
- 1php异步上传图片并创建文件夹保存_php 储存上传的图片
- 2背包问题(416,494,474,322,518,139)_python给你一个 只包含正整数 的 非空 数组 nums 。请你判断是否可以将这个数组分
- 3python3GUI--微博图片爬取工具V1.5(附源码)_微博爬虫gui程序
- 4斯坦福抄袭清华、面壁智能大模型,当事人已道歉、删项目
- 5U3D需要用到的数学基础知识_unity跑酷游戏中有哪些数学原理
- 6android 命令(adb shell)进入指定模拟器或设备_adb -s emulator-5554(模拟器名) shell #打开模拟器的shell
- 7数据百问系列:经典数据结构和算法在数据科学中的作用?
- 8yarn 修改全局安装目录_MapReduce&YARN
- 9区块链基础之共识机制_pow共识机制
- 10python代码大全可复制免费,python简单编程小游戏_小游戏免费秒玩代码
Flink Kafka-Source_flink kafkasource
赞
踩
- Apache Kafka 连接器
Flink 提供了 Apache Kafka 连接器使用精确一次(Exactly-once)的语义在 Kafka topic 中读取和写入数据。 - 依赖
<!-- flink kakfa -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
- 1
- 2
- 3
- 4
- 5
- 6
Kafka Source
1. 使用方法
Kafka Source 提供了构建类来创建 KafkaSource 的实例。以下代码片段展示了如何构建 KafkaSource 来消费 “input-topic” 最早位点的数据, 使用消费组 “my-group”,并且将 Kafka 消息体反序列化为字符串:
KafkaSource<String> source = KafkaSource.<String>builder()
.setBootstrapServers(brokers)
.setTopics("input-topic")
.setGroupId("my-group")
.setStartingOffsets(OffsetsInitializer.earliest())
.setValueOnlyDeserializer(new SimpleStringSchema())
.build();
env.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka Source");
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
2. Topic / Partition 订阅
以下属性在构建 KafkaSource 时是必须指定的:
- Bootstrap server,通过 setBootstrapServers(String) 方法配置
- 消费者组 ID,通过 setGroupId(String) 配置
- 要订阅的 Topic / Partition,请参阅 Topic / Partition 订阅一节
- 用于解析 Kafka 消息的反序列化器(Deserializer),请参阅消息解析一节
Kafka Source 提供了 3 种 Topic / Partition 的订阅方式:
- Topic 列表,订阅 Topic 列表中所有 Partition 的消息:
KafkaSource.builder().setTopics("topic-a", "topic-b");
- 1
- 正则表达式匹配,订阅与正则表达式所匹配的 Topic 下的所有 Partition:
KafkaSource.builder().setTopicPattern("topic.*");
- 1
- Partition 列表,订阅指定的 Partition:
final HashSet<TopicPartition> partitionSet = new HashSet<>(Arrays.asList(
new TopicPartition("topic-a", 0), // Partition 0 of topic "topic-a"
new TopicPartition("topic-b", 5))); // Partition 5 of topic "topic-b"
KafkaSource.builder().setPartitions(partitionSet);
- 1
- 2
- 3
- 4
3. 消息解析
代码中需要提供一个反序列化器(Deserializer)来对 Kafka 的消息进行解析。 反序列化器通过 setDeserializer(KafkaRecordDeserializationSchema) 来指定,其中 KafkaRecordDeserializationSchema 定义了如何解析 Kafka 的 ConsumerRecord。
如果只需要 Kafka 消息中的消息体(value)部分的数据,可以使用 KafkaSource 构建类中的 setValueOnlyDeserializer(DeserializationSchema) 方法,其中 DeserializationSchema 定义了如何解析 Kafka 消息体中的二进制数据。
也可使用 Kafka 提供的解析器 来解析 Kafka 消息体。例如使用 StringDeserializer 来将 Kafka 消息体解析成字符串:
import org.apache.kafka.common.serialization.StringDeserializer;
KafkaSource.<String>builder()
.setDeserializer(KafkaRecordDeserializationSchema.valueOnly(StringDeserializer.class));
- 1
- 2
- 3
- 4
4. 起始消费位点
Kafka source 能够通过位点初始化器(OffsetsInitializer)来指定从不同的偏移量开始消费 。内置的位点初始化器包括:
KafkaSource.builder()
// 从消费组提交的位点开始消费,不指定位点重置策略
.setStartingOffsets(OffsetsInitializer.committedOffsets())
// 从消费组提交的位点开始消费,如果提交位点不存在,使用最早位点
.setStartingOffsets(OffsetsInitializer.committedOffsets(OffsetResetStrategy.EARLIEST))
// 从时间戳大于等于指定时间戳(毫秒)的数据开始消费
.setStartingOffsets(OffsetsInitializer.timestamp(1657256176000L))
// 从最早位点开始消费
.setStartingOffsets(OffsetsInitializer.earliest())
// 从最末尾位点开始消费
.setStartingOffsets(OffsetsInitializer.latest());
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
如果内置的初始化器不能满足需求,也可以实现自定义的位点初始化器(OffsetsInitializer),如果未指定位点初始化器,将默认使用 OffsetsInitializer.earliest();
5. 有界 / 无界模式
Kafka Source 支持流式和批式两种运行模式。默认情况下,KafkaSource 设置为以流模式运行,因此作业永远不会停止,直到 Flink 作业失败或被取消。 可以使用 setBounded(OffsetsInitializer) 指定停止偏移量使 Kafka Source 以批处理模式运行。当所有分区都达到其停止偏移量时,Kafka Source 会退出运行。
流模式下运行通过使用 setUnbounded(OffsetsInitializer) 也可以指定停止消费位点,当所有分区达到其指定的停止偏移量时,Kafka Source 会退出运行。
6. 其他属性
除了上述属性之外,您还可以使用 setProperties(Properties) 和 setProperty(String, String) 为 Kafka Source 和 Kafka Consumer 设置任意属性。KafkaSource 有以下配置项:
- client.id.prefix,指定用于 Kafka Consumer 的客户端 ID 前缀
- partition.discovery.interval.ms,定义 Kafka Source 检查新分区的时间间隔。
- register.consumer.metrics 指定是否在 Flink 中注册 Kafka Consumer 的指标
- commit.offsets.on.checkpoint 指定是否在进行 checkpoint 时将消费位点提交至 Kafka broker
请注意,即使指定了以下配置项,构建器也会将其覆盖:
- key.deserializer 始终设置为 ByteArrayDeserializer
- value.deserializer 始终设置为 ByteArrayDeserializer
- auto.offset.reset.strategy 被 OffsetsInitializer#getAutoOffsetResetStrategy() 覆盖
- partition.discovery.interval.ms 会在批模式下被覆盖为 -1
7. 动态分区检查
为了在不重启 Flink 作业的情况下处理 Topic 扩容或新建 Topic 等场景,可以将 Kafka Source 配置为在提供的 Topic / Partition 订阅模式下定期检查新分区。要启用动态分区检查,请将 partition.discovery.interval.ms 设置为非负值:
KafkaSource.builder()
.setProperty("partition.discovery.interval.ms", "10000"); // 每 10 秒检查一次新分区
- 1
- 2
分区检查功能默认不开启。需要显式地设置分区检查间隔才能启用此功能。
8. 事件时间和水印
默认情况下,Kafka Source 使用 Kafka 消息中的时间戳作为事件时间。您可以定义自己的水印策略(Watermark Strategy) 以从消息中提取事件时间,并向下游发送水印:
env.fromSource(kafkaSource, new CustomWatermarkStrategy(), "Kafka Source With Custom Watermark Strategy");
- 1
9. 空闲
如果并行度高于分区数,Kafka Source 不会自动进入空闲状态。您将需要降低并行度或向水印策略添加空闲超时。如果在这段时间内没有记录在流的分区中流动,则该分区被视为“空闲”并且不会阻止下游操作符中水印的进度。
10. 消费位点提交
Kafka source 在 checkpoint 完成时提交当前的消费位点 ,以保证 Flink 的 checkpoint 状态和 Kafka broker 上的提交位点一致。如果未开启 checkpoint,Kafka source 依赖于 Kafka consumer 内部的位点定时自动提交逻辑,自动提交功能由 enable.auto.commit 和 auto.commit.interval.ms 两个 Kafka consumer 配置项进行配置。
注意:Kafka source 不依赖于 broker 上提交的位点来恢复失败的作业。提交位点只是为了上报 Kafka consumer 和消费组的消费进度,以在 broker 端进行监控。
11. 监控
Kafka source 会在不同的中汇报下列指标。
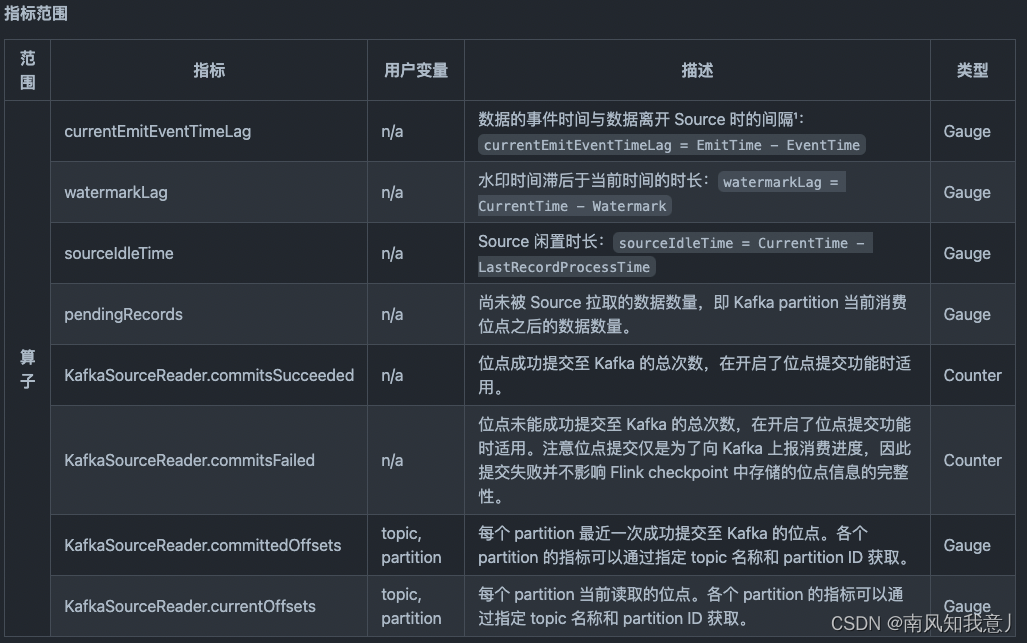
该指标反映了最后一条数据的瞬时值。之所以提供瞬时值是因为统计延迟直方图会消耗更多资源,瞬时值通常足以很好地反映延迟
12. 安全
要启用加密和认证相关的安全配置,只需将安全配置作为其他属性配置在 Kafka source 上即可。下面的代码片段展示了如何配置 Kafka source 以使用 PLAIN 作为 SASL 机制并提供 JAAS 配置:
KafkaSource.builder()
.setProperty("security.protocol", "SASL_PLAINTEXT")
.setProperty("sasl.mechanism", "PLAIN")
.setProperty("sasl.jaas.config", "org.apache.kafka.common.security.plain.PlainLoginModule required username=\"username\" password=\"password\";");
- 1
- 2
- 3
- 4
另一个更复杂的例子,使用 SASL_SSL 作为安全协议并使用 SCRAM-SHA-256 作为 SASL 机制:
KafkaSource.builder()
.setProperty("security.protocol", "SASL_SSL")
// SSL 配置
// 配置服务端提供的 truststore (CA 证书) 的路径
.setProperty("ssl.truststore.location", "/path/to/kafka.client.truststore.jks")
.setProperty("ssl.truststore.password", "test1234")
// 如果要求客户端认证,则需要配置 keystore (私钥) 的路径
.setProperty("ssl.keystore.location", "/path/to/kafka.client.keystore.jks")
.setProperty("ssl.keystore.password", "test1234")
// SASL 配置
// 将 SASL 机制配置为 as SCRAM-SHA-256
.setProperty("sasl.mechanism", "SCRAM-SHA-256")
// 配置 JAAS
.setProperty("sasl.jaas.config", "org.apache.kafka.common.security.scram.ScramLoginModule required username=\"username\" password=\"password\";");
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
如果在作业 JAR 中 Kafka 客户端依赖的类路径被重置了(relocate class),登录模块(login module)的类路径可能会不同,因此请根据登录模块在 JAR 中实际的类路径来改写以上配置。

