
- 1无公网IP内网穿透使用vscode配置SSH远程ubuntu随时随地开发写代码
- 2OpenCV 4基础篇| OpenCV图像的裁切_opencv图像裁剪
- 3轰炸理解深度学习里面的encoder-decoder模型_深度学习encoder decoder
- 4数据结构与算法(七)(哈希表)_参考算法7.10,建立哈希表
- 5Docker一键部署Nextcloud_docker nextcloud
- 6Dijkstra算法图文详解和C++代码_dijkstra算法c++代码
- 7hive启动的一些小问题_com.mysql.jdbc.sqlerror.createsqlexception(sqlerro
- 8基于微信小程序的新生报到系统的设计与实现ssm
- 9华为OD机试C卷-- 约瑟夫问题(Java & JS & Python & C)
- 10AI 写高考作文:10 款大模型,实力水平如何?_qwen2-72b vs文心一言
Kafka 中的再均衡_kafka再均衡
赞
踩
我们先回顾下,一个主题可以有多个分区,而订阅该主题的消费组中可以有多个消费者。每一个分区只能被消费组中的一个消费者消费,可认为每个分区的消费权只属于消费组中的一个消费者。但是世界是变化的,例如消费者会宕机,还有新的消费者会加入,而为了应对这些变化,让分区所属权的分配合理,这都需要对分区所属权进行调整,也就是所谓的 “再均衡”。本文将对再均衡的相关知识进行详细叙述。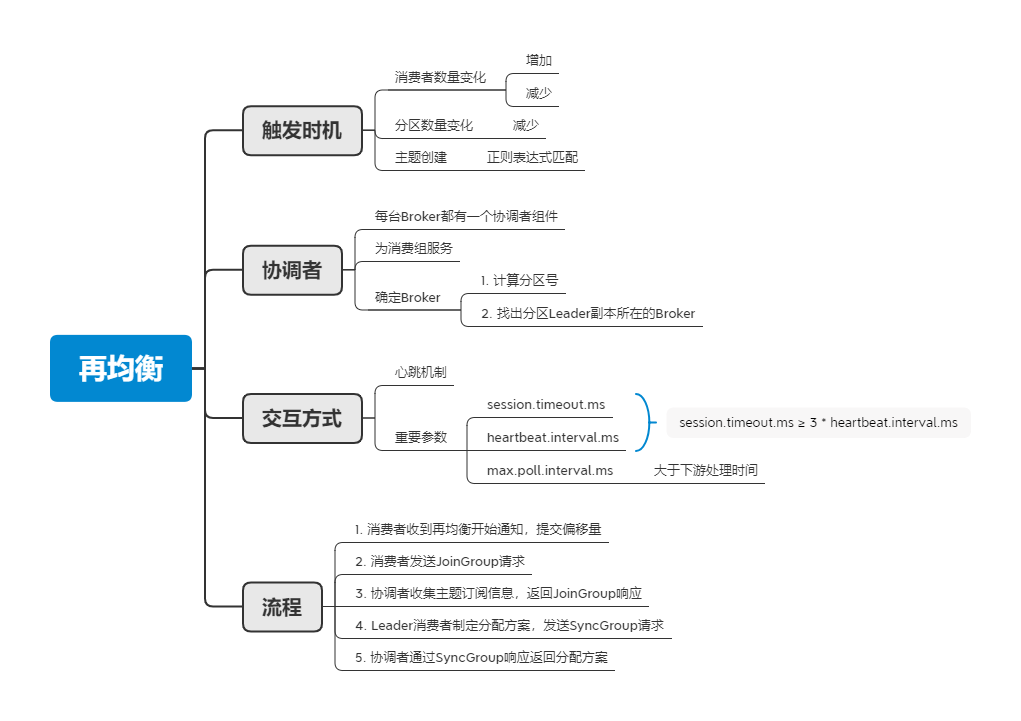
触发时机
首先,我们需要了解什么情况下会触发再均衡,在前文已经提到了消费者数量的变化,是需要再均衡的。在使用 Kafka 时,除了消费者数量可能会变化,分区数量也同样可能变化,我们可以人为的对分区数量进行修改,但是 Kafka 只允许增加分区,所以我们只能把分区数量调大,不能调小,否则会收到 InvalidPartitionException 异常。关于为什么不能减少分区,可参考下面的回答:
按 Kafka 现有的代码逻辑,此功能是完全可以实现的,不过也会使得代码的复杂度急剧增大。实现此功能需要考虑的因素很多,比如删除掉的分区中的消息该作何处理?如果随着分区一起消失则消息的可靠性得不到保障;如果需要保留则又需要考虑如何保留。直接存储到现有分区的尾部,消息的时间戳就不会递增,如此对于 Spark、Flink 这类需要消息时间戳(事件时间)的组件将会受到影响;如果分散插入到现有的分区中,那么在消息量很大的时候,内部的数据复制会占用很大的资源,而且在复制期间,此主题的可用性又如何得到保障?与此同时,顺序性问题、事务性问题、以及分区和副本的状态机切换问题都是不得不面对的。反观这个功能的收益点却是很低,如果真的需要实现此类的功能,完全可以重新创建一个分区数较小的主题,然后将现有主题中的消息按照既定的逻辑复制过去即可。
简单来说,就是做这个功能需要考虑很多因素,这样会把代码弄的很复杂,而收益却很低,而且存在替代方案来实现该效果,创建一个分区数小的主题,再把当前主题迁移过去。
除了消费者、分区数量的变化,还有一种情况,也需要进行再均衡。当消费者订阅主题时使用的是正则表达式,例如 “test.*”,表示订阅所有以 test 开头的主题,当有新的以 test 开头的主题被创建时,则需要通过再均衡将该主题的分区分配给消费者。
再均衡的三种触发时机,我们已经清楚了,下面我们看下再均衡是如何实现的。
协调者
再均衡,将分区所属权分配给消费者。因此需要和所有消费者通信,这就需要引进一个协调者的概念,由协调者为消费组服务,为消费者们做好协调工作。在 Kafka 中,每一台 Broker 上都有一个协调者组件,负责组成员管理、再均衡和提交位移管理等工作。如果有 N 台 Broker,那就有 N 个协调者组件,而一个消费组只需一个协调者进行服务,那该 ** 由哪个 Broker 为其服务?** 确定 Broker 需要两步:
-
计算分区号
partition = Math.abs(groupID.hashCode() % offsetsTopicPartitionCount)根据
groupID的哈希值,取余offsetsTopicPartitionCount(内部主题__consumer_offsets的分区数,默认 50)的绝对值,其意思就是把消费组哈希散列到内部主题__consumer_offsets的一个分区上。确定协调者为什么要和内部主题扯上关系。这就跟协调者的作用有关了。协调者不仅是负责组成员管理和再均衡,在协调者中还需要负责处理消费者的偏移量提交,而偏移量提交则正是提交到__consumer_offsets的一个分区上。所以这里需要取余offsetsTopicPartitionCount来确定偏移量提交的分区。 -
找出分区 Leader 副本所在的 Broker
确定了分区就简单了,分区 Leader 副本所在的 Broker 上的协调者,就是我们要找的。
这个算法通常用于帮助定位问题。当一个消费组出现问题时,我们可以先确定协调者的 Broker,然后查看 Broker 端的日志来定位问题。
交互方式
协调者,我们确定了。那协调者和消费者之间是如何交互的?协调者如何掌握消费者的状态,又如何通知再均衡。这里使用了心跳机制。在消费者端有一个专门的心跳线程负责以 heartbeat.interval.ms 的间隔频率发送心跳给协调者,告诉协调者自己还活着。同时协调者会返回一个响应。而当需要开始再均衡时,协调者则会在响应中加入 REBALANCE_IN_PROGRESS,当消费者收到响应时,便能知道再均衡要开始了。
由于再平衡的开始依赖于心跳的响应,所以 heartbeat.interval.ms 除了决定心跳的频率,也决定了再均衡的通知频率。
现在我们再重新看下,触发再均衡的时机,前面说到有三种情况触发再均衡,分别是消费者数量的增加或减少、分区数的增加和新创建主题,其中消费者数量增加、分区数增加和新创建主题,这都是必须是人为操作,算是计划内的再均衡。而消费者数量减少则除了是人为操作,也可能因为其他原因导致,属于计划之外的再均衡,这是我们需要关心的,毕竟再均衡的开销还是很大的,所有消费者都会停止工作,所以我们应尽量避免不必要的再均衡。下面我们看下影响消费者数量减少的参数有哪些:
-
session.timeout.ms:Broker 端参数,消费者的存活时间,默认 10 秒,如果在这段时间内,协调者没收到任何心跳,则认为该消费者已崩溃离组; -
heartbeat.interval.ms:消费者端参数,发送心跳的频率,默认 3 秒; -
max.poll.interval.ms:消费者端参数,两次调用 poll 的最大时间间隔,默认 5 分钟,如果 5 分钟内无法消费完,则会主动离组。
可以看出 session.timeout.ms 和 heartbeat.interval.ms 是相关的,这里给出一个建议参考的公式:
session.timeout.ms ≥ 3 * heartbeat.interval.ms
为尽量避免因为偶发的网络原因,心跳无法到达协调者,在超时之前,应至少能发送 3 轮心跳。再给出一个经验值的设置:session.timeout.ms=6s,heartbeat.interval.ms=2s。
max.poll.interval.ms 的设置,则主要和下游处理时间有关,例如下游处理时间需要 6 分钟,那按默认值是不合理的,消费者会频繁主动离组。所以需要把值设置的比下游处理时间大一点,避免不必要的再均衡。
这一小节主要讲了协调者如何通知消费者开始再均衡,以及如何设置参数避免不必要的再均衡,下面我们看下再均衡的流程是怎么样的。
流程
-
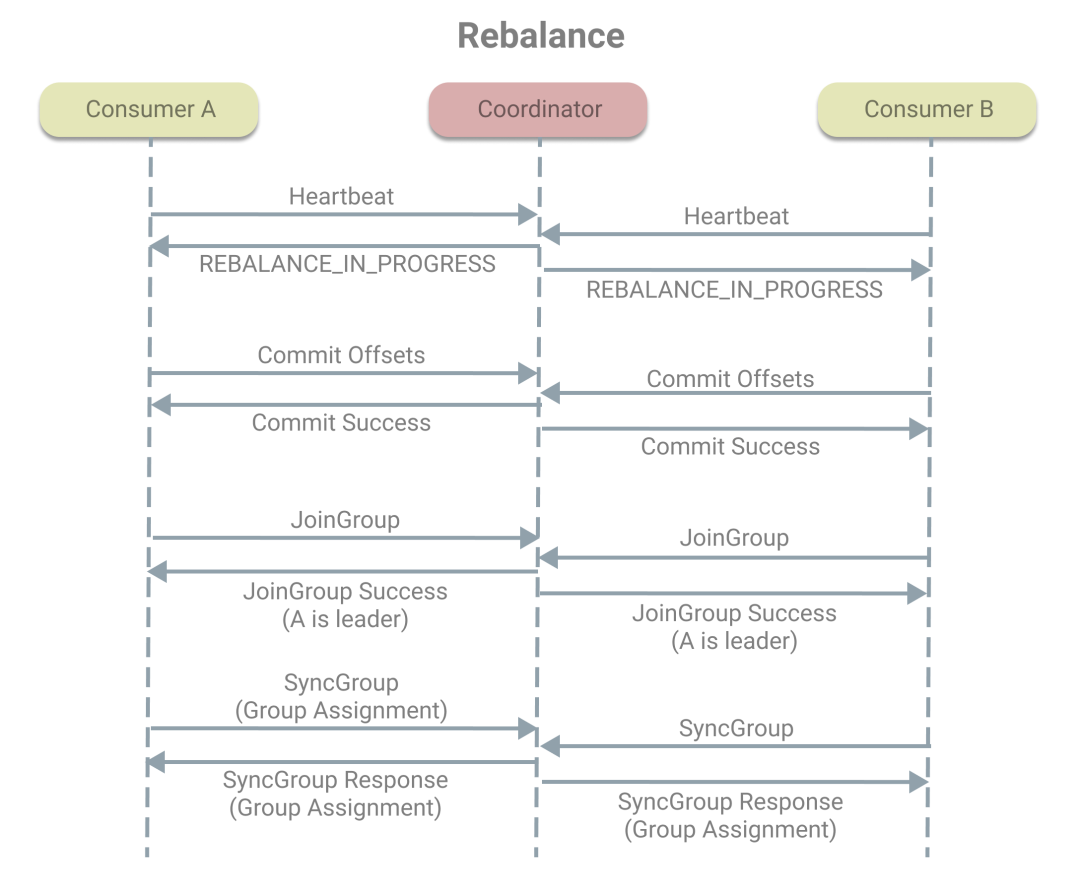
当消费者收到协调者的再均衡开始通知时,需要立即提交偏移量;
-
消费者在收到提交偏移量成功的响应后,再发送 JoinGroup 请求,重新申请加入组,请求中会含有订阅的主题信息;
-
当协调者收到第一个 JoinGroup 请求时,会把发出请求的消费者指定为 Leader 消费者,同时等待
rebalance.timeout.ms,在收集其他消费者的 JoinGroup 请求中的订阅信息后,将订阅信息放在 JoinGroup 响应中发送给 Leader 消费者,并告知他成为了 Leader,同时也会发送成功入组的 JoinGroup 响应给其他消费者; -
Leader 消费者收到 JoinGroup 响应后,根据消费者的订阅信息制定分配方案,把方案放在 SyncGroup 请求中,发送给协调者。普通消费者在收到响应后,则直接发送 SyncGroup 请求,等待 Leader 的分配方案;
-
协调者收到分配方案后,再通过 SyncGroup 响应把分配方案发给所有消费组。
-
当所有消费者收到分配方案后,就意味着再均衡的结束,可以正常开始消费工作了。
参考
-
《深入理解 Kafka》
-
《Kafka 核心技术与实战》
-
Kafka 之 Group 状态变化分析及 Rebalance 过程: https://matt33.com/2017/01/16/kafka-group/#Consumer- 初始化时 -group- 状态变化


