
热门标签
热门文章
- 1AI学习笔记(七)图像滤波器、OpenCV算法解析_pout=pin+xmmeans+sigma
- 2代码文档生成工具doxdgen使用简易教程_doxygen使用教程
- 3第十四届蓝桥杯大赛国赛模拟题Python卷_lanqiaopython青少组国赛
- 4NLP分类
- 5数字IC/FPGA 秋招知识点不全面整理_数字ic fpga 秋招
- 6力扣207题“课程表”
- 7基于K8s调度器实现自定义调度
- 8大数据教材推荐-《Python数据分析与应用(第2版)(微课版)》
- 9(车载)毫米波雷达信号处理中的恒虚警检测(CFAR)技术概述_雷达横虚警检测
- 10python美化图形化界面设计,pythontkinter界面美化_python tkinter窗口美化
当前位置: article > 正文
左神LeetCode_leetcode 左神
作者:小惠珠哦 | 2024-07-04 11:35:21
赞
踩
leetcode 左神
左神LeetCode
1.链表
哈希表:
unordered_set<key>
unordered_map<key,value>
以上二者在结构上没有太大区别。哈希表增删改查时间复杂度都是 O(1)
1.哈希表中的key是基础类型,在插入时按照值传递的方式;是自定义类型,就会按照地址传递方式(8bytes)
eg. student Jomo = new student("Jomo",19),插入时,把Jomo看作指向一块区域的"指针"
有序表:
ordered_Set<key>
ordered_map<key,value>
与哈希表不同的是元素之间按key排序,且自定义类型需要重载比较器;增删改查时间复杂度 O(logn)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
面试时链表解题的方法论:
- 笔试:一切为了时间复杂度
- 面试:考虑时间复杂度的同时,一定要找到空间最省方法
重要技巧:
- 额外数据结构记录(哈希表等)
- 快慢指针
1.1 234. 回文链表
方法一:栈 利用栈先进后出的特性,可以发现遍历链表的过程中把结点压栈,出栈时的顺序恰好就是链表的逆序了。 时间复杂度:O(n) 空间复杂度:O(n) 方法二:一半栈 与方法一大同小异,不过我们利用快慢指针将链表的后半段压入栈即可,节省了一半的空间。 时间复杂度:O(n) 空间复杂度:O(n) 快慢指针遍历链表coding: 方法三:反向链表 fast指针走完时,让后半部分结点的next指针指向每个结点的前一个结点,然后两边向中间遍历比较,最后恢复链表。 class Solution { public: bool isPalindrome(ListNode* head) { //如果为空链表或者结点个数=1,肯定是回文链表 if(head==NULL||head->next==NULL)return true; //创建快慢指针 ListNode*slow=head; ListNode*fast=head; while(fast->next!=NULL&&fast->next->next!=NULL){ slow=slow->next; fast=fast->next->next; } //结束while循环后,slow指向中间结点,接下来就是改变后续链表方向 ListNode*rightOne=slow->next;//记录链表方向开始变化的第一个结点 slow->next=NULL;//mid->next=NULL ListNode*next=NULL;//前驱结点 while(rightOne!=NULL){ next=rightOne->next;//保存原链表中slow的下一个结点 rightOne->next=slow;//让后面的结点指向前面 slow=rightOne;//slow move rightOne=next;//rightOne move } //结束循环后,slow指向链表的最后一个结点 ListNode*last=slow;//保存最后一个结点 ListNode*temp=head;//创建头指针副本 bool res=true;//记录返回值 while(temp!=NULL&&slow!=NULL){ if(temp->val!=slow->val){ res=false; break; } temp=temp->next; slow=slow->next; } //恢复链表原貌 ListNode*pre=last; next=last->next; last->next=NULL; last=next; while(last!=NULL){ next=last->next; last->next=pre; pre=last; last=next; } return res; } };

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
1.2 面试题 02.04. 分割链表
方法一:数组 方法二:小等大指针 1.创建6个结点指针:SH(Smaller Head),ST(Smaller Tail);EH,ET;GH,GT 2.遍历链表,将每个结点值与基准值比较后,放到对应指针区域 eg.SH=NULL且ST=NULL,则SH=第一个符合要求的结点,ST=SH;SH!=NULL且ST!=NULL;ST->next=下一个符合 的结点;ST=ST->next;ST->next=NULL; 3.注意考虑边界情况:没有小于等于或大于基准值的结点 3. ST->next=EH; 4. ET->next=GH; class Solution { public: ListNode* partition(ListNode* head, int x) { ListNode*SH=NULL;//小头 ListNode*ST=NULL;//小尾 ListNode*EH=NULL;//等头 ListNode*ET=NULL;//等尾 ListNode*GH=NULL;//大头 ListNode*GT=NULL;//大尾 //遍历链表 ListNode*temp=head;//创建头指针副本 ListNode*next=NULL; while(temp!=NULL){ next=temp->next; temp->next=NULL; if(temp->val<x){ if(SH==NULL&&ST==NULL){ SH=temp; ST=SH; }else{ ST->next=temp; ST=ST->next; } } else if(temp->val==x){ if(EH==NULL&&ET==NULL){ EH=temp; ET=EH; }else{ ET->next=temp; ET=ET->next; } } else if(temp->val>x){ if(GH==NULL&>==NULL){ GH=temp; GT=GH; }else{ GT->next=temp; GT=GT->next; } } temp=next; } if(ST!=NULL){ ST->next=EH; ET=ET==NULL?ST:ET; } if(ET!=NULL){ ET->next=GH; } return SH==NULL?(EH==NULL?GH:EH):SH; } };
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
1.3 138.复制带随机指针的链表
方法一:哈希表 方法二:插入克隆结点 因为位置的相对关系已经确定,所以我们可以精确的找到克隆结点和旧结点的位置,又因为旧结点和克隆结点是成对存在的,因此有点类似于哈希表。 class Solution { public: Node* copyRandomList(Node* head) { //创建哈希表记录对应的克隆结点 unordered_map<Node*,Node*>st; //创建头指针副本 Node*temp=head; //插入哈希表 while(temp!=NULL){ st.insert(make_pair(temp,new Node(temp->val))); temp=temp->next; } //同步克隆结点和原结点的信息 temp=head; while(temp!=NULL){ //注意克隆结点的指针指向的必须是克隆结点,不能是原结点 st[temp]->next=st[temp->next]; st[temp]->random=st[temp->random]; temp=temp->next; } return st[head]; } };
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
1.4 剑指 Offer II 022. 链表中环的入口节点
![(img-tx5S7Mt6-1668692559795)(C:\Users\86135\OneDrive\文档\数据结构与算法\zsLeetCode-img\1.png)]](https://img-blog.csdnimg.cn/61869e164ee745c2b3c9e5c4f5cde37b.png)
方法一:哈希表 利用哈希表快速查元素的特性。 方法二:快慢指针 class Solution { public: ListNode *detectCycle(ListNode *head) { //如果链表为空或者只有1个结点,肯定无法构成环 if(head==NULL||head->next==NULL||head->next->next==NULL)return NULL; //创建快慢指针 ListNode*fast=head->next->next; ListNode*slow=head->next; //第一次相遇 while(fast!=slow){//注意如果把fast!=slow放在循环条件,那就不能一开始就让fast和slow都指向head if(fast->next==NULL||fast->next->next==NULL){ return NULL; } slow=slow->next; fast=fast->next->next; } fast=head; while(slow!=fast){ slow=slow->next; fast=fast->next; } return slow; } };
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
2.二叉树
2.1 98. 验证二叉搜索树
方法一:中序遍历 看是否升序。不需要数组,因为只需要当前值和前一个值作比较 class Solution { long preVal=LONG_MIN; public: bool isValidBST(TreeNode* root) { //空树 if(root==NULL)return true; //判断左子树 bool isLeftBST=isValidBST(root->left); //左子树不是BST,那整棵树都不是 if(!isLeftBST)return false; //当前值小于前值,说明不是升序,不是BST if(root->val<=preVal){ return false; }else{ preVal=root->val;//更新preVal } //判断右子树 return isValidBST(root->right); } };
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
2.2 958. 二叉树的完全性检验
方法一:宽度遍历 1.碰到任一结点有右子结点而没有左子结点。返回false 2.在1不违规的情况下,遇到了第一个左右子结点不全(缺一即可),那么后续所以结点都必须是叶子结点 class Solution { public: bool isCompleteTree(TreeNode* root) { //空树 if(!root)return true; //创建队列 queue<TreeNode*>qu; //加入根结点 qu.push(root); //判断已经遇到左右子结点不全的情况 bool leaf=false; TreeNode*l=NULL; TreeNode*r=NULL; while(!qu.empty()){ TreeNode*head=qu.front(); qu.pop(); l=head->left; r=head->right; if((l==NULL&&r!=NULL)||leaf&&!(l==NULL&&r==NULL))return false; if(l)qu.push(l); if(r)qu.push(r); if(l==NULL||r==NULL)leaf=true; } return true; } };
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
二叉树的套路:
利用左右子树的信息,罗列各种可能性,树型DP
2.3 判断满二叉树
符合树型DP的才可以用以下套路
思路:nodes=2^h-1 //创建一个类,保存结点信息 class Info{ public: int height; int nodes; Info(int h,int n): height(h),nodes(n){} }; //递归分析函数 Info f(Node*x){ if(x==NULL)return Info(0,0); Info leftData=f(x->left); Info rightData=f(x->right); int height=max(leftData.height,rightData.height)+1; int nodes=leftData.nodes+rightData.nodes+1; return new Info(height,nodes); } bool isF(Node*root){ if(root==NULL)return true; Info data=f(head); return data.nodes==((1<<data.height)-1);//左移几次就是乘以2的几次方 }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
2.4 剑指 Offer 55 - II. 平衡二叉树
思路:判断平衡二叉树需要左子树和右子树的高度和平衡状况,符合树型DP class ReturnType{ public: bool isBalance; int height; ReturnType(bool isB,int h): isBalance(isB),height(h){} }; ReturnType process(Node*x){ if(x==NULL)return ReturnType(true,0); //处理左子树 ReturnType leftData=process(x->left); //处理右子树 ReturnType rightData=process(x->right); //处理本结点 bool isBalance=leftData.isBalance&&rightData.isBalance&&abs(leftData.height-rightData.height)<2; int height=max(leftData.height,rightData.height)+1; //返回本层结点的信息给上一层 return ReturnType(isBalance,height); } bool isB(Node*root){ return process(root).isBalance; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
2.5 剑指 Offer 68 - II. 二叉树的最近公共祖先
方法一:哈希表 思路:找到每个结点的父结点 void process(TreeNode*root,unordered_map<TreeNode*,TreeNode*>&fatherMap){ if(root==NULL)return; fatherMap[root->left]=root; fatherMap[root->right]=root; process(root->left,fatherMap); process(root->right,fatherMap); } //返回o1,o2的最近公共祖先 TreeNode*lca(TreeNode*root,TreeNode*o1,TreeNode*o2){ unordered_map<TreeNode*,TreeNode*>fatherMap; fatherMap[root]=root; process(root,fatherMap); unordered_set<TreeNode*>set1; TreeNode*cur=o1; //让cur向上走,把所有祖先放入set1 while(cur!=fatherMap[cur]){ set1.insert(cur); cur=fatherMap[cur]; } //把root放入set1 set1.insert(root); //让o2向上走,如果走到的结点存在于set1中,那就是最近公共祖先 TreeNode*res=o2; while(set1.find(res)==set1.end()){ res=fatherMap[res]; } return res; } 方法二: 1. o1是o2的lca,或o2是o1的lca 2. o1和o2不互为公共祖先,往上汇聚才能找到 函数实际上只返回NULL或o1或o2或o1、o2的最近共同祖先。 结点左右都为空的话该结点必定也返回空,叶子结点的left和right必定为空,会导致返回空层层向上传递直至o1、o2 class Solution { public: TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) { if(root==NULL||root==p||root==q)return root; TreeNode*left=lowestCommonAncestor(root->left,p,q); TreeNode*right=lowestCommonAncestor(root->right,p,q); if(left!=NULL&&right!=NULL)return root;//当left和right分别等于o1、o2时 return left!=NULL?left:right; } };
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
2.6 面试题 04.06. 后继者
1. x有右树:x的后继结点是其右树的最左结点 2. x无右树:一路往父结点找,当发现某个结点是其父结点的左子结点时,该父结点就是x的后继结点 2.1注意考虑x是不是整棵树的最右结点 3.不考虑左树的原因:后续结点不会出现在左树中 class Solution { public: TreeNode* inorderSuccessor(TreeNode* root, TreeNode* p) { unordered_map<TreeNode*,TreeNode*>fatherMap; fatherMap[root]=NULL; process(root,fatherMap); TreeNode*parent=fatherMap[p]; if(p->right!=NULL)return getLeftMost(p->right); else{//无右树 while(parent!=NULL&&parent->left!=p){ p=parent; parent=fatherMap[p]; } } return parent; } void process(TreeNode*root,unordered_map<TreeNode*,TreeNode*>&fatherMap){ if(root==NULL)return; fatherMap[root->left]=root; fatherMap[root->right]=root; process(root->left,fatherMap); process(root->right,fatherMap); } TreeNode*getLeftMost(TreeNode*node){ if(node==NULL)return node; while(node->left!=NULL){ node=node->left; } return node; } };
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
2.7 剑指 Offer II 048. 序列化与反序列化二叉树
内存里的一棵树如何变成字符串形式,又如何从字符串形式变成内存里的树
class Codec { public: void rserialize(TreeNode* root, string& str) { if (root == nullptr) { str += "null,"; } else { str += to_string(root->val) + ","; rserialize(root->left, str); rserialize(root->right, str); } } string serialize(TreeNode* root) { string ret; rserialize(root, ret); return ret; } TreeNode* rdeserialize(list<string>& dataArray) { if (dataArray.front() == "null") { dataArray.erase(dataArray.begin()); return nullptr; } TreeNode* root = new TreeNode(stoi(dataArray.front())); dataArray.erase(dataArray.begin()); root->left = rdeserialize(dataArray); root->right = rdeserialize(dataArray); return root; } TreeNode* deserialize(string data) { list<string> dataArray; string str; for (auto& ch : data) { if (ch == ',') { dataArray.push_back(str); str.clear(); } else { str.push_back(ch); } } if (!str.empty()) { dataArray.push_back(str); str.clear(); } return rdeserialize(dataArray); } };
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
2.8 微软面试:折纸问题
思路:
除了最上和最下两条折痕,每条折痕的上下两条折痕分别为凹凸
void printProcess(int i,int N,bool down){
if(i>N)return;
//左子结点
printProcess(i+1,N,true);
down?cout<<"凹":cout<<"凸";
//右子结点
printProcess(i+1,N,false);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
3.图
创建一套属于自己的模板,在自己的模板里把算法玩熟悉
模板1:
思路: 1.存储顶点用vector<char> 2.保存矩阵用vector<vector<int>>edges,表示边的关系 class Graph { private: vector<char>vertex;//存储顶点集合 vector<vector<int>>edges;//存储图对应的领接矩阵 int numOfEdges;//边的数目 public: //构造器 Graph(int n) { //初始化矩阵和vertexList for (int i = 0; i < n; i++) { edges.push_back(vector<int>(n)); } numOfEdges = 0; } //图中常用的方法 //返回节点个数 int getNumOfVertex() { return vertex.size(); } //得到边的数目 int getNumOfEdges() { return numOfEdges; } //返回节点i(下标)对应的数据 char getValueByIndex(int i) { return vertex[i]; } //返回[x][y]的权值 int getWeight(int x, int y) { return edges[x][y]; } //显示图对应的矩阵 void showGraph() { for (auto& link : edges) { cout << "[" << " "; for (auto& n : link) { cout << n << " "; } cout <<"]"<< endl; } } //插入节点 void insertVertex(char vertex2) { vertex.push_back(vertex2); } //添加边 void insertEdge(int x, int y, int weight) { edges[x][y] = weight; edges[x][y] = weight; numOfEdges++; } };
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
3.1 图的广度优先遍历:队列
//得到第一个邻接节点的下标w,如果存在就返回对应的下标,否则返回-1 int getFirstNeighbor(int index) { for (int j = 0; j < vertex.size(); j++) { if (edges[index][j] > 0) { return j; } } return -1; } //根据前一个邻接节点的下标来获取下一个邻接节点 int getNextNeighbor(int v1, int v2) { for (int j = v2 + 1; j < vertex.size(); j++) { if (edges[v1][j] > 0) { return j; } } return -1; } //对一个节点进行广度优先遍历的方法 void bfs(vector<bool>& isvisited, int i) { int u=0;//表示队列头的对应下标 int w = 0;//邻接节点w //队列,记录节点访问的顺序 queue<int>qu; //能调用该函数,说明该节点可访问,输出节点信息 cout << getValueByIndex(i) << "=>"; //标记为已访问 isvisited[i] = true; //将节点加入队列 qu.push(i); while (!qu.empty()) { //取出队列的头节点下标 u = qu.front(); qu.pop(); //得到第一个邻接节点的下标 w = getFirstNeighbor(u); while (w != -1) {//找到 //判断w节点是否被访问过 if (!isvisited[w]) {//未被访问过 //输出节点信息 cout << getValueByIndex(w) << "=>"; //标记已被访问 isvisited[w] = true; //入队 qu.push(w); } //如果w已被访问过,那么就以u为前驱节点,找w后面的邻接节点 w = getNextNeighbor(u, w);//体现出广度优先 } } } //重载bfs,遍历所有节点都进行广度优先搜索 void bfs() { for (int i = 0; i < vertex.size(); i++) { if (!isVisited[i]) { bfs(isVisited, i); } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
3.2 图的深度优先遍历:递归
//得到第一个邻接节点的下标w,如果存在就返回对应的下标,否则返回-1 int getFirstNeighbor(int index) { for (int j = 0; j < vertex.size(); j++) { if (edges[index][j] > 0) { return j; } } return -1; } //根据前一个邻接节点的下标来获取下一个邻接节点 int getNextNeighbor(int v1, int v2) { for (int j = v2 + 1; j < vertex.size(); j++) { if (edges[v1][j] > 0) { return j; } } return -1; } //深度优先遍历算法 //i第一次就是0 void dfs(vector<bool>&isvisited,int i) { //首先访问该节点,输出 cout << getValueByIndex(i) << "->"; //将该节点设置成已访问 isvisited[i] = true; //查找i节点的第一个邻接节点 int w = getFirstNeighbor(i); while (w != -1) { if (!isvisited[w]) { dfs(isvisited, w); } w = getNextNeighbor(i, w); } } //重载dfs void dfs() { for (int i = 0; i < vertex.size(); i++) { if (!isVisited[i]) { dfs(isVisited, i); } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
3.3 拓扑排序
确定做事的顺序:优先执行入度为0的点,然后擦拭掉该点的影响(即边)
模板2:
class Node; class Edge{ public: int weight;//权重 Node*from=NULL;//出发点 Node*to;//终点 Edge(int weight,Node*from,Node*to){ this->weight=weight; this->from=from; this->to=to; } }; class Node{ public: int value;//结点值 int in;//入度 int out;//出度 vector<Node*>nexts;//相邻结点 vector<Edge>edges;//相邻边 Node(int value){ this->value=value; in=0; out=0; } }; class Graph{ public: map<int,Node*>nodes; set<Edge>edges; };
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
拓扑排序代码实现:
list<Node*>sortedTopology(Graph&graph){ map<Node*,int>inMap; //入度为0的点才可以进队列 queue<Node*>zeroInQueue; for(auto it=graph.nodes){ inMap.insert(it->second,it->first); if(it->second->in==0){ zeroInQueue.push(it->second); } } //拓扑排序的结果,依次加入result List<Node*>result; while(!zeroInQueue.empty()){ Node*cur=zeroInQueue.front(); zeroInQueue.pop(); result.push(cur); for(Node*next:cur.nexts){ inMap[next]-=1; if(inMap[next]==0){ zeroInQueue.push(next); } } } return result; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
3.4 最小生成树
1.保证所有点连通,但不一定需要所有的边
2.既保证连通性,同时边的权值累加和最小
3.4.1 Kruskal算法
**适用范围:**无向图
思路: 1.一开始把所有点看作孤立点,即每个点自成一个集合 //使用INT_MAX表示两个顶点不连通 int INF = INT_MAX; //创建一个类EData,它的对象实例就表示一条边 class EData { public: char start;//边的起点 char end;//边的终点 int weight;//边的权值 EData() :start(' '), end(' '), weight(0) {} EData(char start, char end, int weight) { this->start = start; this->end = end; this->weight = weight; } void toString() { cout << "start: " << this->start << " end: " << this->end << " weight: " << this->weight << endl; } }; class KruskalCase { private: int edgeNum = 0;//边的个数 string vertexs;//顶点数组 vector<vector<int>>matrix;//邻接矩阵 public: KruskalCase(string vertexs, vector<vector<int>>& matrix) { size_t vlen = vertexs.length(); this->vertexs=vertexs; this->matrix=matrix; //统计边数 for (size_t i = 0; i < vlen; i++) { for (size_t j = i + 1; j < vlen; j++) { if (this->matrix[i][j] != INF) { edgeNum++; } } } } //Kruskal算法 vector<EData> kruskal() { int index = 0;//表示最后结果数组的索引 vector<int>ends(this->edgeNum);//用于保存“已有最小生成树”中的每个顶点在最小生成树中的终点 //创建结果数组,保存最后的最生成树 vector<EData>rets; //获取图中所有边的集合,一共有12条边 vector<EData>edges = getEdges(); //按照边的权值大小进行排序(从小到大) sortEdges(edges); //遍历edges数组,将边添加到最小生成树中时,判断准备加入的边是否形成了回路,如果没有,就加入rets,否则不能加入 for (int i = 0; i < edgeNum; i++) { //获取到第i条边的第一个顶点(起点) int p1 = getPosition(edges[i].start); //获取到第i条边的第二个顶点 int p2 = getPosition(edges[i].end); //获取p1这个顶点在已有最小生成树中的终点 int m = getEnd(ends, p1); //获取p2这个顶点在已有最小生成树中的终点 int n = getEnd(ends, p2); if (m != n) {//不构成回路 ends[m] = n;//设置m 在“已有最小生成树”中的终点 rets.push_back(edges[i]);//有一条边加入到rets数组 } } for (int i = 0; i < rets.size(); i++) { rets[i].toString(); } return rets; } //打印邻接矩阵 void print() { cout << "邻接矩阵为:" << endl; for (int i = 0; i < vertexs.length(); i++) { for (int j = 0; j < vertexs.length(); j++) { cout << matrix[i][j] << "\t"; } cout << endl; } } //对边进行排序处理,冒泡排序 void sortEdges(vector<EData>& edges) { for (int i = 0; i < edges.size(); i++) { for (int j = 0; j < edges.size() - i-1; j++) { if (edges[j].weight < edges[j + 1].weight) { EData temp = edges[j]; edges[j] = edges[j + 1]; edges[j + 1] = temp; } } } } int getPosition(char ch) { for (int i = 0; i < vertexs.length(); i++) { if (vertexs[i] == ch) { return i; } } //找不到,返回-1 return -1; } //获取图中边,放到EData数组中,后面我们需要遍历该数组 vector<EData> getEdges() { vector<EData>edges; for (int i = 0; i < vertexs.length(); i++) { for (int j = i + 1; j < vertexs.length(); j++) { if (matrix[i][j] != INF) { edges.push_back(EData(vertexs[i], vertexs[j], matrix[i][j])); } } } return edges; } //获取下标为i的顶点的终点,,用于判断两个顶点的终点是否相同 //ends数组记录了各个顶点对应的终点,ends数组实在遍历过程中,逐步形成 int getEnd(vector<int>& ends, int i) { while (ends[i] != 0) { i = ends[i]; } return i; } }; int main() { string vertexs = "ABCDEFG"; vector<vector<int>>matrix = { {0,12,INF,INF,INF,16,14}, {12,0,10,INF,INF,7,INF}, {INF,10,0,3,5,6,INF}, {INF,INF,3,0,4,INF,INF}, {INF,INF,5,4,0,2,8}, {16,7,6,INF,2,0,9}, {14,INF,INF,INF,8,9,0} }; //创建KruskalCase对象实例 KruskalCase kruskalCase(vertexs, matrix); //输出构建的 kruskalCase.print(); kruskalCase.kruskal(); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
3.4.2 Prim算法
思路: 1.从已在连通集合中的点中,找到与之相关权值最小的边,依次连通下一个点。 //创建一个类EData,它的对象实例就表示一条边 class EData { public: int start;//边的起点 int end;//边的终点 int weight;//边的权值 EData() :start(' '), end(' '), weight(0) {} EData(int start, int end, int weight) { this->start = start; this->end = end; this->weight = weight; } void toString() { cout << "start: " << this->start << " end: " << this->end << " weight: " << this->weight << endl; } }; class MGraph { public: int verxs;//表示图的节点个数 string data;//存放节点数据 vector<vector<int>>weight;//存放边,邻接矩阵 MGraph(int verxs) {//构造函数 this->verxs = verxs; for (int i = 0; i < verxs; i++) { data.append(" "); weight.push_back(vector<int>(verxs)); } } }; //创建最小生成树->村庄的图 class MinTree { //创建图的邻接矩阵 public: void createGraph(MGraph& graph, int verxs, string data, vector<vector<int>>& weight) { for (int i = 0; i < verxs; i++) {//顶点 graph.data[i] = data[i]; for (int j = 0; j < verxs; j++) { graph.weight[i][j] = weight[i][j]; } } } void showGraph(MGraph&graph) { for (auto& it0 : graph.weight) { for (auto& it1 : it0) { cout << it1 << " "; } cout << endl; } } //Prim算法,得到最小生成树 vector<EData> prim(MGraph&graph,int v) {//v表示从图的第几个顶点开始 //visited标记顶点是否被访问过 vector<int>visited(graph.verxs); //把当前顶点标记为已访问 visited[v] = 1; //创建数组保存最小生成树的边 vector<EData>ret; //h1和h2记录两个顶点的下标 int h1 = -1; int h2 = -1; int minWeight = 10000;//将minWeight初始成一个大数,在遍历过程中会被替换 //因为不是单纯的一次性遍历图,而是需要回溯,每次都要重新从第一个已访问的顶点去分析与各个相邻点的权 //重 for (int k = 1; k < graph.verxs; k++) {//因为有graph.verxs个顶点,所以有graph.verx-1 //条边 //确定每一次生成的子图和那个顶点的距离最近 for (int i = 0; i < graph.verxs; i++) {//i表示已访问过的顶点 if (visited[i] == 1) { for (int j = 0; j < graph.verxs; j++) {//j表示还未访问过的顶点 if (visited[j] == 0 && graph.weight[i][j] < minWeight) { minWeight = graph.weight[i][j]; h1 = i; h2 = j; } } } } ret.push_back(EData(i,j,minWeight)); //将h2设置为已访问 visited[h2] = 1; //重新设置minWeight minWeight = 10000; } return ret; } }; int main() { string data = "ABCDEFG"; int verxs = data.length(); //邻接矩阵,10000表示两个点不连通 vector<vector<int>>weight = { {10000,5,7,10000,10000,10000,2}, {5,1000,10000,9,10000,10000,3}, {7,10000,10000,10000,8,10000,10000}, {10000,9,10000,10000,10000,4,10000}, {10000,10000,8,10000,10000,5,4}, {10000,10000,10000,4,5,10000,6}, {2,3,10000,10000,4,6,10000} }; //创建MGraph对象 MGraph graph(verxs); 创建一个MinTree对象 MinTree minTree; minTree.createGraph(graph, verxs, data, weight); minTree.showGraph(graph); minTree.prim(graph, 1); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
3.4.3 Dijkstra算法
Prim算法和Dijkstra算法十分相似,惟一的区别是: Prim算法要寻找的是离已加入顶点距离最近的顶点; Dijkstra算法是寻找离固定顶点距离最近的顶点。
方法一:普通版 class VisitedVertex { public: vector<int>already_arr;//记录各个顶点是否访问过 1-访问过,0-未访问过,会动态更新 vector<int>pre_visited;//每个下标对应的值为前一个顶点的下标,会动态更新 vector<int>dis;//记录出发顶点到其他所有顶点的距离,比如G为出发顶点,就会记录F到其他顶点的距离,会动态更新,求的最短距离就会存放到dis VisitedVertex(){} VisitedVertex(int length, int index) {//length:顶点个数 index::起始顶点下标 already_arr = vector<int>(length); pre_visited = vector<int>(length); dis = vector<int>(length); this->already_arr[index] = 1;//设置出发顶点被访问 //初始化dis数组 for (int i = 0; i < dis.size() - 1; i++) { this->dis[i] = 65535; } } //判断index顶点是否被访问过 bool in(int index) { return already_arr[index] == 1; } //更新出发顶点到index顶点的距离 void updateDis(int index, int len) { this->dis[index] = len; } //更新pre顶点的前驱顶点为index顶点 void updatePre(int pre, int index) { this->pre_visited[pre] = index; } //返回出发顶点到index顶点的距离 int getDis(int index) { return this->dis[index]; } //继续访问未访问过的顶点 int updateArr() { int min = 65535, index = 0; for (int i = 0; i < already_arr.size(); i++) { if (already_arr[i] == 0 && dis[i] < min) { min = dis[i]; index = i; } } //更新index顶点被访问过 already_arr[index] = 1; return index; } //显示最后的结果 //即将三个数组的情况输出 void show() { for (auto& it0 : already_arr) { cout << it0 << "\t"; } cout << endl; for (auto& it1 : pre_visited) { cout << it1 << "\t"; } cout << endl; for (auto& it2 : dis) { cout << it2 << "\t"; } cout << endl; } }; class Graph { private: string vertrx;//顶点数组 vector<vector<int>>matrix;//邻接矩阵 VisitedVertex vv;//已经访问的顶点的集合 public: Graph(string vertrx, vector<vector<int>>& matrix) { this->vertrx = vertrx; this->matrix = matrix; } //显示图 void showGraph() { for (auto& it0 : matrix) { for (auto& it1 : it0) { cout << it1 << "\t"; } cout << endl; } } //Dijstra算法实现 void dsj(int index) {//index:出发顶点 vv=VisitedVertex(this->vertrx.length(), index); update(index); for (int j = 0; j < vertrx.length()-1; j++) {//因为出发顶点已经处理过了,所以处理的顶点数为总顶点数-1 index = vv.updateArr(); update(index); } } //更新index顶点到周围顶点的距离和周围顶点的前驱顶点 void update(int index) { int len = 0; //根据遍历邻接矩阵的matrix[index]行 for (int j = 0; j < matrix[index].size(); j++) { //len:出发顶点到index顶点的距离+从index顶点到j顶点的距离 len = vv.getDis(index) + matrix[index][j]; //如果j顶点没被访问过,并且len小于出发顶点到j顶点的距离,就需要更新 if (!vv.in(j) && len < vv.getDis(j)) { vv.updatePre(j, index);//更新j顶点的前驱顶点为index顶点 vv.updateDis(j, len);//更新出发顶点到j顶点的距离 } } } void showDijstra() { vv.show(); } }; int main() { string vertrx = "ABCDEFG"; int N = 65535;//表示不连通 //邻接矩阵 vector<vector<int>>matrix = { {N,5,7,N,N,N,2}, {5,N,N,9,N,N,3}, {7,N,N,N,8,N,N}, {N,9,N,N,N,4,N}, {N,N,8,N,N,5,4}, {N,N,N,4,5,N,6}, {2,3,N,N,4,6,N} }; Graph graph(vertrx, matrix); graph.dsj(6); graph.showDijstra(); } 方法二:优化版(小根堆) 思路: 1.设出发点到其他点的距离都为INT_MAX 2.利用小根堆不断更新出发点到其他点的最小权重路径:不需要遍历了,直接访问堆顶即可 3.系统的堆无法满足我们的要求:改变某一个值后重新排序变成小根堆 class Node; class Edge { public: int weight;//权重 Node* from = NULL;//出发点 Node* to;//终点 Edge(int weight, Node* from, Node* to) { this->weight = weight; this->from = from; this->to = to; } }; class Node { public: int value;//结点值 int in;//入度 int out;//出度 vector<Node*>nexts;//相邻结点 vector<Edge>edges;//相邻边 Node(int value) { this->value = value; in = 0; out = 0; } }; class NodeRecord { public: Node* node; int distance; NodeRecord(Node* node, int distance) { this->node = node; this->distance = distance; } }; class NodeHeap { private: vector<Node*>nodes; map<Node*, int>heapIndexMap;//存放结点对应索引 map<Node*, int>distanceMap;//存放结点和起点的距离 int size; public: NodeHeap(int size) { nodes = vector<Node*>(size); this->size = 0;//设置为0,方便后续直接在nodes[size]插入新结点 } bool isEmpty() { return size == 0; } void addOrUpdateOrIgnore(Node* node, int distance) { //update if (inHeap(node)) { distanceMap[node] = min(distanceMap[node], distance); insertHeapify(node,heapIndexMap[node]); } //add if (!isEntered(node)) { nodes[size] = node; heapIndexMap[node] = size; distance[node] = distance; insertHeapify(node,size++); } //ignore:什么也不做 } NodeRecord pop() { NodeRecord nodeRecord(nodes[0], distanceMap[nodes[0]]);//记录堆顶信息 swap(0, size - 1); heapIndexMap[nodes[size - 1]] = -1; distanceMap.erase(nodes[size - 1]); delete nodes[size - 1]; //重新调整树结构 heapify(0, --size); return nodeRecord; } void insertHeapify(Node*node,int index) { while (distanceMap[nodes[index]] < distanceMap[nodes[(index - 1) / 2]]) { swap(index, (index - 1) / 2); index = (index - 1) / 2; } } //从index开始调整 void heapify(int index, int size) { int left = index * 2 + 1; int right = left + 1; //因为循环条件需要left,所以必须在循环之前就定义好left while (left < size) { //right要在冒号前,因为是&&,任意有一个不满足都会赋值后者,因此我们要保证“一致性” int smallest = right < size&& distanceMap[nodes[right]] < distanceMap[nodes[left]] ? right : left; smallest = distanceMap[nodes[smallest]] < distanceMap[nodes[index]] ? smallest : index; if (smallest == index)break;//如果父结点就是最小的,那么不用做任何处理 swap(smallest, index); index = smallest; left = index * 2 + 1; right = left + 1; } } bool isEntered(Node* node) { return heapIndexMap.find(node) != heapIndexMap.end(); } bool inHeap(Node* node) { return isEntered(node) && heapIndexMap[node] != -1; } void swap(int index1, int index2) { heapIndexMap[nodes[index1]] = index2; heapIndexMap[nodes[index2]] = index1; Node* tmp = nodes[index1]; nodes[index1] = nodes[index2]; nodes[index2] = tmp; } }; map<Node*, int> djs2(Node* head, int size) { NodeHeap nodeHeap(size); nodeHeap.addOrUpdateOrIgnore(head, 0); map<Node*, int>res; while (!nodeHeap.isEmpty()) { NodeRecord record = nodeHeap.pop(); Node* cur = record.node; int distance = record.distance; for (Edge& edge : cur->edges) { nodeHeap.addOrUpdateOrIgnore(edge.to, distance + edge.weight); } res[cur] = distance;//会不断更新成最小值,直到不能再更新时,nodeHeap会不断地pop而不会add了 } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
- 233
- 234
- 235
- 236
- 237
- 238
- 239
- 240
- 241
- 242
- 243
- 244
- 245
- 246
- 247
- 248
- 249
- 250
- 251
- 252
- 253
- 254
- 255
- 256
- 257
- 258
- 259
- 260
- 261
- 262
- 263
- 264
- 265
- 266
- 267
- 268
- 269
- 270
- 271
- 272
- 273
- 274
- 275
- 276
- 277
- 278
- 279
- 280
- 281
- 282
- 283
- 284
- 285
- 286
- 287
- 288
- 289
- 290
- 291
- 292
- 293
- 294
3.5 N皇后

方法一:普通版 int num1(int n) { if (n < 1) { return 0; } vector<int>record(n);//表明在第i行的皇后在第几列 return process1(0, record, n); } //判断i行j列的皇后是否有效 bool isValid(vector<int>& record, int i, int j) {//只用和i行之前的判断 for (int k = 0; j < i; k++) { if (record[k] == j || abs(i - k) == abs(j - record[k]))return false; } return true; } //i表示目前来到了第i行 //record表示之前放过的皇后的位置 //n代表共有多少行 //返回值表示摆完所有的皇后,合理的摆法有多少种 int process1(int i, vector<int>& record, int n) { if (i == n)return 1;//终止行,i能到n,说明前面的都合法 int res = 0; for (int j = 0; j < n; j++) {//测试第i行的所有列 //找合理位置 if (isValid(record, i, j)) { record[i] = j; res += process1(i + 1, record, n); } } return res; } 方法二:常数优化版(利用位运算) 因为是位运算,所以尽量不要超过32位 int num2(int n) { if (n < 1||n>32) { return 0; } //生成一个二进制的数 int limit = n == 32 ? -1 : (1 << n) - 1; //能在limit中,位上的值为1上尝试放皇后,且一开始没有限制,所以全为0 return process2(limit, 0, 0, 0); } //colLim列的限制,1的位置不能放皇后,0的位置可以 //leftDiaLim左斜线的限制,1的位置不能放皇后,0的位置可以 //rightDiaLim右斜线的限制,1的位置不能放皇后,0的位置可以 int process2(int limit, int colLim, int leftDiaLim, int rightDiaLim) { if (colLim == limit) {//base case,colLim能递归到全为1,说明前面所有放置的皇后都合法 return 1; } int mostRightOne = 0; // | 保留1,& 保留0,不要忘记最高位还有一个0,取反后变成1,需要让其和limit做&运算变回0 int pos = limit & (~(colLim | leftDiaLim | rightDiaLim));//保留所有能够填皇后的列--1 int res = 0; while (pos != 0) { //在最右侧放皇后 mostRightOne = pos & (~pos + 1); pos = pos - mostRightOne; //同时还保留了之前行对下面行的限制,注:右移是逻辑右移,因为保证左边0不变 res += process2(limit, colLim | mostRightOne, (leftDiaLim | mostRightOne) << 1, (rightDiaLim | mostRightOne) >> 1); } return res; } C++中,signed类型默认逻辑右移:即直接补0;unsigned类型默认算数右移:保留符号位0。重定义类型即可切换。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
4.前缀树
何为前缀树?

前缀树的功能: 1.判断是否加入过某些字符串 2.计算以某字符串为前缀的字符串有几个 //定义结点 class TrieNode { public: //遍历所有字符串后 int pass;//穿过该结点次数 int end;//如果是终点,则end=1,从而可以用来判断是否加过某些字符串 vector<TrieNode*>nexts;//存放该结点的后序结点,索引就是路 //如果是多字符的情况,可以换成哈希表,key代表路,value代表路通往的结点 TrieNode() { pass = 0; end = 0; //nexts[0]==NULL,没有走向a的路 //nexts[0]!=NULL,有走向a的路 nexts = vector<TrieNode*>(26);//a~z,路是提前建好的,通过指针是否为空来判断路的存在 } }; //定义前缀树 class Trie { private: //根结点的pass值代表有多少个字符串以空串""作为前缀(所有字符串),end代表有几个空串 TrieNode* root; public: Trie() { root = new TrieNode(); } //插入字符串 void insert(string word) { if (word.length() == NULL)return; TrieNode* node = root; node->pass++; int index = 0; for (int i = 0; i < word.length(); i++) { index = word[i] - 'a';//计算应走哪一条路 if (node->nexts[index] == NULL)node->nexts[index] = new TrieNode(); node = node->nexts[index]; node->pass++; } //结束循环后,node指向word路径的终点 node->end++; } //查询word这个单词加入过几次 int search(string word) { if (word.length() == 0) { return root->end; } TrieNode* node = root; int index = 0; for (int i = 0; i < word.length(); i++) { index = word[i] - 'a'; if (node->nexts[index] == NULL) { return 0; } node = node->nexts[index]; } return node->end; } //所有加入的字符串中,有几个是以pre这个字符串作为前缀的 int prefixNumber(string pre) { if (pre.length() == 0) { return root->end; } TrieNode* node = root; int index = 0; for (int i = 0; i < pre.length(); i++) { index = pre[i] - 'a'; if (node->nexts[index] == NULL) { return 0; } node = node->nexts[index]; } return node->pass; } void deleteWord(string word) { if (search(word) != 0) {//确认加入过word,才删除 TrieNode* node = root; node->pass--; int index = 0; TrieNode* fatherNode = NULL; int deleteIndex = -1; set<TrieNode*>deleteSet; for (int i = 0; i < word.length(); i++) { index = word[i] - 'a'; if (--node->nexts[index] == 0) { //记录第一个要删去结点的父节点 fatherNode = fatherNode == NULL ? node : fatherNode; deleteIndex = deleteIndex == -1 ? index : deleteIndex; //记录所有要删去的结点 deleteSet.insert(node->nexts[index]); } node = node->nexts[index]; } node->end--; fatherNode->nexts[deleteIndex] = NULL; for (auto deleteNode : deleteSet) { deleteNode = NULL; } } } }; 删除结点时的误区:误以为只要将第一个pass=0的结点置空即可,实际上不对。因为后面还有结点pass=1,等待被删除, 所以,应该把所有待删除结点放入到一个容器先,循环结束后再去遍历该容器一个一个置空结点。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
5.贪心算法
5.1 定义

5.2 1353. 最多可以参加的会议数目

class Program { public: int start; int end; Program(int start, int end) { this->start = start; this->end = end; } }; bool programCompare(Program& p1, Program& p2) { return p1.end < p2.end; } int bestArrange(vector<Program>& programs, int timePoint) { sort(programs.begin(), programs.end(), programCompare); int res = 0; for (int i = 0; i < programs.size(); i++) { if (timePoint <= programs[i].start) { res++; timePoint = programs[i].end; } } return res; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
5.3 解题套路

**对数器:**对数器是通过用大量测试数据来验证算法是否正确的一种方式。
5.4 最小字典序
问题:将所有字符串拼接起来,如何保证拼接完之后的字符串字典序最低? 贪心策略:a.b<=b.a,a,b都为字符串 有效比较策略:原始数据相对位置无论怎么改变,排完序之后的数据位置是固定的 证明: To show:a.b<=b.a,b.c<=c.b => a.c<=c.a 1. 把string看作k进制数,因为数才好比较=>a.b=a*k^b.length()+b 2. k^b.length()=m(b) 3. a.b<=b.a :a*m(b)+b<=b*m(a)+a 4. b.c<=c.b :b*m(c)+c<=c*m(b)+b 5. 由3、4可得:a*m(c)+c<=c*m(a)+a 6. 以上只能证明策略可以排序出一个唯一序列 7. 证明排好序后的序列任意两个字符串交换顺序,新的字符总串的字典序大于旧的 8. 一路和相邻的字符串交换,利用数学归纳法 bool stringCompare(string a, string b) { return a + b <= b + a; } string lowestString(vector<string>& strs) { if (strs.size() == 0) { return ""; } sort(strs.begin(), strs.end(), stringCompare); string res; for (int i = 0; i < strs.size(); i++) { res += strs[i]; } return res; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
5.5 分割金条

赫夫曼编码 int lessMoney(vector<int>& vec) { priority_queue<int, vector<int>, greater<int>>pQ; for (int i = 0; i < vec.size(); i++) { pQ.push(vec[i]); } int sum = 0; int cur = 0; while (pQ.size() > 1) { cur = 0; cur += pQ.top(); pQ.pop(); cur += pQ.top(); pQ.pop(); sum += cur; pQ.push(cur); } return sum; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
5.6 最大钱数

class Project { public: int profit; int cost; Project(int profit, int cost) { this->profit = profit; this->cost = cost; } }; class CostCompare { public: bool compare(Project& p1, Project& p2) { return p1.cost < p2.cost; } }; class ProfitCompare { public: bool compare(Project& p1, Project& p2) { return p1.profit > p2.profit; } }; int findMaximizedCapital(int k, int w, vector<int>& Profits, vector<int>& Capital) { priority_queue<Project, vector<Project>, CostCompare>minCostQ;//存放成本最小的 priority_queue<Project, vector<Project>, ProfitCompare>maxProfitQ;//存放利润最大的 for (int i = 0; i < Profits.size(); i++) { minCostQ.push(Project(Profits[i], Capital[i])); } for (int i = 0; i < k; i++) { while (!minCostQ.empty() && minCostQ.top().cost <= w) { maxProfitQ.push(minCostQ.top()); minCostQ.pop(); } if (maxProfitQ.empty())return w;//没有可以做的项目了 w += maxProfitQ.top().profit; maxProfitQ.pop(); } return w; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
5.7 剑指 Offer 41. 数据流中的中位数

思路: 1. 准备一个小根堆和大根堆 2. 两个堆都为空时,默认放入大根堆 3. 判断cur<=大根堆堆顶 3.1 是:cur入大根堆 3.2 否:cur入小根堆 4. 判断两堆大小差距,超过2:较大的堆堆顶弹出放入另一个堆里 5. 最终:较小的n/2个数在大根堆,较大的n/2个数在小根堆里 class MedianFinder{ public: priority_queue<int, vector<int>, less<int>>maxHeap; priority_queue<int, vector<int>, greater<int>>minHeap; void addNum(int num) { if (maxHeap.empty() || num <= maxHeap.top()) { maxHeap.push(num); } else { minHeap.push(num); } if (maxHeap.size() == minHeap.size() + 2) { minHeap.push(maxHeap.top()); maxHeap.pop(); } if (minHeap.size() == maxHeap.size() + 2) { maxHeap.push(minHeap.top()); minHeap.pop(); } } double findMedian() { int maxHeapSize=maxHeap.size(); int minHeapSize=minHeap.size(); if(((maxHeapSize+minHeapSize)&1)==0)return (maxHeap.top()+minHeap.top())*0.5; return maxHeapSize>minHeapSize?maxHeap.top():minHeap.top(); } };
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
6.暴力递归
6.1 定义

6.2 打印字符串子序列/子集(无序)

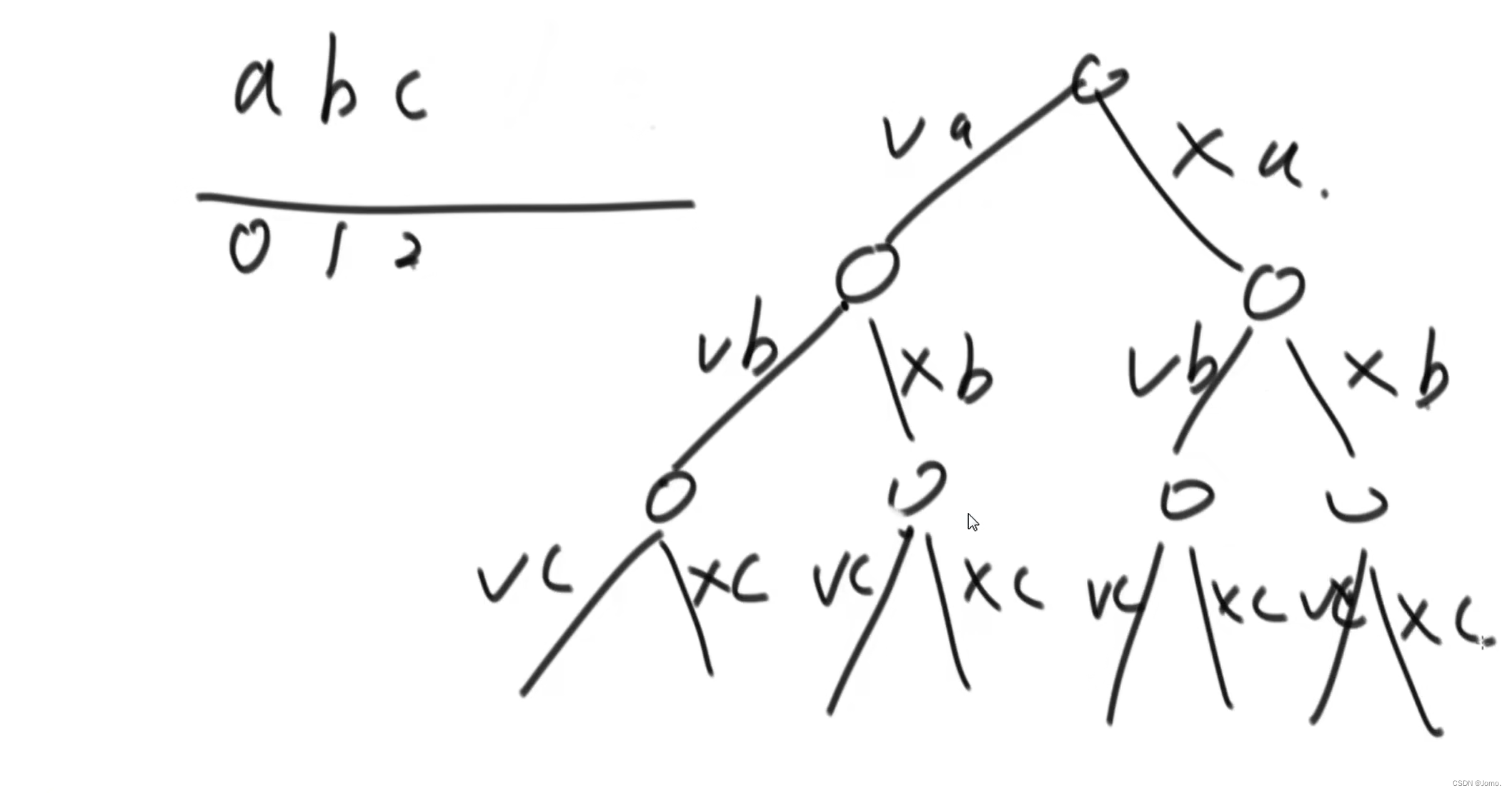
方法一:普通版剑指 Offer 38. 字符串的排列 void process(string str, int i, string res) { if (i == str.length()) {//base case cout<<res<<endl; return; } string resKeep = res; resKeep += str[i]; process(str, i + 1, resKeep);//选择当前字符 string resNoInclude = res; process(str, i + 1, resNoInclude);//不选择当前字符 } 方法二:省空间版 void process(string str, int i) { if (i == str.length()) { cout << str << endl; return; } process(str, i + 1);//选择当前字符 char tmp = str[i]; str[i] = '\0'; process(str, i + 1);//不选择当前字符 str[i] = tmp;//恢复 }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
6.3 打印字符串全排列

//str[i...]范围上,所有的字符都可以在i位置上,后续都可以去尝试
//str[0...i-1]范围上,是之前做的选择
//请把所有的字符串形成的全排列,加入到res中
void process(string str, int i, vector<string>& res) {
if (i == str.length()) {
res.push_back(str);
}
for (int j = i; j < str.length(); j++) {
swap(str[i], str[j]);
process(str, i + 1, res);
swap(str[i], str[j]);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
6.4 打印字符串全排列(不重复)
void process(string str, int i, vector<string>& res) {
if (i == str.length()) {
res.push_back(str);
}
vector<bool>visit(26);//判断26个字母是否被访问过
for (int j = i; j < str.length(); j++) {
if(!visit[str[j]-'a']){
visit[str[j]-'a']=true;
swap(str[i], str[j]);
process(str, i + 1, res);
swap(str[i], str[j]);
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
6.5 拿牌

int win1(vector<int>& arr) { return max(f(arr, 0, arr.size() - 1), s(arr, 0, arr.size() - 1)); } //先手 int f(vector<int>& arr, int L, int R) { if (L == R)return arr[L]; //先手有主动权,必定让自己拿到最多的分数 return max(arr[L] + s(arr, L + 1, R), arr[R] + s(arr, L, R - 1)); } //后手 int s(vector<int>& arr, int L, int R) { if (L == R)return 0; //后手被动,对手肯定会让我们获取最低分数 return min(f(arr, L + 1, R), f(arr, L, R - 1)); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
6.6 逆序栈

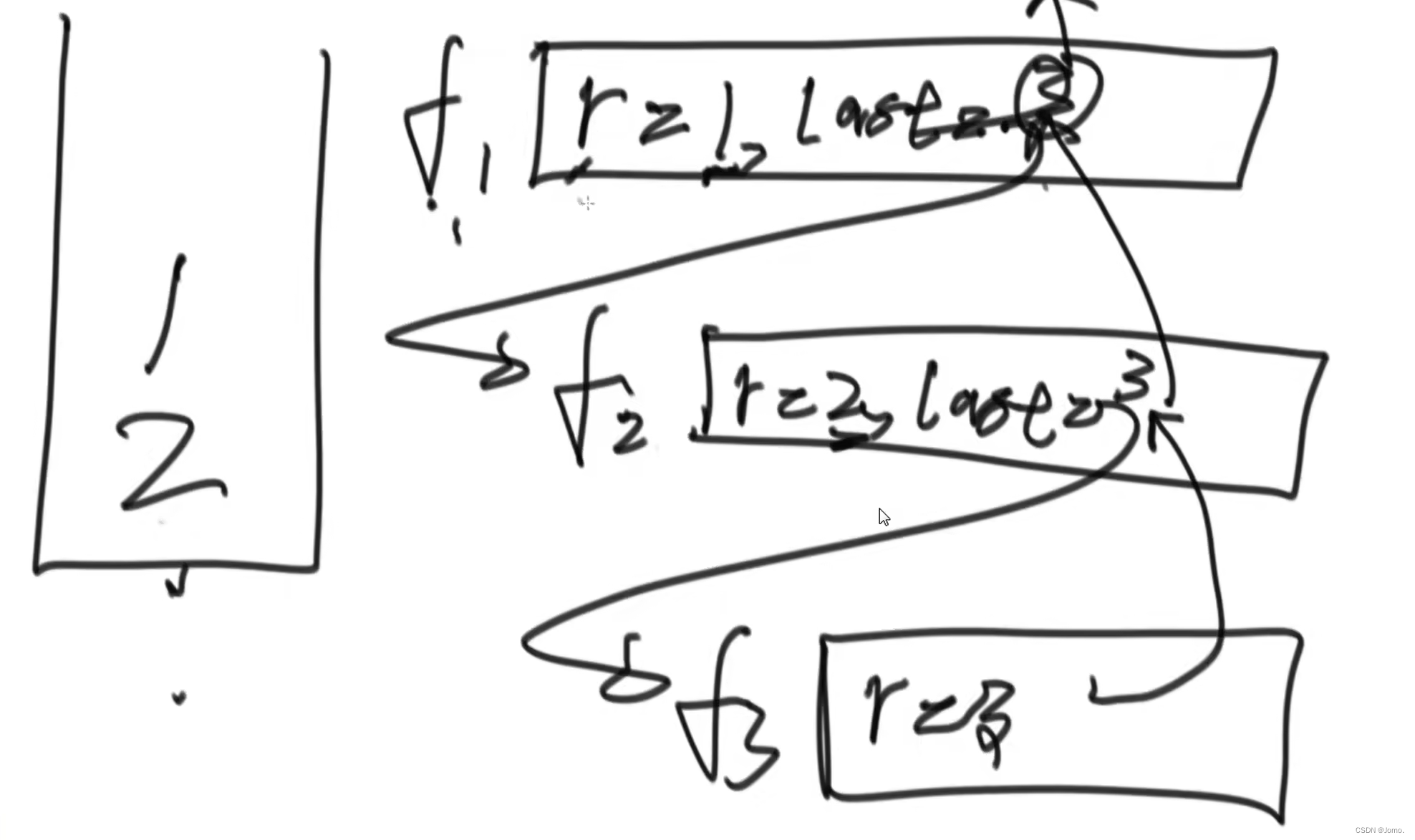
//取出栈底 int f(stack<int>&stk) { int result = stk.top(); stk.pop(); if (stk.empty())return result; else { int last = f(stk); stk.push(result); return last; } } void reverse(stack<int>&stk){ if(stk.empty())return; int i=f(stk); reverse(stk); stk.push(i); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
6.7 数转字符串

思路: s[i]之前有多少种结果是已经确定的 1. s[i]=0,只能尝试与s[i-1]组合 2. s[i]=1,一定可以和s[i+1]组合 3. s[i]=2,判断s[i+1]是否大于6 //i之前的位置如果转化已经做过判断了且有效 int process(string str, int i) { //能到最后一个字符说明s[i]之前的字符转化都是有效的,因此已经固定有1种了 if (i == str.length())return 1; if (str[i] == '0')return 0; if (str[i] == '1') { int res = process(str, i + 1);//i作为单独的部分 if (i + 1 < str.length()) { res += process(str, i + 2);//(i,i+1)看作一个整体 } return res; } if (str[i] == '2') { int res = process(str, i + 1); if (i + 1 < str.length() && str[i + 1] >= '0' && str[i + 1] <= '6') { res += process(str, i + 2); } return res; } //str[i]=='3'~'9' return process(str, i + 1); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
6.8 载物

思路:从左往右一个一个试,max(选择,不选择)
int process(vector<int>&weights, vector<int>&values, int i, int alreadyweight,int alreadyvalue, int bag) {
if (alreadyweight > bag)return 0;//超重,该方案根本不应该存在
if (i == weights.size())return alreadyvalue;//越界
return max(process(weights, values, i + 1, alreadyweight,alreadyvalue, bag),
process(weights, values, i + 1, alreadyweight + weights[i], alreadyvalue+ values[i],bag));
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/小惠珠哦/article/detail/786654
推荐阅读
相关标签

