
- 1SqlServer数据库安装及使用(第一篇)
- 2微调控件 0.1微调_微调T5变压器以完成任何汇总任务
- 3Mamba: Linear-Time Sequence Modeling with Selective State Spaces论文笔记_fm backbone
- 4一款免费开源的 Windows 资源管理神器,高颜值,丝滑流畅,24.5K Star快冲(带私活源码)_开源资源管理器
- 5本地部署Stable Diffusion WebUI_stable-diffusion-webui 本地部署
- 6基于的实验室设备管理系统(源码+开题)_设备管理系统开源
- 7SCP文件传输命令用法_scp -i
- 8NLP工具——doccano标注系统自动标注功能使用_doccano自动标注
- 9QListWidget 布局方向设定_qlistwidget 左右
- 10Linux系统安装海康MVS软件||Embedded Object Detection Project (part 8)_mvs软件linux
2024年大数据最新大数据基础习题(2)(4),2024年最新费时6个月成功入职阿里
赞
踩
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
10.scala>valwordCounts=textFile.flatMap(line=>line.split(“”)).map(word=>(word,1)).reduceByKey((a,b) => a + b) scala > wordCounts.collect() 在上面的代码中属于“行动”类型的操作的是(D)。 A. flatMap() B. Map() C. reduceByKey() D. collect()
11.Map任务的输入文件、Reduce任务的处理结果都是保存在(B)的。 A. 本地存储 B. 分布式文件系统 C. 硬盘 D. 主存
12.以下哪项不是MapReduce体系结构的主要组成部分(D) A. Client B. TaskTracker C. JobTracker D. TaskScheduler
13.下列选项中©不是文档数据库的优点 A. 性能好 B. 复杂性低 C. 统一的查询语法 D. 数据结构灵活
14.HBase是针对谷歌BigTable的开源实现,是一个高可靠、__B___、面向列、可伸缩的分布式数据库,主要用来存储非结构化和半结构化的松散数据。 A. A.高功能 B. B.高性能 C. C.低效率 D. D.高质量
15.UMP系统借助于__C___来实现集群内部的负载均衡。 A. 主从库实现用户调度 B. 主从库实现用户代理服务器 C. 利用主从库实现用户操作的分离 D. 主从库实现用户日志管理
16.Spark的主要编程语言是:(B)。 A. Java B. Scala C. Python D. R
17.以下属于商业级流计算的是:(A) A. IBM InfoSphere Streams B. Twitter Storm C. Yahoo! S4 D. FaceBook Puma
18.下列选项不属于Zookeeper主要发挥的作用的是__D A. 提供分布式锁 B. 监控所有MySQL实例 C. 作为全局的配置服务器 D. 支持透明的数据分片作用
19.以下哪项步骤不包含在溢写过程中(B) A. 分区 B. 文件归并 C. 排序 D. 合并
20.下列哪个不是连接RDS for MySQL数据库的方法© A. 使用客户端MySQL-Front访问 B. 使用数据库管理工具Navicat_MySQL C. Shell命令 D. 使用MySQL命令登录
21.MapReduce的处理单位是(B) A. block B. split C. Map D. RR
22.以下不属于hadoop存在的缺点的是:(B) A. 表达能力有限 B. 编程模式灵活 C. 磁盘IO开销大 D. 延迟高
23.谷歌的GFS和MapReduce等大数据技术受到追捧,Hadoop平台开始大行其道是在大数据发展的那个时期(B ) A. 第一阶段 B. 第二阶段 C. 第三阶段 D. 第四阶段
24.每个Map任务分配一个缓存,MapReduce默认缓存是(A) A. 100MB B. 80MB C. 120MB D. 200MB
多选: 1.MapReduce执行的全过程包括以下几个主要阶段(ABCD) A. 从分布式文件系统读入数据 B. 执行Map任务输出中间结果 C. 通过Shuffle阶段把中间结果分区排序整理后发送给Reduce任务 D. 执行Reduce任务得到最终结果并写入分布式系统文件
2.HDFS特殊的设计,在实现上述优良特性的同时,也使得自身具有一些应用局限性,主要包括以下几个方面 (AB) A. A.不适合低延迟数据访问 B. B.无法高效存储大量小文件 C. C.不支持单用户写入及任意修改文件 D. D.硬件设备昂贵
3.最终一致性根据更新数据后各进程访问到数据的时间和方式的不同,可以进行区别。下列说法正确的是 ABCD A. 因果一致性 B. 读己之所写一致性 C. 单调读一致性$会话一致性 D. 单调写一致性
4.Reduce端的Shuffle过程包括(ABD) A. “领取”数据 B. 归并数据 C. 溢写 D. 把数据输入到Reduce任务
5.采用HDFS联邦的设计方式,可解决单名称节点以下问题(ABD) A. HDFS集群可扩展性 B. 性能更高效 C. 单点故障问题 D. 良好的隔离性
6.MapReduce1.0架构设计具有一些很难克服的缺陷,包括(ABCD) A. 存在单点故障 B. JobTracker“大包大揽”导致任务过重 C. 容易出现内存溢出 D. 资源划分不合理
7.三次信息化浪潮的标志有哪些(ABC) A. 个人计算机 B. 互联网 C. 物联网,云计算和大数据 D. 人工智能
8.信息科技需要解决的核心问题包括:(ACD) A. 信息存储 B. 信息可视 C. 信息传输 D. 信息处理
9.以下属于批处理大数据计算的产品有:(AC) A. MapReduce B. Storm C. Spark D. Pregel
10.以下属于图计算的产品有:(ABCD) A. Pregel B. GraphX C. Giraph D. PowerGraph
11.访问HBase表中的行有哪几种方式(ABD) A. 通过单个行键 B. 行键的区间 C. 列族 D. 全表扫描
12.大数据对科学研究有哪些影响(ABCD) A. 第一范式:实验科学 B. 第二范式:理论科学 C. 第三范式:计算科学 D. 第四范式:数据密集型科学
13.关系数据库无法满足Web2.0的需求主要表现在哪几个方面(ACD) A. 无法满足海量数据的管理需求 B. 无法满足数据完整性 C. 无法满足数据高并发的需求 D. 无法满足高可扩展性和高可用性的需求
14.人类科学研究范式包括:(ABCD) A. 实验 B. 理论 C. 计算 D. 数据
15.下面关于MapReduce工作流程说法正确的是(ABD) A. 不同的Map任务之间不会进行通信。 B. 不同的Reduce任务之间也不会发生任何信息交换。 C. 用户能显式的从一台机器向另一台机器发送信息 D. 所有的数据交换都是通过MapReduce框架自身去实现的
16.与传统并行计算框架相比,以下哪些是MapReduce的优势(ABC) A. 非共享式,容错性好 B. 普通PC机,便宜,扩展性好 C. 编程/学习难度较简单 D. 适用场景为实时、细粒度计算、计算密集型
17.Hadoop1.0的核心组件主要存在以下不足(ABCD) A. 难以看到程序整体逻辑 B. 开发者自己管理作业之间的依赖关系 C. 执行迭代操作效率低 D. 资源浪费
18.NoSQL数据库的明显优势在于(BCD) A. 数据的完整性 B. 可以支持超大规模数据存储 C. 灵活的数据模型 D. 强大的横向扩展能力
19.HDFS在设计上采取了多种机制保证在硬件出错的环境中实现数据的完整性。总体而言,HDFS要实现以下目标: (1)兼容廉价的硬件设备 (2)流数据读写 (3)大数据集 (4)复杂的文件模型 (5)强大的跨平台兼容性 (D) A. A.(1)(2)(3)(4) B. B.(1)(2)(4)(5) C. C.(2)(3)(4)(5) D. D.(1)(2)(3)(5)
20.Map端的Shuffle过程包括以下哪几个步骤。(ABCD) A. 输入数据和执行Map任务 B. 写入缓存 C. 溢写(分区、排序、合并) D. 文件归并
21.MapReduce的广泛应用包括(ABCD) A. 关系代数运算 B. 分组与聚合运算 C. 矩阵乘法 D. 矩阵-向量乘法
22.大数据处理主要包括三个类型,分别是:(ABC)。 A. 复杂的批量数据处理 B. 基于历史数据的交互式查询 C. 基于实时数据流的数据处理 D. 集成数据
23.UMP系统采用哪两种资源隔离方式(AB) A. 用Cgroup限制MySQL进程资源 B. 在Proxy服务器端限制QPS C. 通过MySQL实例的迁移 D. 采用资源池机制管理数据库服务器资源
24.MapReduce执行的全过程包括以下几个主要阶段(ABCD) A. 从分布式文件系统读入数据 B. 执行Map任务输出中间结果 C. 通过Shuffle阶段把中间结果分区排序整理后发送给Reduce任务 D. 执行Reduce任务得到最终结果并写入分布式系统文件
25.以下(ACD)产品使Hadoop功能更加完善. A. Pig B. QJM C. Tez D. Oozie
26.以下属于流计算的产品有:(ABCD) A. Storm B. S4 C. Flume D. Puma
27.基于MapReduce模型的关系上的标准运算,包括(ABCD) A. 选择运算 B. 并、交、差运算 C. 投影运算 D. 自然连接运算
28.不同的计算框架统一运行在YARN中,可以带来如下好处:(ACD) A. 计算资源按需伸缩 B. 计算资源平均分配 C. 不用负载应用混搭,集群利用率高 D. 共享底层存储,避免数据跨集群迁移
29.数据采集系统的基本架构一般有以下三个部分:(ABD) A. Agent B. Collector C. Calculate D. Store
30.以下属于Spark的主要特点的是:(ABCD)。 A. 运行速度快 B. 容易使用 C. 通用性 D. 运行模式多样
31.Spark采用RDD以后能够实现高效计算的原因主要在于:(ABD) A. 高效的容错性 B. 中间结果持久化到内存 C. 两种依赖方式 D. 存放的数据可以是Java对象
32.下列为UMP系统架构设计遵循的原则的是(ABCD) A. 保持单一的系统对外入口,并且为系统内部维护单一的资源池 B. 消除单点故障,保证服务的高可用性 C. 保证系统具有良好的可伸缩性,能动态地增加、删减计算与存储节点 D. 保证分配给用户的资源也是弹性可伸缩的,资源之间相互隔离,确保应用和数据的安全
33.信息科技为大数据时代提供的支撑(BCD) A. 计算机设备廉价 B. 存储设备容量不断增加 C. CPU处理能力大幅度提升 D. 网络带宽不断增加

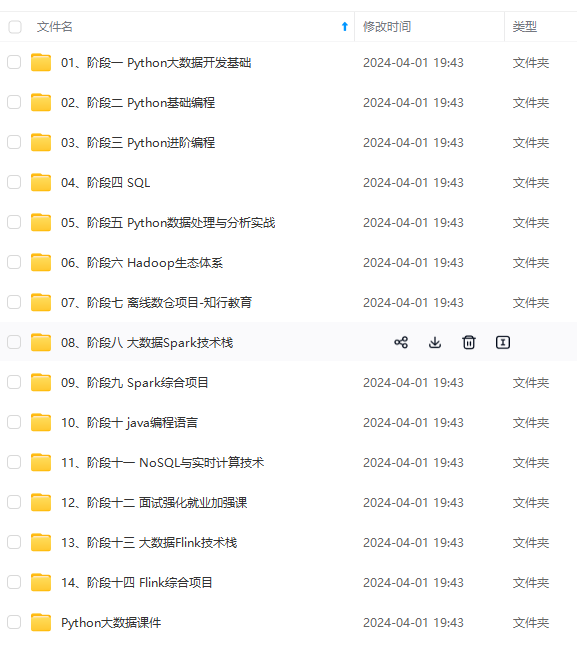
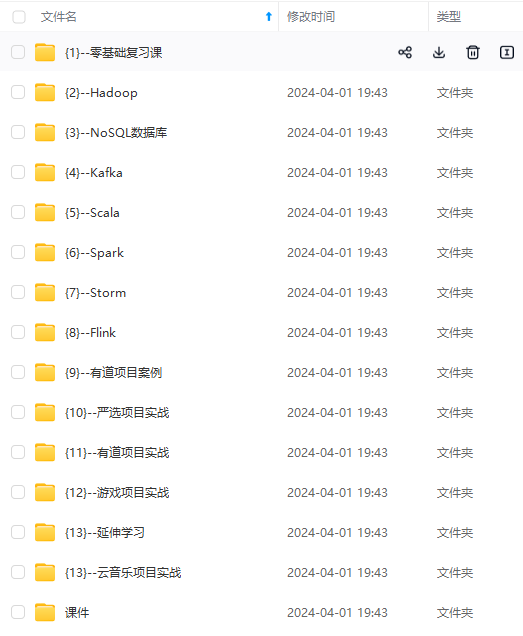
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
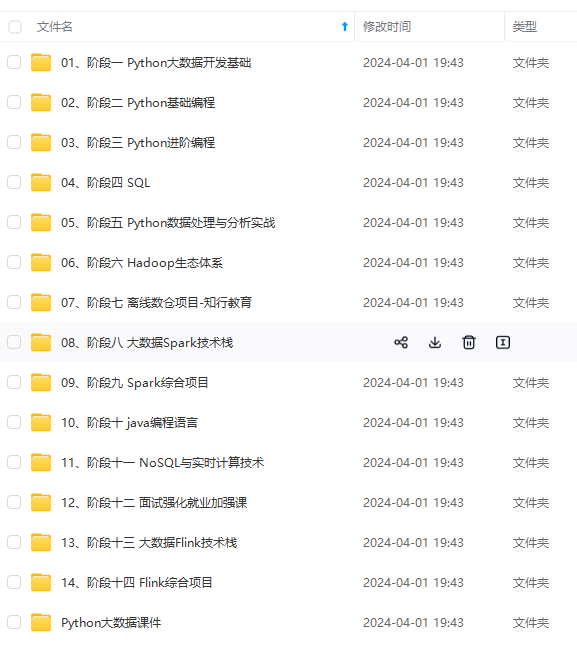
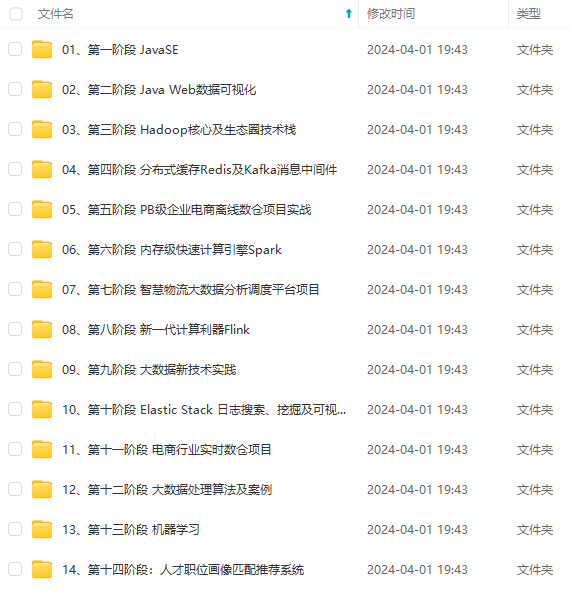
也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!**
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新

