover):
当一个主服务器不能正常工作时, Sentinel 会开始一次自动故障迁移操作, 它会将失效主服务器的其中一个从服务器升级为新的主服务器, 并让失效主服务器的其他从服务器改为复制新的主服务器; 当客户端试图连接失效的主服务器时, 集群也会向客户端返回新主服务器的地址, 使得集群可以使用新主服务器代替失效服务器
Sentinel 节点是一个特殊的 Redis 节点,他们有自己专属的 API(端口)
规划安装配置命令
- 哨兵是基于主从复制,所以需要先部署好主从复制
- 手工操作步骤如下:
- 1.先配置和创建好1台服务器的节点和哨兵
- 2.使用rsync传输到另外2台机器
- 3.修改另外两台机器的IP地址
- 建议使用ansible剧本批量部署
结构图
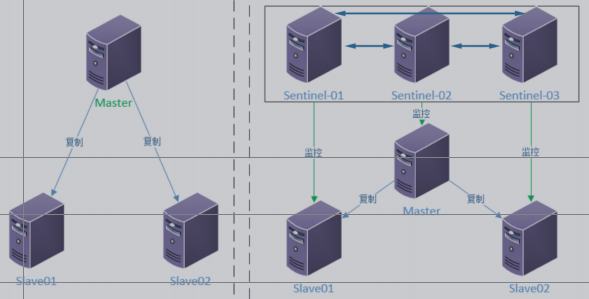
做db03的主从
- 1.db03上执行快速安装第3个redis节点
- rsync -avz 10.0.0.51:/opt/* /opt/
- mkdir /data/redis_6379 -p
- cd /opt/redis
- make install
- sed -i 's#51#53#g' /opt/redis_6379/conf/redis_6379.conf
- redis-server /opt/redis_6379/conf/redis_6379.conf
- redis-cli
-
- 2.启动所有的单节点
- redis-server /opt/redis_6379/conf/redis_6379.conf
-
- 3.配置主从复制(任意节点)
- redis-cli -h 10.0.0.52 slaveof 10.0.0.51 6379
- redis-cli -h 10.0.0.53 slaveof 10.0.0.51 6379
安装部署3个哨兵节点-----基于主从的前提
!!!!注意!!!!
三个节点的bind IP修改为自己的IP地址
- mkdir -p /data/redis_26379
- mkdir -p /opt/redis_26379/{conf,pid,logs}
-
- #.配置哨兵的配置文件
- 注意!三台机器都操作
- cat >/opt/redis_26379/conf/redis_26379.conf << EOF
- bind $(ifconfig eth0|awk 'NR==2{print $2}')
- port 26379
- daemonize yes
- logfile /opt/redis_26379/logs/redis_26379.log
- dir /data/redis_26379
- sentinel monitor myredis 10.0.0.51 6379 2
- sentinel down-after-milliseconds myredis 3000
- sentinel parallel-syncs myredis 1
- sentinel failover-timeout myredis 18000
- EOF
-
- #.启动哨兵
- redis-sentinel /opt/redis_26379/conf/redis_26379.conf
-
- #.验证主节点(注意对应的节点)
- redis-cli -h 10.0.0.51 -p 26379 Sentinel get-master-addr-by-name myredis
- redis-cli -h 10.0.0.52 -p 26379 Sentinel get-master-addr-by-name myredis
- redis-cli -h 10.0.0.53 -p 26379 Sentinel get-master-addr-by-name myredis
配置文件的变化
当所有节点启动后,配置文件的内容发生了变化,体现在三个方面:
- 1)Sentinel节点自动发现了从节点,其余Sentinel节点
- 2)去掉了默认配置,例如parallel-syncs failover-timeout参数
- 3)添加了配置纪元相关参数
查看配置文件命令
- [root@db01 ~]# tail -6 /opt/redis_cluster/redis_26379/conf/redis_26379.conf
- # Generated by CONFIG REWRITE
- sentinel known-slave mymaster 10.0.0.52 6379
- sentinel known-slave mymaster 10.0.0.53 6379
- sentinel known-sentinel mymaster 10.0.0.53 26379 7794fbbb9dfb62f4d2d7f06ddef06bacb62e4c97
- sentinel known-sentinel mymaster 10.0.0.52 26379 17bfab23bc53a531571790b9b31558dddeaeca40
- sentinel current-epoch 0
模拟故障转移
- 关闭主节点服务上的所有redis进程
- 观察其他2个节点会不会发生选举
- 查看配置文件里会不会自动更新
- 查看新的主节点能不能写入
- 查看从节点能否正常同步
模拟故障修复上线
- 启动单节点
- 启动哨兵
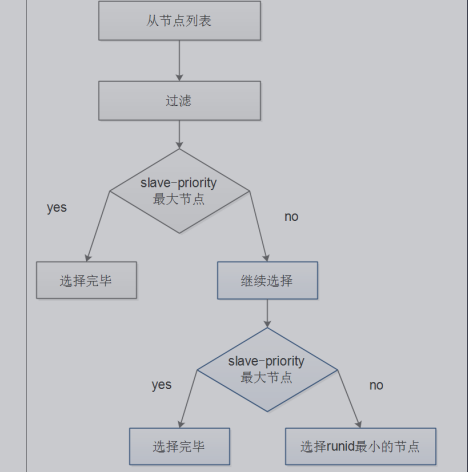
模拟权重选举,权重相同的id小的优先(最好其他权重设置为0,100以上有问题)
- 设置其他节点的权重为0
- 手动发起重新选举
- 观察所有节点消息是否同步
- 观察切换结果是否符合预期
命令解释:
- 1.查询命令:CONFIG GET slave-priority
- 2.设置命令:CONFIG SET slave-priority 0
- 3.主动切换(哨兵):sentinel failover myredis
-
- redis-cli -h 10.0.0.52 -p 6379 CONFIG SET slave-priority 0
- redis-cli -h 10.0.0.53 -p 6379 CONFIG SET slave-priority 0
- redis-cli -h 10.0.0.51 -p 26379 sentinel failover myredis
验证选举结果:
redis-cli -h 10.0.0.51 -p 26379 Sentinel get-master-addr-by-name myredis
Redis哨兵+主从+密码
- 主从密码配置文件里添加2行参数:
- requirepass "123456"
- masterauth "123456"
-
- 哨兵配置文件添加一行参数:
- sentinel auth-pass myredis 123456
Redis哨兵设置权重手动故障转移
- 1.查看权重
- CONFIG GET slave-priority
-
- 2.设置权重
- 在其他节点把权重设为0
- CONFIG SET slave-priority 0
-
- 3.主动发起重新选举
- sentinel failover mymaster
-
- 4.恢复默认的权重
- CONFIG SET slave-priority 100
redis集群安装部署-----基于主从的前提
Redis Cluster 是 redis的分布式解决方案,在3.0版本正式推出
当遇到单机、内存、并发、流量等瓶颈时,可以采用Cluster架构方案达到负载均衡目的。
Redis Cluster之前的分布式方案有两种:
- 客户端分区方案,优点分区逻辑可控,缺点是需要自己处理数据路由,高可用和故障转移等。
- 代理方案,优点是简化客户端分布式逻辑和升级维护便利,缺点加重架构部署和性能消耗。
官方提供的 Redis Cluster集群方案,很好的解决了集群方面的问题
数据分布
分布式数据库首先要解决把整个数据库集按照分区规则映射到多个节点的问题,即把数据集划分到多个节点上,每个节点负责整体数据的一个子集,需要关注的数据分片规则,redis clusterciyong哈希分片规则
手动搭建部署集群
思路:
- 部署一台服务器上的2个集群节点
- 发送完成后修改其他主机的ip地址
- 使用ansible批量部署
拓扑图
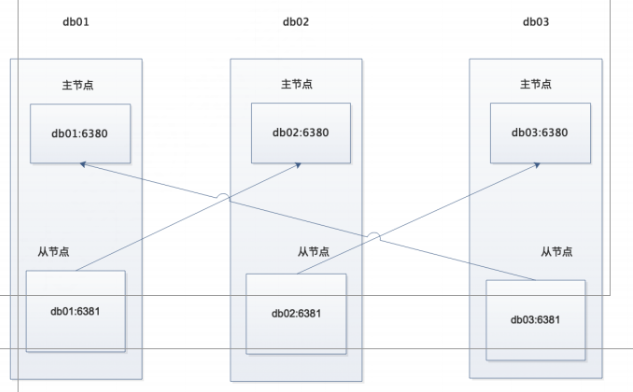
1.目录规划
- 主节点 6380
- 从节点 6381
-
- # redis安装目录
- /opt/redis_{6380,6381}/{conf,logs,pid}
- # redis数据目录
- /data/redis_{6380,6381}
- # redis运维脚本
- /root/scripts/redis_shell.sh
2.db01创建命令
- #为了关闭其他redis端口,生产中需要注意
- pkill redis
-
- mkdir -p /opt/redis_{6380,6381}/{conf,logs,pid}
- mkdir -p /data/redis_{6380,6381}
-
- cat >/opt/redis_6380/conf/redis_6380.conf<<EOF
- bind 10.0.0.51
- port 6380
- daemonize yes
- pidfile "/opt/redis_6380/pid/redis_6380.pid"
- logfile "/opt/redis_6380/logs/redis_6380.log"
- dbfilename "redis_6380.rdb"
- dir "/data/redis_6380/"
- cluster-enabled yes
- cluster-config-file nodes_6380.conf
- cluster-node-timeout 15000
- EOF
-
- cd /opt/
- cp redis_6380/conf/redis_6380.conf redis_6381/conf/redis_6381.conf
- sed -i 's#6380#6381#g' redis_6381/conf/redis_6381.conf
- rsync -avz /opt/redis_638* 10.0.0.52:/opt/
- rsync -avz /opt/redis_638* 10.0.0.53:/opt/
- redis-server /opt/redis_6380/conf/redis_6380.conf
- redis-server /opt/redis_6381/conf/redis_6381.conf
- ps -ef|grep redis
3.db02操作命令
- pkill redis
-
- find /opt/redis_638* -type f -name "*.conf"|xargs sed -i "/bind/s#51#52#g"
- mkdir –p /data/redis_{6380,6381}
- redis-server /opt/redis_6380/conf/redis_6380.conf
- redis-server /opt/redis_6381/conf/redis_6381.conf
- ps -ef|grep redis
4.db03操作命令
- pkill redis
- find /opt/redis_638* -type f -name "*.conf"|xargs sed -i "/bind/s#51#53#g"
- mkdir –p /data/redis_{6380,6381}
- redis-server /opt/redis_6380/conf/redis_6380.conf
- redis-server /opt/redis_6381/conf/redis_6381.conf
- ps -ef|grep redis
手动配置节点发现
当把所有节点都启动后查看进程会有cluster的字样,但是登录后执行CLUSTER NODES命令会发现只有每个节点自己的ID,目前集群内的节点,还没有互相发现,所以搭建redis集群我们第一步要做的就是让集群内的节点互相发现.,在执行节点发现命令之前我们先查看一下集群的数据目录会发现有生成集群的配置文件,查看后发现只有自己的节点内容,等节点全部发现后会把所发现的节点ID写入这个文件
集群模式的Redis除了原有的配置文件之外又加了一份集群配置文件.当集群内节点. 信息发生变化,如添加节点,节点下线,故障转移等.节点会自动保存集群状态到配置文件.
需要注意的是,Redis自动维护集群配置文件,不需要手动修改,防止节点重启时产生错乱.
节点发现使用命令: CLUSTER MEET {IP} {PORT}
提示:在集群内任意一台机器执行此命令就可以
发现节点(db01)
- redis-cli -h 10.0.0.51 -p 6380 CLUSTER MEET 10.0.0.51 6381
- redis-cli -h 10.0.0.51 -p 6380 CLUSTER MEET 10.0.0.52 6380
- redis-cli -h 10.0.0.51 -p 6380 CLUSTER MEET 10.0.0.52 6381
- redis-cli -h 10.0.0.51 -p 6380 CLUSTER MEET 10.0.0.53 6380
- redis-cli -h 10.0.0.51 -p 6380 CLUSTER MEET 10.0.0.53 6381
查询
- redis-cli -h 10.0.0.51 -p 6380 CLUSTER NODES
-
- [root@db01 opt]# redis-cli -h 10.0.0.51 -p 6380 CLUSTER NODES
- 0a138d3b47ae0ac83719d150ac5e46f1986c92f9 10.0.0.52:6381 master - 0 1577372412387 3 connected
- f1c6d6a418edb08f986715f093934646d92f99e3 10.0.0.53:6381 master - 0 1577372411377 0 connected
- dc225e89785179d0045d82a2b3f0c1d072466713 10.0.0.53:6380 master - 0 1577372410361 4 connected 10922-16383
- 81b466115f32423ecd32a2cb4477f1e1a9913437 10.0.0.52:6380 master - 0 1577372408341 5 connected 5461-10921
- 83d86340bf4859023994ba75f4b1d84778a58840 10.0.0.51:6381 master - 0 1577372413402 2 connected
- b0cda45c78d5a7fe288f46fa85c4041da795a5ec 10.0.0.51:6380 myself,master - 0 0 1 connected 0-5460
-
Redis Cluster 通讯流程
在分布式存储中需要提供维护节点元数据信息的机制,所谓元数据是指:节点负责哪些数据,是否出现故障灯状态信息,redis 集群采用 Gossip(流言)协议,Gossip 协议工作原理就是节点彼此不断交换信息,一段时间后所有的节点都会知道集群完整信息,这种方式类似流言传播。
通信过程:
-
集群中的每一个节点都会单独开辟一个 Tcp 通道,用于节点之间彼此通信,通信端口在基础端口上家10000.
-
每个节点在固定周期内通过特定规则选择结构节点发送 ping 消息
-
接收到 ping 消息的节点用 pong 消息作为响应。集群中每个节点通过一定规则挑选要通信的节点,每个节点可能知道全部节点,也可能仅知道部分节点,只要这些节点彼此可以正常通信,最终他们会打成一致的状态,当节点出现故障,新节点加入,主从角色变化等,它能够给不断的ping/pong消息,从而达到同步目的。
通讯消息类型:
-
Gossip
Gossip 协议职责就是信息交换,信息交换的载体就是节点间彼此发送Gossip 消息。
常见 Gossip 消息分为:ping、 pong、 meet、 fail 等 -
meet
meet 消息:用于通知新节点加入,消息发送者通知接受者加入到当前集群,meet 消息
通信正常完成后,接收节点会加入到集群中并进行ping、 pong 消息交换
-
ping
ping 消息:集群内交换最频繁的消息,集群内每个节点每秒想多个其他节点发送 ping 消息,用于检测节点是否在线和交换彼此信息。
-
pong
Pong 消息:当接收到 ping,meet 消息时,作为相应消息回复给发送方确认消息正常通信,节点也可以向集群内广播自身的 pong 消息来通知整个集群对自身状态进行更新。 -
fail
fail 消息:当节点判定集群内另一个节点下线时,回向集群内广播一个fail 消息,其他节点收到 fail 消息之后把对应节点更新为下线状态。
通讯示意图:
-
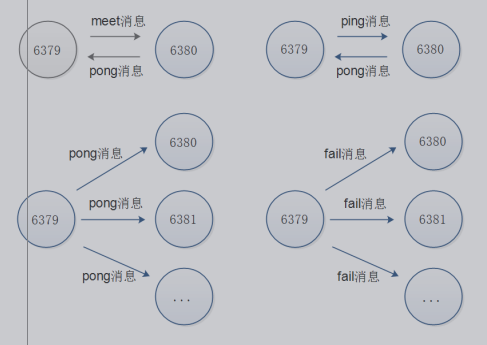
手动分配槽位
-
redis集群一共有16384个槽,所有的槽都必须分配完毕,
-
有一个槽没分配整个集群都不可用,每个节点上槽位的顺序无所谓,重点是槽位的个数,
-
hash分片算法足够随机,足够平均
-
不要去手动修改集群的配置文件
我们虽然有6个节点,但是真正负责数据写入的只有3个节点,其他的3个节点只是作为主节点的从节点,也就是说,只需要分配期中三个节点的的槽位就可以
非配槽位需要在每个主节点上来配置,两种方法执行:
- 分别登陆到每个主节点的客户端来执行命令
- 一台远程登录在其主节点上执行
1.槽位规划
- db01:6380 0-5460
- db02:6380 5461-10921
- db03:6380 10922-16383
2.分配槽位(有的版本有坑,会报错,需要注意)
- redis-cli -h 10.0.0.51 -p 6380 CLUSTER ADDSLOTS {0..5460}
- redis-cli -h 10.0.0.52 -p 6380 CLUSTER ADDSLOTS {5461..10920}
- redis-cli -h 10.0.0.52 -p 6380 CLUSTER ADDSLOTS 10921
-
- redis-cli -h 10.0.0.53 -p 6380 CLUSTER ADDSLOTS {10922..16383}
3.查看集群状态
redis-cli -h db01 -p 6380 CLUSTER info
允许的槽位个数误差范围2%以内
手动配置集群的高可用
虽然这时候集群是可用的了,但是整个集群只要有一台机器坏掉了,那么整个集群都是不可用的.
所以这时候需要用到其他三个节点分别作为现在三个主节点的从节点,以应对集群主节点故障时可以进行自动切换以保证集群持续可用.
注意:
1.不要让复制节点复制本机器的主节点, 因为如果那样的话机器挂了集群还是不可用状态, 所以复制节点要复制其他服务器的主节点.
2.使用redis-trid工具自动分配的时候会出现复制节点和主节点在同一台机器上的情况,需要注意
手动部署复制关系
- #查询id
- redis-cli -h 10.0.0.51 -p 6380 CLUSTER NODES
-
-
- redis-cli -h 10.0.0.51 -p 6381 CLUSTER REPLICATE 35b5ee70a887b5256089a5eebf521aa21a0a7a7a
- redis-cli -h 10.0.0.52 -p 6381 CLUSTER REPLICATE 65baaa3b071f906c14da10452c349b0871317210
- redis-cli -h 10.0.0.53 -p 6381 CLUSTER REPLICATE a1d47ccb19411eaf12d5af4b22cafbbefc8e2486
测试集群
- 1.尝试插入一条数据发现报错
- 10.0.0.51:6380> set k1 v1
- (error) MOVED 12706 10.0.0.53:6380
-
- 2.目前的现象
-
- - 在db01的6380节点插入数据提示报错
- - 报错内容提示应该移动到db03的6380上
- - 在db03的6380上执行相同的插入命令可以插入成功
- - 在db01的6380节点插入数据有时候可以,有时候不行
- - 使用-c参数后,可以正常插入命令,并且节点切换到了提示的对应节点上
-
- 3.问题原因
- 因为集群模式又ASK路由规则,加入-c参数后,会自动跳转到目标节点处理
- 并且最后由目标节点返回信息
-
- 4.测试足够随机足够平均
- #!/bin/bash
- for i in $(seq 1 1000)
- do
- redis-cli -c -h db01 -p 6380 set k_${i} v_${i} && echo "set k_${i} is ok"
- done
控制脚本
- sh redis_shell.sh login 6380 10.0.0.52
-
- [root@db03 script]# cat redis_shell.sh
- #!/bin/bash
-
- USAG(){
- echo "sh $0 {start|stop|restart|login|ps|tail} PORT"
- }
- if [ "$#" = 1 ]
- then
- REDIS_PORT='6379'
- elif
- [ "$#" -gt 2 -a -z "$(echo "$2"|sed 's#[0-9]##g')" ]
- then
- REDIS_PORT="$2"
- else
- USAG
- exit 0
- fi
-
- REDIS_IP=$3
- PATH_DIR=/opt/redis_${REDIS_PORT}/
- PATH_CONF=/opt/redis_${REDIS_PORT}/conf/redis_${REDIS_PORT}.conf
- PATH_LOG=/opt/redis_${REDIS_PORT}/logs/redis_${REDIS_PORT}.log
-
- CMD_START(){
- redis-server ${PATH_CONF}
- }
-
- CMD_SHUTDOWN(){
- redis-cli -c -h ${REDIS_IP} -p ${REDIS_PORT} shutdown
- }
-
- CMD_LOGIN(){
- redis-cli -c -h ${REDIS_IP} -p ${REDIS_PORT}
- }
-
- CMD_PS(){
- ps -ef|grep redis
- }
-
- CMD_TAIL(){
- tail -f ${PATH_LOG}
- }
-
- case $1 in
- start)
- CMD_START
- CMD_PS
- ;;
- stop)
- CMD_SHUTDOWN
- CMD_PS
- ;;
- restart)
- CMD_START
- CMD_SHUTDOWN
- CMD_PS
- ;;
- login)
- CMD_LOGIN
- ;;
- ps)
- CMD_PS
- ;;
- tail)
- CMD_TAIL
- ;;
- *)
- USAG
- esac
-
模拟故障转移
至此,我们已经手动的把一个redis高可用的集群部署完毕了, 但是还没有模拟过故障
这里我们就模拟故障,停掉期中一台主机的redis节点,然后查看一下集群的变化
我们使用暴力的kill -9杀掉 db02上的redis集群节点,然后观察节点状态
理想情况应该是db01上的6381从节点升级为主节点
在db01上查看集群节点状态
虽然我们已经测试了故障切换的功能,但是节点修复后还是需要重新上线
所以这里测试节点重新上线后的操作
重新启动db02的6380,然后观察日志
观察db01上的日志
这时假如我们想让修复后的节点重新上线,可以在想变成主库的从库执行CLUSTER FAILOVER命令
这里我们在db02的6380上执行
Redis Cluster ASK路由介绍
在集群模式下,Redis接受任何键相关命令时首先会计算键对应的槽,再根据槽找出所对应的节点 如果节点是自身,则处理键命令;否则回复MOVED重定向错误,通知客户端请求正确的节点,这个过程称为Mover重定向.
知道了ask路由后,我们使用-c选项批量插入一些数据
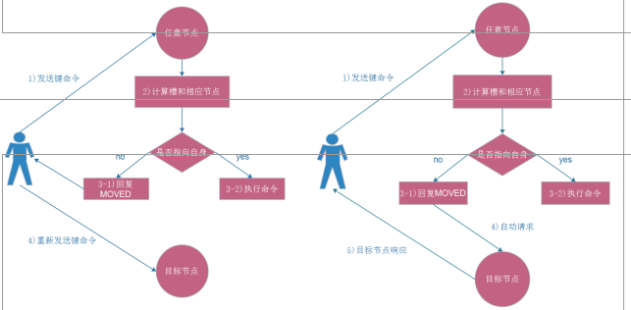
使用工具搭建部署Redis Cluster
手动搭建集群便于理解集群创建的流程和细节,不过手动搭建集群需要很多步骤,当集群节点众多时,必然会加大搭建集群的复杂度和运维成本,因此官方提供了 redis-trib.rb的工具方便我们快速搭建集群。
redis-trib.rb是采用 Ruby 实现的 redis 集群管理工具,内部通过 Cluster相关命令帮我们简化集群创建、检查、槽迁移和均衡等常见运维操作,使用前要安装 ruby 依赖环境
- 1.安装依赖-只要在db01上操作
- yum makecache fast
- yum install rubygems -y
- gem sources --remove https://rubygems.org/
- gem sources -a http://mirrors.aliyun.com/rubygems/
- gem update –system
- gem install redis -v 3.3.5
-
- 2.还原环境-所有节点都执行!!!
- pkill redis
- rm -rf /data/redis_6380/*
- rm -rf /data/redis_6381/*
-
- 3.启动集群节点-所有节点都执行
- redis-server /opt/redis_6380/conf/redis_6380.conf
- redis-server /opt/redis_6381/conf/redis_6381.conf
- ps -ef|grep redis
-
- 4.使用工具搭建部署Redis(一台部署)
- cd /opt/redis/src/
- ./redis-trib.rb create --replicas 1 10.0.0.51:6380 10.0.0.52:6380 10.0.0.53:6380 10.0.0.51:6381 10.0.0.52:6381 10.0.0.53:6381
-
- 5.检查集群完整性
- ./redis-trib.rb check 10.0.0.51:6380
-
- 6.检查集群负载是否合规
- ./redis-trib.rb rebalance 10.0.0.51:6380
使用工具扩容节点
redis集群的扩容操作规划
- 准备新节点
- 加入集群
- 迁移槽和数据(迁移过程千万不能中断,以防集群故障)
扩容流程图
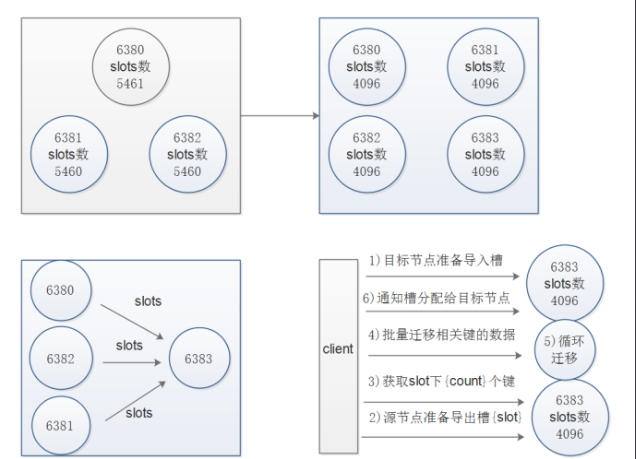
- 打印出进群每个节点信息后,reshard命令需要确认迁移的槽数量,这里我们输入4096个:
- How many slots do you want to move (from 1 to 16384)? 4096
- 输入6390的节点ID作为目标节点,也就是要扩容的节点,目标节点只能指定一个
- What is the receiving node ID? xxxxxxxxx
- 之后输入源节点的ID,这里分别输入每个主节点的6380的ID最后输入done,或者直接输入all
- Source node #1:all
- 迁移完成后命令会自动退出,这时候我们查看一下集群的状态
- ./redis-trib.rb rebalance 10.0.0.51:6380
- 1.创建新节点-db01操作
- mkdir -p /opt/redis_{6390,6391}/{conf,logs,pid}
- mkdir -p /data/redis_{6390,6391}
- cd /opt/
- cp redis_6380/conf/redis_6380.conf redis_6390/conf/redis_6390.conf
- cp redis_6380/conf/redis_6380.conf redis_6391/conf/redis_6391.conf
- sed -i 's#6380#6390#g' redis_6390/conf/redis_6390.conf
- sed -i 's#6380#6391#g' redis_6391/conf/redis_6391.conf
- redis-server /opt/redis_6390/conf/redis_6390.conf
- redis-server /opt/redis_6391/conf/redis_6391.conf
- ps -ef|grep redis
- redis-cli -c -h db01 -p 6380 cluster meet 10.0.0.51 6390
- redis-cli -c -h db01 -p 6380 cluster meet 10.0.0.51 6391
- redis-cli -c -h db01 -p 6380 cluster nodes
-
- 2.使用工具扩容步骤
- cd /opt/redis/src/
- ./redis-trib.rb reshard 10.0.0.51:6380
-
- 第一次交互:每个节点保留多少个槽位
- How many slots do you want to move (from 1 to 16384)? 4096
-
- 第二次交互:接收节点的ID是什么
- What is the receiving node ID? 6390的ID
-
- 第三次交互:哪个节点需要导出
- Source node #1: all
-
- 第四次交互:确认是否执行分配
- Do you want to proceed with the proposed reshard plan (yes/no)? yes
-
- 3.检查集群完整性
- ./redis-trib.rb check 10.0.0.51:6380
-
- 4.检查集群负载是否合规
- ./redis-trib.rb rebalance 10.0.0.51:6380
-
- 5.调整复制顺序
- redis-cli -h 10.0.0.53 -p 6381 CLUSTER REPLICATE 51-6390的ID
- redis-cli -h 10.0.0.51 -p 6391 CLUSTER REPLICATE 51-6380的ID
-
-
- 6.测试写入脚本
- [root@db01 ~]# cat for.sh
- #!/bin/bash
- for i in $(seq 1 100000)
- do
- redis-cli -c -h db01 -p 6380 set k_${i} v_${i} && echo "set k_${i} is ok"
- done
-
-
- 7.测试读脚本
- [root@db03 ~]# cat du.sh
- #!/bin/bash
-
- for i in $(seq 1 100000)
- do
- redis-cli -c -h db01 -p 6380 get k_${i}
- sleep 0.1
- done
使用工具收缩节点
流程说明
- 确定下线节点是否有负责的槽,如果是,要把槽迁移到其他节点,保证节点下线后整个集群槽节点映射的完整性
- 当下线节点不再负责槽或者本身是从节点时,就可以通知群内其他节点忘记下线节点,当所有的节点忘记该节点后可以正常关闭
- 计划将6390和6391节点下线,收缩和扩容的方向相反,6390变为源节点,其他节点变为目标节点,源节点把自己负责的4096个槽均匀的迁移到其他节点上,由于
redis-trib.rb reshard命令只能有一个目标节点,因此需要执行3次reshard命令,分别迁移1365,1365,1366个槽
收缩流程图

- 1.使用工具收缩节点
- cd /opt/redis/src/
- ./redis-trib.rb reshard 10.0.0.51:6380
-
- 2.第一次交互: 要迁移多少个
- How many slots do you want to move (from 1 to 16384)? 1365
-
- 3.第二次交互: 输入第一个需要接收节点的ID
- What is the receiving node ID? db01的6380的ID
-
- 4.第三次交互: 输入需要导出的节点的ID
- Please enter all the source node IDs.
- Type 'all' to use all the nodes as source nodes for the hash slots.
- Type 'done' once you entered all the source nodes IDs.
- Source node #1: db01的6390的ID
- Source node #2: done
-
- 5.第四次交互: 确认
- Do you want to proceed with the proposed reshard plan (yes/no)? yes
-
- 6.继续重复的操作,直到6390所有的槽位都分配给了其他主节点
-
- 7.确认集群状态是否正常,确认6390槽位是否都迁移走了
- 10.0.0.51:6380> CLUSTER NODES
-
-
- 8.忘记以及下线节点(从节点可以直接删除,主节点先移走数据,再删除)
- ./redis-trib.rb del-node 10.0.0.51:6390 baf9585a780d9f6e731972613a94b6f3e6d3fb5e
- ./redis-trib.rb del-node 10.0.0.51:6391 e54a79cca258eb76fb74fc12dafab5ebac26ed90
排错思路
-
首先确定端口是否启动
-
检查防火墙,getenforce
-
./redis-trib.rb check 10.0.0.51:6380检查
-
cluster nodes
企业案例
迁移过程中,ctrl+c,集群出现问题
解决办法:
- 工具关闭槽
- cd /opt/redis/src
- ./redis-trib.rb fix 10.0.0.51:6380
-
-
- 手动关闭:
- 连接对应的redis节点,执行cluster setslot 773 stable,(导入,导出问题槽位)
-
执行,reblance是出现#######,按下ctrl+c发现集群执行cluster info时.ok,但槽的状态有问题
解决思路:
- 1手动关闭:
- 连接对应的redis节点,执行cluster setslot 773 stable,
- 查询槽的状态已经恢复
- cluster info
- 检查,有报错,
- ./redis-trib.rb check 10.0.0.51:6380
- cluster info 状态ok,集群用fix,有问题,发现问题773槽位识别出现问题,其他节点上看0-773在6390上,6390上看而在6380上
-
- 2.删除两个问题槽位,6380,6390
- cluster delslots 773
- 3.6390添加773
- cluster addslots 773
- 发现大家看到的结果一致6390上,check.reblance ok
-
redis集群常用的命令
- 集群(cluster)
- CLUSTER INFO 打印集群的信息
- CLUSTER NODES 列出集群当前已知的所有节点(node),以及这些节点的相关信息。
- 节点(node)
- CLUSTER MEET <ip> <port> 将 ip 和 port 所指定的节点添加到集群当中,让它成为集群的一份子。
- CLUSTER FORGET <node_id> 从集群中移除 node_id 指定的节点。
- CLUSTER REPLICATE <node_id> 将当前节点设置为 node_id 指定的节点的从节点。
- CLUSTER SAVECONFIG 将节点的配置文件保存到硬盘里面。
- 槽(slot)
- CLUSTER ADDSLOTS <slot> [slot ...] 将一个或多个槽(slot)指派(assign)给当前节点。
- CLUSTER DELSLOTS <slot> [slot ...] 移除一个或多个槽对当前节点的指派。
- CLUSTER FLUSHSLOTS 移除指派给当前节点的所有槽,让当前节点变成一个没有指派任何槽的节点。
- CLUSTER SETSLOT <slot> NODE <node_id> 将槽 slot 指派给 node_id 指定的节点,如果槽已经指派给另一个节点,那么先让另一个节点删除该槽>,然后再进行指派。
- CLUSTER SETSLOT <slot> MIGRATING <node_id> 将本节点的槽 slot 迁移到 node_id 指定的节点中。
- CLUSTER SETSLOT <slot> IMPORTING <node_id> 从 node_id 指定的节点中导入槽 slot 到本节点。
- CLUSTER SETSLOT <slot> STABLE 取消对槽 slot 的导入(import)或者迁移(migrate)。
- 键 (key)
- CLUSTER KEYSLOT <key> 计算键 key 应该被放置在哪个槽上。
- CLUSTER COUNTKEYSINSLOT <slot> 返回槽 slot 目前包含的键值对数量。CLUSTER GETKEYSINSLOT <slot> <count> 返回 count 个 slot 槽中的键。
数据迁移
需求背景
刚切换到redis集群的时候肯定会面临数据导入的问题,所以这里推荐使用redis-migrate-tool工具来导入单节点数据到集群里
官方地址:
http://www.oschina.net/p/redis-migrate-tool
导出工具
- 1.安装工具
- yum install libtool autoconf automake git bzip2 -y
- cd /opt/
- git clone https://github.com/vipshop/redis-migrate-tool.git
- cd redis-migrate-tool/
- autoreconf -fvi
- ./configure
- make && make install
-
-
- 2.编写配置文件
- cat > 6379_to_6380.conf << EOF
- [source]
- type: single
- servers:
- - 10.0.0.51:6379
-
- [target]
- type: redis cluster
- servers:
- - 10.0.0.51:6380
-
- [common]
- listen: 0.0.0.0:8888
- source_safe: true
- EOF
-
-
- 3.单节点生成测试数据
- redis-server /opt/redis_6379/conf/redis_6379.conf
- cat >input_6379.sh<<EOF
- #!/bin/bash
- for i in {1..1000}
- do
- redis-cli -c -h db01 -p 6379 set oldzhang_\${i} oldzhang_\${i}
- echo "set oldzhang_\${i} is ok"
- done
- EOF
-
- 4.运行工具迁移单节点数据到集群
- redis-migrate-tool -c 6379_to_6380.conf
-
-
- 5.运行工具验证数据是否迁移完成
- redis-migrate-tool -c 6379_to_6380.conf -C redis_check
-
RDB文件迁移到集群
- 1.先把集群的RDB文件都收集起来
- - 在从节点上执行bgsave命令生成RDB文件
- redis-cli -h db01 -p 6381 BGSAVE
- redis-cli -h db02 -p 6381 BGSAVE
- redis-cli -h db03 -p 6381 BGSAVE
-
- 2.把从节点生成的RDB文件拉取过来
- mkdir /root/rdb_backup
- cd /root/rdb_backup/
- scp db01:/data/redis_6381/redis_6381.rdb db01_6381.rdb
- scp db02:/data/redis_6381/redis_6381.rdb db02_6381.rdb
- scp db03:/data/redis_6381/redis_6381.rdb db03_6381.rdb
-
- 3.清空数据
- redis-cli -c -h db01 -p 6380 flushall
- redis-cli -c -h db02 -p 6380 flushall
- redis-cli -c -h db03 -p 6380 flushall
-
- 7.编写配置文件
- cat >rdb_to_cluter.conf <<EOF
- [source]
- type: rdb file
- servers:
- - /root/rdb_backup/db01_6381.rdb
- - /root/rdb_backup/db02_6381.rdb
- - /root/rdb_backup/db03_6381.rdb
-
- [target]
- type: redis cluster
- servers:
- - 10.0.0.51:6380
-
- [common]
- listen: 0.0.0.0:8888
- source_safe: true
- EOF
-
- 8.使用工具导入
- redis-migrate-tool -c rdb_to_cluter.conf
-
使用工具分析key的大小(注意Python环境的安装过程,有出错多执行几次)
需求背景
redis的内存使用太大键值太多,不知道哪些键值占用的容量比较大,而且在线分析会影响性能
- 0.需求背景
- redis的内存使用太大键值太多,不知道哪些键值占用的容量比较大,而且在线分析会影响性能.
-
- 1.安装命令:(pip可能会出错,)
- yum install python-pip gcc python-devel -y
- cd /opt/
- git clone https://github.com/sripathikrishnan/redis-rdb-tools
- cd redis-rdb-tools
- pip install python-lzf
- python setup.py install
-
- 2.生成测试数据:
- redis-cli -h db01 -p 6379 set txt $(cat txt.txt)
-
- 3.执行bgsave生成rdb文件
- redis-cli -h db01 -p 6379 BGSAVE
-
- 3.使用工具分析:
- cd /data/redis_6379/
- rdb -c memory redis_6379.rdb -f redis_6379.rdb.csv
-
- 4.过滤分析
- awk -F"," '{print $4,$3}' redis_6379.rdb.csv |sort -n
-
- 5.将结果整理汇报给领导,询问开发这个key是否可以删除
预防redis不断写入数据
- 设置内存最大限制
- config set maxmemory 2G
-
- 内存回收机制
- 当达到内存使用限制之后redis会出发对应的控制策略
- redis支持6种策略:
- 1.noevicition 默认策略,不会删除任务数据,拒绝所有写入操作并返回客户端错误信息,此时只响应读操作
- 2.volatile-lru 根据LRU算法删除设置了超时属性的key,指导腾出足够空间为止,如果没有可删除的key,则退回到noevicition策略
- 3.allkeys-lru 根据LRU算法删除key,不管数据有没有设置超时属性
- 4.allkeys-random 随机删除所有key
- 5.volatile-random 随机删除过期key
- 5.volatile-ttl 根据key的ttl,删除最近要过期的key
-
- 动态配置
- config set maxmemory-policy
-
监控过期键
需求背景
因为开发重复提交,导致电商网站优惠卷过期时间失效
问题分析
如果一个键已经设置了过期时间,这时候在set这个键,过期时间就会取消
解决思路
如何在不影响机器性能的前提下批量获取需要监控键过期时间
1.Keys * 查出来匹配的键名。然后循环读取ttl时间
2.scan * 范围查询键名。然后循环读取ttl时间
Keys 重操作,会影响服务器性能,除非是不提供服务的从节点
Scan 负担小,但是需要去多次才能取完,需要写脚本
脚本内容:
- cat 01get_key.sh
- #!/bin/bash
- key_num=0
- > key_name.log
- for line in $(cat key_list.txt)
- do
- while true
- do
- scan_num=$(redis-cli -h 192.168.47.75 -p 6380 SCAN ${key_num} match ${line}\* count 1000|awk 'NR==1{print $0}')
- key_name=$(redis-cli -h 192.168.47.75 -p 6380 SCAN ${key_num} match ${line}\* count 1000|awk 'NR>1{print $0}')
- echo ${key_name}|xargs -n 1 >> key_name.log
- ((key_num=scan_num))
- if [ ${key_num} == 0 ]
- then
- break
- fi
- done
- done

