
- 1Distilling the Knowledge in a Neural Network 论文笔记_generalist model论文
- 2【产业互联网周报】多家国产芯片设计公司获得亿级融资;中芯国际首发过会;中兴通讯澄清“7nm芯片规模量产”:系误读...
- 3MySQL简单安装(无需配置环境)_不需要安装配置的数据库
- 4Gitea搭建
- 5群晖搭建网页版Linux Ubuntu系统并实现远程访问_怎么通过网页访问ubutun
- 6Weibo-Analyst:微博数据分析利器
- 7关于FPGA的三种电源需求浅析_fpga芯片能用于控制电源吗
- 8技术解密Java Chassis 3超实用的可观测性
- 92分钟教你如何产生1Hz频率,你还有更好的方法吗_4060分频产生1hz
- 10Deep learning + SLAM小综述_deep-learn-slam可以有效解决场景退化问题吗?
音频信号处理-基于麦克风阵列的声源定位算法之GCC-PHAT
赞
踩
目前基于麦克风阵列的声源定位方法大致可以分为三类:
基于最大输出功率的可控波束形成技术
基于高分辨率谱图估计技术和基于声音时间差(time-delay estimation,TDE)。
基于TDE的算法核心在于对传播时延的准确估计,一般通过对麦克风间信号做互相关处理得到。进一步获得声源位置信息,可以通过简单的延时求和、几何计算或是直接利用互相关结果进行可控功率响应搜索等方法。这类算法实现相对简单,运算量小,便于实时处理,因此在实际中运用最广。
GCC-PHAT
基于广义互相关函数的时延估计算法引入了一个加权函数,对互功率谱密度进行调整,从而优化时延估计的性能。根据加权函数的不同,广义互相关函数有多种不同的变形,其中广义互相关-相位变换方法(Generalized Cross Correlation PHAse Transformation,GCC-PHAT)方法应用最为广泛。GCC-PHAT方法本身具有一定的抗噪声和抗混响能力,但是在信噪比降低和混响增强时,该算法性能急剧下降。
研究表明麦克风对的GCC-PHAT函数的最大值越大则该对麦克风的接收信号越可靠,也就是接收信号质量越高。
1、计算传播时延
广义互相关函数时延估计算法根据两个麦克风信号的互相关函数峰值来估计时延值。在声源定位系统中,麦克风阵列的每个阵元接收到的目标信号都来自于同一个声源。因此,各通道信号之间具有较强的相关性。理想情况下,通过计算每两路信号之间的相关函数,就可以确定两个麦克风观测信号之间的时延。
阵列中两个麦克风的接收信号为:
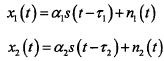
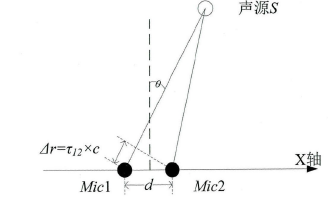
其中s(t)为声源信号,n1(t)和n2(t)为环境噪声,τ1和τ2是信号从声源处传播到两个麦克风阵元的传播时间。相关参数可参见下图:
互相关算法经常被用来做时延估计,表示为:
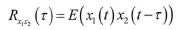
代入信号模型,则有:
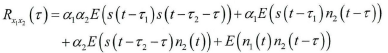
此时因为s(t)和n1(t)互不相关,上式可以简化为:

其中τ12=τ1-τ2,假设n1和n2是互不相关的高斯白噪声,则上式可以进一步简化为:
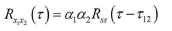
由相关函数的性质可知,当τ12=τ1-τ2时,Rx1x2(τ)取最大值,是两个麦克风之间的时延。
互相关函数和互功率谱的关系:
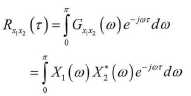
在麦克风阵列信号处理实际模型中,由于存在混响和噪声影响,导致Rx1x2(τ)的峰值不明显,降低了时延估计的精度。为了锐化Rx1x2(τ)的峰值,可以根据信号和噪声的先验知识,在频域内对互功率谱进行加权,从而能抑制噪声和混响干扰。最后进行傅里叶逆变换,得到广义互相关函数Rx1x2(τ):
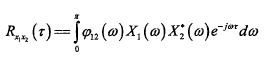
其中φ12(w)表示频域加权函数。广义互相关时延估计算法框图如下:
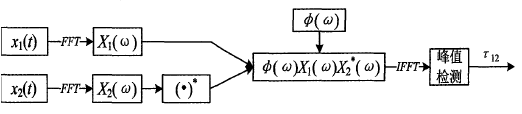
2、常用加权函数及其特点
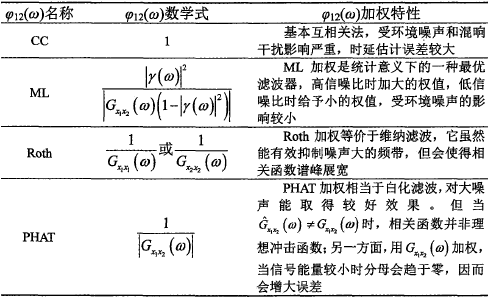
相位变换加权函数的表达式为:
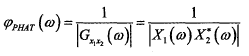
由上式可知,相位变换加权函数实质上是一个白化滤波器,使得信号间的互功率谱更加平滑,从而锐化广义互相关函数。经过PHAT加权之后,Rx1x2(τ)广义互相关函数的表达式为:
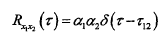
可以看出,经过PHAT加权的互功率谱近似于单位冲激响应的表达式,突出了时延的峰值,能够有效抑制混响噪声,提高时延估计的精度和准确度。
3、互相关函数
x(n)和y(n)的互相关函数是将x(n)保持不动, y(n)左移m个样本点,两个序列逐个相乘的结果,顺序不能互换。但是,按照时域卷积的方式求互相关函数的方法计算复杂度较大,所以将在频域进行操作(FFT和IFFT),即线性卷积的FFT算法。
两个信号的互相关函数的频域等于x信号频域的共轭乘以Y信号的频域。
4、近场和远场
需要说明的是,GCC-PHAT算法是用在近场模型下的。
当声源足够远时,麦克风阵列的直径与声源距离相比可忽略,此时一般采用远场模型。远场模型认为声源位于无穷远处,麦克风接收到的声波为平面波,此时我们仅考虑声波的入射方向,而不考虑声源相对于麦克风阵列的的距离。
当声源的距离较近时,我们需要考虑声源相对于麦克风阵列中的距离,此时远场模型里不再适用,应当采用近场模型。近场模型认为麦克风接收到的声波为球面波。近场模型更符合实际应用情况,能提供更多的声源位置信息,提高定位的精度。
通常,判断近场和远场的经验公式为:

其中d为麦克风阵列的直径,λ为目标信号的波长,r为麦克风阵列和声源之间距离。
在实际的近场模型应用中,麦克风阵列所接收到的信号主要包括3部分;声源直达信号、经过墙壁或障碍物的反射信号以及环境噪声信号。
声波的波长:0.017--17米。 波长=波速/频率,波速一般是340米/秒;,人耳听到的声音的频率是20HZ--20KHZ,所以得出人耳听到的声音的波长:0.017--17米。
0.18*0.18*2/0.017 =3.8m
SRP-PHAT
SRP-PHAT(Steered Response Power - Phase Transform) 基于相位变换加权的可控响应功率的声源定位算法。
基于麦克风阵列的声源定位方法很多,相位变换加权的可控响应功率SRP-PHAT声源定位算法在混响环境中有较强的鲁棒性,可实现真实环境中的声源定位,因此该算法得到了广泛应用。SRP-PHAT对阵型没有特定要求,因此也适用于分布式阵列,事实上很多基于分布式阵列的定位系统采用了该算法。
SRP-PHAT算法的基本原理是在假想声源位置计算所有麦克风对接收信号的相位变换加权的广义互相关GCC-PHAT函数之和,在整个声源空间寻找使SRP值最大的点即为声源位置估计。SRP-PHAT对混响有较强的鲁棒性,但是在低信噪比SNR(Signal-to-NoiseRatio)环境中其定位性能较差。
SRP-PHAT算法的计算流程如下:

其中, Q 为预先设定的搜索空间。
SRP-PHAT法是一种对窄带和宽带信号均可适用的有效方法, 得到了广泛研究和应用。但是由于其全局搜索算法运算量较大,限制了该方法的实时性。
扩展
GCC时延估计中,信号x1和x2都采用理想模型,并没有过多考虑混响噪声,所以当混响较强时,GCC时延估计算法效果较差。而自适应最小均方算法采用麦克风信号的实际模型,通过自适应滤波产生h1(n)和h2(n),再从h1(n)和h2(n)中估计时延,可以有效抑制混响的影响。
实际模型中,第i个麦克风接收的信号xi(t)可以表示为:
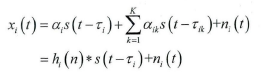
其中aik表示第k条反射路径到达第i个麦克风的能量衰减,τik表示对应的时延。*表示信号卷积,hi(t)称之为房间单位冲激响应函数,从数学角度反映了房间互相的物理特性。麦克风阵列信号的实际模型见下图:
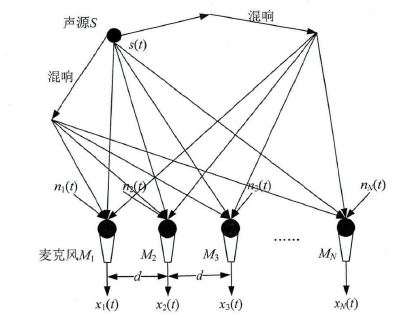
如图所示,实际模型中,麦克风接收信号不仅包括声源的直达信号和环境噪声,还包括语音信号在墙壁以及房间的其他物体之间重复反射再到达麦克风的信号,我们称之为混响。
更多地,麦克风阵列信号的理想模型参见下图:
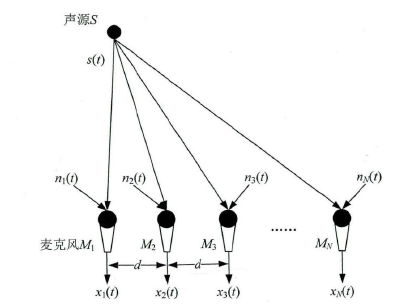
如上图所示,在理想模型中,假设麦克风阵列的所有阵元接收到的语音信号只包含直达信号与噪声信号,噪声信号为环境噪声(高斯白噪声),并且每个麦克风之间的噪声相互独立。
- p=p->next;}cout
[详细] -->赞
踩

