
- 1kafka监控配置和告警配置——筑梦之路_kafka-exporter error.go:210
- 2搭建基于Django的博客系统数据库迁移从Sqlite3到MySQL(四)_django服务器部署sqlite
- 3springboot 实现机器学习_「机器学习」自动调参器设计实现
- 4C# WPF入门学习主线篇(十九)—— 布局管理实战『混合布局案例』
- 5订阅切换按钮(subscribe toggle button)_yf54gyaqe9iisbp+ltamgzcoa5mgkvjhsrdgshfsfz3f0nptrk
- 6轻松使用 Debian的Linux_debian linux
- 7【深度学习】Ubuntu18.04安装NVIDIA GTX960M驱动_nvidiagtx960m显卡驱动
- 8Spring Cloud —— 消息队列与 RocketMQ_springcloud rocketmq
- 9图形矩阵变换(2D篇)_在2d齐次坐标系中,写出下列图形变换矩阵表达式:保持x=5,y=10 。图形点固定,在y轴
- 10Nginx_04——Tomcat+Nginx_负载均衡+反向代理_nginx反向代理tomcat
实时数据系列之kafka connect
赞
踩
前言
下面是关于kafka connect的官方定义
Kafka Connect是一种用于在Apache Kafka和其他系统之间以可伸缩的方式可靠地流式传输数据的工具。它使快速定义连接器变得简单,这些连接器可以将大量数据移入和移出kafka。Kafka Connect可以将整个数据库或从所有应用程序服务器收集到Kafka 的topic中,使数据可用于低延迟的流处理。导出作业可以将kafka topic中的数据传递到辅助存储和查询系统或批处理系统中,以便进行脱机分析。
安装
首先下载kafka并安装到本地环境,如果不知道怎么安装请跳转到kafka系列-入门篇之安装。
启动
分别启动zookeeper、kafka
启动kafka connect
kafka connect有两种方式,一种是单机模式,另一种是分布式模式。
单机模式
启动命令如下,稍微有点长。其中connect-standalone.properties是关于kafka connect的配置,另外两个配置是文件输入输出的配置。
connect-standalone.sh $KAFKA_HOME/config/connect-standalone.properties $KAFKA_HOME/config/connect-file-source.properties $KAFKA_HOME/config/connect-file-sink.properties
- 1
两个配置文件
name=local-file-source_demo
connector.class=FileStreamSource
tasks.max=1
file=/usr/local/apache/kafka_2.12-2.8.0/source.txt
topic=connect-demo
- 1
- 2
- 3
- 4
- 5
name=local-file-sink_demo
connector.class=FileStreamSink
tasks.max=1
file=/usr/local/apache/kafka_2.12-2.8.0/sink.txt
topics=connect-demo
- 1
- 2
- 3
- 4
- 5
测试
测试结果如下
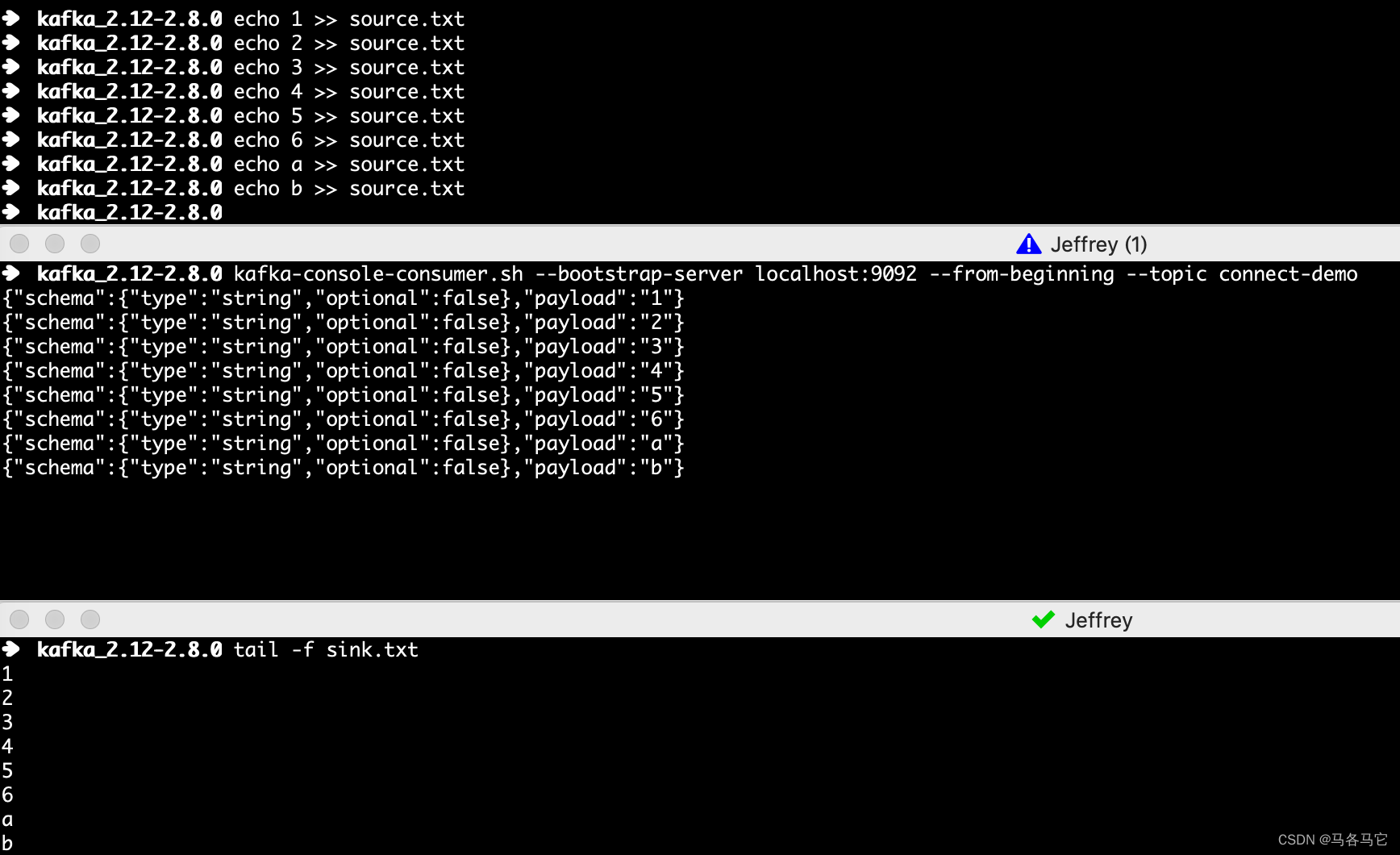
offset
kafka connect在单机模式下,有一个connect.offset文件会记录file source connector的offset,来保证不会重复消费

分布式模式
启动分布式模式的kafka connect
connect-distributed.sh $KAFKA_HOME/config/connect-distributed.properties
- 1
添加两个配置
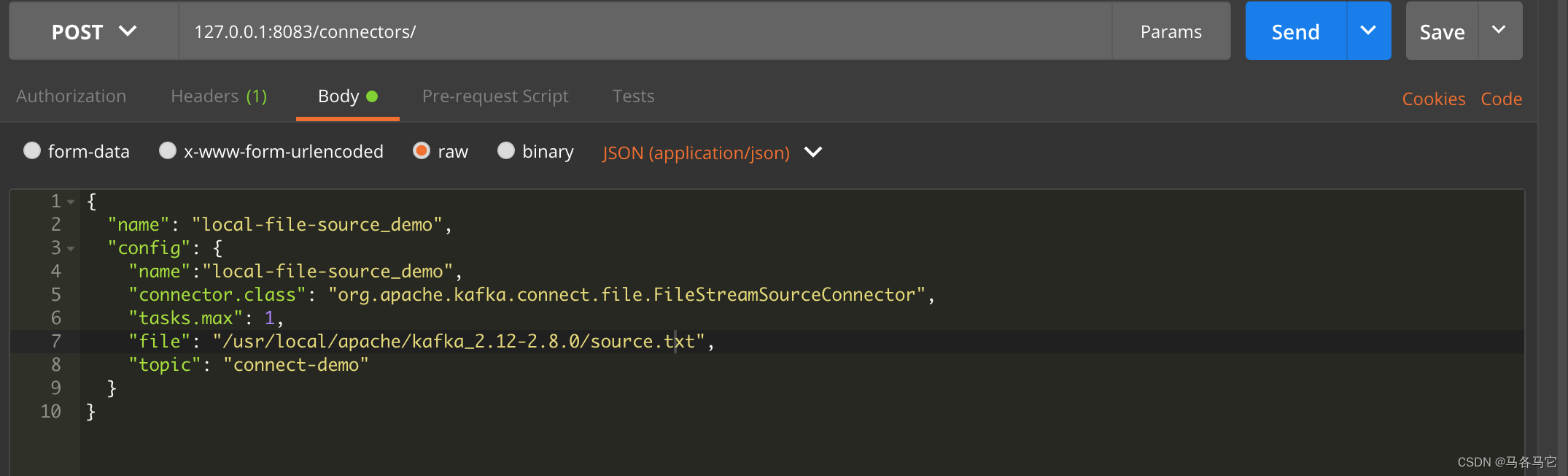
使用postman提交一个file source demo
{
"name": "local-file-source_demo",
"config": {
"name":"local-file-source_demo",
"connector.class": "org.apache.kafka.connect.file.FileStreamSourceConnector",
"tasks.max": 1,
"file": "/usr/local/apache/kafka_2.12-2.8.0/source.txt",
"topic": "connect-demo"
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
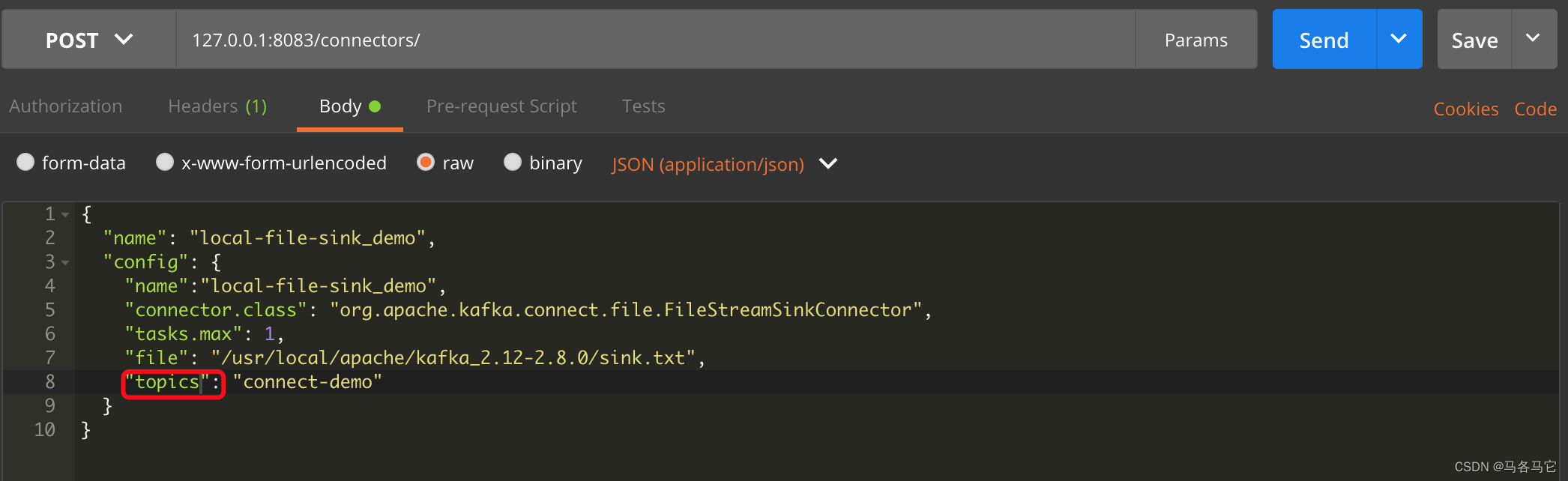
{
"name": "local-file-sink_demo",
"config": {
"name":"local-file-sink_demo",
"connector.class": "org.apache.kafka.connect.file.FileStreamSinkConnector",
"tasks.max": 1,
"file": "/usr/local/apache/kafka_2.12-2.8.0/sink.txt",
"topics": "connect-demo"
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
测试方式同单机一样,就忽略了
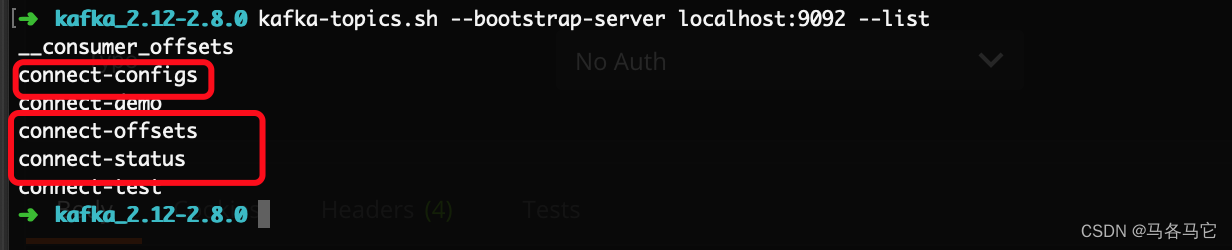
三个topic
分布式模式有三个默认topic
- connect-configs: 存放source connect的配置
- connect-offsets:存放source connect的offset
- connect-status:存放source connect的状态
单机和分布式的区别
- 单机使用的本地的properties文件存放每个connect的配置信息,而分布式使用的kafka topic来存放,通过api来添加。
- 单机的offset是用文件存放的,而分布式使用的kafka topic来存放。
- 单机也可以使用API,查看和添加都可以使用。只不过,一旦服务重启,通过api添加的connect就没有了。
因此,分布式模式可以使用多台机器负载,因为数据都不在某一台机器上,而是以副本的方式存放在kafka topic里面。
API
官方提供的API
单机和分布式都可以使用API,包括connector的增删改查、任务状态的控制和plugins列表等等。这里我就不翻译了,直接贴出来重要的几个api
- GET /connectors - return a list of active connectors
- POST /connectors - create a new connector; the request body should be a JSON object containing a string name field and an object config field with the connector configuration parameters
- GET /connectors/{name} - get information about a specific connector
- GET /connectors/{name}/config - get the configuration parameters for a specific connector
- PUT /connectors/{name}/config - update the configuration parameters for a specific connector
- DELETE /connectors/{name} - delete a connector, halting all tasks and deleting its configuration
- POST /connectors/{name}/restart?includeTasks=<true|false>&onlyFailed=<true|false> - restart a connector and its tasks instances.
- POST /connectors/{name}/tasks/{taskId}/restart - restart an individual task (typically because it has failed)
- PUT /connector-plugins/{connector-type}/config/validate - validate the provided configuration values against the configuration definition. This API performs per config validation, returns suggested values and error messages during validation.
connector和task
kafka connect定义connector和task来处理数据同步。了解源代码可以发现是connector来启动task,connector负责kafka的连接信息、topic,之后再启动一个或者多个task,去读取connector对应的信息,来同步数据。生产环境在同步mysql数据库时,如果同步失败,往往task就出现异常停止了,而connector还是正常工作。以后有机会在仔细的介绍吧。
三方插件
访问这个地址第三方提供的connector插件,可以查看到许多三方提供的kafka connect插件,上游同步jdbc的debizium是个不错的选择,下游可以使用jdbc、elasticsearch、mongo搭配着,就可以做端到端的实时同步了。依赖kafka的可用性、扩展性和性能,是一个非常不错的解决方案。
总结
通过一个简单的方式介绍了kafka connect的使用,实际生产使用的插件选择还比较多,做实时同步jdbc时,会遇到不少问题,有兴趣的可以留言一起讨论。

