
- 1最新langchain v0.3版本+配合xinference框架+RAG详细教程—环境配置(常见坑总结)_xinference langchain
- 2OSPF定义的5种区域类型:标准区域、主干区域、存根区域、完全存根区域_ospf的区域有几种类型,分别是什么?
- 3【Kafka专题】Kafka集群架构设计原理详解
- 4掌握大模型这些优化技术,优雅地进行大模型的训练和推理!_大模型推理优化
- 5Ubuntu安装Python2或Python3多版本_2to3 python2-minimal:i386 python2:i386 python2-min
- 6Swin-Transformer论文阅读
- 7命令行修改MySQL数据库密码_mysql命令行修改密码
- 8Python中有关链表的操作(经典面试内容)_python 链表操作操作
- 9Visual Studio新手入门--调试、编译、设置断点详解_vs debug前提示进行编译
- 10SpringCloud-Eureka搭建_spring cloud eureka搭建
老黄不止卖铲子了:英伟达配合Llama3.1推出定制模型、推理服务
赞
踩
梦晨 发自 凹非寺
量子位 | 公众号 QbitAI
芯片巨头英伟达,在AI时代一直被类比为在淘金热中“卖铲子”的背后赢家。

现在他不装了,也要亲自下场“挖金矿”:
配合最强开源大模型Llama3.1,推出NVIDIA AI Foundry和NVIDIA NIM推理微服务两大新业务。
Foundry在芯片行业指“铸造厂”,比如台积电制造其他公司设计的芯片。
NVIDIA AI Foundry,代表英伟达可以定制化制造大模型了:
NVIDIA AI Foundry 提供从数据策管、合成数据生成、微调、检索、防护到评估的全方位生成式AI模型服务。

NVIDIA NIM在年初的GTC大会上首次亮相,使用几行代码就可以在云、数据中心、工作站和PC上部署AI模型。
现在则又新加一个标签:将Llama 3.1模型部署到生产中的最快途径,吞吐量最多可比不使用NIM运行推理时高出2.5倍。
为什么在这个时间点出手?
黄仁勋表示:“Meta的Llama 3.1开源模型标志着全球企业采用生成式 AI 的关键时刻已经到来”。
企业可以将Llama 3.1 NIM 微服务与与全新NVIDIA NeMo Retriever NIM微服务组合使用,为AI copilot、助手和数字人虚拟形象搭建先进的检索工作流。
NVIDIA和Meta还一起为Llama 3.1提供了一种提炼方法,供开发者为生成式AI应用创建更小的自定义Llama 3.1模型。这使企业能够在更多加速基础设施(如 AI 工作站和笔记本电脑)上运行由Llama驱动的AI应用。
之前老黄与小扎见面,交换皮衣穿,原来是商量这些合作去了(手动狗头)。

自定义模型+加速部署全流程服务
Llama 3.1系列模型发布还没几天,手快的企业已经用在生产中了。
Aramco、AT&T和优步,成为首批使用面向Llama 3.1全新NVIDIA NIM微服务的公司。
咨询巨头埃森哲更进一步,借助NVIDIA AI Foundry为自己以及咨询客户创建自定义Llama 3.1 模型,
从自定义模型到加速部署,被英伟达打造进了同一套流程。
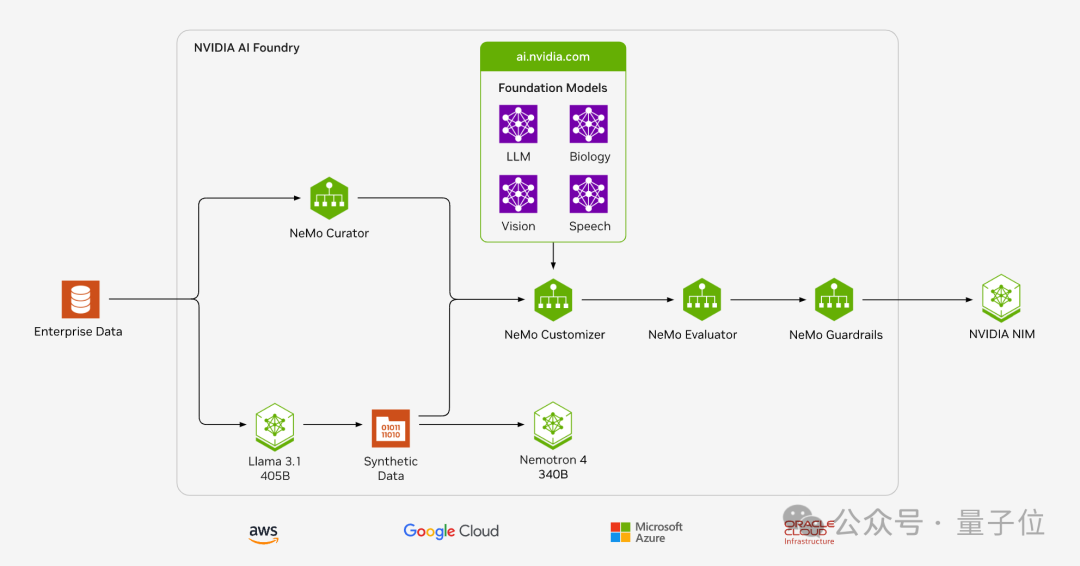
企业自有数据,可使用NeMo Curator开源Python库完成快速且可扩展的数据集准备和大模型用例的管理,包括基础模型预训练、领域自适应预训练 (DAPT)、监督微调 (SFT) 和参数高效微调 (PEFT)。
接下来使用NeMo Customizer简化大模型的微调和对齐。最初支持两种流行的参数高效微调技术:LoRA和P-Tuning。未来还将添加对完全对齐技术的支持,包括监督式微调(SFT)、从人类反馈中进行强化学习(RLHF)、直接偏好优化(DPO)以及NVIDIA SteerLM等。
Nemo Evaluator支持多种学术基准的自动评估,能够对自定义数据集进行评估,同时也支持支持使用大模型作为评委(LLM-as-a-Judge)对模型响应进行自动评估。
NeMo Guardrails使开发者能够构建三种边界:
主题护栏防止应用偏离进非目标领域,例如防止客服助理回答关于天气的问题。
功能安全护栏确保应用能够以准确、恰当的信息作出回复。它们能过滤掉不希望使用的语言,并强制要求模型只引用可靠的来源。
信息安全护栏限制应用只与已确认安全的外部第三方应用建立连接。
在创建了自定义模型后,企业就可以构建NVIDIA NIM推理微服务,在其首选的云平台,使用自己选择的最佳机器学习运维(MLOps)和人工智能运维(AIOps)平台在生产中运行这些模型。
合成数据趋势爆发
像Llama 3.1 405B和和英伟达Nemotron-4 340B这样超过千亿参数的大模型,用在绝大多数场景在成本和速度上都不会令人满意。
英伟达和Meta都意识到,用于生产合成数据,将是他们发挥作用的最大场景。
英伟达Nemotron-4 340B系列包括基础、指导和奖励模型,这些模型形成一个管道,用于生成用于训练和优化LLMs的合成数据,并且使用了独特宽松的开放模型许可证,为开发人员提供了一种免费、可扩展的方式来生成合成数据
Llama 3.1更新的开源协议这次也特别声明:允许使用Llama生产的数据去改进其他模型,只不过用了之后模型名称开头必须加上Llama字样。

参考链接:
[1]https://nvidianews.nvidia.com/news/nvidia-ai-foundry-custom-llama-generative-models
[2]https://blogs.nvidia.com/blog/nemotron-4-synthetic-data-generation-llm-training/
— 完 —
量子位年度AI主题策划正在征集中!
欢迎投稿专题 一千零一个AI应用,365行AI落地方案
或与我们分享你在寻找的AI产品,或发现的AI新动向

点这里
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

