
- 1Python数据结构12:冒泡排序,选择排序,插入排序,希尔排序,归并排序,快速排序_对序列(55,22,97,13)冒泡排序,第一趟排序的结果是()
- 2华为fusionsphere整体架构及其各组件功能_华为数据之道:面向业务的信息架构建设...
- 3计算机科学与技术万金油专业,盘点工学大类里的“万金油”专业
- 4【基础】队列的插入和删除--C++源代码(g++ 7.2.0)_数据结构队列的插入和删除代码c++
- 5数据仓库知识随记-数据湖_data warehouses and data lakes
- 62024最全AI绘画Midjourney绘画提示词Prompt大全,AI换脸、垫图混图【宝藏级收藏】_ai绘图 prompt大全
- 7Python,课上练习,词云库wordcloud的安装与应用_wordcloud库的安装
- 8Vue实现Hello World_用vue 前端工程 hello word
- 9知攻善防应急靶场二
- 10FIFO_fifo usdw
STM32移植FreeRTOS系列十三:RTOS中的任务切换流程(总结)_freertos任务切换详细流程
赞
踩
目录
又为什么要使用PendSV来进行上下文切换而不适用其他异常呢?
正点原子视频P24-P28里有结合实际的源码来分析,我这里的话主要就是结合Cortex-M3权威指南和ARM Cortex-M3与Cortex-M4权威指南来进行分析。
1、任务切换的概念和流程
第一步:需暂停任务A的执行,并将此时任务A的寄存器保存到任务堆栈,这个过程叫做保存现场;
第二步:将任务B的各个寄存器值(被存于任务堆栈中)恢复到CPU寄存器中,这个过程叫做恢复现场;
对任务A保存现场,对任务B恢复现场,这个整体的过程称之为:上下文切换
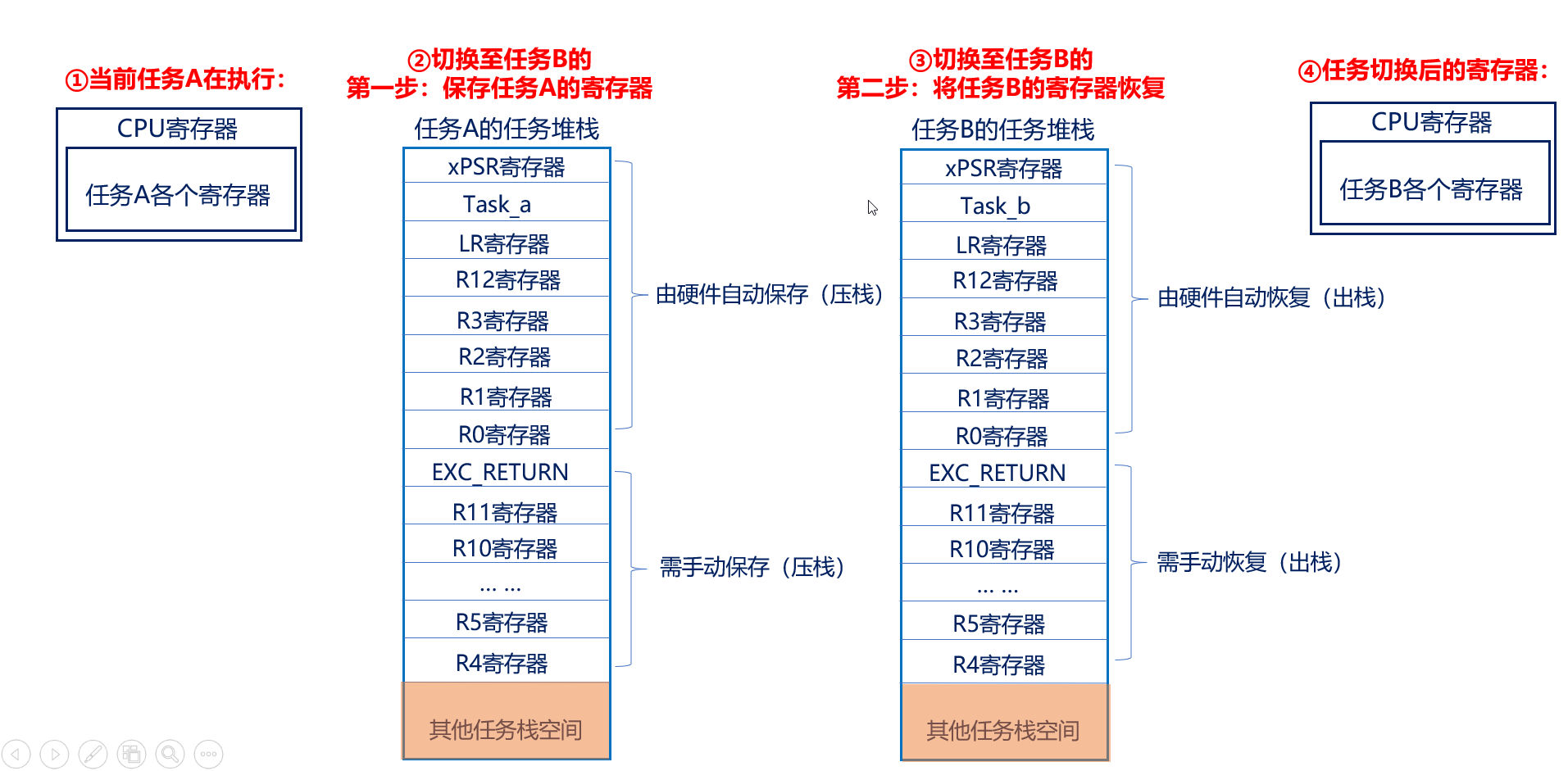
任务切换的本质:就是CPU寄存器的切换。
而任务切换的过程在PendSV中断服务函数里边完成
2、任务切换与PendSV异常之间的关系
2.1、什么是PendSV
在了解PendSV(可悬起系统调用)前,需要对SVC(系统服务调用,亦简称系统调用)有一个基本的概念。
SVC 用于产生系统函数的调用请求。例如,操作系统不让用户程序直接访问硬件,而是通过提供一些系统服务函数,用户程序使用 SVC 发出对系统服务函数的呼叫请求,以这种方法调用它们来间接访问硬件。因此,当用户程序想要控制特定的硬件时,它就会产生一个 SVC 异常,然后操作系统提供的 SVC 异常服务例程得到执行,它再调用相关的操作系统函数,后者完成用户程序请求的服务。SVC异常是必须立即得到响应的(若优先级不比当前正处理的高, 或是其它原因使之无法立即响应, 将上访成硬 fault),应用程序执行 SVC 时都是希望所需的请求立即得到响应。
PendSV(可悬挂的系统调用),它和 SVC 协同使用。 PendSV 与SVC不同地是,它是可以像普通的中断一样被悬起的(不像 SVC 那样会上访)。 OS 可以利用它“缓期执行” 一个异常——直到其它重要的任务完成后才执行动作。 悬起 PendSV 的方法是:手工往 NVIC 的 PendSV 悬起寄存器中写 1。 悬起后, 如果优先级不够高,则将缓期等待执行。PendSV是可悬起异常,如果我们把它配置最低优先级,那么如果同时有多个异常被触发,它会在其他异常执行完毕后再执行,而且任何异常都可以中断它。
2.2 使用PendSV进行上下文切换的原因
PendSV的典型使用场合是在上下文切换时(在不同任务之间切换)。例如,一个系统中有两个就绪的任务,上下文切换被触发的场合可以是:
1、执行一个系统调用
这里一般来说是执行系统api函数
2、系统滴答定时器(SYSTICK)中断,(轮转调度中需要)
在系统定时器中断服务函数中,会对当前正在运行的任务优先级与就绪列表中其他优先级的任务进行比较,判断就绪列表中是否存在比该任务优先级更高的任务或者存在同等优先级的任务,有的话就需要进行任务切换。
那为什么要通过异常来进行上下文切换,而不在其他地方呢?
我们先解决第一个问题为什么要通过异常来进行上下文切换
在实时操作系统中,使用异常来进行上下文切换是一种常见的做法,主要有以下几个原因:
-
硬件支持:许多处理器和微控制器提供了用于任务调度和上下文切换的特殊机制,例如中断向量表和异常处理机制。通过使用这些硬件支持,可以实现高效且可靠的上下文切换。
-
响应性:异常处理具有优先级和固定的响应时间。当异常被触发时,处理器会立即跳转到相应的异常处理程序,在处理程序执行完毕后,可以很快地切回原来的上下文。这样可以确保实时任务能够及时响应,并满足系统的实时性要求。
-
隔离性:通过使用异常来进行上下文切换,可以实现任务之间的严格隔离。每个任务都有自己的上下文,包括堆栈、寄存器等,而异常处理程序也有独立的上下文。这样可以避免任务之间的相互影响和数据冲突。
-
可靠性:异常处理通常由操作系统内核或底层驱动程序提供,这些代码经过精心设计和测试,以确保其正确性和稳定性。通过使用异常进行上下文切换,可以借助这些可靠的代码来管理任务调度和上下文切换,提高系统的可靠性和健壮性。
为什么不在其他地方进行上下文切换
在其他地方进行上下文切换可能会导致以下问题:
-
不可预测性:如果在任意的代码位置进行上下文切换,那么任务的切换时机将不可控制,可能导致无法满足实时要求。在实时系统中,任务的调度和切换需要具备可预测性和确定性,以保证任务能在规定的时间内得到执行。
-
安全性问题:上下文切换涉及到任务的状态保存和恢复,包括寄存器、堆栈等关键数据。如果在任意位置进行上下文切换,可能导致数据丢失或损坏,进而影响任务的正确执行。通过使用异常处理机制,可以确保上下文切换发生在安全的、事先定义的位置,从而避免数据的不一致性问题。
-
复杂性和可维护性:将上下文切换集中在异常处理机制中,可以提高代码的可读性、可维护性和可扩展性。异常处理程序通常由操作系统内核或底层驱动程序提供,这些代码经过精心设计和测试,可以提供一致且可靠的上下文切换机制。如果在其他地方进行上下文切换,可能导致代码分散、逻辑混乱,不利于系统的维护和调试。
综上所述,通过异常来进行上下文切换是为了满足实时系统的要求,包括可预测性、安全性和可维护性等方面。异常处理机制提供了一种可靠、统一的方式来管理任务的调度和上下文切换,并且能够与硬件支持紧密结合,以实现高效且可控的任务切换。
又为什么要使用PendSV来进行上下文切换而不适用其他异常呢?
让我们举个简单的例子来辅助理解。假设有这么一个系统,里面有两个就绪的任务,并且通过SysTick异常启动上下文切换。但若在产生 SysTick 异常时正在响应一个中断,则 SysTick异常会抢占其 ISR。在这种情况下,OS是不能执行上下文切换的,否则将使中断请求被延迟,而且在真实系统中延迟时间还往往不可预知——任何有一丁点实时要求的系统都决不能容忍这种事。因此,在 CM3 中也是严禁没商量——如果 OS 在某中断活跃时尝试切入线程模式,将触犯用法fault异常。
为什么在异常抢占中断时,OS不能执行上下文切换呢?
在实时系统中,中断服务程序(ISR)通常是为了响应紧急事件而设计的,具有相对较高的优先级。当一个中断请求到来时,CPU会立即跳转到对应的ISR执行。在ISR执行期间,中断请求被认为处于中断处理状态,并且通常会被屏蔽,以确保响应的实时性和一致性。
但是如果在异常处理过程中触发了上下文切换,即切换到另一个任务的执行,那么中断请求会被延迟处理。这是因为在进行上下文切换时,操作系统需要保存当前任务的上下文(包括寄存器值、堆栈信息等),然后加载下一个任务的上下文。这涉及到对系统状态的修改和操作,需要消耗一定时间和计算资源。因此,在上下文切换期间,CPU无法立即响应新的中断请求,导致中断的处理被延迟。这样如果任务切换时间过久,那么实时操作系统的实时那就沦为笑柄了。
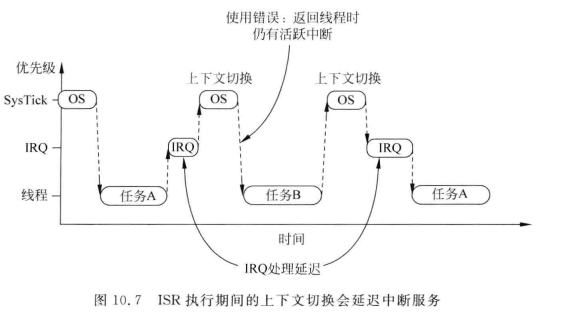
为了解决这个问题,早期的 OS 大多会检测当前是否有中断在活跃中,只有在无任何中断需要响应时,才执行上下文切换(切换期间无法响应中断)。然而,这种方法的弊端在于,它可以把任务切换动作拖延很久(因为如果抢占了 IRQ,则本次 SysTick在执行后不得作上下文切换,只能等待下 一次SysTick异常),尤其是当某中断源的频率和SysTick异常的频率比较接近时,会发生“共振”, 使上下文切换迟迟不能进行。现在好了,PendSV来完美解决这个问题了。PendSV异常会自动延迟上下文切换的请求,直到 其它的 ISR都完成了处理后才放行。为实现这个机制,需要把PendSV编程为最低优先级的异常。如果 OS检测到某 IRQ正在活动并且被 SysTick抢占,它将悬起一个 PendSV异常,以便缓期执行上下文切换。
2.3、PendSV异常是如何触发的
1、滴答定时器中断调用
2、执行FreeRTOS提供的相关API函数:portYIELD()
下表摘取于《Cortex M3权威指南(中文)》第131页。
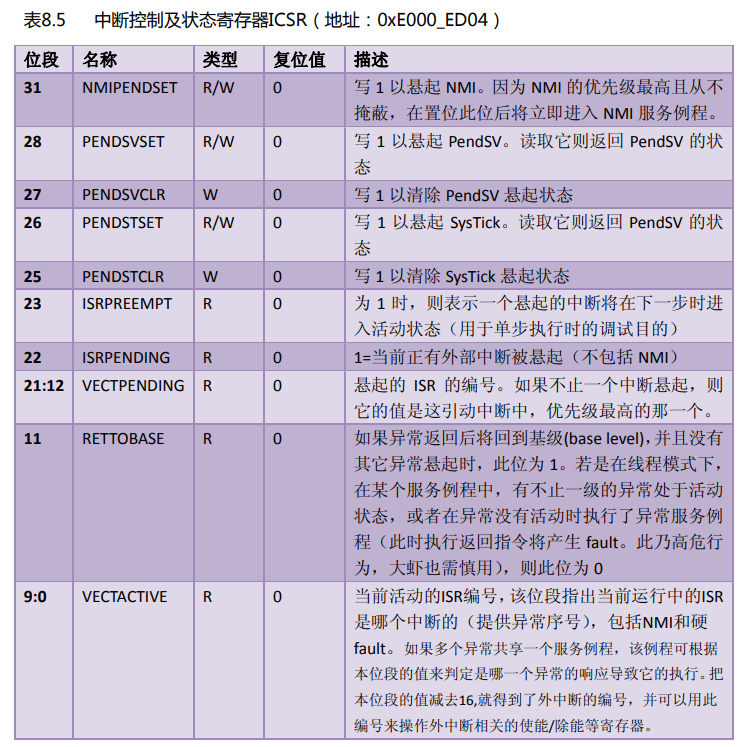
本质:通过向中断控制和状态寄存器 ICSR 的bit28 写入 1 挂起 PendSV 来启动 PendSV 中断
2.4、PendSV是如何控制上下文切换的
PendSV 异常会自动延迟上下文切换的请求, 直到其它的 ISR 都完成了处理后才放行。为实现这个机制,需要把 PendSV 编程为最低优先级的异常。如果 OS 检测到某 IRQ 正在活动并且被 SysTick 抢占,它将悬起一个 PendSV 异常, 以便缓期执行上下文切换。如图 7.17 所示

个中事件的流水账记录如下:
1. 任务 A 呼叫 SVC 来请求任务切换(例如,等待某些工作完成)
2. OS 接收到请求,做好上下文切换的准备,并且 pend 一个 PendSV 异常。
3. 当 CPU 退出 SVC 后,它立即进入 PendSV,从而执行上下文切换。
4. 当 PendSV 执行完毕后,将返回到任务 B,同时进入线程模式。
5. 发生了一个中断,并且中断服务程序开始执行
6. 在 ISR 执行过程中,发生 SysTick 异常,并且抢占了该 ISR。
7. OS 执行必要的操作,然后 pend 起 PendSV 异常以作好上下文切换的准备。
8. 当 SysTick 退出后,回到先前被抢占的 ISR 中,ISR 继续执行
9. ISR 执行完毕并退出后,PendSV 服务例程开始执行,并且在里面执行上下文切换
10. 当 PendSV 执行完毕后,回到任务 A,同时系统再次进入线程模式。
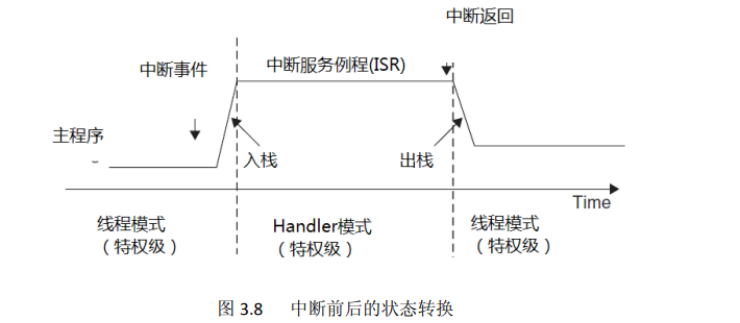
3、任务调度时Cortex-M3/4的工作模式
参考:(1条消息) RTOS系列文章(6):Cortex-M3/4之SP,MSP,PSP,Thread模式、Handler模式、内核态、用户态_psp msp_猪哥-嵌入式的博客-CSDN博客
CM3内核为什么要有线程模式、handler模式
在ARM Cortex-M3内核中,引入了线程模式(Thread mode)和处理器模式(Handler mode)的设计,主要是为了提供多任务处理和实时操作系统(RTOS)的支持。
-
线程模式(Thread mode):线程模式是Cortex-M3处理器的一种特殊模式,用于支持多任务处理。在线程模式下,处理器可以执行多个线程,每个线程有自己的堆栈和上下文,并且可以通过任务切换机制在不同的线程之间切换。这种多任务处理的能力使得Cortex-M3内核能够支持实时操作系统(RTOS)的运行,实现并发执行和任务调度。
-
处理器模式(Handler mode):处理器模式是Cortex-M3内核的默认模式,也被称为特权模式。在处理器模式下,处理器可以执行异常处理程序(例如中断服务程序、异常处理程序等)。处理器模式提供了更高优先级的特权级别,可以处理系统中发生的各种异常情况,并且具有对特权寄存器和特权指令的访问权限。
通过区分线程模式和处理器模式,Cortex-M3内核能够有效地支持多任务处理和实时操作系统的需求。线程模式用于执行多个用户线程的任务切换和调度,实现任务的并发执行;而处理器模式则用于执行高优先级的异常处理和系统级任务,确保系统的正确运行和异常的处理。
需要注意的是,Cortex-M3内核并不直接支持操作系统功能,而是提供了一些特定的硬件机制和模式,以便实现多任务处理和RTOS的支持。具体的操作系统需要在这些机制的基础上进行开发和实现。
CM3内核为什么要特权分级
在ARM Cortex-M3内核中引入特权分级(Privilege Level)的设计,是为了实现系统的安全性和可靠性。
特权分级允许不同的软件模块以不同的特权级别运行,这种特权分离的机制有以下几个主要目的:
-
系统安全性:特权分级可以确保系统的安全性,防止低特权级别的软件对高特权级别的资源和功能产生未经授权的访问。通过限制低特权级别软件的权限,可以有效地保护系统免受恶意软件或错误代码的影响。
-
系统可靠性:特权分级有助于提高系统的可靠性和稳定性。高特权级别的软件可以访问更多的硬件资源和执行特权指令,从而能够进行关键任务的处理和系统级操作。低特权级别的软件则被限制在受控的环境中,不具备对系统关键部分的直接访问权限,避免了一些潜在的错误或异常导致系统崩溃或数据损坏的风险。
-
软件可维护性:特权分级使得软件的开发、维护和调试更加方便。通过将不同功能的代码划分到不同的特权级别中,可以实现代码的模块化和层次化设计,降低了代码的复杂度。此外,在调试过程中,将不同特权级别的代码隔离开来,有助于定位和解决问题。
Cortex-M3 内核工作模式、特权分级
内核工作模式
线程模式:正常应用程序运行时的模式,应用程序包括程序员编写的应用程序,也包括OS的部分程序。
Handler模式:出现异常、中断时工作模式。
特权分级
Cortex-M3/M4内核特权分级有两种,分别是特权(privileged)和非特权(unprivileged),很多书籍会将这两种特权分为内核态、用户态。
特权模式、非特权模式和线程模式、Handler模式之间存在一些联系,但它们是不同的概念。
特权模式(privileged mode)和非特权模式(unprivileged mode)主要涉及处理器的特权级别和对系统资源的访问权限。特权模式具有较高的特权级别,可以执行特权指令、访问敏感的系统资源,适用于执行关键任务和操作系统内核的执行;非特权模式则具有较低的特权级别,受到一定的限制,主要用于正常应用程序的运行。
线程模式(thread mode)是处理器在正常应用程序运行时的模式,包括应用程序员编写的应用程序和一些操作系统的部分程序。线程模式可以运行在特权模式或非特权模式下,取决于操作系统的实现和配置。在线程模式下,处理器会切换不同的线程来执行任务。
Handler模式是在出现异常或中断时工作的一种模式。当发生异常或中断事件时,处理器会自动切换到Handler模式,并执行与之对应的异常或中断处理程序,这些处理程序通常在特权模式下运行。Handler模式允许对异常和中断进行特殊处理,例如保存上下文、响应中断请求、执行特权操作等。
因此,在正常应用程序运行时,处理器可以处于特权模式或非特权模式的线程模式下。当出现异常或中断时,处理器会切换到Handler模式,执行相应的异常或中断处理程序。特权模式和非特权模式是线程模式的一部分,而Handler模式是在异常或中断情况下的工作模式。它们之间有联系,但并非完全等同。
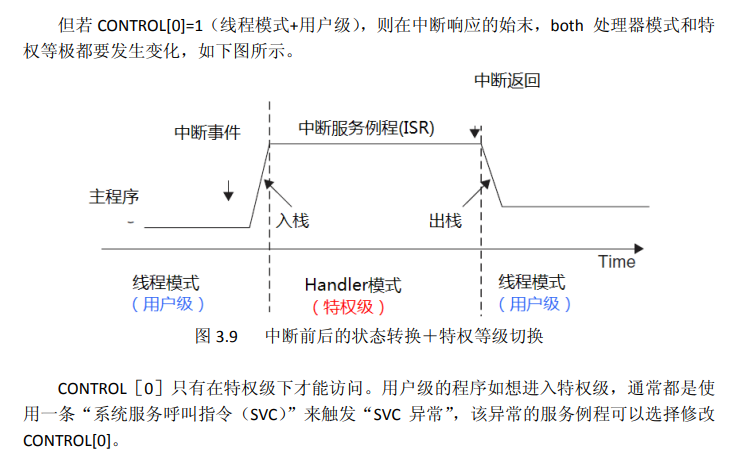
4、双堆栈指针MSP和PSP
CM3内核为什么需要两个SP(MSP和PSP)
MSP用于线程模式 + handler模式。
Handler模式下CPU会强制使用MSP。
主堆栈指针(MSP):MSP是系统启动时初始化的默认堆栈指针,用于保存全局变量、中断服务程序(ISR)的上下文以及异常处理过程中的堆栈帧。MSP通常被用于保存系统级别的上下文,并且在处理器模式(Handler mode)下使用。
线程模式下可以使用MSP,也可以使用PSP。
进程堆栈指针(PSP):PSP是线程模式(Thread mode)下使用的堆栈指针,用于保存线程的上下文,如局部变量、函数调用信息等。PSP一般用于保存线程级别的上下文,并在任务切换时进行保存和恢复。
举例:对于裸机程序,一直使用MSP。对于有OS的程序,OS内核和中断使用MSP,而应用程序task则使用PSP。
那双堆栈指针的作用是什么?
答案是为了隔离OS和应用程序,程序的运行少不了堆栈,因为我们CPU只有少量的通用寄存器,当我们使用的临时变量比较多得时候,就需要将这些临时变量存储到堆栈里,而堆栈的push和pop都是通过SP来实现的,所以通过MSP和PSP就能实现OS内核与应用程序的隔离,应用程序task用PSP,而OS用MSP,这样会非常安全。因为应用程序再怎么折腾也只是在自己的堆栈内折腾,不会影响内核OS。
规范一点来说就是
-
支持多任务处理:通过使用PSP,Cortex-M3能够支持多任务处理,允许同时运行多个线程。每个线程都有自己独立的堆栈空间,通过切换PSP,可以实现不同线程之间的堆栈切换和上下文保存。
-
异常处理:在异常发生时,Cortex-M3会自动切换到处理器模式(Handler mode)下,并使用MSP保存当前的异常上下文。这样可以确保在异常处理过程中不会破坏线程的堆栈信息,同时,通过使用MSP,可以方便地管理和处理异常情况.。
接下来引入《The definitive guide to ARM Cortex-M3/4》10.2章节的一段话来进一步说明SP,MSP,PSP的作用:
For most cases, it is not necessary to use the PSP if the application doesn’t require an embedded OS. Many simple applications can rely on the MSP completely.
The PSP is normally used when an embedded OS is involved, where the stack for theOS kernel and application tasks are separated. The initial value of PSP is undefined,and the initial value of MSP is taken from the first word of the memory during the reset sequence
翻译过来,有如下关键信息:
MSP是默认使用的堆栈指针,可以工作在线程模式,而handler模式一定是使用MSP。
PSP只能用于线程模式。
MSP和PSP的切换有2种情况:
(1)发生异常或中断时,CPU自动进入Handler模式,CPU会自动设置CONTROL bit[1] 为0,使用MSP。
(2)OS或程序员将 CONTROL bit[1] 设置为1, 则进入线程模式,则使用PSP。
在RTOS下,OS为每个task都会分配堆栈空间,各task运行的时候,使用PSP,而在异常中断、OS内核下,则使用MSP。
SP与MSP、PSP拓扑结构
我们先看下寄存器内部的结构
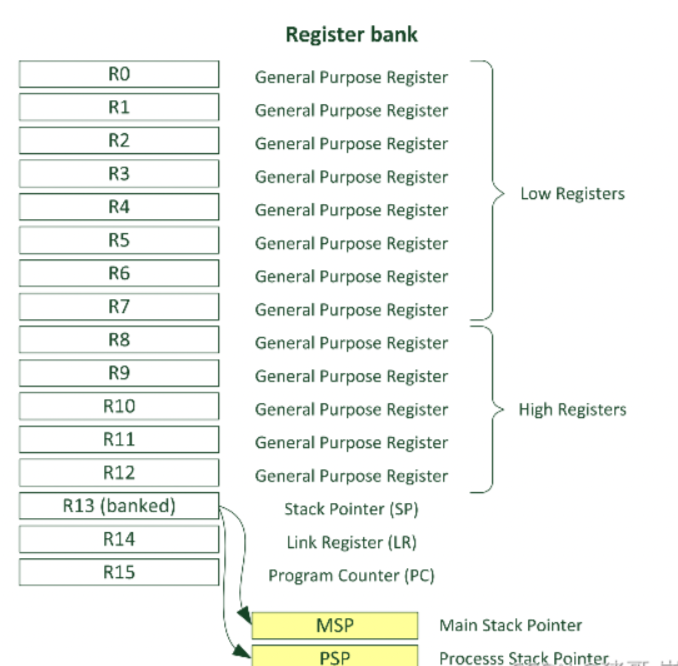
我们可以进一步细化一下,如下图所示:

为了方便理解,我们可以简单的这么想:
在CPU中,堆栈寄存器SP一共有3个,分别为SP、MSP、PSP。
SP是对外使用的寄存器,或者认为SP始终指向各种模式、各种场景下使用的堆栈指针,只不过在OS或Handler模式下,SP先指向MSP,或者说SP拷贝了MSP的值,可以直接访问主堆栈。而在线程模式下,SP拷贝了PSP的值,可以直接访问线程(任务)堆栈。
即SP是MSP和PSP的代言人,即SP是MSP和PSP的逻辑地址,对于裸机程序,我们只需要知道SP即可,而对于OS系统,尤其涉及中断、任务上下文切换时,就需要知道PSP和MSP了,OS底层也会直接针对PSP进行编程。这里后续分析FreeRTOS调度实现原理时再详细解释。
进入中断前后MSP,PSP的切换
在前面的分析中我们知道,MSP用于线程模式+Handler模式,尤其在Hander模式下,CPU会自动切换到MSP,只有在OS系统中,任务task才会使用PSP,即PSP是专门为OS系统设计的,用于任务运行。
在发生中断或异常时,CPU需要自动的保存一半的现场寄存器值,R0~R3, R12, R13(SP), R14(LR)、R15(PC)到堆栈。这部分工作是CPU的硬件实现的。然后才执行中断服务程序。在这个过程中,我们写汇编程序的时候,其实只关心SP,但是内部,尤其是有OS系统的时候,其实是有区别的:
在发生中断时,CPU硬件需要自动保存现场,此时SP指向MSP还是PSP,取决于发生中断前正在使用的堆栈,即如果发生中断前,正在运行线程模式,而且是task任务运行,则使用PSP,而如果进入中断前,使用的MSP,这里就继续使用MSP。
一旦开始执行中断服务程序,即handler模式,则一定使用MSP,也就是,如果是有OS的情况下,正在运行task的时候,发生了中断,CPU先使用PSP自动保存现场,跳入到中断服务程序后,就从PSP切换到MSP,所有中断服务程序用到的临时变量都存放到MSP里。
上述两种情况MSP和PSP使用示意图如下:
裸机程序,一直使用MSP

OS系统下,MSP/PSP切换
上图中,入栈就是CPU自动保存现场的过程,此处仍然是使用PSP,只有进入到中断后,才会使用MSP。
任务切换过程中PSP和MSP指针的操作
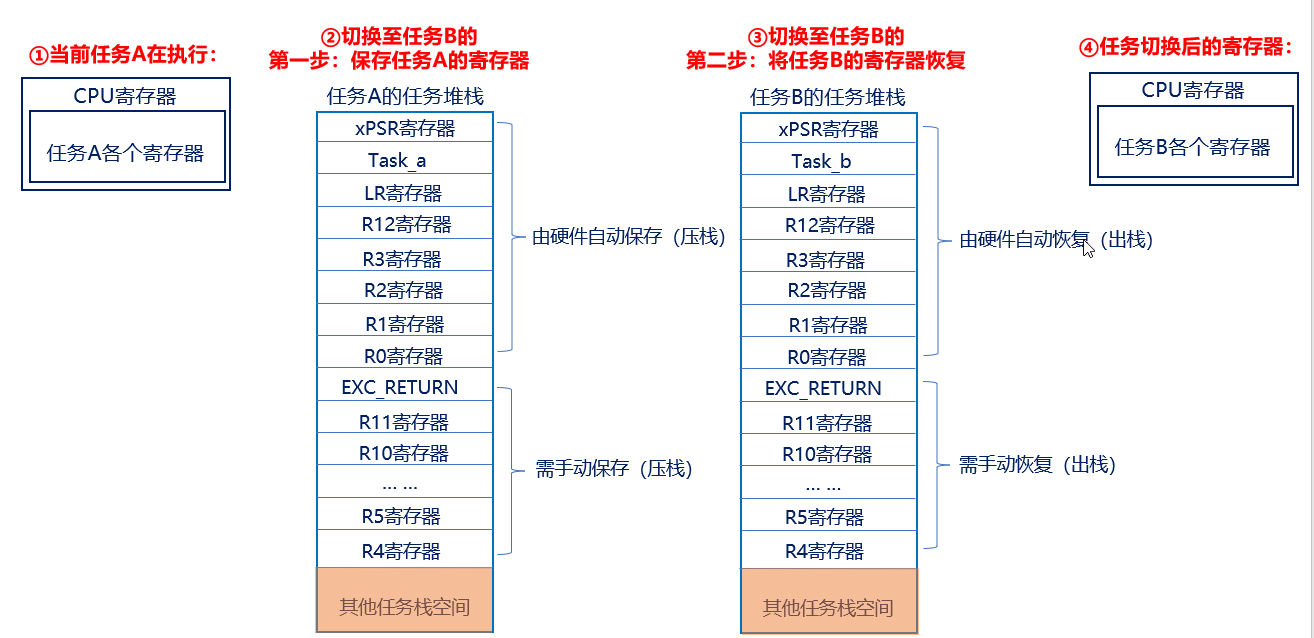
大概举个例子
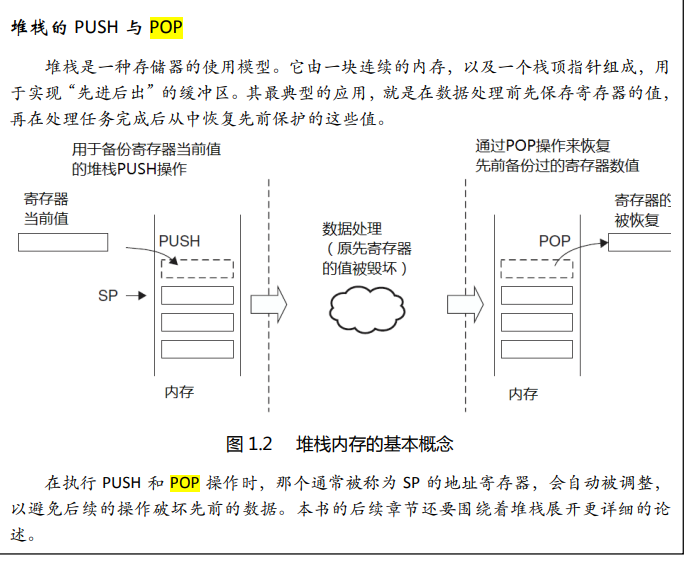
堆栈指针用于访问堆栈,并且 PUSH 指令和 POP 指令默认使用 SP
寄存器的 PUSH 和 POP 操作永远都是 4 字节对齐的,所以增删也是四个字节四个字节操作(动一次四个字节的情况通常是因为处理器的数据总线宽度是32位(4字节))
对于STM32来说,栈的生长方向由上往下生长,栈底位于高地址,栈顶位于低地址。出栈操作是将栈顶指针向高地址移动,入栈操作是将栈顶指针向低地址移动

’

