
- 1android 自定义radiobutton 样式,RadioButton自定义点击时的背景颜色
- 2kafka命令行操作_kafka命令行发送消息
- 3使用 Java api在MongoDB中获取最后插入的文档ID_java mongo插入对象,返回主键到对象的属性中
- 4小梅哥Xilinx FPGA学习笔记15——基于SPI接口的ADC芯片驱动_adc128s102
- 5mysql索引—B+树 查找_b数索引查找过程
- 6SELINUX=enforcing时无法启动httpd服务的解决方案(semanage命令以及setroubleshoot-server插件的妙用)
- 7git教程(基于vscoede)_vscode git版本回退
- 8一个驱动商业创新的业务中台长啥样?让它来告诉你!_社会化商业架构最直接的体现是什么
- 9java微服务应用层join_《中台架构与实现 DDD和微服务》核心思想
- 10深度学习_PyCharm入门_pycharm深度学习
【Redis】Redis 通用命令、键的过期策略、渐进式遍历_渐进性遍历 scan 虽然解决了阻塞的问题,但如果在遍历期间键有所变化(增加、修改、
赞
踩
Redis 有许多种数据结构,但是这些数据结构的 key 的类型都是字符串类型的(所以说,Redis 不同的数据结构都是针对于 value 而言的)。正因如此,对应相同类型的 key 来说,就有一些通用的来操作 Redis 的命令。
一、基础命令
SET 和 GET
SET 和 GET 可以说是 Redis 中最基础也是最核心的两个命令了,Redis 是以键值对的形式来储存数据的,因此对于 Redis 中数据的存取就如同在操作一个哈希表一样。SET的作用就是 把 key 和 value 设置进 Redis,而 GET 则是通过 key 将 value 从 Redis 中取出。
例如下面的操作:
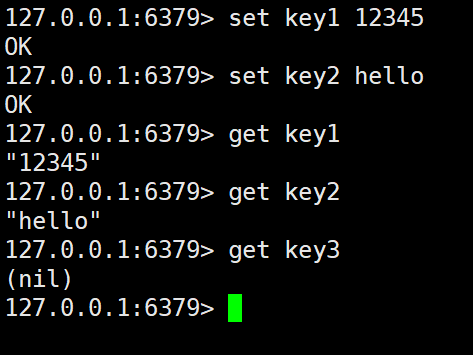
- 上述操作中,使用 SET 命令向 Redis 中添加了一个 key 为
key1,value 为12345和 key 为key2,value 为hello的两个键值对; - 然后再使用 GET key 这样的语法的命令获取到 key 对应的 value 值。
- 如果使用 GET 获取一个不存在的 key 对应的值则会返回
nil(即相当于null)。
注意事项:
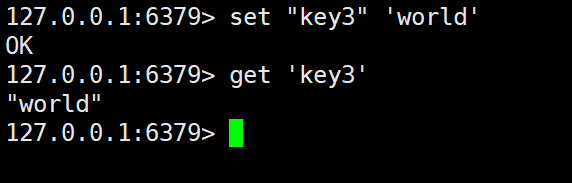
通过上述操作可以发现,在 Redis 中 key 和 value 其实都是字符串,但是不需要加上引号。当然如果想要加的话,单引号和双引号都可以。
二、全局命令
Redis 有许多种数据结构,但是这些数据结构的 key 的类型都是字符串类型的(所以说,Redis 不同的数据结构都是针对于 value 而言的)。正因如此,对应相同类型的 key 来说,就有一些全局通用的来操作 Redis 的命令。
KEYS
KEYS 命令的作用是用来查询当前 Redis 服务器上匹配的所有的 key 的,可以通过一些特殊的通配符来描述 key 的模式,然后就可以查询出 Redis 中所有匹配这个模式的 key 。
keys pattern
- 1
在 Redis 的官方文档中给出 KEYS 的模式类型如下:

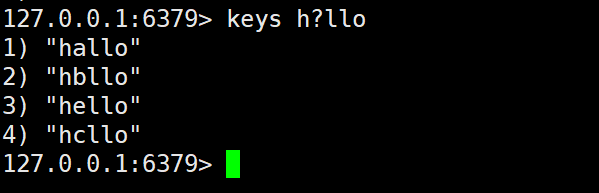
a)? 符号的作用是匹配一个字符
例如:当 pattern 为 h?llo 的时候,就能匹配到如:hello、hallo、hxllo 这样的 key。
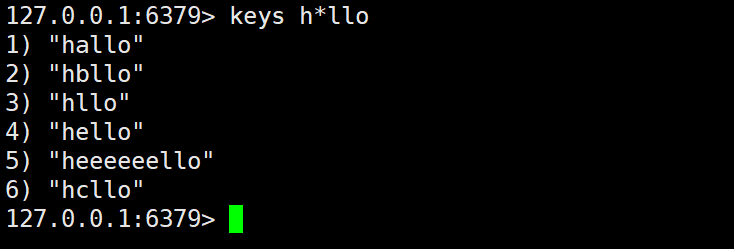
b)* 符号的作用是匹配 0 个或多个任意字符
例如:当 pattern 为 h*llo 的时候,就能匹配到如:hllo、heeeello 这样的 key。
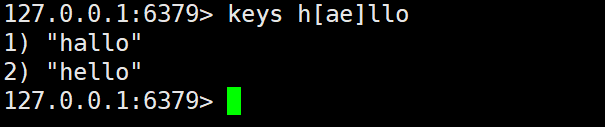
c)[ae] 符号的意思只匹配 a 或 e 这样的
例如:当 pattern 为 h[ae]llo 的时候,就能匹配到 hallo、hello,但是不会匹配到 hillo。
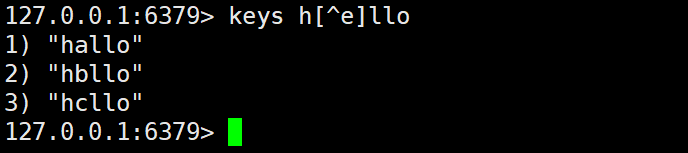
d)[^e] 符号的意思是匹配非 e 的
例如:当 pattern 为 h[^e]llo 的时候,就不会到 hello,但能匹配到其他的如 hallo、hbllo 这样的。
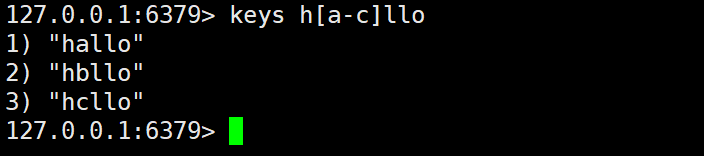
f)[a-b] 符号的意思是匹配 a ~ b 之间的
例如:当 pattern 为 h[a-e]llo 的时候,就能匹配到 hallo、hello 这样的。
关于 KEYS 命令的注意事项:
在实际生产环境中,要谨慎使用命令
keys *,因为这条命令会查询出当前 Redis 中储存的所有 key,其时间复杂度为 O(N)。如果使用了该命令,可能会造成一些严重的后果:
- 由于 Redis 是用单线程处理命令的,如果使用
keys *命令的话,就可能导致 Redis 会执行很长时间,而在此期间无法为其他用户提供服务了。- Redis 常作为 MySQL 这样的数据库的挡箭牌(缓存),一旦因为
keys *导致数据无法从 Redis 中获取(Redis 阻塞),累计的大量的其他请求超时后就会从数据库中去查询数据,此时 MySQL 这样的数据库可能就会措手不及了,非常有可能造成数据库崩溃。
EXISTS
exists 命令的作用是判断某个 key 是否存在。如果存在则返回 1, 不存在则返回 0。
其语法格式为:
exists key [key ...]
- 1
那么就意味着 exists 命令可以单独查询一个 key,也可以同时查询多个 key:
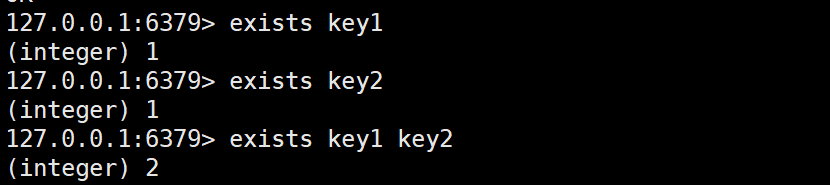
使用 EXISTS 命令的注意事项:
- Redis 查询某个 key 是否存在的时间复杂度是 O(1),因为 Redis 组织这些 key 是以哈希表这样的数据结构来组织的。
- 尽管 Redis 查询某个 key 是否存在的时间复杂度是 O(1),但是由于 Redis 是以单线程来处理命令的,并且 Redis 的客户端与服务器是通过网络进行通信的,因此同时查询多个 key 的效率比分开查询单个 key 时的效率要高得多。
DEL
DEL 命令的功能是删除指定的 key,删除成功返回 1,失败则返回 0。
使用语法:
del key [key ...]
- 1
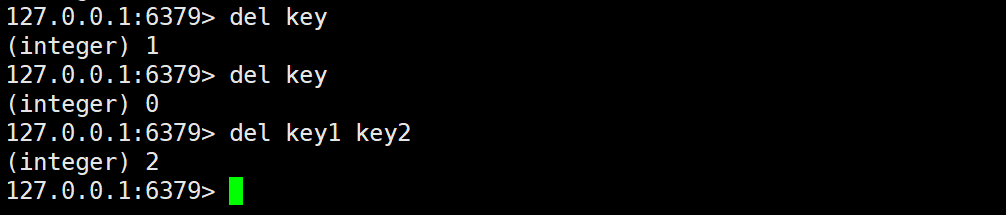
和 EXISTS 命令一样,执行 DEL 命令的时间复杂度也是 O(1),可以单独删除一个 key,也可以同时删除多个 key,但注意应该同时删除多个 key 以避免影响 Redis 的性能。
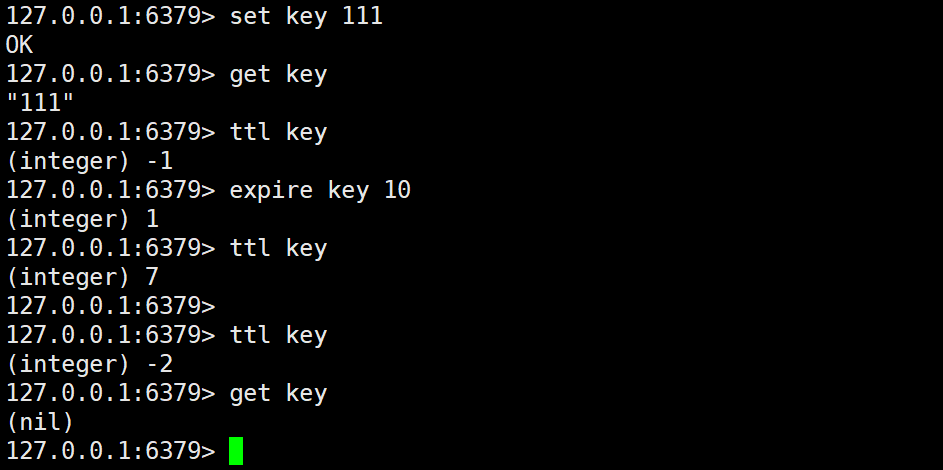
EXPIRE 和 TTL
EXPIRE 命令的作用是为 key 指定一个秒级的过期时间,当然还有一个命令 PEXPIER,其指定的是毫秒级别的过期时间,当 key 过期之后则会删除这个 key。而 TTL 命令的作用是获取某个 key 剩余的过期时间,如果没有设置过期时间则返回 - 1,已经超时了则返回 - 2。
EXPIRE 的使用语法:
expire key seconds
- 1
TTL 的使用语法:
ttl key
- 1
使用例子:
经典面试题:Redis 中 key 的过期策略是怎么实现的
如下图所示,展示了 key 设置了超时时间然后到过期的整个过程:
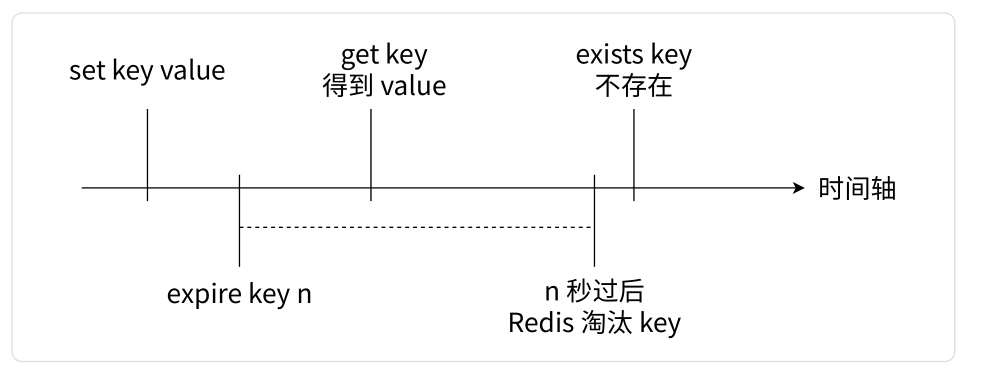
在实际生成环境中,Redis 存在了大量的 key,并且大多数的 key 都是设置了超时时间的。对于 Redis 来说,内存空间是极其宝贵的资源,如果不及时清理过期的 key,就会浪费大量的内存空间。
那么如何清理这些随时会过期的 key 呢?
可能一拍脑门就会想到定时在所有的 key 里面去找出过期的 key 并清除,乍一看实现起来非常简单,但是别忘了,Redis 是使用多线程来处理任务的,如果以这样的方式去清理 key 的话,那么 Redis 的生命周期早就结束了。
实际上,简单来说 Redis 中 key 的过期策略是 定期删除与惰性删除相结合:
1. 定期删除
定期删除是 Redis 中的一种主动过期检查机制。
Redis 定期地(默认每秒钟10次,可以在配置文件中进行调整)随机选择一些已设置过期时间的键,并检查它们的过期时间是否已到。如果键已经过期,Redis 会将其删除。
并且,Redis 会在每次执行定期删除操作时,随机选择一部分键进行检查和清理。这样做是为了分散定期删除操作对性能的影响,以免在某一刻集中删除大量过期键。
2. 惰性删除
惰性删除是 Redis 中的被动过期检查机制。
当客户端尝试读取一个键的值时,Redis 会首先检查该键的过期时间。如果键已经过期,Redis 不会返回它的值,而是立即将其删除。惰性删除确保了在键被访问时,如果已经过期,会立即删除。这降低了过期键在内存中积累的可能性。
综合使用这两种方法,Redis 实现了高效的键过期策略,但仍然可能存在一些过期键没有及时清理的情况,特别是在大量过期键堆积时。为了确保过期键的及时清理,还可以考虑以下方法:
-
设置适当的过期时间: 在配置文件中,为键设置合理的过期时间,以确保不会在内存中积累大量过期键。
-
使用内存淘汰策略: Redis 提供了不同的内存淘汰策略,如LRU(最近最少使用)、LFU(最不经常使用)等。通过选择适当的淘汰策略,可以在内存不足时主动删除一些键,包括过期键。
-
定期扫描和清理: 可以定期执行自定义脚本或任务来扫描和清理过期键。这样可以确保即使 Redis 主线程繁忙,也有一个独立的任务负责清理过期键。
-
使用 Redis 的 Pub/Sub 功能: 可以使用 Redis 的发布/订阅功能来实现一个过期键的监控系统。当键过期时,Redis 可以发布一个消息,然后订阅者可以处理这些消息来执行清理操作。
综合使用这些方法,可以确保 Redis 中的过期键得到及时清理,从而维护内存的稳定和性能。
TYPE
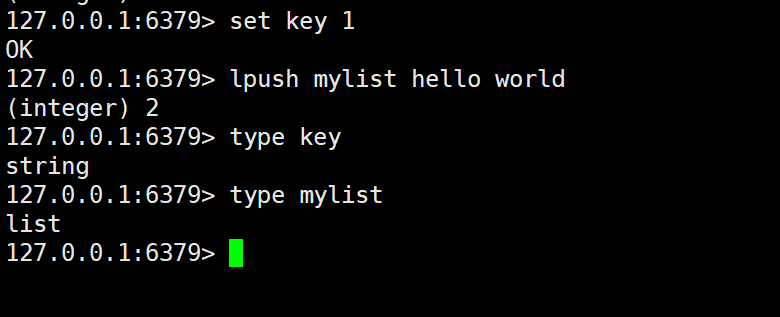
TYPE 命令的作用是返回指定 key 对应 value 的数据类型。
其语法为:
type key
- 1
例如:
三、渐进式遍历
SCAN 命令用于渐进式遍历键,以避免 KEYS 命令可能导致的阻塞问题。SCAN 命令的语法如下:
SCAN cursor [MATCH pattern] [COUNT count] [TYPE type]
- 1
其中,各个选项的说明如下:
-
cursor:游标,用于迭代遍历。初始时,可以将游标设置为 0,然后根据返回的新游标来继续遍历。这个参数是必需的。 -
MATCH pattern(可选):用于匹配指定模式的键。只返回匹配模式的键。这个参数是可选的。 -
COUNT count(可选):指定每次遍历返回的元素数量。这有助于控制一次扫描的数据量,减轻服务器的负担。这个参数是可选的。 -
TYPE type(可选):指定要匹配的键的类型,例如 STRING、LIST、SET、ZSET、HASH。这个参数是可选的。
使用 SCAN 命令的好处是它可以将键的遍历分布在多个迭代中,以便逐步获取数据,而不会在一次操作中返回大量键,从而导致阻塞。这对于大型数据库非常有用,因为它允许你在不影响 Redis 性能的情况下获取所有键。
注意,由于 Redis 数据可能在迭代期间发生变化,因此迭代期间新增或删除的键可能会被忽略或遍历多次,具体取决于 SCAN 命令的调用时机。
例如,使用 SCAN 遍历所有 key 的整个过程如下图 所示:

说明:
- 首次使用 SCAN 命令从 0 位置开始遍历;
- 未遍历完成时,会返回下一次遍历的开始位置;
- 当 SCAN 命令返回的下次位置为 0 时,表示遍历结束;
- count 指定一次遍历数量仅供参考,Redis 会根据实际情况做出调整,即 Redis 并不保证严格遵循该数量。
除了SCAN 命令以外,Redis 面向哈希类型、集合类型、有序集合类型分别提供了HSCAN、SSCAN、ZSCAN 命令,它们的用法和 SCAN 命令基本类似。
渐进性遍历 SCAN 虽然解决了阻塞的问题,但如果在遍历期间键有所变化(增加、修改、删除),可能导致遍历时键的重复遍历或者遗漏,这点务必在实际开发中考虑。

