
热门标签
热门文章
- 1Flask-SQLAlchemy、Flask-migrate、flask-script、flask-upload_sqlalchemy 1.3.19插件安装包
- 2简述人工智能的研究目标_人工智能的目标是什么?研究内容主要有哪些?2.图灵测试和中文房间问题的主要内
- 3网络原理-TCP/IP --传输层(UDP)
- 4PTA天梯赛习题 L2-006 树的遍历_pta l2树的遍历c++
- 5Verilog语言之结构语句:Always过程块和assign连续赋值语句_assign语句可以嵌入到always块中
- 6搭建自己的git服务器、配置公钥私钥(解决每次 clone push需要密码问题)_git服务器需要配置公密和私密吗?
- 7CPU密集型和IO密集型对 CPU内核之间的关系
- 8Android中使用MediaCodec视频编码异步实现_getdequeueencode()
- 9麒麟V10(SP1\23)服务器镜像包(干货分享)_麒麟v10镜像大小
- 10MongoDB基础之索引详解_mongodb索引
当前位置: article > 正文
python+Tesseract OCR实现截屏识别文字_tesseractocr下载教程
作者:小小林熬夜学编程 | 2024-06-04 22:47:02
赞
踩
tesseractocr下载教程
一、tesseract-ocr下载安装
1、下载
以下是关于Tesseract的常用网址
下载地址:https://digi.bib.uni-mannheim.de/tesseract/
官方网站:https://github.com/tesseract-ocr/tesseract
官方文档:https://github.com/tesseract-ocr/tessdoc
语言包地址:https://github.com/tesseract-ocr/tessdata
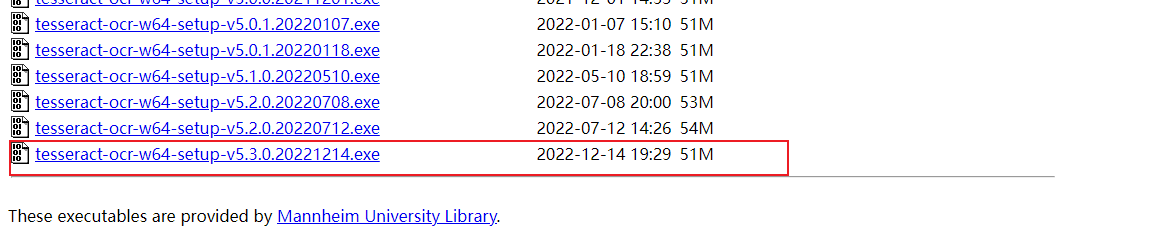
2、安装tesseract-ocr
(1)选择语言
(2)开始安装

(3)同意许可

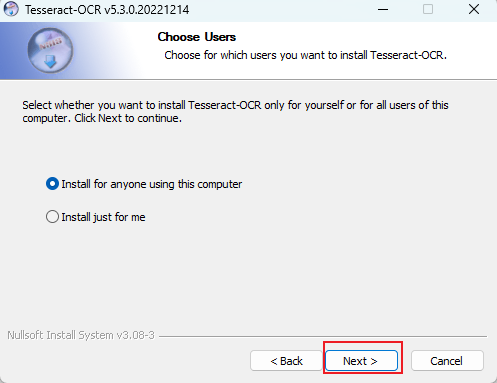
(4)选择安装的用户
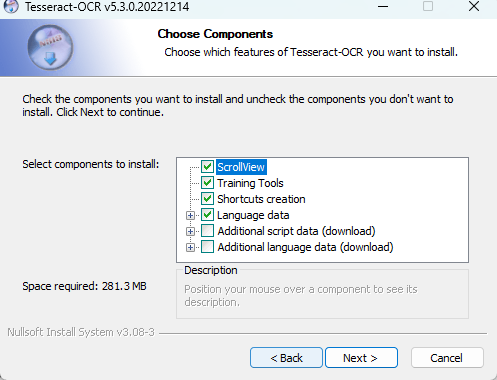
(5)选择附带要安装的语言包
此后会在安装过程中会自动从服务器下载该语言包。(这里不太建议勾选下载语言包,因为下载速度实在太慢。本教程后续会介绍如何拓展语言包,但如果已经翻墙的话,可以忽略这个建议。)
默认即可。
(6)安装位置
(7)开始安装

(8)安装完成
3、安装语言包
(1)下载安装
https://github.com/tesseract-ocr/tessdata
项目较大,可以按需下载简体中文:

将下载的文件存放到该目录:D:\Program Files\Tesseract-OCR\tessdata
注:若小伙伴无法科学上网,可以从这里下载简体中文语言包:https://download.csdn.net/download/A_art_xiang/88334913
(2)测试
进入到Tesseract OCR安装目录:
# 查看版本 PS D:\Program Files\Tesseract-OCR> .\tesseract.exe -v tesseract v5.3.0.20221214 leptonica-1.78.0 libgif 5.1.4 : libjpeg 8d (libjpeg-turbo 1.5.3) : libpng 1.6.34 : libtiff 4.0.9 : zlib 1.2.11 : libwebp 0.6.1 : libopenjp2 2.3.0 Found AVX2 Found AVX Found FMA Found SSE4.1 Found libarchive 3.5.0 zlib/1.2.11 liblzma/5.2.3 bz2lib/1.0.6 liblz4/1.7.5 libzstd/1.4.5 Found libcurl/7.77.0-DEV Schannel zlib/1.2.11 zstd/1.4.5 libidn2/2.0.4 nghttp2/1.31.0 # 查看安装的语言包 PS D:\Program Files\Tesseract-OCR> .\tesseract.exe --list-langs List of available languages in "D:\Program Files\Tesseract-OCR/tessdata/" (4): chi_sim chi_sim_vert eng osd

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
二、python截屏识别文字
1、安装必须的包
pip install pyautogui
pip install pytesseract
- 1
- 2
2、截屏识别文字
import pyautogui import pytesseract # 设置Tesseract的安装路径(如果它不在默认的系统路径中) pytesseract.pytesseract.tesseract_cmd = 'D:/Program Files/Tesseract-OCR/tesseract.exe' # 截取屏幕截图 screenshot = pyautogui.screenshot() # 定义区域范围(左上角x坐标,左上角y坐标,右下角x坐标,右下角y坐标) region = (100, 100, 300, 200) # 从屏幕截图中使用指定区域创建一个新的图像对象 custom_screenshot = screenshot.crop(region) # 将图像对象转换为灰度图像,以帮助提高文本识别的准确性 custom_screenshot = custom_screenshot.convert('L') # 使用pytesseract进行文字识别 text = pytesseract.image_to_string(custom_screenshot) # 打印识别的文本 print(text)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
3、准确度
英文准确度还行,中文准确度。。。一言难尽。应该是可以通过训练提高准确度的。
参考资料
https://blog.csdn.net/weixin_51571728/article/details/120384909
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/小小林熬夜学编程/article/detail/673833
推荐阅读
相关标签

