
热门标签
热门文章
- 1android jni Log
- 2基于neo4j的机械设备知识图谱问答展示系统_给电机及拖动基础知识问答网页系统(用python、neo4j做的)画一个主程序流程图和子
- 3我的保研之旅——北京航空航天大学、北理工、南大_北航美赛s加分不
- 4c++ string类构造函数(string变量与字符相结合)_c++如何把一个字符串和一个string变量连接
- 5mysql redis双写_Redis Mysql 双写一致性问题
- 6【数据库】SQL Server 数据库、附加数据库时出错。有关详细信息,请单击“消息”列中的超链接_附加数据库时出错,请单击消息中的超链接
- 7Redis的SCAN命令_setscan
- 8yolov5+Deepsort目标检测加目标跟踪算法(yolo版本更改为6.1版本)_yolov5 6.1 deepsort
- 9Spire.Presentation[PPT/PPTX] 8.1.2 for Java Crack_spire.presentation需要安装office吗
- 10排序算法-选择排序_筛选法调整堆
当前位置: article > 正文
2.Spark的工作与架构原理_简述spark运行架构和原理
作者:小惠珠哦 | 2024-06-30 10:28:15
赞
踩
简述spark运行架构和原理
概述
目标:
- spark的工作原理
- spark数据处理通用流程
- rdd
- 什么是
rdd rdd的特点
- 什么是
- spark架构
- spark架构相关进程
- spark架构原理
spark的工作原理
spark 的工作原理,如下图
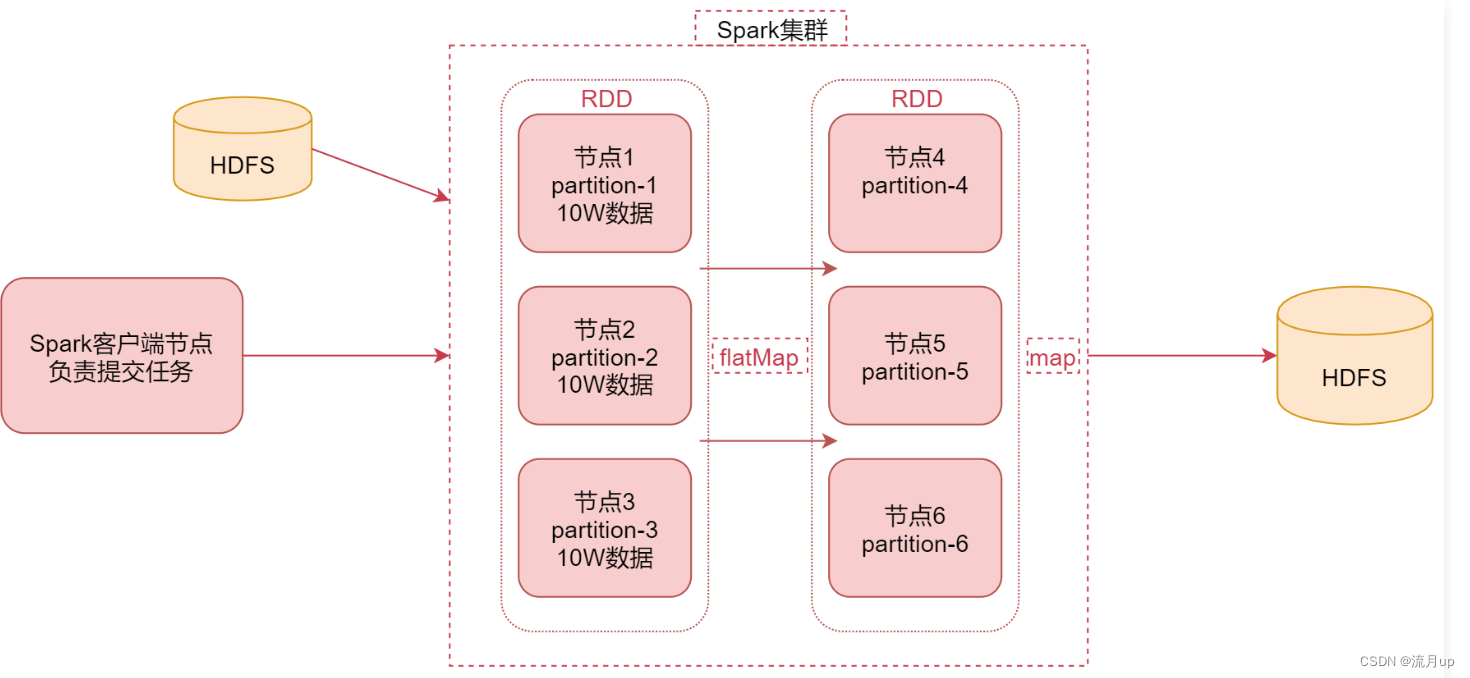
- 图中中间部分是
spark集群,也可以是基于yarn的,图上可以理解为spark的standalone集群,集群中有6个节点 - 左边是
spark的客户端节点,这个节点主要的任务是向spark集群提交任务, - 左边的
hdfs是提交的任务所需要的数据源,当spark读取hdfs中的数据后,会将数据转化为rdd,rdd是弹性分布式数据集,是一个逻辑概念,在此,可以先理解为一个数据集合就可,这个rdd是具有分区特性的,如节点1,节点2,节点3,这样可以轻易的提高数据的并发处理能力 - 接下来就可以对这
rdd数据进行处理了,图中使用了,flatMap函数,计算之后的结果还是一个带有分区的rdd,就是在节点4,节点5,节点6 - 当处理到最后一步的时候是需要将数据存起来的,实际工作中,针对离线计算的,大部分的结果数据都是存储在
hdfs上的,也可以存储在其它的存储介质中。
针对上面几条,可以总结出,spark处理数据的基本构成,如下图

后面
spark代码中基本都是这三板斧,可以参考 单词统计编程的代码
rdd
rdd 是 spark 中一个很重要的概念
什么是rdd
在实际工作中,rdd 通常通过 hadoop 上的文件,即 hdfs 文件进行创建,也可以通过程序中的集合来创建,rdd是 spark 提供的核心抽象,全称为 Resillient Distributed Dataset ,即弹性分布式数据集
rdd 的特点
- 弹性:
rdd数据默认情况下是存储在内存中,但是在内存资源不足时,spark也会自动将rdd数据写入磁盘 - 分布式:
rdd在抽象上来说是一种元素集合,它是被分区的,每个分区分布在集群中的不同节点上,从而让rdd中的数据可以被并行操作 - 容错性:
rdd最重要的特性就是提供了容错性,可以自动从节点失败中恢复过来,如果某个节点上的rdd分区,因为节点故障了,导致数据丢了,那么rdd会自动通过自己的数据来源重新计算该分区的数据
spark架构
下面熟悉一下 spark 架构相关的进程信息
注意: 在此是以 spark 的 standalone 集群为例进行分析,其实在 spark standalone环境安装 中,成功后有查询对应的 进程 是否成功启动了
spark架构相关进程
- driver:编写的
spark程序就在driver(进程)上,由driver进程负责执行,driver进程所在的节点可以是spark集群的某一个节点,或者就是提交任务的客户端节点,具体driver进程在哪个节点上启动,是由提交任务时指定的参数决定的 - master:集群的主节点中启动的进程,主要负责集群资源管理和分配,还有集群的监控等。
- worker:集群的从节点中启动的进程,主要负责启动其它进程来执行具体的数据处理和计算任务
- executor:此进程由
worker负责启动,主要为了执行数据处理和计算 - taks:是一个线程,由
executor负责启动,是真正干活的
spark架构原理
如下图来看一spark的架构原理
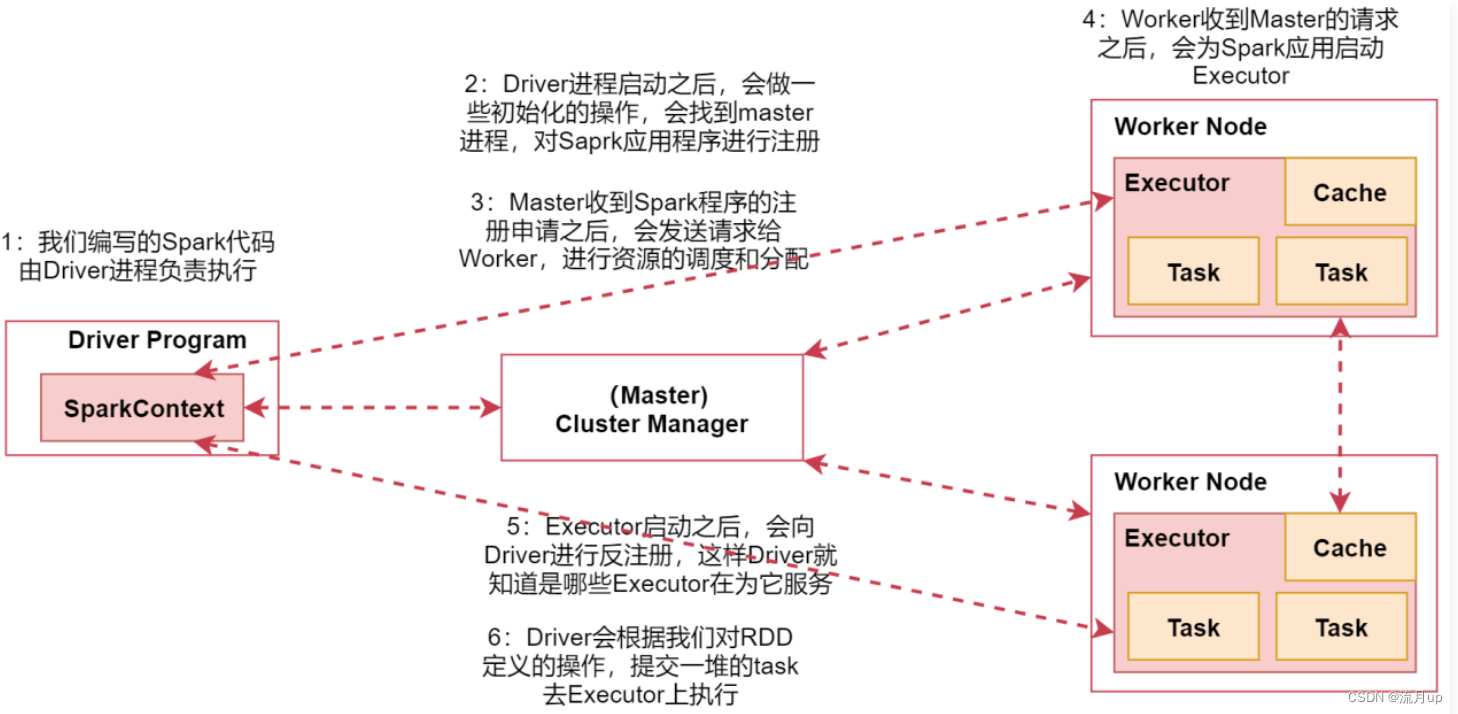
- 在
spark的客户端机器上通过driver进程执行的spark代码,通过spark-submit脚本提交spark任务的时候driver进程就启动了。 driver启动之后,会做一些初始化操作,并找到集群的master进程,对spark程序进行注册- 当
master收到spark程序注册成功之后,会向worker节点发送请求,进行资源调试和分配 worker收到master请求后,为任务启动executor进程,启动多少个,会根据配置来启动executor启动之后会向driver进行注册,这样driver就能知道哪些executor在为它服务了driver会根据对rdd定义的操作,提交一堆的task(map,flatMap等) 去executor上执行
结束
spark 的工作与架构原理就介绍至此,如有问题,欢迎评论区留言。
声明:本文内容由网友自发贡献,转载请注明出处:【wpsshop博客】
推荐阅读
相关标签

