
- 1ADB获取手机分辨率的多种方法,解决部分手机获取不到的问题_adb调手机分辨率
- 2GIt常用指令、概念及原理分析,图解rebase、merge指令区别,stash、reset贮藏重置等指令详解,每一条指令都有详细说明,值得收藏!_git rm stash
- 3Python自然语言处理笔记(五)------获取文本语料库_什么函数用于获取语料库中的文件
- 4ESP8266 01sWiFi模块保姆级教程 烧录和联网,连接华为云_esp8266wifi模块如何连接网络
- 5PostgreSQL11 | 数据类型和运算符_pgsql boolean相关函数
- 6开篇,对想学Java的小伙伴说点掏心窝子的大实话_程序员青戈怎么样
- 7[开题报告]Springboot会议室预约管理系统0bcs4计算机毕业设计
- 82024年运维最全升级Linux下的sudo_sudo v1(1),2024年最新原理+实战+视频+源码_sudo最新补丁包下载
- 9hive建表_hive创建外部表并指定存储位置
- 10LangChain快速加proxy代理_langchain openai proxy
Sqoop数据迁移,导入数据至hdfs,hive,hbase,mysql_sqoop概述
赞
踩
Sqoop数据迁移
一、Sqoop概述
Sqoop是什么?
Sqoop是一个用于在Hadoop和关系数据库之间传输数据的工具。
将数据从RDBMS(Relational Database Management System)导入到HDFS、Hive、HBase
从HDFS导出数据到RDBMS
使用MapReduce导入和导出数据,提供并行操作和容错。
对于某些NoSQL数据库它也提供了连接器。Sqoop,类似于其他ETL工具,使用元数据模型来判断数据类型并在数据从数据源转移到Hadoop时,确保类型安全的数据处理。Sqoop专为大数据批量传输设计,能够分割数据集并创建Hadoop任务来处理每个区块。
二、Sqoop数据迁移
1.从RDB(Relational Database)导入数据到HDFS
准备工作:
素材下载:retail_db.sql脚本及customer.csv表数据
链接:https://pan.baidu.com/s/1GlFMDnN21kiIsKa1MyR5KQ
提取码:wmm1
-
首先将sql文件 retail_db.sql 上传至linux /opt/software/sqoop/ 目录下

-
mysql中建库建表:
//创建数据库
mysql> create database retail_db;
mysql> use retail_db;
//执行sql语句
mysql> source /opt/software/sqoop/retail_db.sql
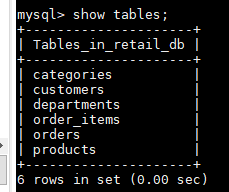
mysql> show tables;
- 1
- 2
- 3
- 4
- 5
- 6
展示如下:
1.1全量导入数据(customers)
在linux命令行执行:
sqoop import \
--connect jdbc:mysql://localhost:3306/retail_db \
--driver com.mysql.jdbc.Driver \
--table customers \
--username root \
--password ok \
--target-dir /data/retail_db/customers \
-m 3
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
相关参数解析:\ 表示换行
sqoop import \
--connect jdbc:mysql://localhost:3306/retail_db \ #配置数据库连接为mysql数据库
--driver com.mysql.jdbc.Driver \ #加载jdbc驱动
--table customers \ #将customer表上传至hdfs中
--username root \ #mysql的用户名
--password ok \ #mysql用户名密码
--target-dir /data/retail_db/customers \ #指定hdfs上传的路径
-m 3 #设置Mapper的数量
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
注: -m 参数能够设置导入数据的 map 任务数量,m>1 表示导入方式为并发导入,这时我们必须同时指定 - -split-by (分割列 int)参数指定根据哪一列来实现哈希分片,从而将不同分片的数据分发到不同 map 任务上去跑,避免数据倾斜。
执行完成可以在hdfs web端50070端口 /data/retail_db/customers 路径下看到customers表信息,12435条数据被分成了3个分区存储

在linux上查看导入的customers表数据:
hdfs dfs -cat /data/retail_db/customers/part-m-00000
- 1
如下:

1.2通过Where语句过滤导入表(orders)
where条件: order_id < 500
sqoop import \
--connect jdbc:mysql://localhost:3306/retail_db \
--driver com.mysql.jdbc.Driver \
--table orders \
--where "order_id < 500" \
--username root \
--password ok \
--delete-target-dir \
--target-dir /data/retail_db/orders \
-m 3
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
注: 此处 delete-target-dir 表示删除hdfs目标路径的目录,因为之前1.1中已经创建过目标customers表文件,产生了数据,所以需先删除原先的目标路径文件,不然会起冲突报错
执行成功如图:

在linux上查看导入的orders表数据:
hdfs dfs -cat /data/retail_db/orders/part-m-00002
- 1
如下:

可以看到order_id最大为499,满足where条件,导入执行成功
1.3通过COLUMNS过滤导入表(customers)
选择导入字段: customer_id,customer_fname,customer_lname
sqoop import \
--connect jdbc:mysql://localhost:3306/retail_db \
--driver com.mysql.jdbc.Driver \
--table customers \
--columns "customer_id,customer_fname,customer_lname" \
--username root \
--password ok \
--delete-target-dir \
--target-dir /data/retail_db/customers \
-m 3
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
执行成功如下图:

在linux上查看导入的customers表数据:
hdfs dfs -cat /data/retail_db/customers/part-m-00000
- 1
如下:

可以看到只显示3个字段:customer_id,customer_fname,customer_lname ,导入成功
1.4使用query方式导入数据
使用查询语句: select * from orders where order_status!=‘CLOSED’
sqoop import \
--connect jdbc:mysql://localhost:3306/retail_db \
--driver com.mysql.jdbc.Driver \
--query "select * from orders where order_status!='CLOSED' and \$CONDITIONS" \
--username root \
--password ok \
--split-by order_id \
--delete-target-dir \
--target-dir /data/retail_db/orders \
-m 3
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
注: 使用查询语句导入时,
- 需要在查询语句末尾加上 and $CONDITIONS ,表示sqoop内部使用该条件将记录范围分发给所有Mapper
- split-by order_id 表示指定用于分割数据的列为 order_id (数据切片字段(int类型,m>1时必须指定))
执行成功可以看到下图:

在linux上查看导入的orders表数据:
hdfs dfs -cat /data/retail_db/orders/part-m-00000
- 1
如下:

可以看到订单状态都为非关闭状态,则导入成功
1.5使用Sqoop增量导入数据
由于在生产环境中,系统可能会定期从与业务相关的关系型数据库向Hadoop导入数据,导入数仓后进行后续离线分析。这时就不需要再将所有数据重新导一遍,所以引入增量导入模式可以只导入增加的数据,速度上会快很多。
增量数据模式分为两种:①基于递增列的增量数据导入(Append方式)
②:基于时间列的增量数据导入(LastModified方式)
①: 使用 Append 递增列方式插入:
mysql中查询customers表数据得知:(select * from customers;)

customer_id 最大为12435
先将customers表数据全量导入至hdfs中,见1.1
sqoop import \
--connect jdbc:mysql://localhost:3306/retail_db \
--driver com.mysql.jdbc.Driver \
--table customers \
--username root \
--password ok \
--delete-target-dir \
--target-dir /data/retail_db/customers \
-m 3
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
然后在mysql中往customers表插入一些数据:
insert into customers values
(12436,'kitty','xxx','xxx','xxx','xxx','xxx','xxx','xxx'),
(12437,'mimi','xxx','xxx','xxx','xxx','xxx','xxx','xxx'),
(12438,'mystic','xxx','xxx','xxx','xxx','xxx','xxx','xxx');
- 1
- 2
- 3
- 4
查询一下:(select * from customers;)

刚才三条数据已经成功插入
现在要将刚才新增的三条数据以增量的形式导入到hdfs中
代码如下:
sqoop import \
--connect jdbc:mysql://localhost:3306/retail_db \
--table customers \
--username root \
--password ok \
--split-by customer_id \
--incremental append \
--check-column customer_id \
--last-value 12435 \
--target-dir /data/retail_db/customers \
-m 3
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
注: incremental 表示指定增量导入的模式,此处指定为append
check-column 递增列(int),此处指定为cusomer_id
last-value 阈值(int),此处表示customer_id>12435都会被插入
执行成功如图:

在linux上查看导入的orders表数据:
hdfs dfs -cat /data/retail_db/orders/part-m-00000
- 1
如下:

可以看到新增的三条数据已经成功导入
②:使用 lastModify 时间列方式 插入
此方式要求原有表中有time字段,它能指定一个时间戳,让Sqoop把该时间戳之后的数据导入到HDFS。
比如说在订单表orders中,后续订单可能状态会变化,变化后time字段时间戳也会变化,此时Sqoop依然会将相同状态更改后的订单导入HDFS,此时可以指定merge-key参数为orser_id,表示将后续新的记录与原有记录合并。
示例:
首先将数据全量导入至hdfs中:
sqoop import \
--connect jdbc:mysql://localhost:3306/retail_db \
--driver com.mysql.jdbc.Driver \
--table orders \
--username root \
--password ok \
--split-by order_id \
--delete-target-dir \
--target-dir /data/retail_db/orders \
-m 3
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
hdfs上数据信息:

在mysql中查看orders表数据:(select * from orders;)
插入以下数据:
insert into orders values
(68884,'2020-1-18',123,'complete'),
(68885,'2020-2-18',123,'complete'),
(68886,'2020-3-18',123,'complete'),
(68887,'2020-4-18',123,'complete');
- 1
- 2
- 3
- 4
- 5
现在使用 lastModify 增量导入,将修改过的以及新增的表数据都导入到hdfs上
执行以下代码:
sqoop import \
--connect jdbc:mysql://localhost:3306/retail_db \
--table orders \
--username root \
--password ok \
--incremental lastmodified \
--merge-key order_id \
--split-by order_id \
--check-column order_date \
--last-value '2014-07-24 00:00:00' \
--target-dir /data/retail_db/orders \
-m 3
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
注: incremental lastmodified 指定增量模式为时间列(将时间列大于等于阈值的所有数据增量导入hdfs)
check-column 时间列(int)
last-value 阈值(int)
merge-key 合并列(主键,合并键值相同的记录)
执行成功在hdfs删显示如下

此时刚插入的4条数据已经导入进来,并且oeder_id顺序混乱,只是由于虽然指定Mapper数量为3,但是实际上并没有分区,而又全部将数据重新并发写入到了一个分区中,这种增量导入的方式并不推荐,工作中常用的是使用静态分区指定分区列,增量插入
2.从RDB(Relational Database)导入数据到hive
将mysql中 “orders” 表数据导入到 hive 中
- 在hive上创建数据库
create database retail_db;
- 1
- 将 orders 表数据导入到hive中
sqoop import \
--connect jdbc:mysql://localhost:3306/retail_db \
--table orders \
--username root \
--password ok \
--hive-import \
--create-hive-table \
--hive-database retail_db \
--hive-table orders \
--m 3
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
执行成功显示下图信息:

3. 导入数据到hive分区表中,要求表不存在,或者表是分区表
sqoop import \ --connect jdbc:mysql://localhost:3306/retail_db \ --driver com.mysql.jdbc.Driver \ --query "select order_id,order_status from orders where order_date>='2013-11-03' and order_date<'2013-11-04' and \$CONDITIONS" \ --username root \ --password ok \ --delete-target-dir \ --target-dir /data/retail_db/orders \ --split-by order_status \ --hive-import \ --create-hive-table \ --hive-database retail_db \ --hive-table orders \ --hive-partition-key "order_date" \ --hive-partition-value "2013-11-03" \ --m 3

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
执行成功后在hdfs上显示:

在hive 中可以查询到orders表数据,如下图:

3.从RDB(Relational Database)导入数据到HBase
将mysql中 “orders” 表数据导入到 hbase 中
- 在hbase中创建表
create 'orders','msg'
- 1
- 导入数据至hbase
//重要参数解析: //--table 指定导入HBase的表 //--hbase-table HBase中的表 //--column-family 列簇 //--hbase-row-key 行键 sqoop import \ --connect jdbc:mysql://localhost:3306/retail_db \ --driver com.mysql.jdbc.Driver \在这里插入图片描述 --username root \ --password ok \ --table orders \ --hbase-table orders \ --columns "order_id,order_date,order_customer_id,order_status" \ --column-family msg \ --hbase-row-key order_id \ --m 1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
在hbase中查看数据: scan 'orders ,数据存在,说明导入成功
4.从hdfs导出数据到MySQL
- 先在mysql创建一个空表
create table `customers_demo` (
`customer_id` int(11),
`customer_fname` varchar(45),
`customer_lname` varchar(45),
`customer_email` varchar(45),
`customer_password` varchar(45),
`customer_street` varchar(255),
`customer_city` varchar(45),
`customer_state` varchar(45),
`customer_zipcode` varchar(45)
);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 在hdfs上创建目录,上传表数据 customers.csv
hdfs dfs -mkdir /customerinput/table
hdfs dfs -put customers.csv /customerinput/table
- 1
- 2
- 导入数据至mysql
sqoop export \
--connect jdbc:mysql://localhost:3306/retail_db \
--driver com.mysql.jdbc.Driver \
--username root \
--password ok \
--table customers_demo \
--export-dir /customerinput/table \
-m 1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
在mysql中查看数据: select * from customers_demo; ,数据存在,说明导入成功
三、执行Sqoop脚本
#sqoop脚本 #1编写脚本job_RDBMS2HDFS.opt,内容如下 ############################# import --connect jdbc:mysql://hadoop01:3306/retail_db --driver com.mysql.jdbc.Driver --table customers --username root --password root --target-dir /data/retail_db/customers --delete-target-dir --m 3 ############################## #2执行脚本 sqoop --options-file job_RDBMS2HDFS.opt
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
四、执行Sqoop job任务
#创建job 注意import前必须有空格 sqoop job \ --create mysqlToHdfs \ -- import \ --connect jdbc:mysql://localhost:3306/retail_db \ --table orders \ --username root \ --password ok \ --incremental append \ --check-column order_date \ --last-value '0' \ --target-dir /data/retail_db/orders \ --m 3 #查看job sqoop job --list #执行job,可设置crontab定时执行 用的比较多 sqoop job --exec mysqlToHdfs
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18

