
- 1AXI Quad SPI IP核基于AXI接口的设计指南
- 2数据传输安全(为支付宝第三方做铺垫)
- 3解码2024:可解释人工智能的十大突破揭晓_2024年神经网络的可解释性这一大突破对于什么至关重要
- 4Android Gradle相关总结_gradle-6.7.1-all.zip
- 5Vue+OpenLayers 实现地图上添加 Echarts 环形图_openlayers在地图上添加效果
- 6毕业设计:基于深度学习的用户评价情感分析系统_怎么通过平均主题余弦相似度判断最优主题数
- 7vue3+vite+ts 使用webrtc-streamer播放海康rtsp监控视频_vue3 webrtc 播放
- 8NOI的1.5.39与7无关的数_noi与7无关的数csdn
- 9linux安装emqx_linux 更换emqx版本
- 10终于还是在上电时序问题上给自己挖了个坑
AI 时代的巫师与咒语
赞
踩
2022底年初,回看生成式ai时代,现在我们每个人都可以使用自己喜欢的咒语去创造一个光彩斑斓的幻想世界
背景
AIGC 产品的爆发
回顾下AIGC的发展
copy.ai
Copy.ai 是一个通过人工智能(AI)技术帮你写各种推广文案的创业公司,你可以用它几秒钟内生成高质量的广告和营销文案,核心是帮助企业和个人节省时间和精力
仅2年时间,Copy.ai的ARR达1000万美金用户突破200万
Jasper.ai
Jasper.ai 10月宣布完成了 1.25 亿美金的 A 轮融资,估值达到了 15 亿美金,而 Jasper AI 从产品上线到现在也就 18 个月时间

Jasper.ai 做的事情和 Copy.ai 非常类似,通过 AI 人工智能帮企业和个人写营销推广文案以及博客等各种文字内容,整个逻辑和 Copy.ai 非常类似,并且也提供了大量的模版,其底层技术也是 GPT-3,但团队在此基础上做了大量的改进,特别是在广告和营销的内容生成这块。
DALL E2
Open AI 出品,diffusion 模型,不开源
-
文字生成图片

-
Inpainting
DALL·E 2 can expand images beyond what’s in the original canvas, creating expansive new compositions

-
edit
DALL·E 2 can make realistic edits to existing images from a natural language caption. It can add and remove elements while taking shadows, reflections, and textures into account

Imagen
Google 出品,不开源

Midjourney
https://www.midjourney.com/
使用discord 社区提供服务,偏向于创建具有绘画性、美观性的图像

Runway
基于人工智能的视频编辑器 RunwayML 已被用于编辑《The Late Show》、
《Top Gear America》和《Everything Everywhere All at Once》等电视
电影节目。
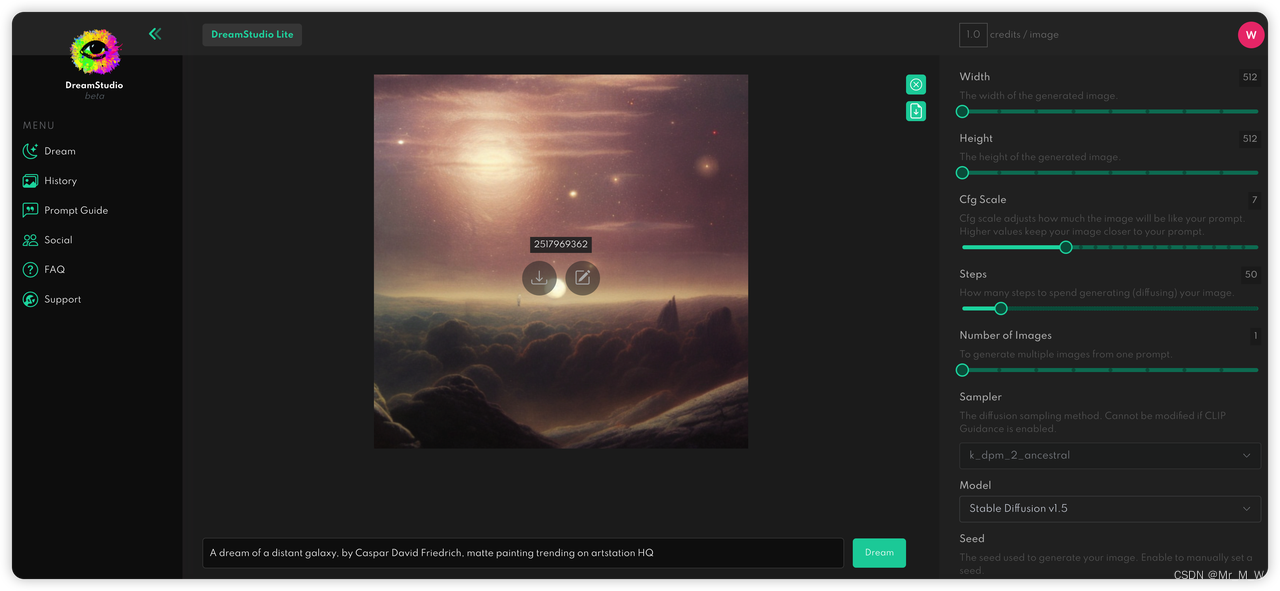
Stable diffusion
stability.ai 开源的模型,引爆文生图市场
种子轮拿了 1.01 亿美金估值 10 亿美金的 Stability AI
https://beta.dreamstudio.ai/dream


AIGC
定义
AIGC全称为AI-Generated Content,指基于生成对抗网络GAN、大型预训练模型等人工智能技术,通过已有数 据寻找规律,并通过适当的泛化能力生成相关内容的技术。与之相类似的概念还包括Synthetic media,合成式媒 体,主要指基于AI生成的文字、图像、音频等

特点:多模态,大模型,开源
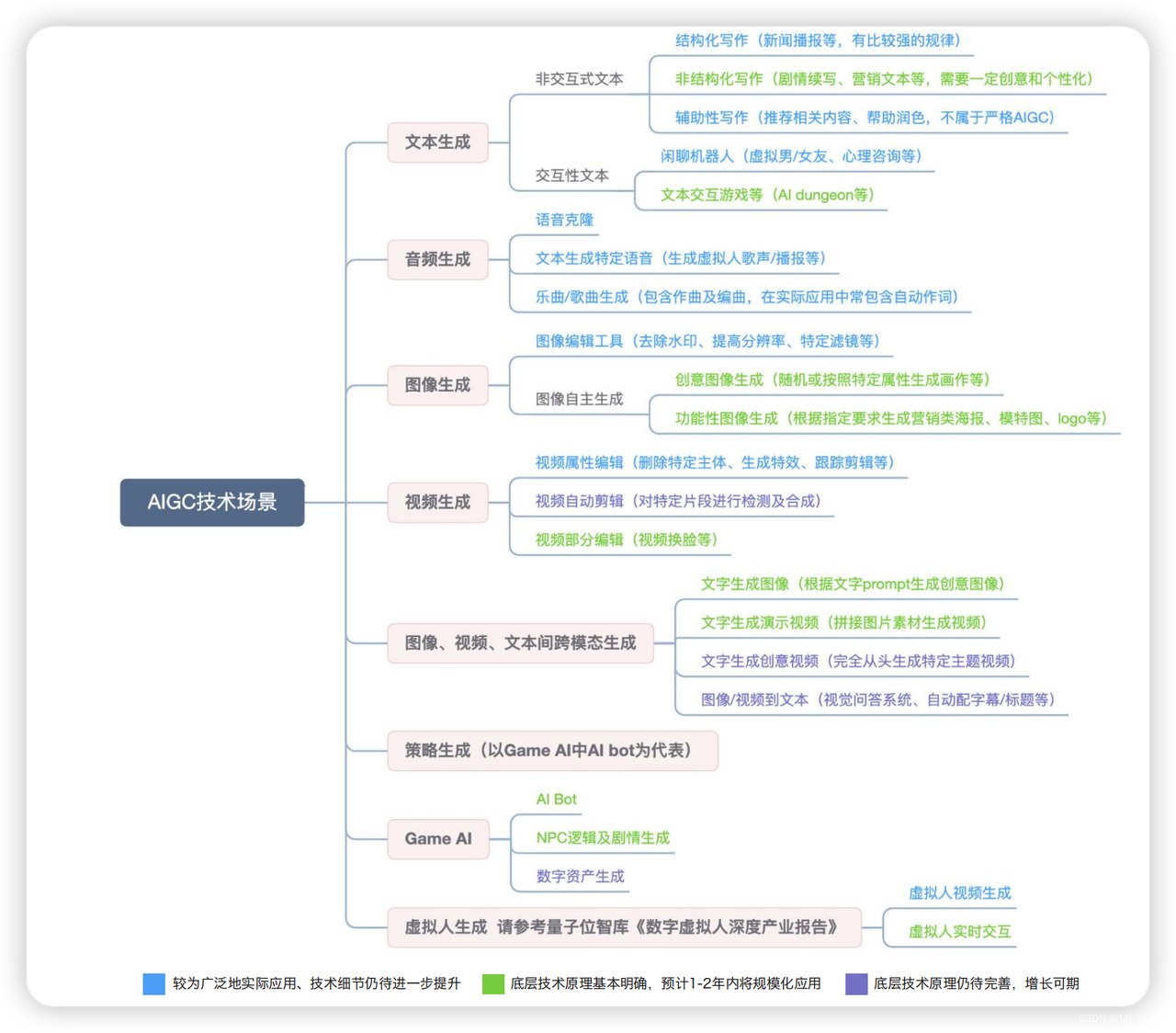
技术场景
产品
国外:
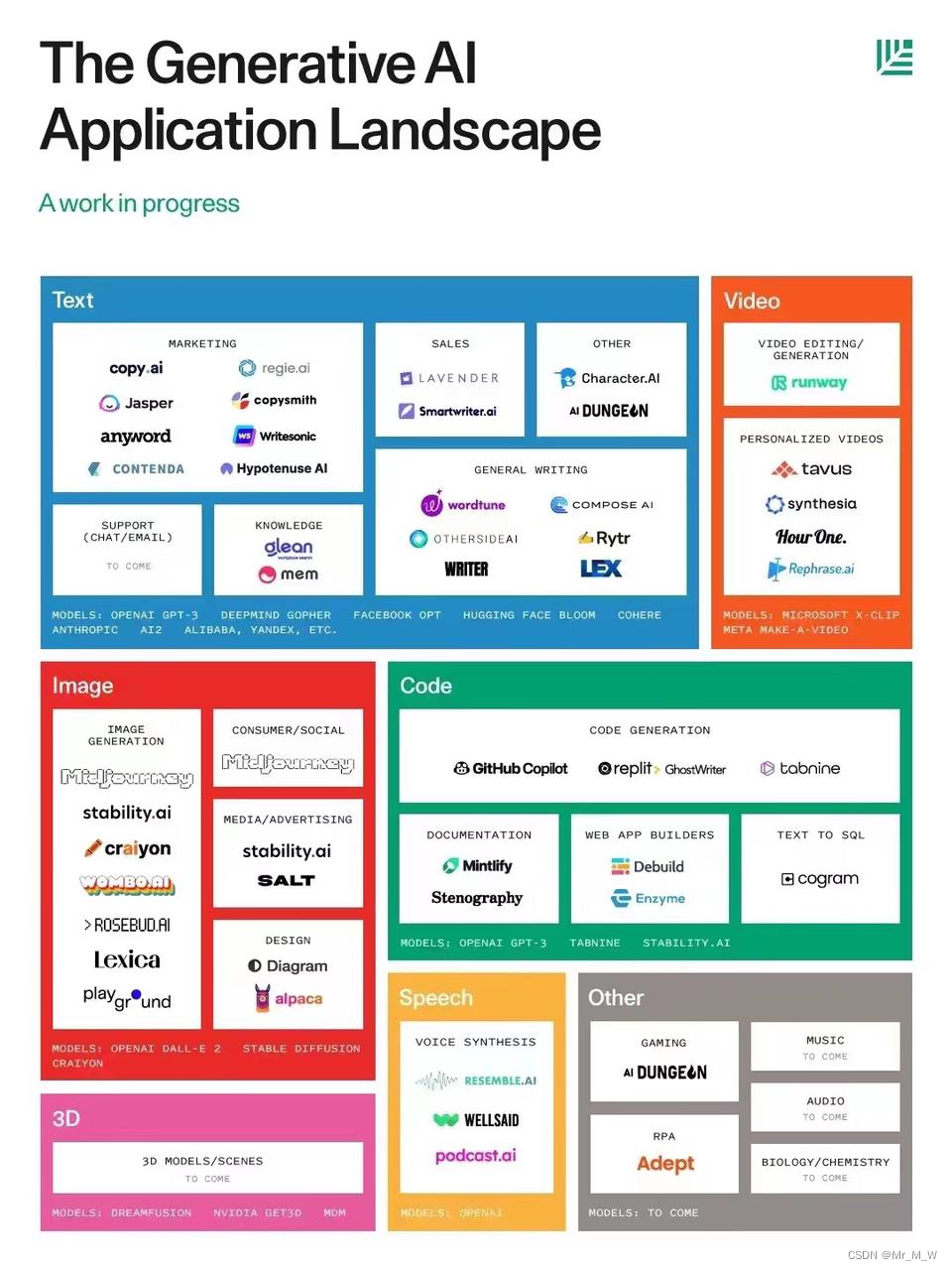
视频生成
2022年9月29日,Meta 和 Phenaki.video 已经公开Text to Video工具,https://makeavideo.studio/

国内:
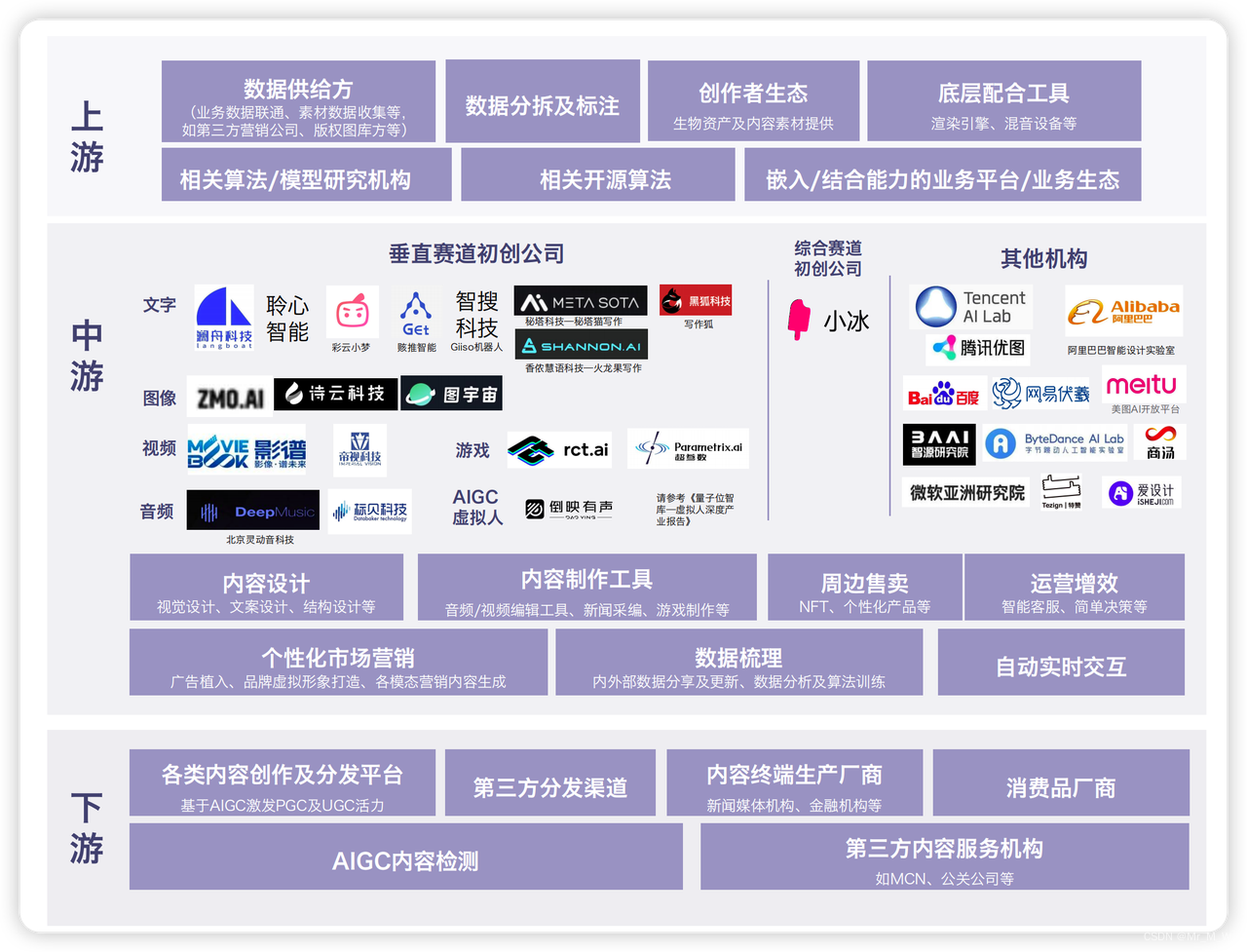
技术发展milliestone
图像生成关键节点
GAN系列
GAN(2014)指Generative Adversarial Nets,生成式对抗网络,由生成器和判别器两部分组成,生成器将抓取数据、 产生新的生成数据,并将其混入原始数据中送交判别器区分。这一过程将反复进行,直到判别器无法以超过50% 的准确度分辨出真实样本
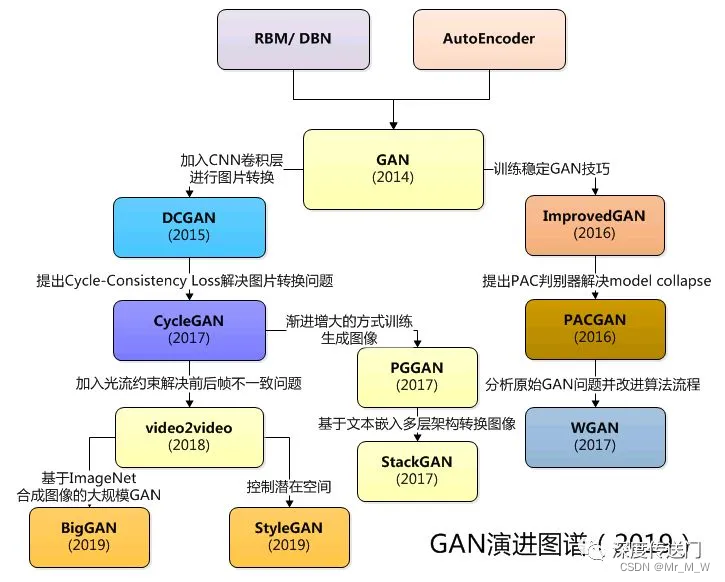
延伸发展模型: styleGAN, CircleGAN,EditGAN 等

生成模型
比较关键的几个生成模型 GAN、VAE、Flow-based Models、Diffusion Models
生成模型的对比:
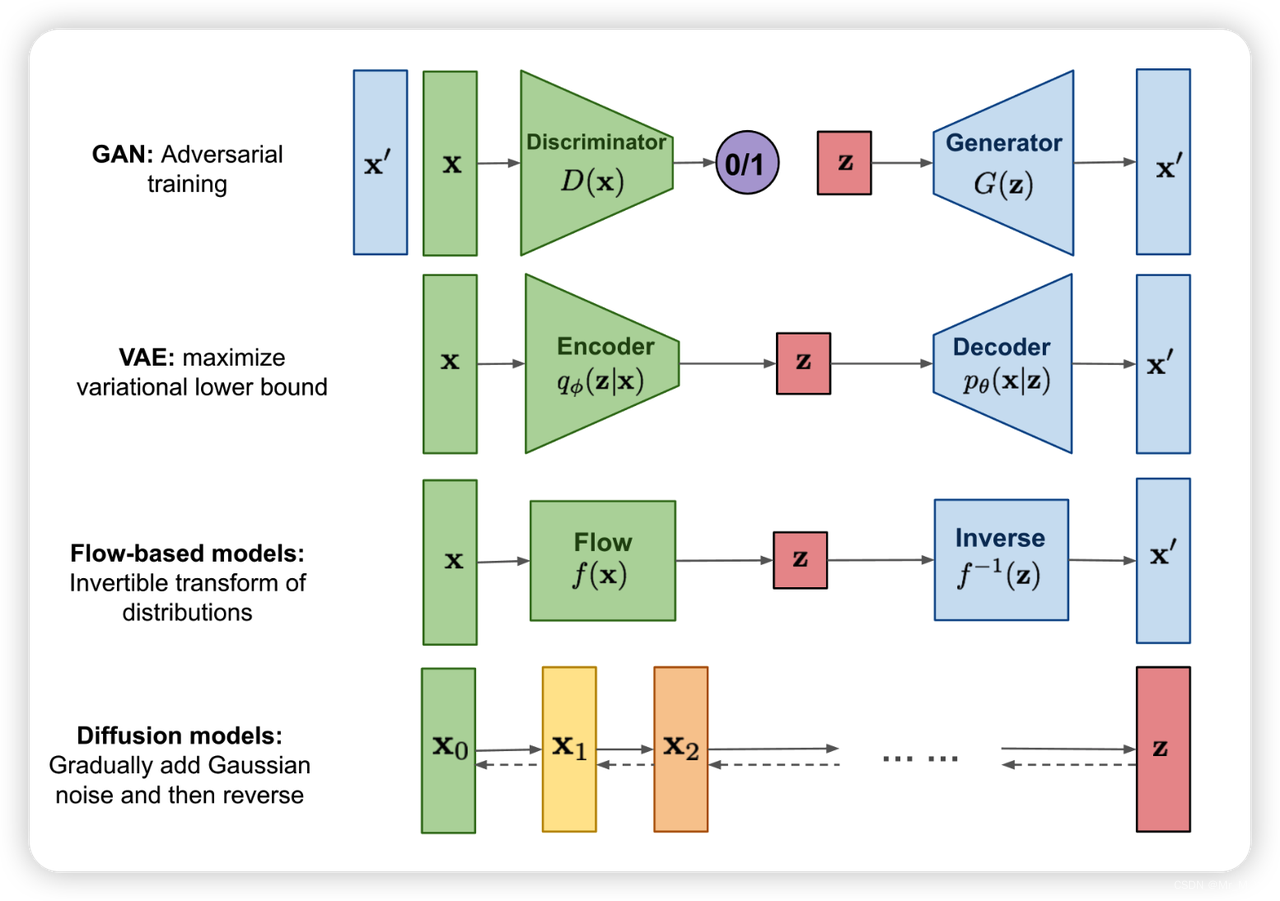
GAN 由一个生成器(generator)和判别器(discriminator)组成,generator 负责生成逼真数据以“骗”过 discriminator,而 discriminator 负责判断一个样本是真实的还是“造”出来的。GAN 的训练其实就是两个模型在相互学习,能不能不叫“对抗”,和谐一点。
VAE 同样希望训练一个生成模型 x=g(z),这个模型能够将采样后的概率分布映射到训练集的概率分布。生成隐变量 z,并且 z 是及含有数据信息又含有噪声,除了还原输入的样本数据以外,还可以用于生成新的数据。
Diffusion Models 的灵感来自 non-equilibrium thermodynamics (非平衡热力学)。理论首先定义扩散步骤的马尔可夫链,以缓慢地将随机噪声添加到数据中,然后学习逆向扩散过程以从噪声中构造所需的数据样本。与 VAE 或流模型不同,扩散模型是通过固定过程学习,并且隐空间 z 具有比较高的维度。
Diffusion Models
扩散模型(Diffusion Models)是深度生成模型中新的SOTA。扩散模型在图片生成任务中超越了原SOTA:GAN,并且在诸多应用领域都有出色的表现,如计算机视觉,NLP、波形信号处理、多模态建模、分子图建模、时间序列建模,对抗性净化等
生成模型发展脉络
Diffusion模型自从Jascha于2015年第一次提出后,各类Diffusion模型层出不穷。
如今生成扩散模型的大火,则是始于2020年所提出的 DDPM(Denoising Diffusion Probabilistic Model),仅在 2020 年发布的开创性论文 DDPM 就向世界展示了扩散模型的能力,在图像合成方面击败了 GAN,所以后续很多图像生成领域开始转向 DDPM 领域的研究。
Diffusion Models 既然叫生成模型,这意味着 Diffusion Models 用于生成与训练数据相似的数据
一个标准扩散模型有两个主要的过程域: 前向扩散和逆向扩散。在前向扩散阶段,图像被逐渐引入的噪声污染,直到图像成为完全随机噪声。在反向过程中,利用一系列马尔可夫链在每个时间步逐步去除预测噪声,从而从高斯噪声中恢复数据
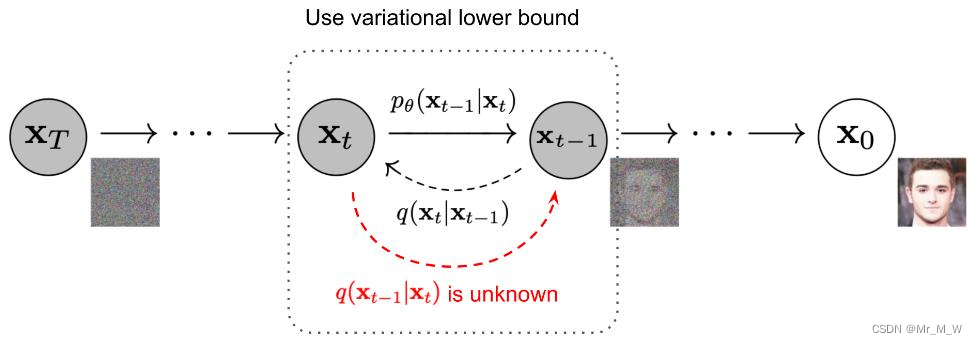
前向扩散过程:给图片加高斯噪声,不断迭代之后生成一个噪点图
DDPM模型:根据噪点图,反向施加高斯噪声,还原(其实就是画)出图片 模型学习的参数:反向还原时,高斯噪声的均值需要用神经网络拟合
图片生成的过程:

更多:
-
DDIM
Denoising Diffusion Implicit Models
DDIM和DDPM有相同的训练目标,但是它不再限制扩散过程必须是一个马尔卡夫链,这使得DDIM可以采用更小的采样步数来加速生成过程,DDIM的另外是一个特点是从一个随机噪音生成样本的过程是一个确定的过程(中间没有加入随机噪音)。
-
GLIDE-基于类别引导的扩散模型
GLIDE(202112) : Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models
OpenAI的Guided Diffusion 提出了一种简单有效的类别引导的扩散模型生成方式。Guided Diffusion的核心思路是在逆向过程的每一步,用一个分类网络对生成的图片进行分类,再基于分类分数和目标类别之间的交叉熵损失计算梯度,用梯度引导下一步的生成采样。这个方法一个很大的优点是,不需要重新训练扩散模型,只需要在前馈时加入引导既能实现相应的生成效果
-
LDM
Laten diffusion model (stable diffusion 的来源)
-
Classifier-Free Diffusion Guidance(202207):
省略分类器,联合训练条件/非条件diffusion模型,更好地权衡质量和多样性
2d-3d 的转换
神经辐射场模型NeRF — 符合3D内容消费趋势的新一代模型


多模态技术
Transformer
Transformer 是关键的技术
2017年的一篇关于来自 Google Brain 和多伦多大学研究人员关于 Transformer 模型在自然语言处理中应用的论文:《Attention Is All You Need》。

Transformer 最早由Google发明,但很快就被OpenAI应用于其GPT1/2/3的开发当中,也奠定了之后出现的一系列AI内容生成产品的基础。
Transformer架构的核心是Self-Attention机制,该机制使得Transformer能够有效提取长序列特征,相较于 CNN能够更好的还原全局。而多模态训练普遍需要将图片提取为区域序列特征,也即将视觉的区域特征和文本特征 序列相匹配,形成Transformer架构擅长处理的一维长序列,对Transformer的内部技术架构相符合。与此同时, Transformer架构还具有更高的计算效率和可扩展性,为训练大型跨模态模型奠定了基础。
Vision Transformer 将Transformer架构首次应用于图像领域。该模型在特定大规模数据集上的训练成果超出了 ResNet。随后,谷歌的VideoBERT尝试了将Transformer拓展到“视频-文本”领域。该模型能够完成看图猜词 和为视频生成字幕两项功能,首次验证了Transformer+预训练在多模态融合上的技术可行性。
基于Transformer 的多模态模型开始受到关注,ViLBERT、LXMERT、UNITER、Oscar等纷纷出现
CLIP模型
CLIP模型的出现,成为跨模态生成应用的一个重要节点。CLIP 真的把自然语言级别的抽象概念带到计算机视觉里了,可以说是奇点的存在
CLIP,Contrastive Language–Image Pre-training,由OpenAI在2021年提出,图像编码器和文本编码器以 对比方式进行联合训练,能够链接文本和图片。可以简单将其理解为,利用CLIP测定图片和文本描述的贴切程度。
CLIP是一种基于对比学习的多模态模型,与CV中的一些对比学习方法如moco和simclr不同的是,CLIP的训练数据是文本-图像对:一张图像和它对应的文本描述,这里希望通过对比学习,模型能够学习到文本-图像对的匹配关系。如下图所示,CLIP包括两个模型:Text Encoder和Image Encoder,其中Text Encoder用来提取文本的特征,可以采用NLP中常用的text transformer模型;而Image Encoder用来提取图像的特征,可以采用常用CNN模型或者vision transformer。
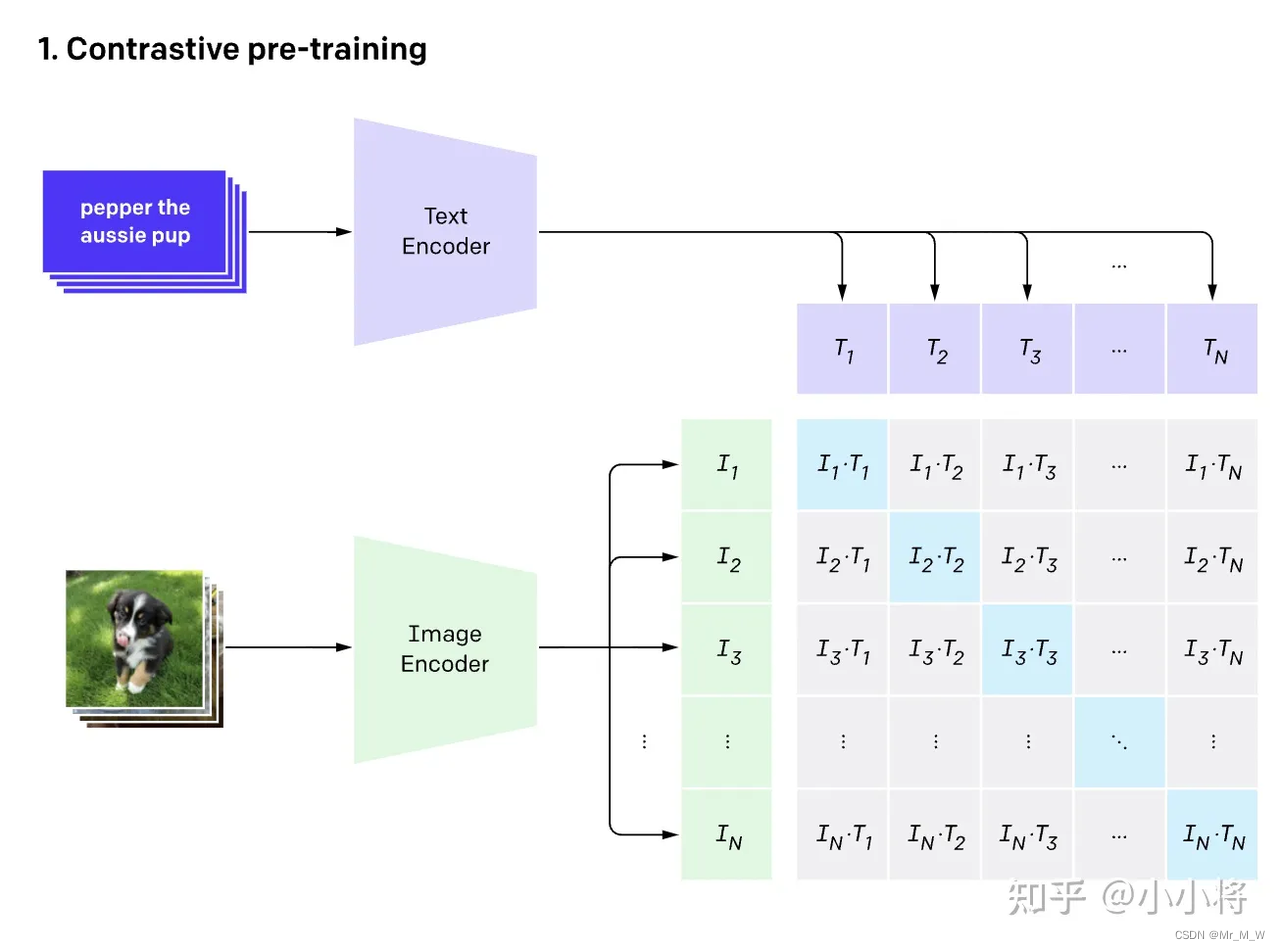
DDPM 模型
DDPM(Denoising Diffusion Probabilistic Model)
大型预训练模型
跨模态大型预训练模型的代表包括:开启了跨模态预训练模型的Open AI DALL·E及CLIP、NVIDIA GauGAN2、 微软及北大 NÜWA女娲、NVIDIA PoE GAN、DeepMind的Gato、百度ERNIE-ViLG、Facebook及Meta 的AV- HuBERT(基于语音和唇语输出文本)及Data2vec(横跨CV、NLP和语音)、中科院“紫东太初”、哥大及 Facebook开发的VX2Text(基于视频、音频等输出文本)、stable difusion
大型预训练模型的发展重点开始向横跨文本、图像、语音、视频的全模态通用模型发展。模型的参数量越来越大,从1亿级到百亿级再到千亿级
多模态能力的提升将成为A真正I实现认知智能和决策智能的关键转折点
开源趋势
https://huggingface.co/
Hugging Face 已经成为AI和 machine learning 领域模型和人才的聚集社区
Stable diffusion 模型
目前diffusion model 存在的问题: 高昂的计算代价,推理速度不够快
Latent Diffusion Models
来自的论文 High-Resolution Image Synthesis with Latent Diffusion Models (CVPR 2022)
Intro
这篇文章的核心在于改善diffusion mode训练和推理过程中效率低的问题。总所周知,DM的训练需要消耗数百GPU/天的资源,DM的推理也需要数百step的序列化过程。本文提出一种基于latent特征空间的DM,可以实现计算资源要求的降低,并且保持生成的质量和合理性。这不就是解决了中小企业训练文图生成大模型的痛点了。本文的主要贡献有:
-
多尺度。本文提出的LDM可以很好的适配高清图片的生成场景。
-
高效率。本文提出的LDM模型在inpainting,文图生成、超分等任务中都极大的提升了模型训练和对立效率。
-
训练稳定性。特征隐空间的构建能力更加faithful。
-
模型优化。本文设计了基于cross-attention的结构,可以较好的进行conditional方式的训练。
-
代码开源。
LDM 基本原理
流程
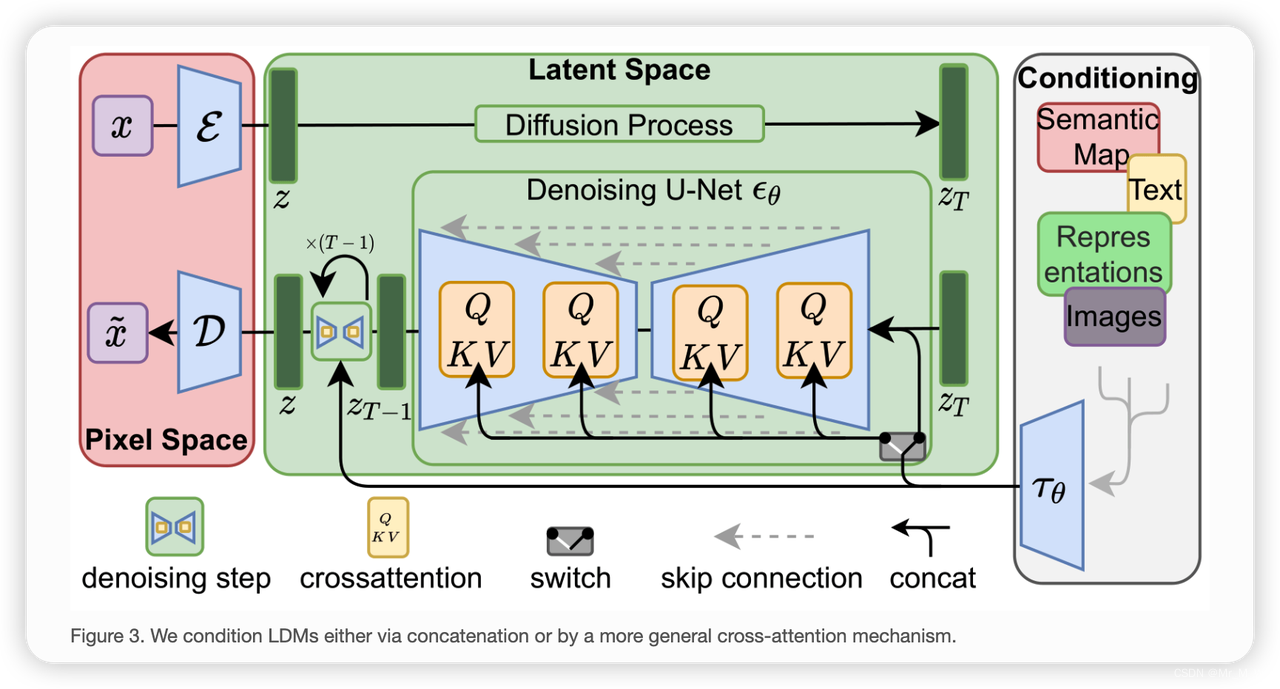
Latent Diffusion Models整体框架如图,首先需要训练好一个自编码模型(AutoEncoder,包括一个编码器 E 和一个解码器 D )。这样一来,我们就可以利用编码器对图片进行压缩,然后在潜在表示空间上做diffusion操作,最后我们再用解码器恢复到原始像素空间即可,论文将这个方法称之为感知压缩(Perceptual Compression)。这种将高维特征压缩到低维,然后在低维空间上进行操作的方法具有普适性,可以很容易推广到文本、音频、视频等领域。
在潜在表示空间上做diffusion操作其主要过程和标准的扩散模型没有太大的区别,所用到的扩散模型的具体实现为 time-conditional UNet。但是有一个重要的地方是论文为diffusion操作引入了条件机制(Conditioning Mechanisms),通过cross-attention的方式来实现多模态训练,使得条件图片生成任务也可以实现。
核心:感知压缩、扩散模型、条件机制。
三个主要组成部分
-
The Autoencoder (VAE)
自动编码器(VAE)由两个主要部分组成:编码器和解码器。编码器将把图像转换成低维的潜在表示形式,该表示形式将作为下一个组件U_Net的输入。解码器将做相反的事情,它将把潜在的表示转换回图像。
在潜扩散训练过程中,利用编码器获得正向扩散过程中输入图像的潜表示(latent)。而在推断过程中,VAE解码器将把潜信号转换回图像。
-
U-NET
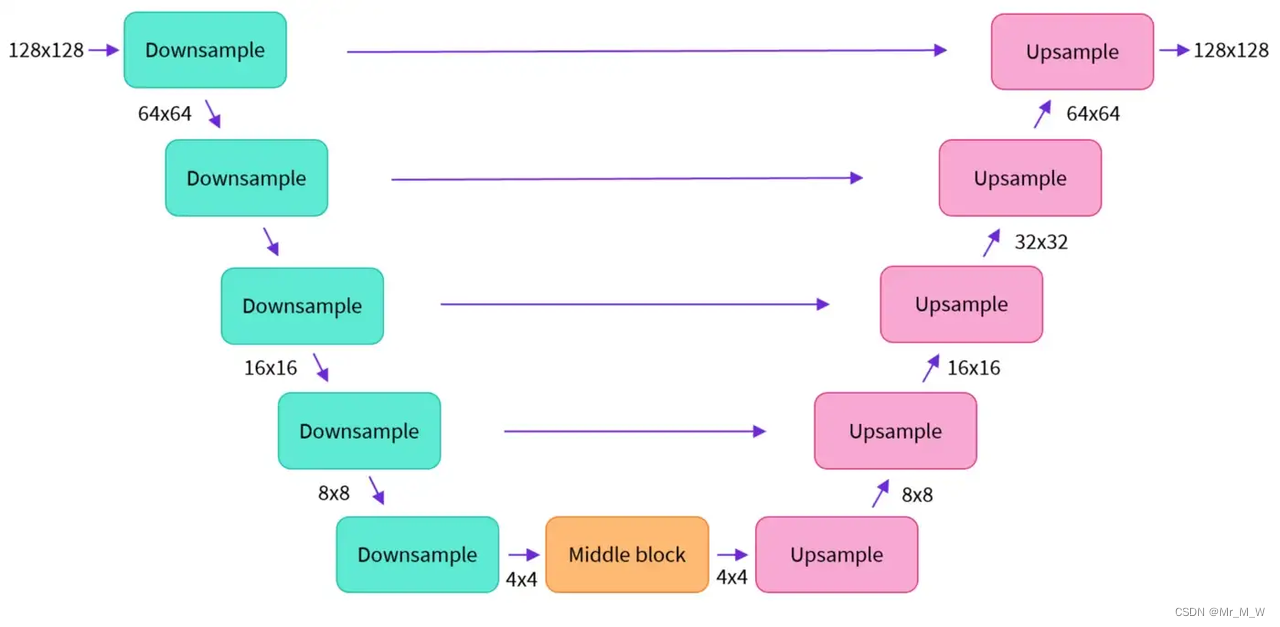
U-Net还包括编码器和解码器两部分,两者都由ResNet块组成。编码器将图像表示压缩为低分辨率图像,解码器将低分辨率解码回高分辨率图像
为了防止U-Net在下采样时丢失重要信息,通常在编码器的下采样resnet和解码器的上采样resnet之间添加short-cut连接。
此外,稳定的扩散U-Net能够通过交叉注意层对文本嵌入的输出进行调节。交叉注意层被添加到U-Net的编码器和解码器部分,通常在ResNet块之间。
-
The Text-Encoder
文本编码器将把输入提示转换为U-Net可以理解的嵌入空间,例如,“皮卡丘精致的餐厅,可以看到Effiel塔”。这将是一个简单的基于变压器的编码器,它将标记序列映射到潜在文本嵌入序列。
使用良好的提示符以获得预期的输出是很重要的。这就是为什么现在提示工程的话题成为趋势。提示工程是寻找某些词的行为,这些词可以触发模型产生具有特定属性的输出
LDM高效的原因
Latent Diffusion之所以快速有效,是因为它的U-Net是在低维空间上工作的。与像素空间扩散相比,这降低了内存和计算复杂度。例如,一个(3,512,512)的图像在潜在空间中会变成(4,64,64),内存将会减少64倍
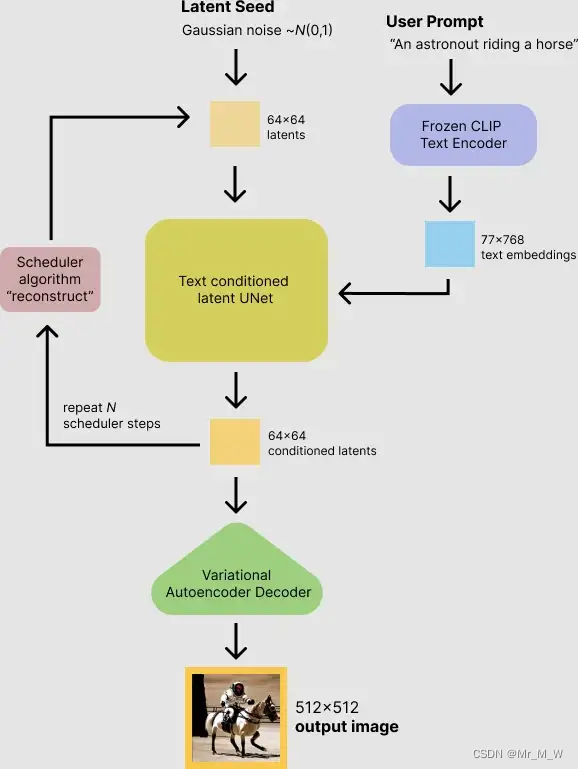
推理的过程
首先,模型将潜在空间的随机种子和文本提示同时作为输入。然后使用潜在空间的种子生成大小为64×64的随机潜在图像表示,通过CLIP的文本编码器将输入的文本提示转换为大小为77×768的文本嵌入。
然后,使用U-Net 在以文本嵌入为条件的同时迭代地对随机潜在图像表示进行去噪。 U-Net 的输出是噪声的残差,用于通过scheduler 程序算法计算去噪的潜在图像表示。 scheduler 算法根据先前的噪声表示和预测的噪声残差计算预测的去噪图像表示。
许多不同的scheduler 算法可以用于这个计算,每一个都有它的优点和缺点。对于Stable Diffusion,建议使用以下其中之一:
-
PNDM scheduler (默认)
-
DDIM scheduler
-
K-LMS scheduler
去噪过程重复约50次,这样可以逐步检索更好的潜在图像表示。一旦完成,潜在图像表示就会由变分自编码器的解码器部分进行解码。

LDM 效果




Stable diffusion 模型介绍
Stable diffusion是一个基于Latent Diffusion Models(潜在扩散模型,LDMs)的文图生成(text-to-image)模型,使用了 Classifier-Free Diffusion Guidance 分类器。
具得益于Stability AI的计算资源支持和LAION的数据资源支持,Stable Diffusion在LAION-5B的一个子集中对512x512的图像训练,得到了一个Latent Diffusion Models。与谷歌的Imagen类似,该模型使用冻结的CLIP vitl /14文本编码器对文本提示条件模型。该型号具有860M的UNet和123M的文本编码器,相对较小,可以运行在至少10GB VRAM的GPU上。
模型参数
seed
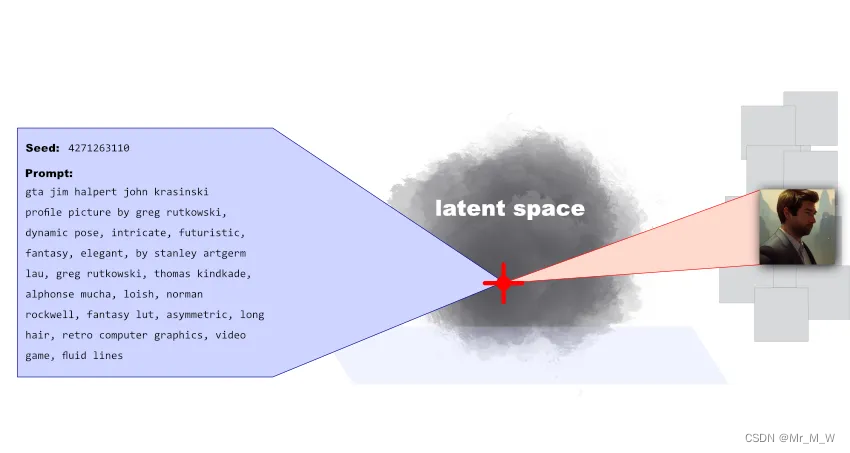
Stable Diffusion 每次生成图片,模型会同时生成一个 Seed 编码,Seed 就像是在可能性空间中的锚点一样,表达了用户 Prompts 的合成结果,将结果锚定一个特定的可能性空间 Latent Space。
Seed 与 Prompts 组合以及一致的参数就可以还原生成一致的图像,通过https://lexica.art/平台可以看到AI图像背后 Seed 与 Prompts 的组合。
Seed + Prompts 从另外一个角度甚至可以理解为是一种压缩方式,Seed 和自然语言文本,任何人在任何地方通过模型都可以解压缩(生成)特定的内容:自然语言变成了一种压缩比极高的代码。
Prompt
Prompts 提示词理解非常类似于搜索 Queries 关键词,给予模型 Prompts 提示词(给于搜索引擎关键词),返回生成结果(返回搜索结果);通过调整提示词可以优化生成结果,设置生成参数相当于设定搜索条件;每一次提示词录入和图片输出的过程,都是一次模型训练。
与搜索引擎不同在于,搜索是通过索引所有已经存在的数据,在一个有限数据集合中检索并给予已经存在的相关数据,而图像生成模型是在与Prompts 提示词描述的可能性空间 Latent Space 中生成新的数据(或输出已经训练过的数据)
Stable diffusion 初步实践
Stable diffusion使用思路:Midjourney + Runway 的技术路线
使用基础的底层大模型,然后做产品侧的特征优化,提供差异化的生成能力和workflow的整体使用,更加细致的功能,提供英文转中文,或者中文语境下的图片
原生Stable diffusion 模型的使用,使用gpu 服务器进行推理任务
GPU服务器:GPU芯片的阶梯分布 K80, T4, V100, A100,N卡
开源的仓库和模型
CompVis/latent-diffusion
latent-diffusion 原始论文的提供的仓库,https://github.com/CompVis/latent-diffusion
CompVis/stable-diffusion
CompVis 是论文作者官方的github 库,提供了原始的模型和算法
hggingface/diffusers
这是社区使用SD 模型进行了整合
runwayml/stable-diffusion
Runway 公司提供的仓库
AWS GPU 服务器
P4 实例
A100 GPU ,算力最强,费用最贵,可用于模型训练
配置:

价格:32.7 USD/小时

P3 实例
V100 GPU ,算力校强,费用比较贵,可用于模型训练,推理,
多个配置可选:
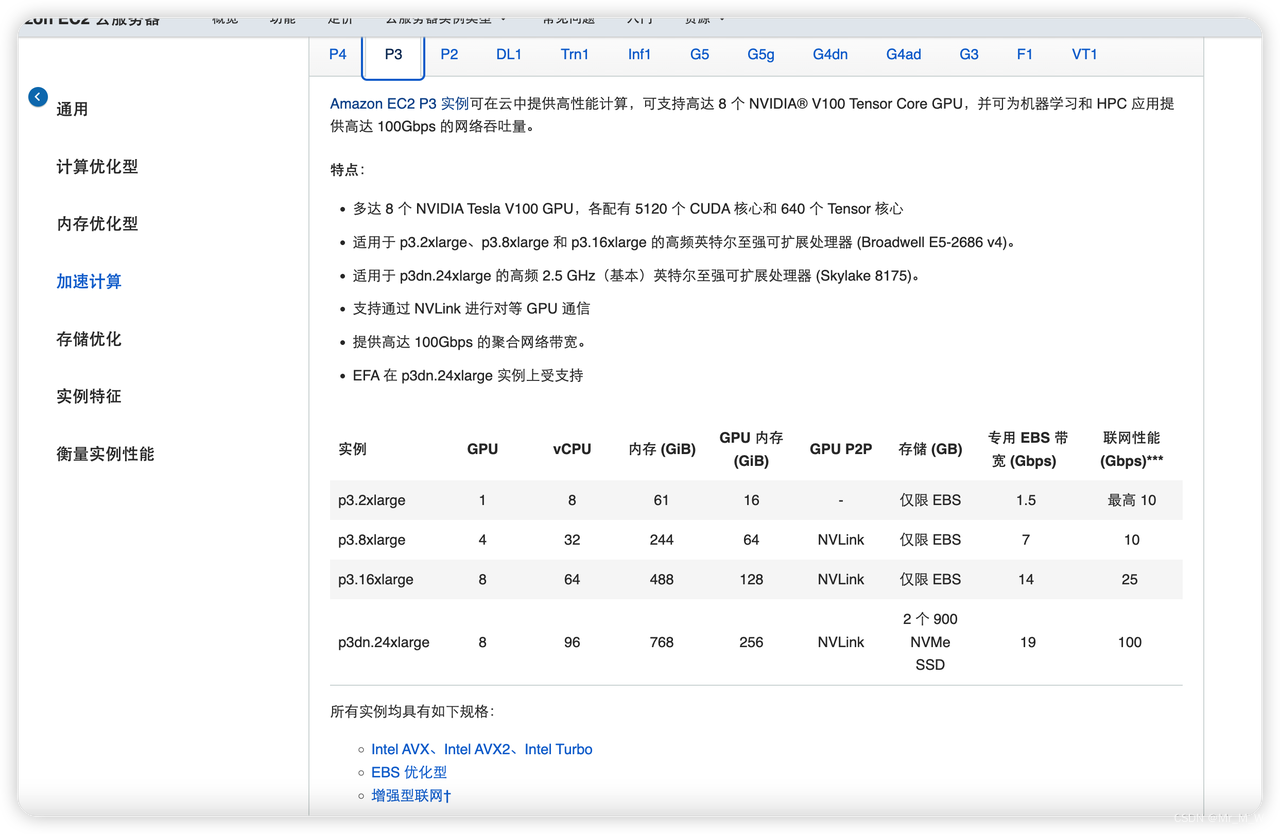
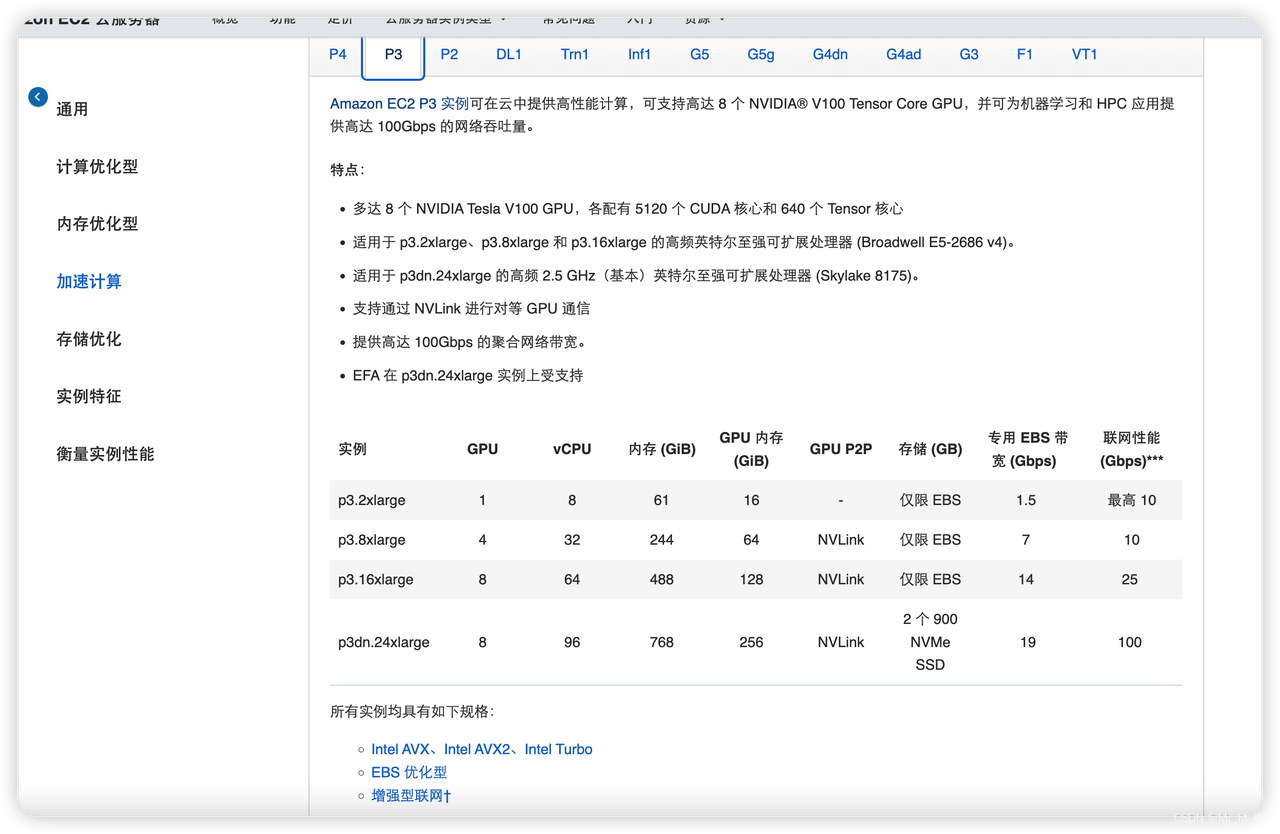
价格:3-31 USD/小时

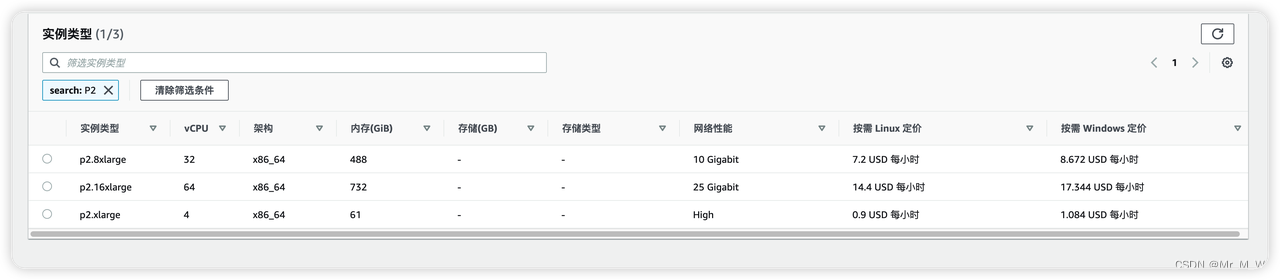
P2 实例
K80 GPU ,算力中等,费用比较便宜,可用于模型训练,推理
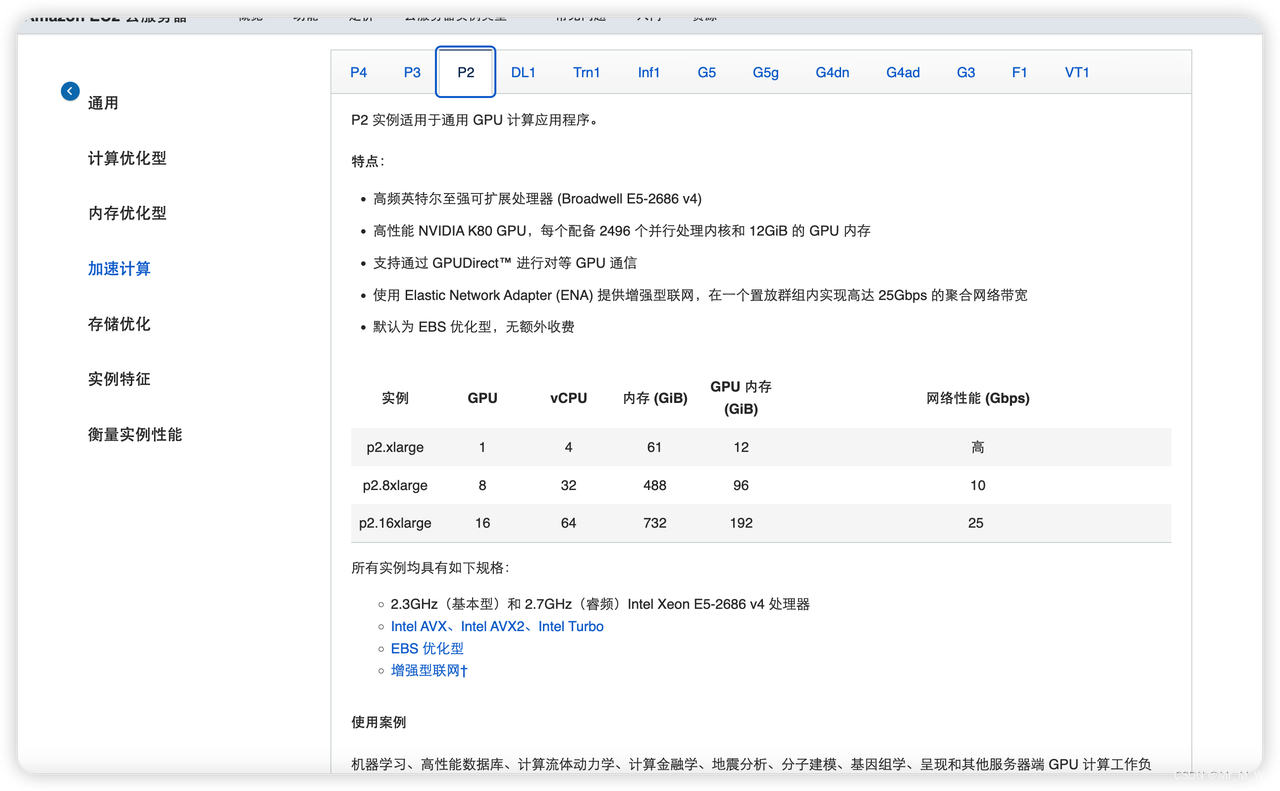
价格:0.9-7.2 USD/小时
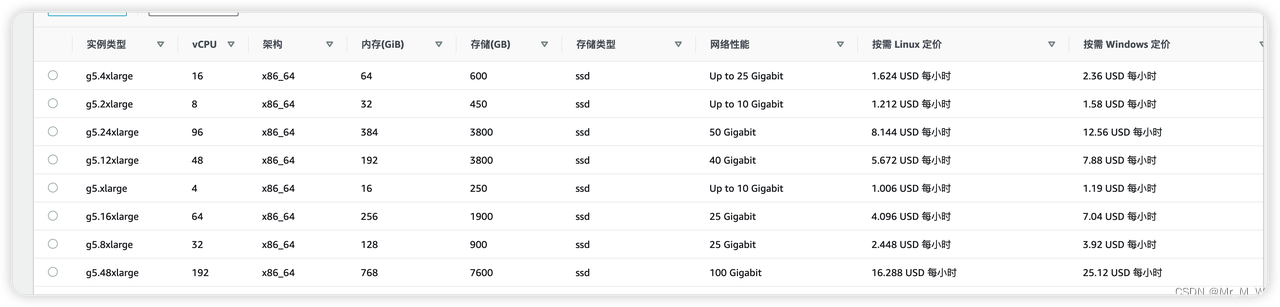
G5 实例
A10G GPU ,算力中等,费用比较便宜,可用于模型训练,推理
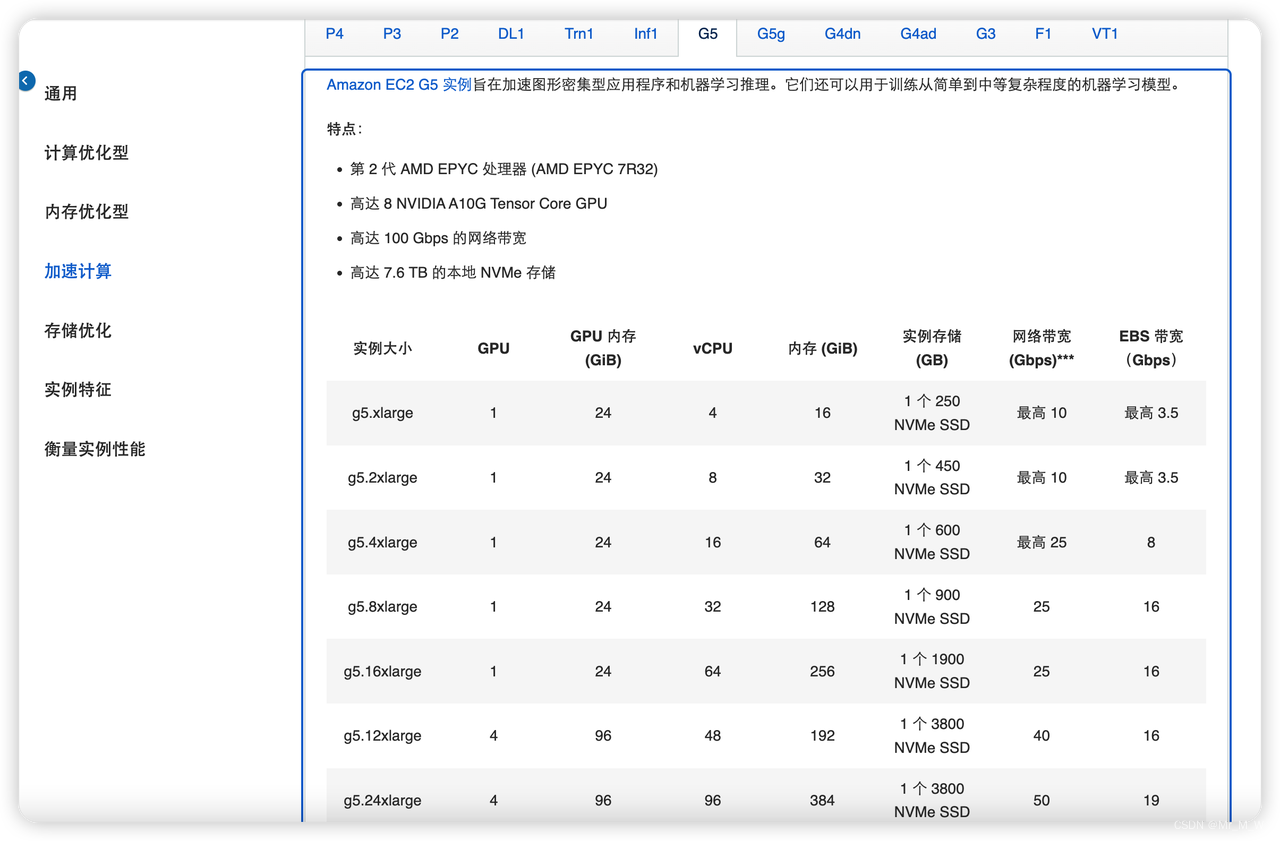
价格:1.6-16.2 USD/小时
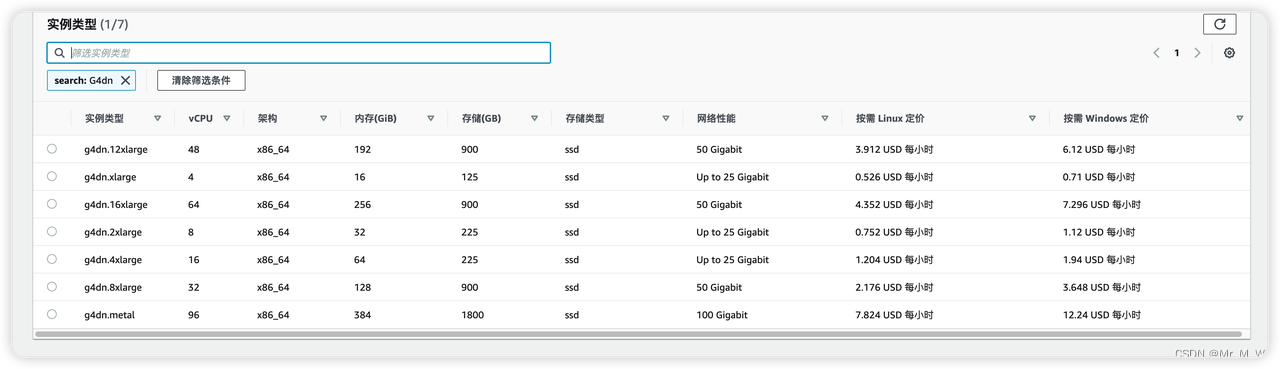
G4dn 实例
T4 GPU ,算力中等,费用比较便宜,可用于模型训练,推理
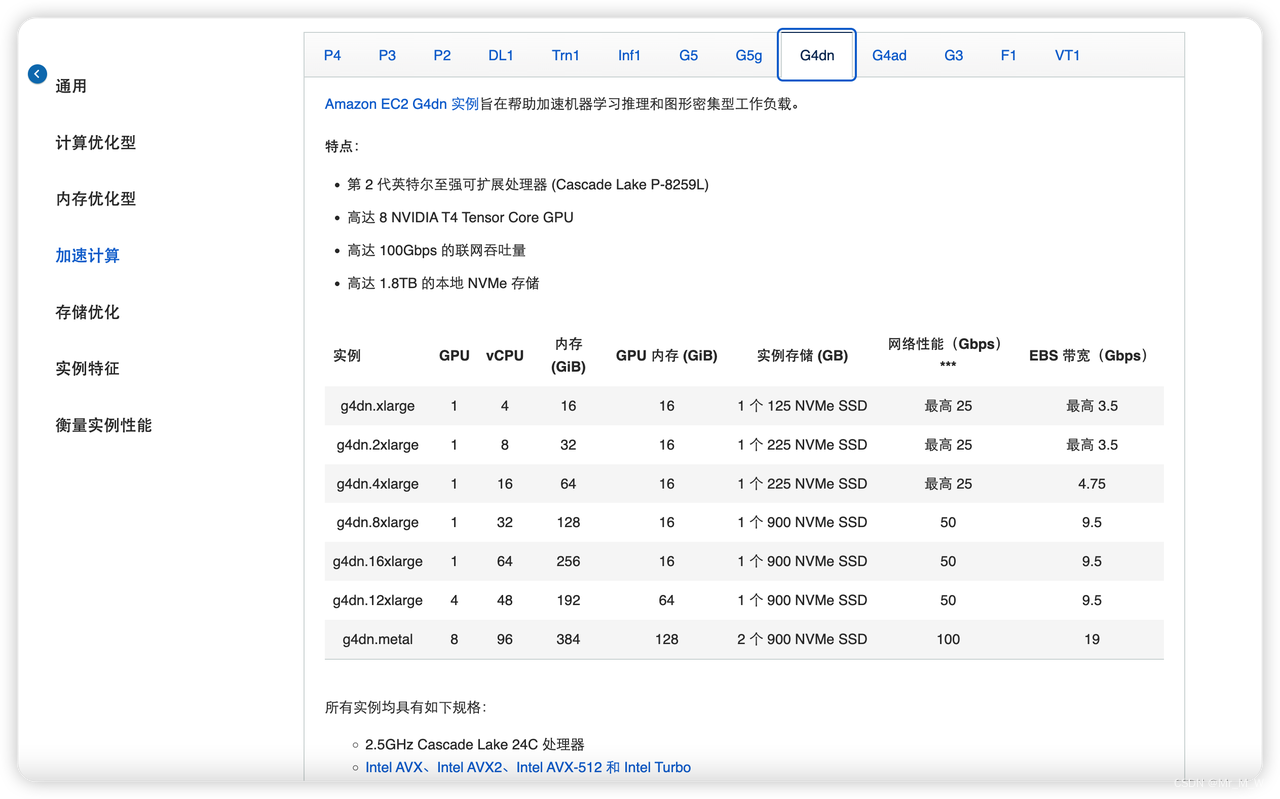
价格:0.5-7.8 USD/小时
推理测试
AWS P3 实例 V100 GPU 16G 显存, huggfaceing/diffusers 仓库
文字生成图片
-
单张图片
-
半精度:


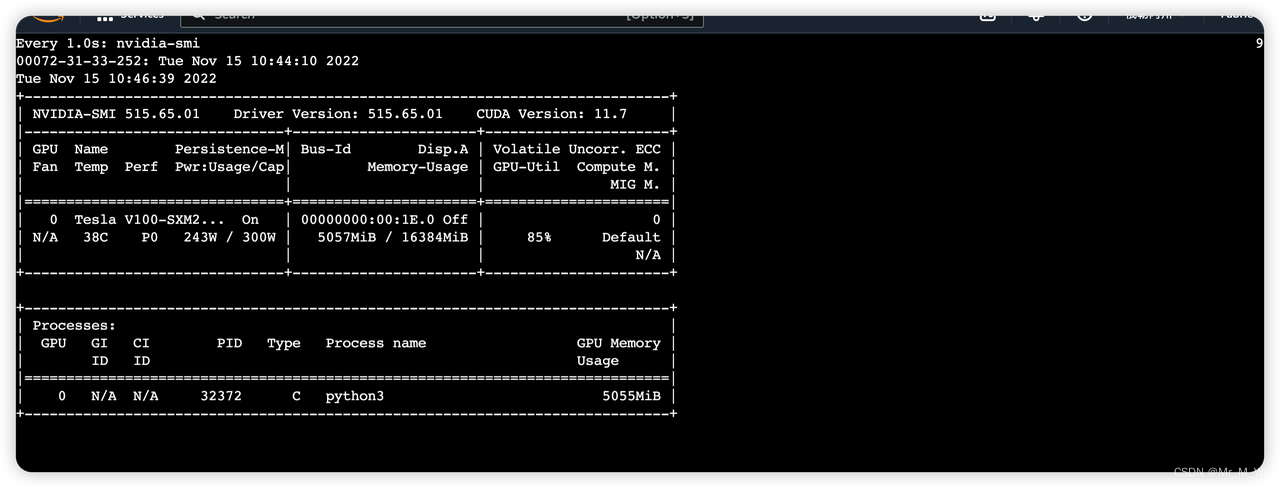
同时运行两个任务时,报错:
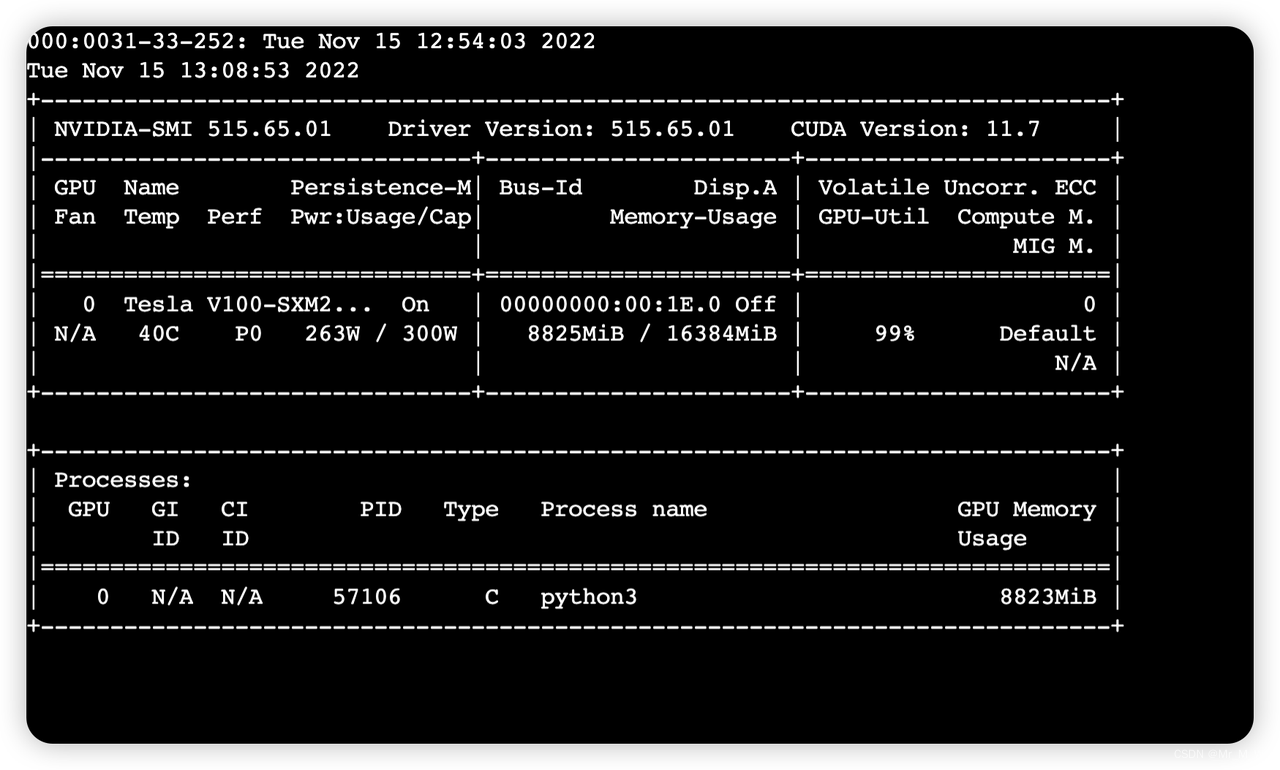

-
全精度:


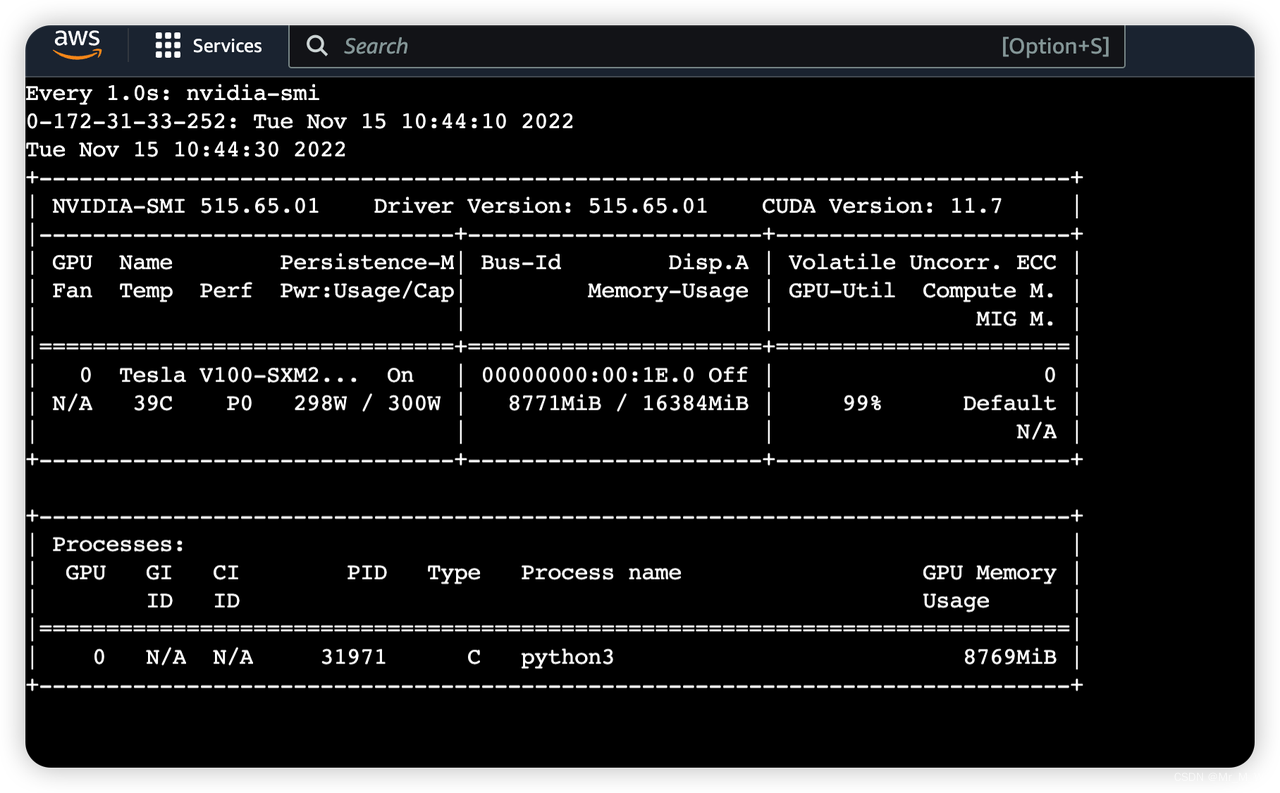
多张图片
5张图片,fp16 精度

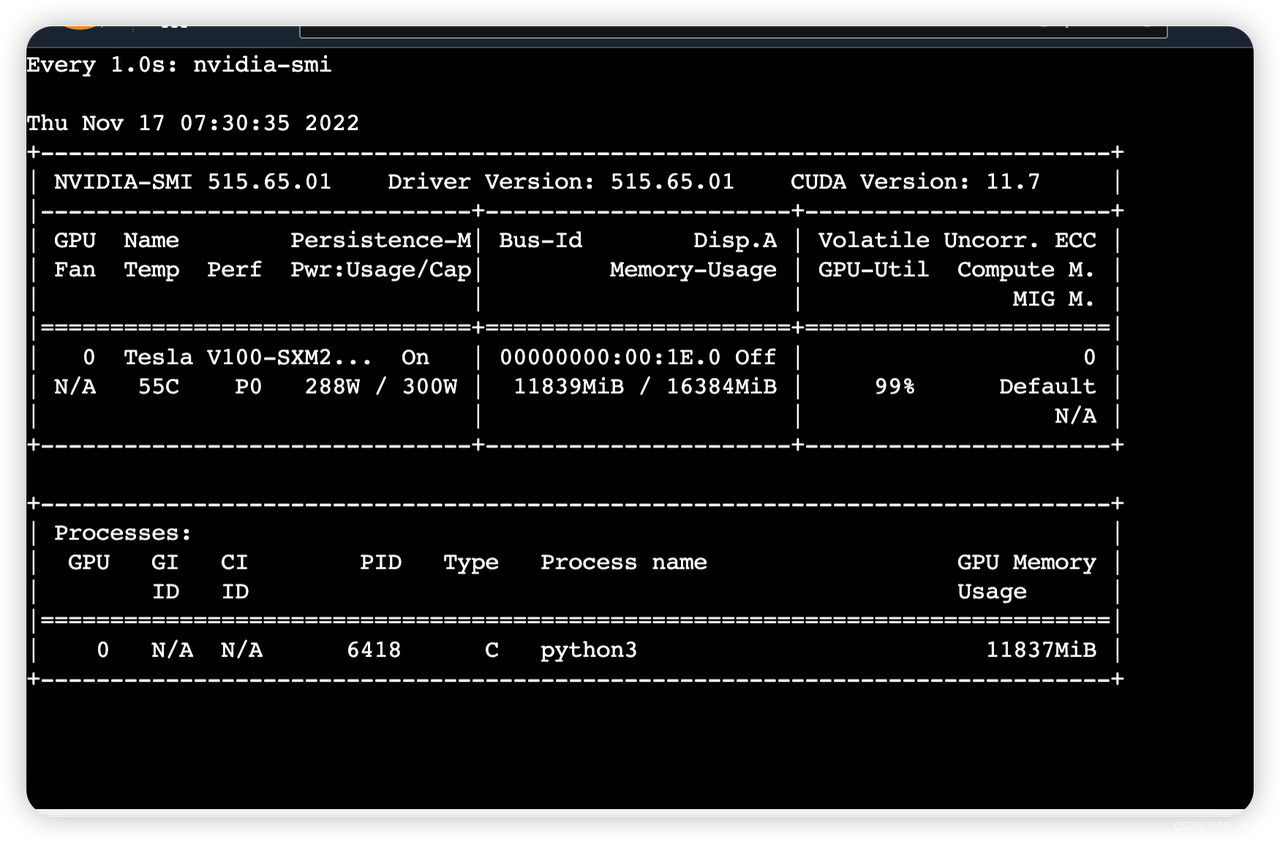
增加生成张数,8张会导致 CUDA OOM

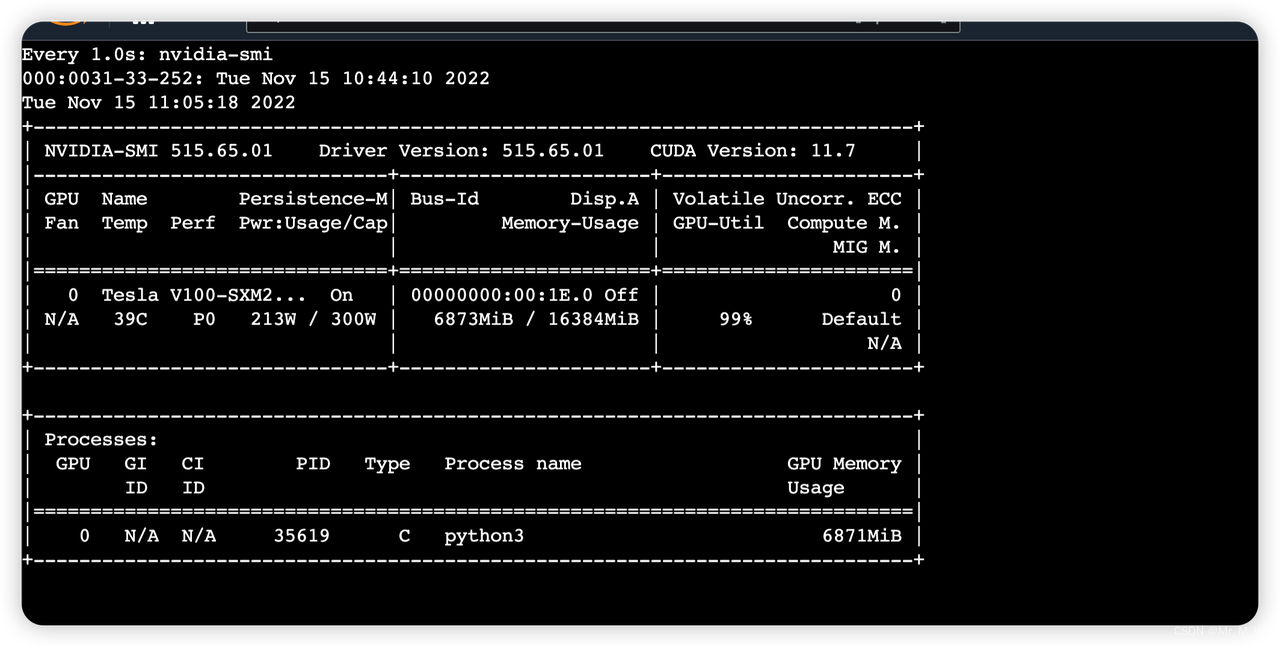
文字与初始图片生成图片

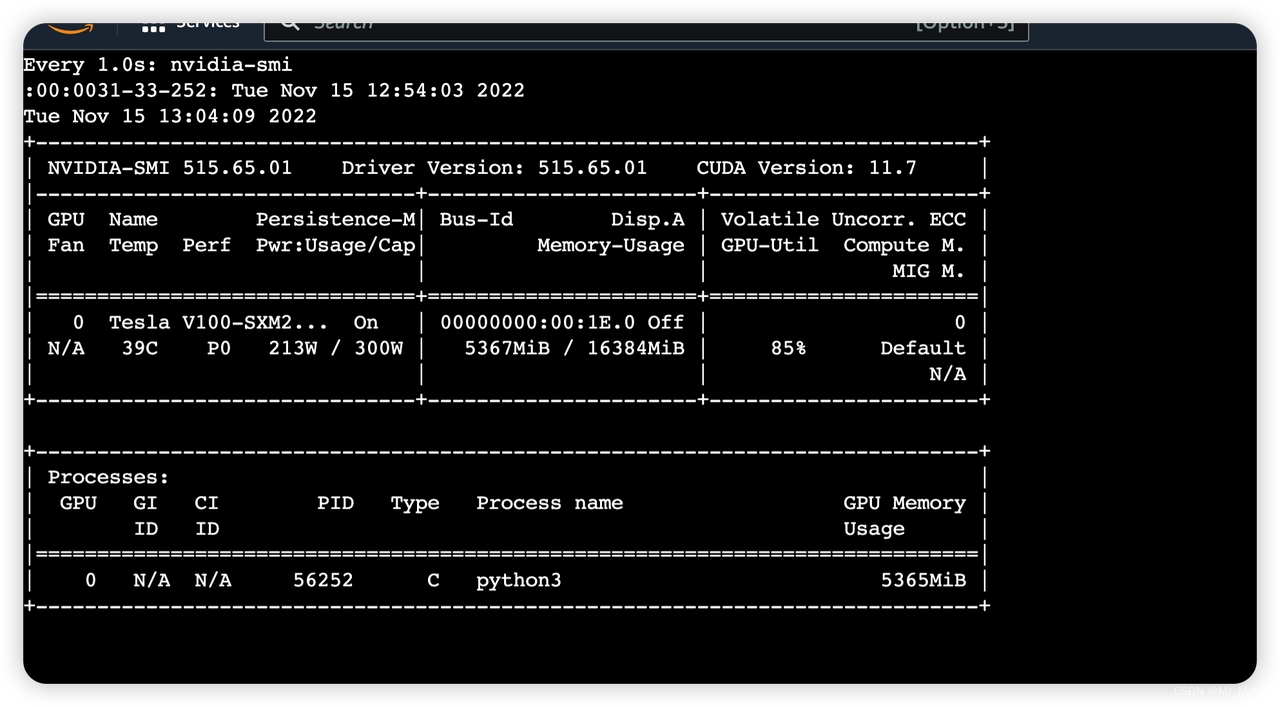
Inpainting 图像

模型微调
Lambda Labs 的机器学习研究员 Justin Pinkney 训练的Pokeman 风格图像
硬件:使用Lambda GPU Cloud上的2xA6000 GPU,运行训练大约15,000个步骤,大约需要6个小时,成本约为10美元。
数据集:神奇宝贝数据集
关键点: Stable Diffusion 在训练期间保持模型的指数移动平均 (EMA) 版本,通常用于推理。使用EMA实际上是在使用原始模型和微调模型的平均值。事实证明,这对于生成神奇宝贝而言是必不可少的。此外,你还可以通过直接将新模型与初始模型的权重进行平均来微调效果,以控制生成神奇宝贝的数量。微调和对模型进行平均的操作可以将原始内容与微调后的风格有效混合。

Promot: Girl with a pearl earring, Cute Obama creature, Donald Trump, Boris Johnson, Totoro, Hello Kitty
SD 的原理与进阶应用
SD 模型系列的发展和不同场景模型训练与应用后续会继续更新文章来介绍

