
- 1vue 页面导出excel表格,提示excel文件损坏_axios.post下载excel 文件会损坏
- 2【ComfyUI插件】ComfyUI核心节点(一)_comfyui节点列表
- 3Ubuntu20.04安装ROS2遇到的问题以及解决_e: unable to locate package ros-foxy-desktop
- 4解决Office账号的Authenticator验证问题_手机解除微软authenticator
- 5测试用例的书写方式及测试模板大全_测试工具写法
- 6qt实现视频播放器_qt播放视频
- 7如何用WordPress 搭建一个内容管理系统?_wordpress搭建信息管理平台
- 8项目实训- 基于unity的2D多人乱斗闯关游戏设计与开发(七2、酷跑——地面)_unity2d如何做地面
- 9C++ | Leetcode C++题解之第40题组合总和II
- 10stm32之GP2Y1014AU使用_stm32gp2y1014
Flink——最流批的大数据框架(流批一体)
赞
踩
Apache Flink基础教程
资料来源:Apache Flink Tutorial (tutorialspoint.com)

Apache Flink是Apache Hadoop的开源本地分析数据库。它由Cloudera、MapR、Oracle和Amazon等供应商提供。本教程中提供的示例是使用Cloudera Apache Flink开发的。
本教程是为那些想要学习Apache Flink的人准备的。Apache Flink使用传统的SQL知识以闪电般(松鼠般doge)的速度处理大量数据。
1. Flink-前置知识
1.1 大数据平台
学习Flink之前,先来点前置知识
在过去的10年里,数据的进步是巨大的;这就产生了一个术语“大数据”。可以称之为大数据的没有固定大小;传统系统(RDBMS)无法处理的任何数据都是大数据。这些大数据可以是结构化、半结构化或非结构化的格式。最初,数据有三个维度:体量(Volume) 、速度(Velocity)、种类(Variety)。现在,维度已经超过了三个“V”.我们现在添加了其他的V -真实性(Veracity),有效性(Validity),脆弱性(Vulnerability),价值(Value),可变性(Variability)等。
大数据导致了多种工具和框架的出现,这些工具和框架有助于存储和处理数据。目前流行的大数据框架有Hadoop、Spark、Hive、Pig、Storm和Zookeeper等。它还提供了在医疗保健、金融、零售、电子商务等多个领域创建下一代产品的机会。
无论是跨国公司还是初创企业,每个人都在利用大数据来存储和处理数据,并做出更明智的决策。
1.2 批处理vs实时处理
在大数据而言,有两种类型的处理:
- (批处理)Batch Processing
- (实时处理)Real-time Processing
处理基于一段时间内收集的数据称为批处理。例如,银行经理希望处理过去一个月的数据(随时间收集),以了解过去一个月被取消的支票数量。
处理基于即时数据的即时结果称为实时处理。例如,银行经理在发生欺诈交易(即时结果)后立即收到欺诈警报。
下表列出了批处理和实时处理的区别:
| 批处理(Batch Processing) | 实时处理(Real-Time Processing) |
|---|---|
| 静态文件 | 事件流 |
| 按分钟、小时、天等周期处理。 | 纳秒级,及时处理 |
| 存在磁盘上的历史数据 | 内存存储 |
| 例子−票据生成 | 例子−ATM事务警报 |
如今,实时处理在每个组织(泛指各种公司、政府部门等机构)中都得到了广泛的应用。欺诈检测、医疗保健中的实时警报和网络攻击警报等用例需要实时处理即时数据;即使是几毫秒的延迟也会产生巨大的影响。
对于这种实时用例,理想的工具应该是能够以流而不是批处理的方式输入数据的工具。Apache Flink就是实时处理工具。
1.3 Flink 简介
Apache Flink是一个实时处理框架,可以处理流数据。它是一个开源流处理框架,用于高性能、可扩展和精确的实时应用程序。它具有真正的流模型。
tips: flink最初是为实时处理设计的,但现在是流批一体(从 Apache Flink 1.12.0 开始),就问你流不流批
Apache Flink是由Data Artisans公司创建的,现在由Apache Flink社区在Apache许可下开发。到目前为止,这个社区有超过479个贡献者和15500多个提交。
Apache Flink的生态系统
下图显示了Apache Flink生态系统的不同层:
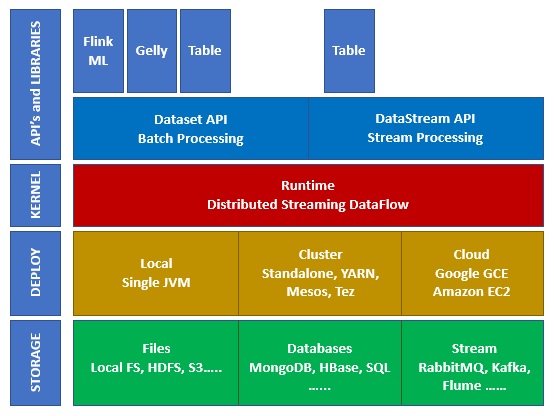
下面,将从该图的从下往上,分别简要介绍STORAGE、DEPLOY、KERNEL、API’s and LIBRARIES
Storage(存储)
Apache Flink有多种读/写数据的选项。下面是一个基本存储列表−
- HDFS (Hadoop Distributed File System)
- 本地文件系统(Local File System)
- S3
- 关系型数据库:RDBMS (MySQL, Oracle, MS SQL etc.)
- MongoDB
- HBase
- Apache Kafka
- Apache Flume
Deploy(部署)
您可以在本地模式、集群模式或云上部署Apache Fink。集群模式包括:standalone、YARN、MESOS。
在云端,Flink可以部署在AWS或GCP上(都是云服务器)。
Kernel(内核)
这是运行时层,它提供分布式处理、容错、可靠性、本地迭代处理能力等等。
APIs & Libraries(api和库)
这是Apache Flink的顶层,也是最重要的一层。它有数据集API,负责批处理;和数据流API,负责流处理。还有其他库,如Flink ML(用于机器学习),Gelly(用于图形处理),Tables for SQL。这一层为Apache Flink提供了多种功能。
未完待续,点个赞呗

