
- 1SpringAOP的实现原理_spring aop 实现原理
- 2可以说今年最详细的面试要点!耗时两个礼拜,五章8000字面试长文,写简历—阿里Offer一步到位!(2)
- 3meta-data android,AndroidManifest meta-data 知识介绍
- 4如何使用Python从视频中提取图像?(帧提取)详细代码实现_python 读取特定路径下的视频文件,并对视频中的图像进行编号,最后将编号后的图像
- 5uCOS-II v2.52在MCS-51系列单片机上的移植实例(修订版)_ucos-ii v2.52基于51单片机的移植实例 + proteus仿真
- 6idea 回滚某次提交的代码_idea代码回滚到指定提交位置
- 7Gradle的学习
- 8学习Python语言有什么优势?_谈谈如果让你再深入学习python语言,你想深入哪方面?
- 9Spark源码——Job全流程以及DAGScheduler的Stage划分_spark dag划分源码
- 10Ubuntu Linux下通过代理(proxy)使用git上github.com
MySql SQL优化
赞
踩
一、其他SQL优化
1.1、插入数据
1.1.1、insert
如果我们需要一次性往数据库表中插入多条记录,可以从以下三个方面进行优化。
- 批量插入数据
Insert into tb_test values(1,'Tom'),(2,'Cat'),(3,'Jerry');
每次插入记录除了处理执行SQL语句外,还需要做连接数据库之类的操作,所以要插入多条记录时,可以批量地插入数据来提高插入性能,插入的数据量不宜过大。
- 手动控制事务
start transaction;
insert into tb_test values(1,'Tom'),(2,'Cat'),(3,'Jerry');
insert into tb_test values(4,'Tom'),(5,'Cat'),(6,'Jerry');
insert into tb_test values(7,'Tom'),(8,'Cat'),(9,'Jerry'); commit;
- 主键顺序插入,性能要高于乱序插入。
主键乱序插入会带来“页分裂” 的问题(后面解释页分裂)
主键乱序插入 : 8 1 9 21 88 2 4 15 89 5 7 3
主键顺序插入 : 1 2 3 4 5 7 8 9 15 21 88 89
1.1.2、大批量插入数据
如果一次性需要插入大批量数据(比如: 几百万的记录),使用insert语句插入性能较低,此时可以使 用MySQL数据库提供的load指令进行插入。操作如下:
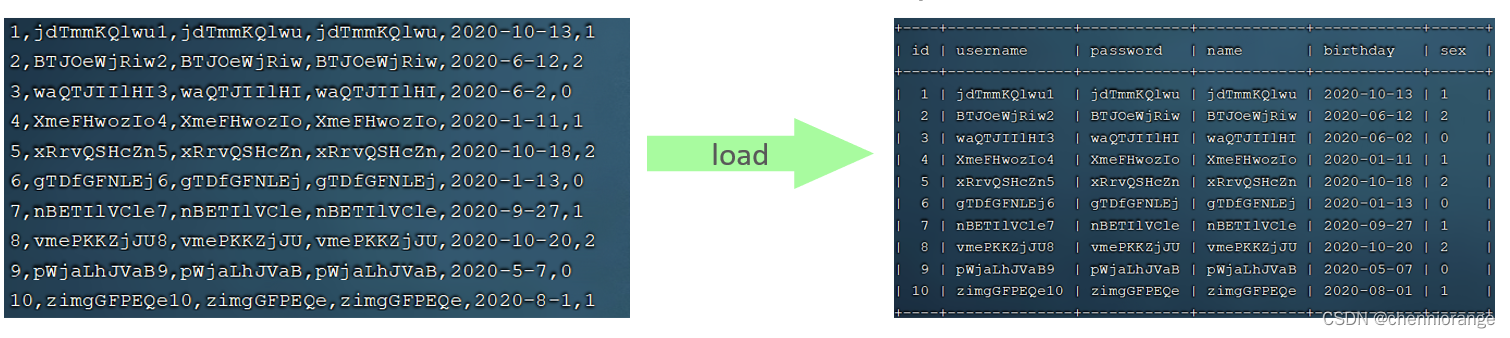
可以执行如下指令,将数据脚本文件中的数据加载到表结构中:
- -- 客户端连接服务端时,加上参数 -–local-infile
-
- mysql –-local-infile -u root -p
-
- -- 设置全局参数local_infile为1,开启从本地加载文件导入数据的开关
-
- set global local_infile = 1;
-
- -- 执行load指令将准备好的数据,加载到表结构中
-
- load data local infile '/root/sql1.log' into table tb_user fields
- terminated by ',' lines terminated by '\n' ;
同时这里也可以尽量遵循主键按顺序插入的原则,提高插入性能。
1.2、主键优化
现在我们来解释为什么主键按顺序插入时的性能高于乱序插入。
1.2.1、数据组织方式
在InnoDB存储引擎中,表数据都是根据主键顺序组织存放的,这种存储方式的表称为索引组织表(index organized table IOT)。

行数据,都是存储在聚集索引的叶子节点上的。而我们之前也讲解过InnoDB的逻辑结构图:
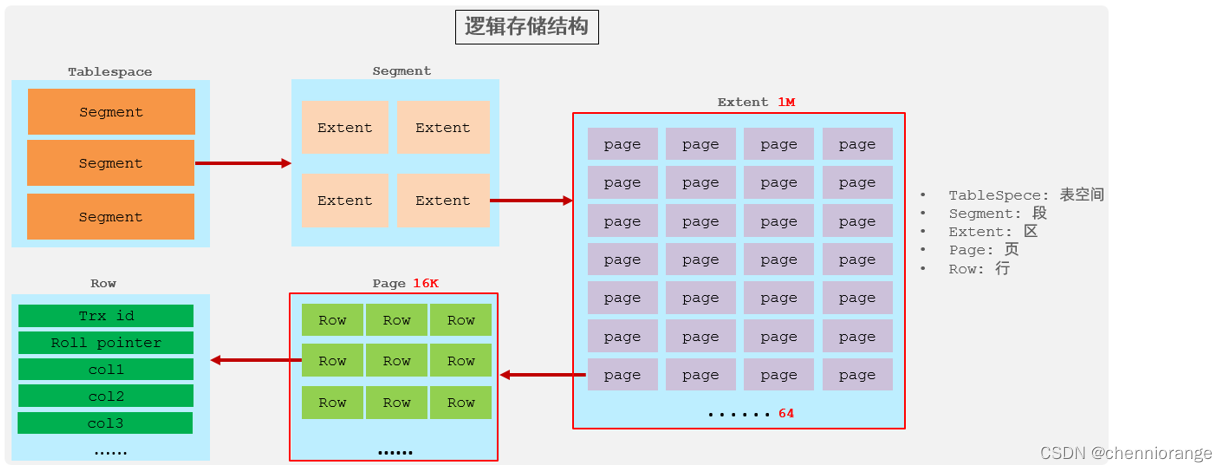
在InnoDB引擎中,数据行是记录在逻辑结构 page 页中的,而每一个页的大小是固定的,默认16K。 那也就意味着, 一个页中所存储的行也是有限的,如果插入的数据行row在该页存储不小,将会存储 到下一个页中,页与页之间会通过指针连接。
1.2.2、 页分裂
页可以为空,也可以填充一半,也可以填充100%。每个页包含了2-N行数据(如果一行数据过大,会行 溢出),根据主键排列。
A. 主键顺序插入效果
①. 从磁盘中申请页, 主键顺序插入

②. 第一个页没有满,继续往第一页插入
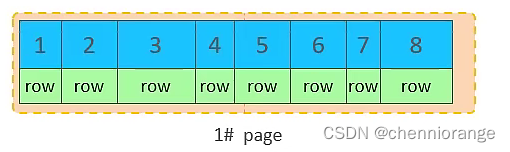
③. 当第一个也写满之后,再写入第二个页,页与页之间会通过指针连接

④. 当第二页写满了,再往第三页写入

B. 主键乱序插入效果
①. 加入1#,2#页都已经写满了,存放了如图所示的数据

②. 此时再插入id为50的记录,我们来看看会发生什么现象
会再次开启一个页,写入新的页中吗?
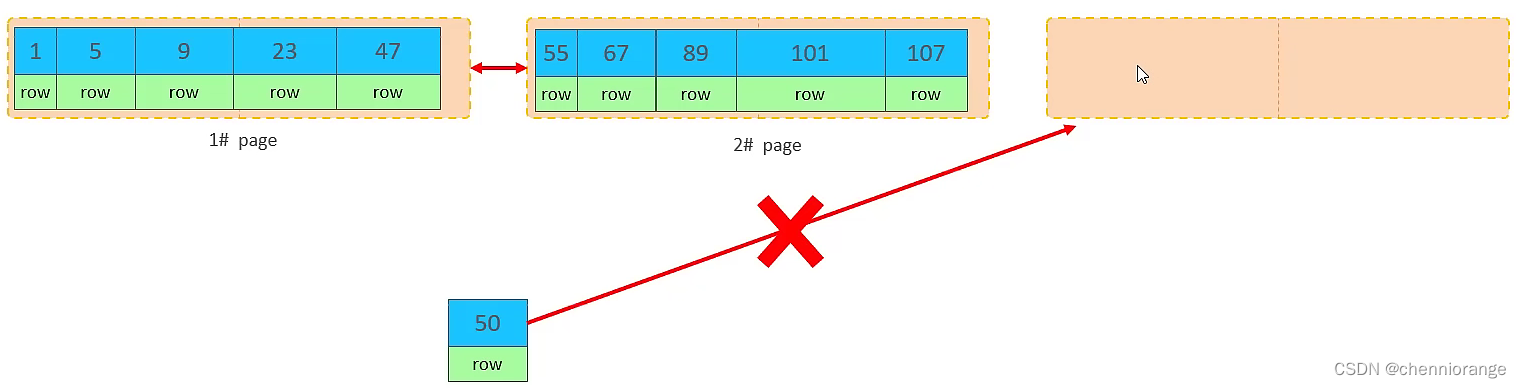
不会。因为,索引结构的叶子节点是有顺序的。按照顺序,应该存储在47之后。

但是47所在的1#页,已经写满了,存储不了50对应的数据了。 那么此时会开辟一个新的页 3#。

但是并不会直接将50存入3#页,而是会将1#页后一半的数据,移动到3#页,然后在3#页,插入50。(发生页分裂)

 移动数据,并插入id为50的数据之后,那么此时,这三个页之间的数据顺序是有问题的。 1#的下一个 页,应该是3#, 3#的下一个页是2#。 所以,此时,需要重新设置链表指针。
移动数据,并插入id为50的数据之后,那么此时,这三个页之间的数据顺序是有问题的。 1#的下一个 页,应该是3#, 3#的下一个页是2#。 所以,此时,需要重新设置链表指针。

上述的这种现象,称之为 "页分裂",是比较耗费性能的操作。
1.2.3、页合并
目前表中已有数据的索引结构(叶子节点)如下:

当我们对已有数据进行删除时,具体的效果如下:
当删除一行记录时,实际上记录并没有被物理删除,只是记录被标记(flaged)为删除并且它的空间变得允许被其他记录声明使用。

当我们继续删除2#的数据记录

当页中删除的记录达到 MERGE_THRESHOLD(默认为页的50%),InnoDB会开始寻找最靠近的页(前 或后)看看是否可以将两个页合并以优化空间使用。


删除数据,并将页合并之后,再次插入新的数据20,则直接插入3#页

这个里面所发生的合并页的这个现象,就称之为 "页合并"。
tips:
MERGE_THRESHOLD:合并页的阈值,可以自己设置,在创建表或者创建索引时指定。
1.2.4、索引设计原则
- 满足业务需求的情况下,尽量降低主键的长度。
- 插入数据时,尽量选择顺序插入,选择使用AUTO_INCREMENT自增主键。
- 尽量不要使用UUID做主键或者是其他自然主键,如身份证号。
- 业务操作时,避免对主键的修改。
1.3、order by优化
MySQL的排序,有两种方式:
Using filesort : 通过表的索引或全表扫描,读取满足条件的数据行,然后在排序缓冲区sort buffer中完成排序操作,所有不是通过索引直接返回排序结果的排序都叫 FileSort 排序。
Using index : 通过有序索引顺序扫描直接返回有序数据,这种情况即为 using index,不需要额外排序,操作效率高。
对于以上的两种排序方式,Using index的性能高,而Using filesort的性能低,我们在优化排序操作时,尽量要优化为 Using index。
示例:
A、没有对age和phone创建索引时
explain select id,age,phone from tb_user order by age ;

explain select id,age,phone from tb_user order by age, phone ;

由于 age, phone 都没有索引,所以此时再排序时,出现Using filesort, 排序性能较低。
B、创建索引
-- 创建索引
create index idx_user_age_phone_aa on tb_user(age,phone);
C、创建索引后,根据age, phone进行升序排序
explain select id,age,phone from tb_user order by age;

explain select id,age,phone from tb_user order by age , phone;

建立索引之后,再次进行排序查询,就由原来的Using filesort, 变为了 Using index,性能 就是比较高的了。
D、创建索引后,根据age, phone进行降序排序
explain select id,age,phone from tb_user order by age desc , phone desc ;

出现 Using index, 但是此时Extra中出现了 Backward index scan,这个代表反向扫描索 引,因为在MySQL中我们创建的索引,默认索引的叶子节点是从小到大排序的,而此时我们查询排序 时,是从大到小,所以,在扫描时,就是反向扫描,就会出现 Backward index scan。
在MySQL8版本中,支持降序索引,我们也可以创建降序索引。
E、根据phone,age进行升序排序,phone在前,age在后。
explain select id,age,phone from tb_user order by phone , age;

排序时,也需要满足最左前缀法则,否则也会出现 filesort。因为在创建索引的时候, age是第一个 字段,phone是第二个字段,所以排序时,也就该按照这个顺序来,否则就会出现 Using filesort。
order by 和 where 不同,order by的条件字句有先后顺序,where的and字句是不在乎先后顺序的,所以这里phone在前,age在后违背了最左前缀法则。
F、根据age, phone进行降序一个升序,一个降序
explain select id,age,phone from tb_user order by age asc , phone desc ;

因为创建索引时,如果未指定顺序,默认都是按照升序排序的,而查询时,一个升序,一个降序,此时 就会出现Using filesort。

为了解决上述的问题,我们可以创建一个索引,这个联合索引中 age 升序排序,phone 倒序排序。
G. 创建联合索引(age 升序排序,phone 倒序排序)
create index idx_user_age_phone_ad on tb_user(age asc ,phone desc);

H. 然后再次执行如下SQL
explain select id,age,phone from tb_user order by age asc , phone desc ;

升序/降序联合索引结构图示:


由上述的测试,我们得出order by优化原则:
- 根据排序字段建立合适的索引,多字段排序时,也遵循最左前缀法则。
- 尽量使用覆盖索引。
- 多字段排序, 一个升序一个降序,此时需要注意联合索引在创建时的规则(ASC/DESC)。
- 如果不可避免的出现filesort,大数据量排序时,可以适当增大排序缓冲区大小 sort_buffer_size(默认256k)。
1.4、group by优化
分组操作,我们主要来看看索引对于分组操作的影响。
在没有索引的情况下,执行如下SQL,查询执行计划:
explain select profession , count(*) from tb_user group by profession ;

然后,我们在针对于 profession , age, status 创建一个联合索引。
create index idx_user_pro_age_sta on tb_user(profession , age , status);
紧接着,再执行前面相同的SQL查看执行计划。
explain select profession , count(*) from tb_user group by profession ;

再执行如下的分组查询SQL,查看执行计划:


我们发现,如果仅仅根据age分组,就会出现 Using temporary ;而如果是 根据 profession,age两个字段同时分组,则不会出现 Using temporary。原因是因为对于分组操作, 在联合索引中,也是符合最左前缀法则的。
所以,在分组操作中,我们需要通过以下两点进行优化,以提升性能:
- 在分组操作时,可以通过索引来提高效率。
- 分组操作时,索引的使用也是满足最左前缀法则的。
1.5、limit优化
在数据量比较大时,如果进行limit分页查询,在查询时,越往后,分页查询效率越低。
我们一起来看看执行limit分页查询耗时对比:

通过测试我们会看到,越往后,分页查询效率越低,这就是分页查询的问题所在。
因为,当在进行分页查询时,如果执行 limit 2000000,10 ,此时需要MySQL排序前2000010 记 录,仅仅返回 2000000 - 2000010 的记录,其他记录丢弃,查询排序的代价非常大 。
优化思路: 一般分页查询时,通过创建 覆盖索引 能够比较好地提高性能,可以通过覆盖索引加子查 询形式进行优化。
explain select * from tb_sku t , (select id from tb_sku order by id limit 2000000,10) a where t.id = a.id;
1.6、count优化
如果数据量很大,在执行count操作时,是非常耗时的。
- MyISAM 引擎把一个表的总行数存在了磁盘上,因此执行 count(*) 的时候会直接返回这个 数,效率很高; 但是如果是带条件的count,MyISAM也慢。
- InnoDB 引擎就麻烦了,它执行 count(*) 的时候,需要把数据一行一行地从引擎里面读出 来,然后累积计数。
如果说要大幅度提升InnoDB表的count效率,主要的优化思路:自己计数(可以借助于redis这样的数 据库进行,但是如果是带条件的count又比较麻烦了)。
count用法:
count() 是一个聚合函数,对于返回的结果集,一行行地判断,如果 count 函数的参数不是 NULL,累计值就加 1,否则不加,最后返回累计值。
用法:count(*)、count(主键)、count(字段)、count(数字)
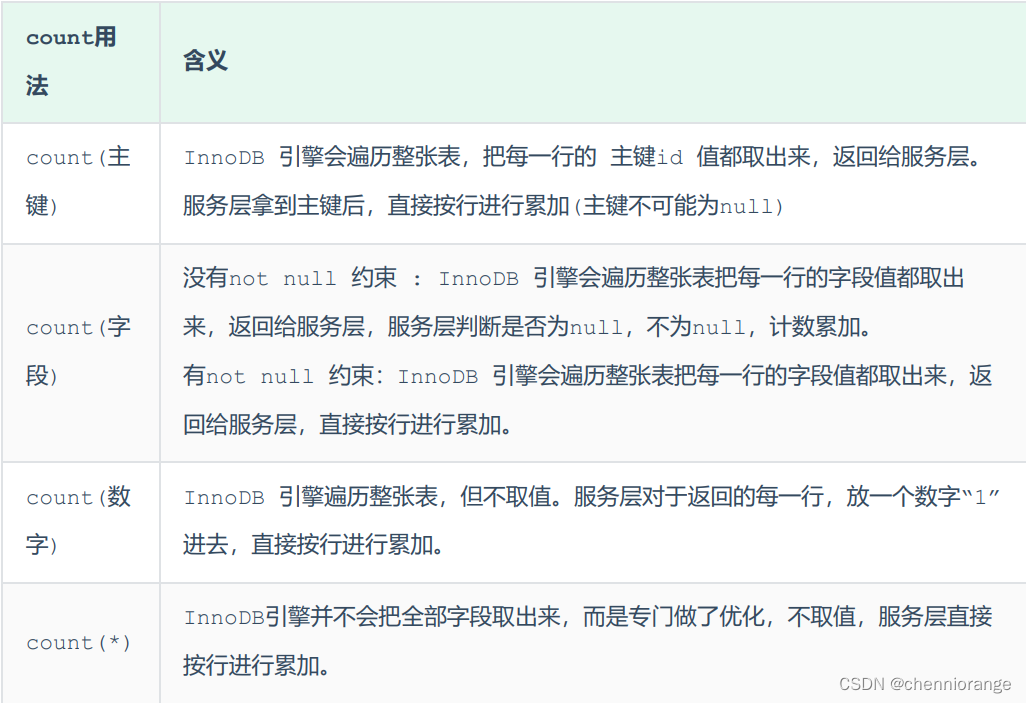
按照效率排序的话,count(字段) < count(主键 id) < count(1) ≈ count(*),所以尽 量使用 count(*)。
1.7、update优化
我们主要需要注意一下update语句执行时的注意事项。
update course set name = 'javaEE' where id = 1 ;
InnoDB引擎支持行级锁,当事务开启后,我们在执行删除的SQL语句时,会锁定id为1这一行的数据,在事务提交之前不允许其他线程操作id为1的这一行数据,然后事务提交之后,行锁释放。
但是当我们在执行如下SQL时。
update course set name = 'SpringBoot' where name = 'PHP' ;
当我们开启多个事务,在执行上述的SQL时,我们发现行锁升级为了表锁。 导致该update语句的性能 大大降低。
InnoDB的行锁是针对索引加的锁,不是针对记录加的锁 ,并且该索引不能失效,否则会从行锁 升级为表锁 。
二、视图
2.1、介绍
视图(View)是一种虚拟存在的表。视图中的数据并不在数据库中实际存在,行和列数据来自定义视 图的查询中使用的表,并且是在使用视图时动态生成的。
通俗的讲,视图只保存了查询的SQL逻辑,不保存查询结果。所以我们在创建视图的时候,主要的工作就落在创建这条SQL查询语句上。
2.2、语法
1). 创建
CREATE [OR REPLACE] VIEW 视图名称[(列名列表)] AS SELECT语句 [ WITH [ CASCADED | LOCAL ] CHECK OPTION ]
2). 查询
查看创建视图语句:SHOW CREATE VIEW 视图名称;
查看视图数据:SELECT * FROM 视图名称 ...... ;
3). 修改
方式一:
CREATE [OR REPLACE] VIEW 视图名称[(列名列表)] AS SELECT语句 [ WITH [ CASCADED | LOCAL ] CHECK OPTION ]
方式二:
ALTER VIEW 视图名称[(列名列表)] AS SELECT语句 [ WITH [ CASCADED | LOCAL ] CHECK OPTION ]
4). 删除
DROP VIEW [IF EXISTS] 视图名称 [,视图名称] ...
示例:
- -- 创建视图
-
- create or replace view stu_v_1 as select id,name from student where id <= 10;
-
- -- 查询视图
-
- show create view stu_v_1;
-
- select * from stu_v_1;
-
- select * from stu_v_1 where id < 3;
-
- -- 修改视图
-
- create or replace view stu_v_1 as select id,name,no from student where id <= 10;
-
- alter view stu_v_1 as select id,name from student where id <= 10;
-
- -- 删除视图
-
- drop view if exists stu_v_1;

2.3、检查选项
当使用WITH CHECK OPTION子句创建视图时,MySQL会通过视图检查正在更改的每个行,例如 插 入,更新,删除,以使其符合视图的定义。 MySQL允许基于另一个视图创建视图,它还会检查依赖视 图中的规则以保持一致性。为了确定检查的范围,mysql提供了两个选项: CASCADED 和 LOCAL,默认值为 CASCADED 。
1). CASCADED
级联。
比如,v2视图是基于v1视图的,如果在v2视图创建的时候指定了检查选项为 cascaded,但是v1视图 创建时未指定检查选项。 则在执行检查时,不仅会检查v2,还会级联检查v2的关联视图v1。

2). LOCAL
本地。
比如,v2视图是基于v1视图的,如果在v2视图创建的时候指定了检查选项为 local ,但是v1视图创 建时未指定检查选项。 则在执行检查时,知会检查v2,不会检查v2的关联视图v1。

也就是说:CASCADED会将检查选项传递到父视图,而LOCAL则不会。
2.4、视图的更新
要使视图可更新,视图中的行与基础表中的行之间必须存在一对一的关系。如果视图包含以下任何一 项,则该视图不可更新:
A. 聚合函数或窗口函数(SUM()、 MIN()、 MAX()、 COUNT()等)
B. DISTINCT
C. GROUP BY
D. HAVING
E. UNION 或者 UNION ALL
2.5、视图作用
1). 简单
视图不仅可以简化用户对数据的理解,也可以简化他们的操作。那些被经常使用的查询可以被定义为视 图,从而使得用户不必为以后的操作每次指定全部的条件。
2). 安全
数据库可以授权,但不能授权到数据库特定行和特定的列上。通过视图用户只能查询和修改他们所能见 到的数据
3). 数据独立
视图可帮助用户屏蔽真实表结构变化带来的影响。


