
- 1信号处理基础之噪声与降噪(二)| 时域降噪方法(平滑降噪、SVD降噪)python代码实现_信号去噪平滑度指标
- 2【网络安全 | CTF】攻防世界 simple_php 解题详析_小宁听说php是最好的语言,于是她简单学习之后写了几行php代码。
- 3MobileNet实战:tensorflow2(1),2024年最新跳槽 面试
- 4微信小程序实现 API Promise 化_微信小程序new promise
- 5GitHub的Fork的作用(Github fork 和 git clone的区别)_fork仓库的好处
- 6数据可视化分析教学课件——FineBI实验册节选====高校招生数据分析_招生、流失可视化分析
- 7【日常问题】解决git clone提示unable to access 问题_git clone unable to access
- 8【自然语言处理】【大模型】DeepSeek-V2论文解析_deepseek v2
- 9外卖扫码点餐全开源小程序源码_点餐小程序下载开源
- 10YoloV8改进策略:蒸馏改进|CWDLoss|使用蒸馏模型实现YoloV8无损涨点|特征蒸馏
Flink的高可用集群环境_flink1.19 生产环境用哪种集群模式
赞
踩
JobManager高可用(HA)
JobManager协调每一个Flink集群环境,它负责作业调度和资源管理。默认情况下,一个Flink集群中只有一个JobManager实例,这很容易造成单点故障(SPOF)。如果JobManager奔溃了,那么将没有新的程序被提交,同时运行的程序将失败。
对于JobManager高可用来说,我们可以从失败的JobManager中恢复,因此可以消除单点故障的问题。我们可以配置Standalone模式和YARN集群模式下的高可用。
Standalone集群模式高可用
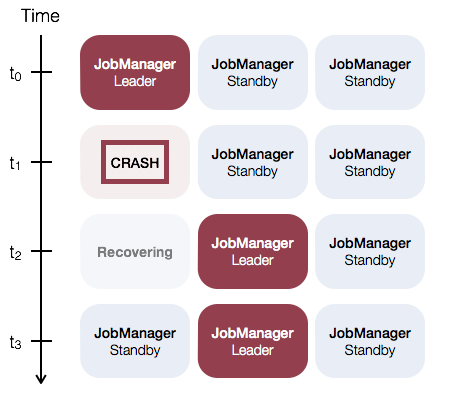
对于Standalone集群模式下的JobManager高可用通常的方案是:Flink集群的任一时刻只有一个leading JobManager,并且有多个standby JobManager。当leader失败后,standby通过选举出一个JobManager作为新的leader。这个方案可以保证没有单点故障的问题。对于standby和master JobManager实例来说,其实没有明确的区别,每一个JobManager能够当担master或standby角色。
下面举一个有三个JobManager实例的例子:
相关配置
为了保证JobManager高可用,你需要设置Zookeeper为recovery mode(恢复模式),配置一个Zookeeper quorum并且对所有的JobManager节点和它们的Web UI端口号设置一个masters文件。
Flink引入Zookeeper的目的主要是让JobManager实现高可用(leader选举)
Flink使用Zookeeper在所有运行的JobManager实例中进行分布式调度的协调。Zookeeper在Flink中是一个独立的服务,它能够通过leader选举和轻量级的一致性状态存储来提供高度可靠的分布式协调器。
Master File(masters)
为了启动一个HA-cluster,需要在conf/masters中配置masters。
l masters文件:masters文件包含所有的hosts,每个host启动都JobManager,并且指定绑定的Web UI端口号。
jobManagerAddress1:webUIPort1
[...]
jobManagerAddressX:webUIPortX
默认情况下,JobManager挑选随机的端口号作为内部进程交互。我们可以通过recovery.jobmanager.port的值来修改,这个参数配置的值为单个端口号(比如50010),范围为50000~50025,或者端口号组合(比如50010,50011,50020~50025,50050~50075)。
配置文件flink-conf.yaml
为了启动一个HA-Cluster,需要在conf/flink-conf.yaml添加如下配置参数:
l Recovery mode(必须的):
recovery.mode: zookeeper
l Zookeeper quorum(必须的):
recovery.zookeeper.quorum: address1:2181,...
l Zookeeper root(推荐的):Flink在Zookeeper中的root节点,下面放置所有需要协调的数据
recovery.zookeeper.path.root: /flink
如果你运行多个Flink HA集群,那么你必须手工配置每个Flink集群使用独立的root节点。
l State backend and storage directory(必须的):JobManager元数据在statebackend保持并且仅仅在Zookeeper中存储,目前在HA模式中,仅支持filesystem。
state.backend: filesystem
state.backend.fs.checkpointdir:hdfs://namenode-host:port/flink-checkpoints
recovery.zookeeper.storageDir: hdfs:///recovery
recovery.zookeeper.storageDir指定的路径中存储了所有的元数据,用来恢复失败的JobManager。
示例:拥有两个JobManager的Standalone模式下的集群
步骤一:在conf/flink-conf.yaml文件中配置恢复模式和Zookeeper quorum
recovery.mode: zookeeper
recovery.zookeeper.quorum: gpmaster:2181,gpseg:2181
recovery.zookeeper.path.root: /flink # important: customizeper cluster
state.backend: filesystem
state.backend.fs.checkpointdir: hdfs://gpmaster:9000/flink/checkpoints
recovery.zookeeper.storageDir: hdfs://gpmaster:9000/flink/recovery
步骤二:配置conf/masters文件
gpmaster:8081
gpseg:8081
步骤三:配置conf/zoo.cfg文件,添加Zookeeper集群节点(目前仅支持一个节点运行一个Zookeeper服务)
server.1=gpmaster:2888:3888
server.2=gpseg:2888:3888
步骤四:启动Zookeeper集群
[hadoop@gpmaster flink]$ bin/start-zookeeper-quorum.sh
Starting zookeeper daemon on host gpmaster.
Starting zookeeper daemon on host gpseg.
步骤五:启动HA-Cluster
[hadoop@gpmaster flink]$ bin/start-cluster.sh
Starting HA cluster with 2 masters.
Starting jobmanager daemon on host gpmaster.
Starting jobmanager daemon on host gpseg.
Starting taskmanager daemon on host gpmaster.
Starting taskmanager daemon on host gpseg.
如果想停止Flink集群,如下:
bin/stop-cluster.sh
bin/stop-zookeeper-quorum.sh
YARN集群模式高可用
当运行一个高可用YARN集群时,我们不需要运行多个JobManager(ApplicationMaster)实例,只需要运行一个实例,如果失败了通过YARN来进行重启。
相关配置
1. 在yarn-site.xml中配置最大的Application Master Attempts
<property>
<name>yarn.resourcemanager.am.max-attempts</name>
<value>4</value>
<description>
The maximumnumber of application master execution attempts.
</description>
</property>
当前YARN版本的默认值为2(意味着单个JobManager失败是可以容忍的)。
2. 在flink-conf.yaml中配置Application Attempts
yarn.application-attempts: 10
这意味着这个application可以在YARN使application失败之前可以重启10次。需要注意的是yarn.resourcemanager.am.max-attempts此application重启的上限值。
3. Container终止的方式
YARN 2.3.0 < version < 2.4.0:如果application失败,那么所有的containers将重启。
YARN 2.4.0 < version < 2.6.0:TaskManager containers在application master失败时保持活着状态,这样后续可以更快地启动,用户不用再等待去获取container资源。
YARN 2.6.0 <= version:设置attempt failure validity interval为Flink的Akka超时值。
这样可以避免一个长时间运行作业耗尽它的application尝试次数。
示例:
步骤一:在conf/flink-conf.yaml文件中配置恢复模式和Zookeeper quorum
recovery.mode: zookeeper
recovery.zookeeper.quorum: gpmaster:2181,gpseg:2181
recovery.zookeeper.path.root: /flink # important: customizeper cluster
state.backend: filesystem
state.backend.fs.checkpointdir:hdfs://gpmaster:9000/flink/checkpoints
recovery.zookeeper.storageDir:hdfs://gpmaster:9000/flink/recovery
yarn.application-attempts: 10
步骤二:配置conf/zoo.cfg文件,添加Zookeeper集群节点(目前仅支持一个节点运行一个Zookeeper服务)
server.1=gpmaster:2888:3888
server.2=gpseg:2888:3888
步骤三:启动Zookeeper集群
[hadoop@gpmaster flink]$ bin/start-zookeeper-quorum.sh
Starting zookeeper daemon on host gpmaster.
Starting zookeeper daemon on host gpseg.
步骤四:启动HA-Cluster
bin/yarn-session.sh -n 2
如果想停止Flink集群,如下:
yarn application -kill application_1474621817184_0001 #启动的applicationID
bin/stop-zookeeper-quorum.sh

