- 12024年最新怎样将本地项目上传到gitee(使用idea或者git推送),前端面试题web
- 2每天5分钟玩转OpenStack--第10篇 动手实践虚拟网络---问题解决_systemctl is-enabled libvirtd.service
- 3什么是事务?Mysql事务怎么用?Mybatis怎么操作事务的?Spring呢?快进来看看_mybatis 开启事务
- 4Redis实战——分布式锁&Redisson_redisson分布式锁实战
- 5RobotFramework全部Library一览_robotframe 查看library
- 6NLP技术_bert+fasttext
- 7数据结构队列顺序存储代码实现(C语言)_数据结构顺序队列完整代码
- 8网络安全-安全服务工程师-技能手册详细总结(建议学习収藏)_安全服务工程师技能介绍
- 9【抓包教程】BurpSuite联动雷电模拟器——安卓高版本抓包移动应用教程_雷电模拟器burpsuite抓包
- 10一个简单的方法解决Android Studio打开旧项目、其他项目各种报错问题_android studio 2022.3.1打开旧版本项目
hive企业级调优策略之小文件合并_文件合并性能优化
赞
踩
测试所用到的数据参考:
原文链接:https://blog.csdn.net/m0_52606060/article/details/135080511
本教程的计算环境为Hive on MR。计算资源的调整主要包括Yarn和MR。
优化说明
小文件合并优化,分为两个方面,分别是Map端输入的小文件合并,和Reduce端输出的小文件合并。
Map端输入文件合并
合并Map端输入的小文件,是指将多个小文件划分到一个切片中,进而由一个Map Task去处理。目的是防止为单个小文件启动一个Map Task,浪费计算资源。
相关参数为:
–可将多个小文件切片,合并为一个切片,进而由一个map任务处理
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
- 1
Reduce输出文件合并
合并Reduce端输出的小文件,是指将多个小文件合并成大文件。目的是减少HDFS小文件数量。其原理是根据计算任务输出文件的平均大小进行判断,若符合条件,则单独启动一个额外的任务进行合并。
相关参数为:
–开启合并map only任务输出的小文件
set hive.merge.mapfiles=true;
- 1
–开启合并map reduce任务输出的小文件
set hive.merge.mapredfiles=true;
- 1
–合并后的文件大小
set hive.merge.size.per.task=256000000;
- 1
–触发小文件合并任务的阈值,若某计算任务输出的文件平均大小低于该值,则触发合并
set hive.merge.smallfiles.avgsize=16000000;
- 1
优化案例
(1)示例用表
现有一个需求,计算各省份订单金额总和,下表为结果表。
drop table if exists order_amount_by_province;
create table order_amount_by_province(
province_id string comment '省份id',
order_amount decimal(16,2) comment '订单金额'
)
location '/order_amount_by_province';
- 1
- 2
- 3
- 4
- 5
- 6
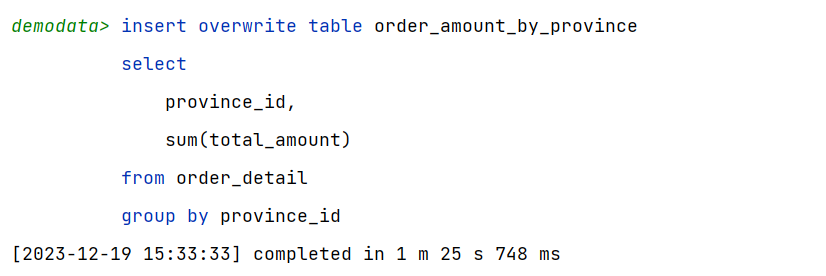
(2)示例SQL语句
insert overwrite table order_amount_by_province
select
province_id,
sum(total_amount)
from order_detail
group by province_id;
- 1
- 2
- 3
- 4
- 5
- 6
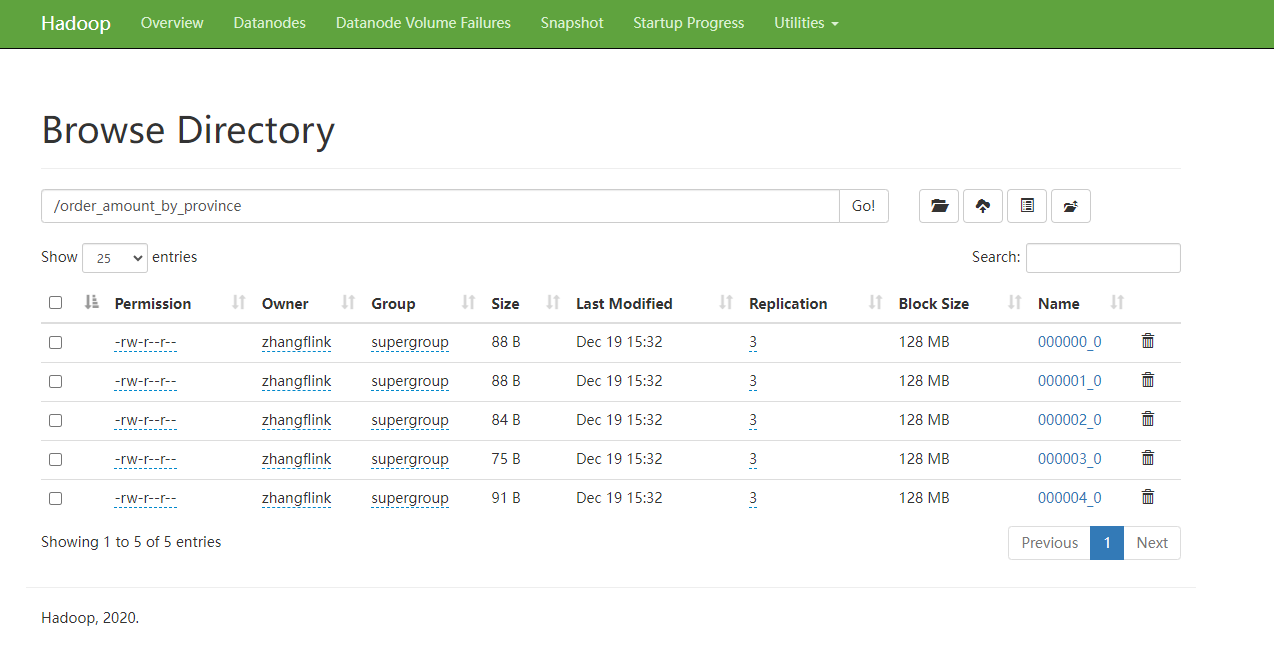
(3)优化前
根据任务并行度一节所需内容,可分析出,默认情况下,该sql语句的Reduce端并行度为5,故最终输出文件个数也为5,下图为输出文件,可以看出,5个均为小文件。
(4)优化思路
若想避免小文件的产生,可采取方案有两个。
(1)合理设置任务的Reduce端并行度
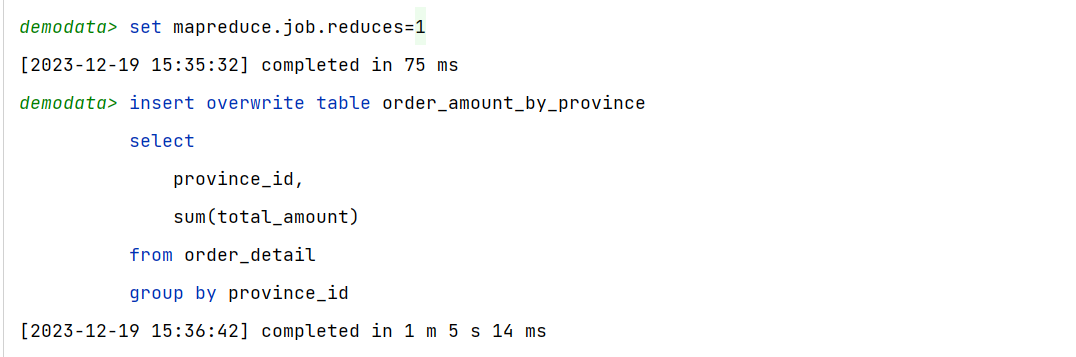
若将上述计算任务的并行度设置为1,就能保证其输出结果只有一个文件。
set mapreduce.job.reduces=1;
- 1
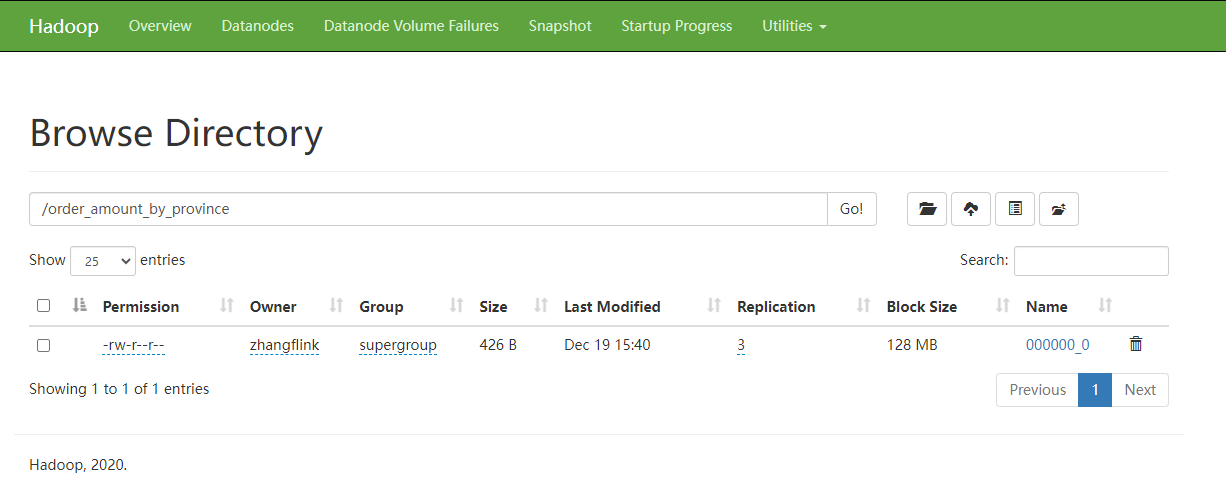
再次执行上述的insert语句,观察结果表中的文件,只剩一个了。
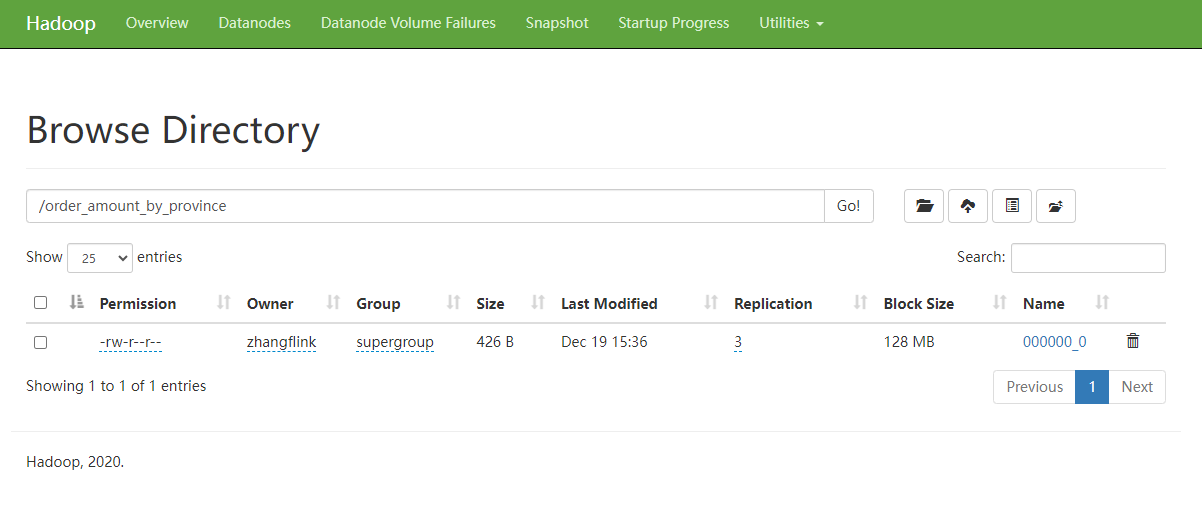
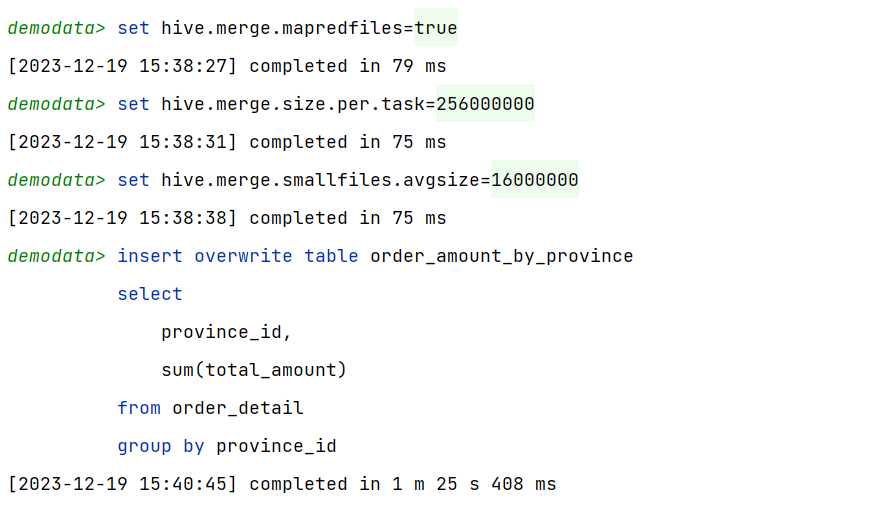
(2)启用Hive合并小文件优化
设置以下参数:
–开启合并map reduce任务输出的小文件
set hive.merge.mapredfiles=true;
- 1
–合并后的文件大小
set hive.merge.size.per.task=256000000;
- 1
–触发小文件合并任务的阈值,若某计算任务输出的文件平均大小低于该值,则触发合并
set hive.merge.smallfiles.avgsize=16000000;
- 1
再次执行上述的insert语句,观察结果表中的文件,只剩一个了。