- 1spring-cloud-kubernetes与SpringCloud Gateway_kubernates gateway spring cloud gateway
- 2雷达信号的检测-恒虚警率处理_雷达快门限和慢门限区别
- 3Python Cookbook(第3版)pdf
- 4链队列的出队,入队_链队列的入队和出队
- 5Git常用命令和GUI工具_gui常用命令
- 6win10使用ssh连接linux、更换yum源_ssh 换源
- 7顺序表ArrayList_arraylist顺序
- 8『哈哥赠书 - 54期』-『架构思维:从程序员到CTO』
- 9用深度强化学习玩FlappyBird_强化学习玩游戏
- 10基于FPGA的数字信号处理【1.3】
flink-安装以及可视化界面的简单使用_flink submit new job
赞
踩
简易安装Flink
flink的运行需要依赖JDK的环境,所以无论以何种方式安装flink,首先要确保环境中的JDK能正常使用
说明:此笔记中的所有内容都是以Linux系统进行演示
一、基于Flink包进行安装
1、安装openJDK
#下载
$ apt install openjdk-11-jdk
#配置全局环境
$ gedit ~/.bashrc
#将配置写入配置文件中
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
#检查安装结果
$ java -version
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14

2、安装Flink
下载地址:https://www.apache.org/dyn/closer.lua/flink/flink-1.13.6/flink-1.13.6-bin-scala_2.12.tgz
- 将下好的安装包放入一个任意的文件夹中进行解压
bin:该目录包含flink的二进制文件
conf: 该目录存放了flink的配置文件
examples: 该目录存放了flink的示例应用程序
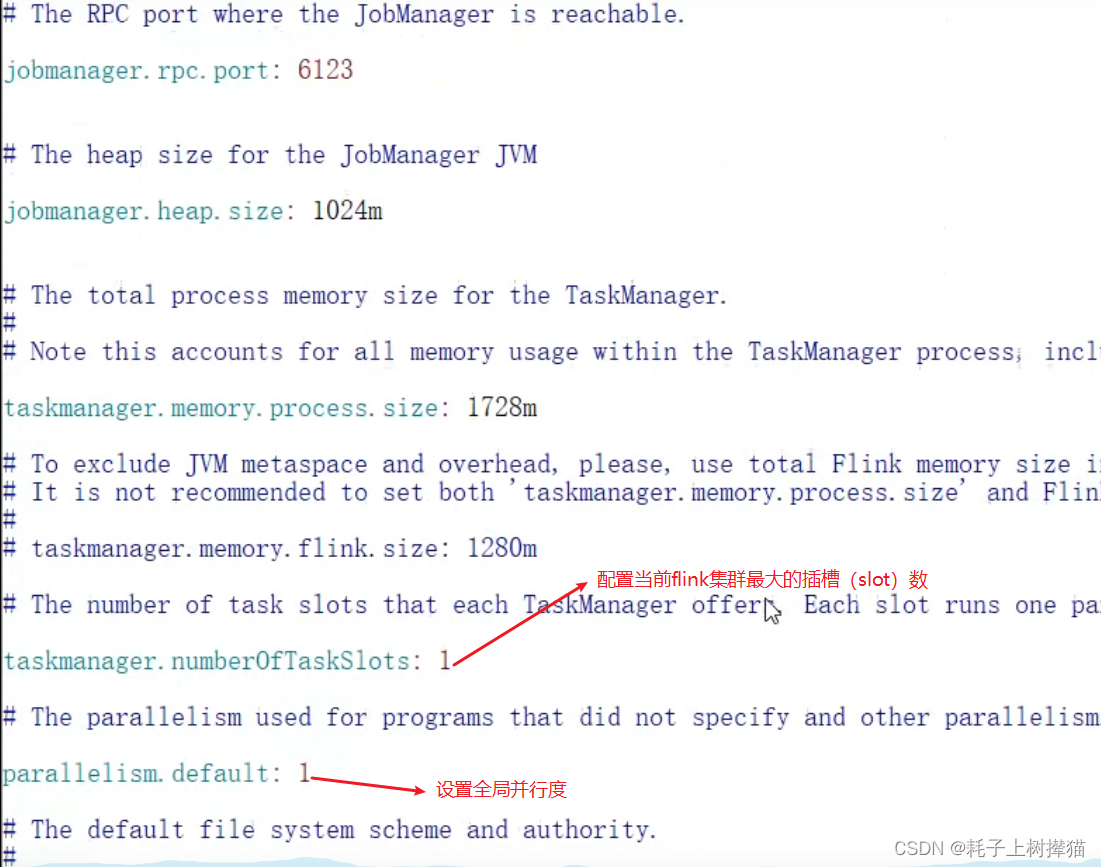
在conf中修改flink-conf.yaml
- 操作local cluster
$ ./bin/start-cluster.sh
- 1

看到这些信息说明flink已经在后台运行,可以使用一下命令查看:
$ ps aux | grep flink
- 1
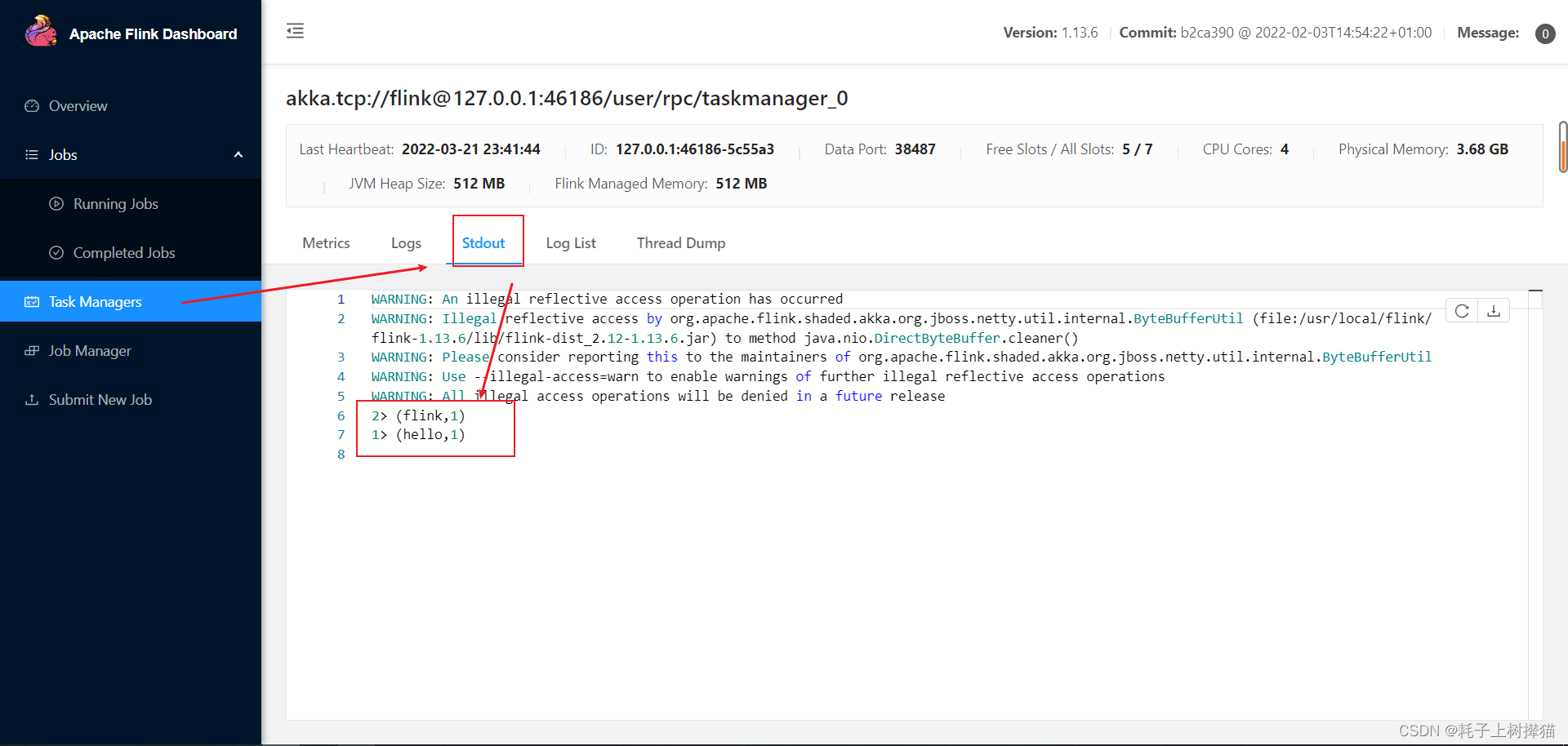
并且这个时候可以通过访问IP:8081访问flink的可视化界面,查看正在运行的集群成员
最后,如果要停止flink的cluster,可以使用以下命令:
$ ./bin/stop-cluster.sh
- 1
- 提交一个Flink Job
Flink提供了一个CLI工具bin/ Flink,它可以运行打包为Java archive (JAR)的程序并控制它们的执行。提交作业意味着将作业的JAR文件和相关依赖项上传到正在运行的Flink集群并执行它。
Flink发行版附带了示例jar,您可以在examples/文件夹中找到这些jar。要将WordCount.jar部署到正在运行的集群,请执行以下命令:
$ ./bin/flink run examples/streaming/WordCount.jar
- 1
通过查看日志信息,可以验证输出结果。
$ tail log/flink-*-taskexecutor-*.out
- 1

二、使用docker
1、使用docker-hub中提供的镜像
#搜索镜像
$ docker search flink
- 1
- 2
#拉取镜像
$ docker pull flink:[指定版本] #不指定版本,默认拉取最新版本
$ docker images #拉取成功后可使用该命令查看拉取成功的镜像
- 1
- 2
- 3
- 4
#启动flink容器
$ docker run -t -d --name jobmanager --network host -e JOB_MANAGER_RPC_ADDRESS=jmr -p 8081:8081 flink:1.14.4-scala_2.12-java8 jobmanager
#查看已启动的容器
$ docker ps
- 1
- 2
- 3
- 4
- 5

2、使用dockerfile自己自定义镜像
我在测试时,是使用的centos7作为基础镜像,然后在该镜像上安装JDK以及Flink。其实,flink的运行只要依赖于JDK就可以,那我们其实可以已JDK作为基础镜像去构建出自定义镜像。
准备:
JDK :openjdk-11+28_linux-x64_bin.tar.gz
flink:flink-1.13.6-bin-scala_2.12.tgz
准备一个文件夹,将我们要用到的包以及dockerfile文件放在一起

编写dockerfile文件
FROM centos:7 ADD flink-1.13.6-bin-scala_2.12.tgz /usr/local ADD openjdk-11+28_linux-x64_bin.tar.gz /usr/local RUN yum -y install vim ENV MYPATH /usr/local WORKDIR $MYPATH ENV JAVA_HOME /usr/local/jdk-11 ENV PATH $PATH:$JAVA_HOME/bin EXPOSE 8081 CMD /usr/local/flink-1.13.6/bin/start-cluster.sh && tail -F /usr/local/flink-1.13.6/log/link-root-standalonesession-0-localhost.localdomain.out && tail -F /usr/local/flink-1.13.6/log/flink-root-taskexecutor-0-localhost.localdomain.out

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
注意:如果我们只使用flink提供的单机部署启动命令./bin/start-cluster.sh来启动flink容器,那么在容器启动成功之后就会被关闭掉。因为docker容器后台运行要求程序必须有一个前台进程,但是flink的start-cluster.sh命令是后台启动flink程序,所以当flink启动后,docker没有检测到前台程序或者一直挂起的命令,那么docker容器就会认为程序已经执行结束,从而关闭容器。既然我们知道的问题出现的原因,那么解决就只需要对症下药,在bin/start-cluster.sh命令后面,我紧跟着又使用tail -F 的命令去持续输出运行日志,这样的话,docker容器启动时就会有一个一直挂起的命令,docker容器就不会自动关闭。
构建镜像:
#构建镜像
$ docker build -t flink:0.1 . # [自定义镜像名]:[版本号]
#查看构建好的镜像
$ docker images
- 1
- 2
- 3
- 4

启动容器:
#启动容器
$ docker run -d -p 8081:8081 --name flink flink:1
#查看已经启动的容器
$ docker ps
- 1
- 2
- 3
- 4

3、使用docker-compose启动standlone模式
环境准备:flink:1.14.4-scala_2.12-java8 镜像
编写docker-compose.yaml文件:
version: "3.7" services: jobmanager: image: flink:1.14.4-scala_2.12-java8 expose: - "6123" ports: - "8081:8081" command: jobmanager environment: - JOB_MANAGER_RPC_ADDRESS=jobmanager taskmanager: image: flink:1.14.4-scala_2.12-java8 expose: - "6121" - "6122" depends_on: - jobmanager command: taskmanager links: - "jobmanager:jobmanager" environment: - JOB_MANAGER_RPC_ADDRESS=jobmanager
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
启动容器:
#启动容器
$ docker-compose up -d
- 1
- 2

查看容器:
$ docker ps
- 1

三、Flink UI界面的使用
前面我们使用几种方式成功启动了FLink,接下来就是提交任务进行执行,flink提交任务的方式是多样的,不仅可以使用命令行直接提交,还提供了简洁易懂的UI可视化界面进行操作。
接下来我们了解一下Flink可视化界面的使用:
1、启动flink服务
$ ./bin/start-cluster.sh
- 1

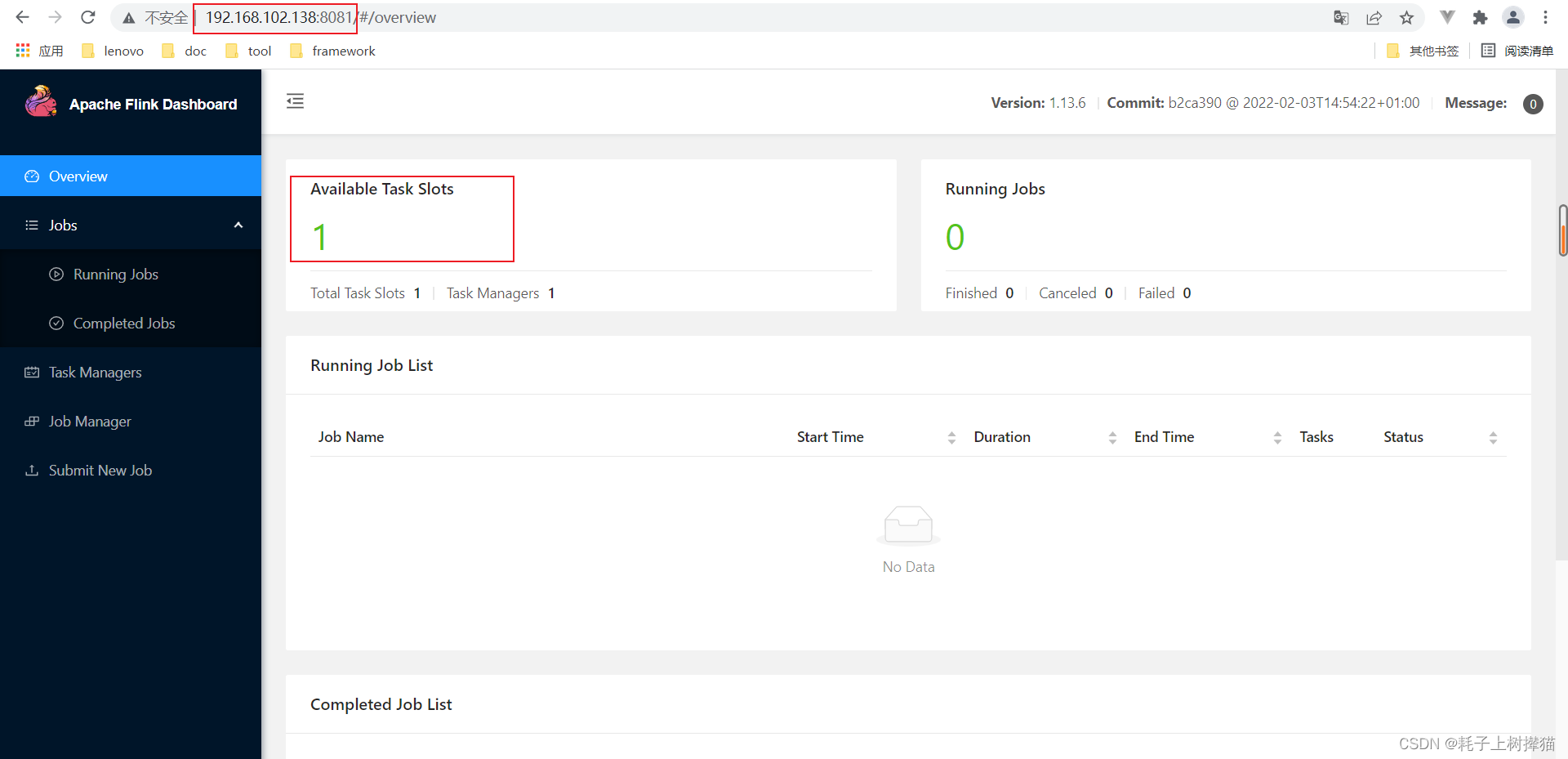
2、使用8081端口打开UI界面
http://192.168.102.139:8081

3、主页
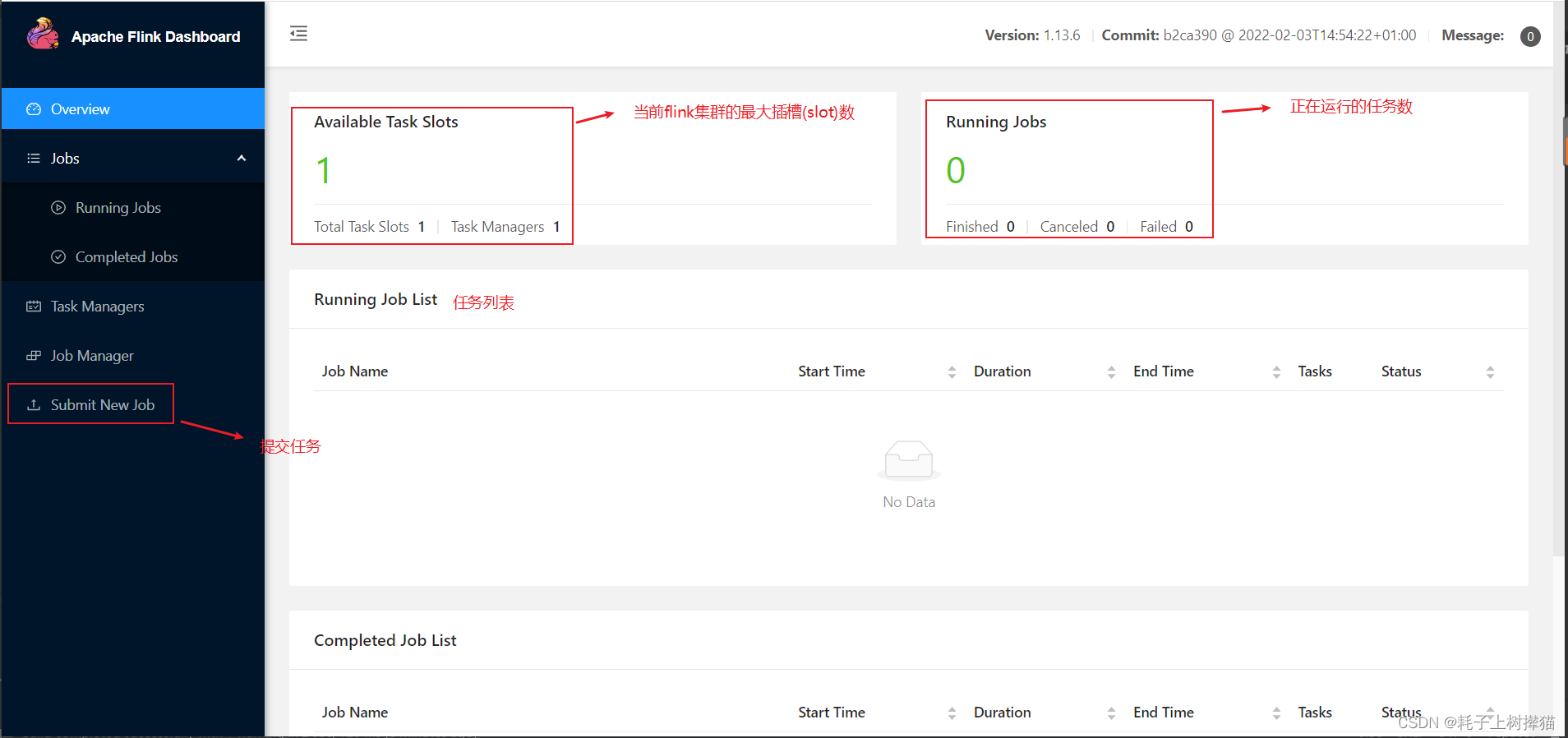
4、Task Managers
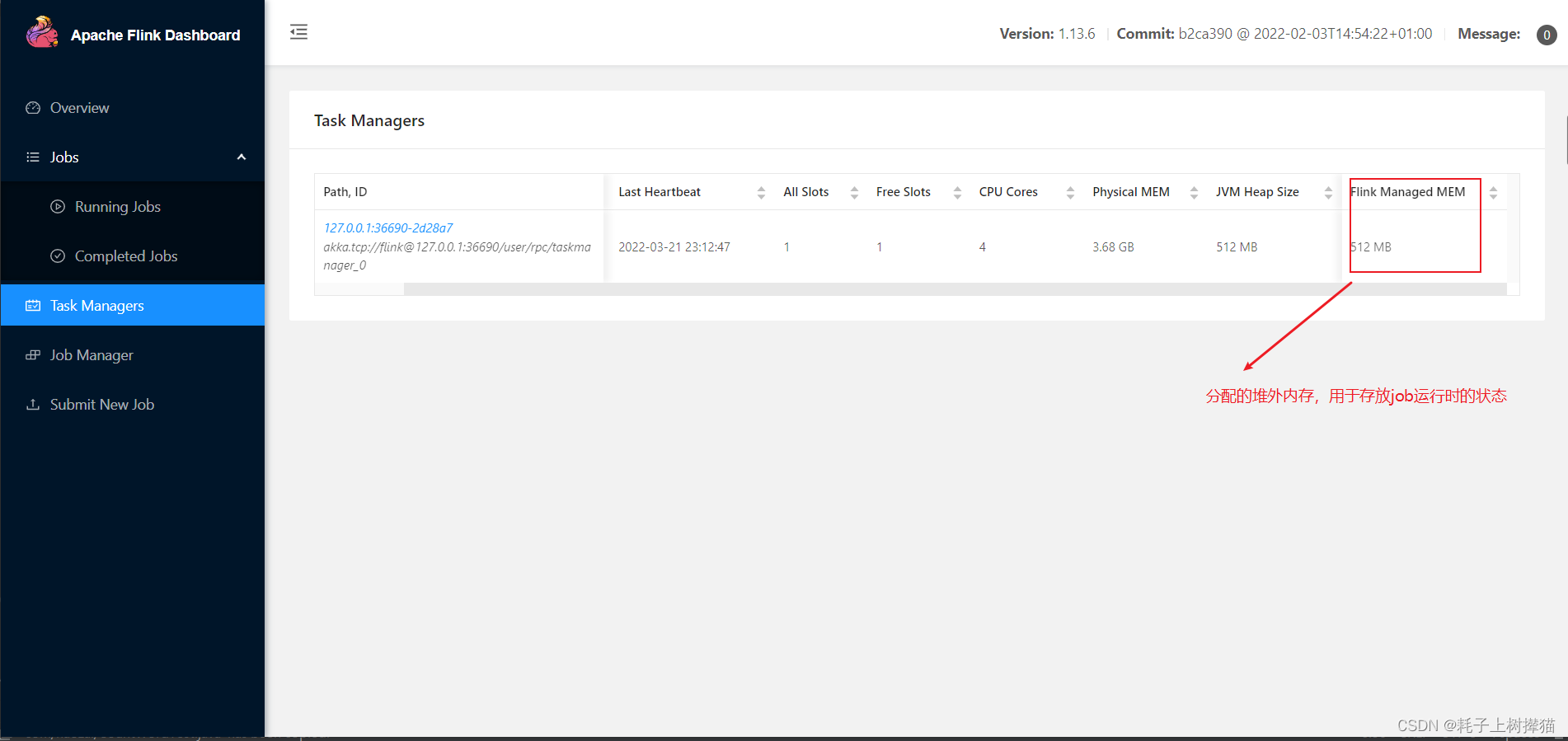
5、Job Manager
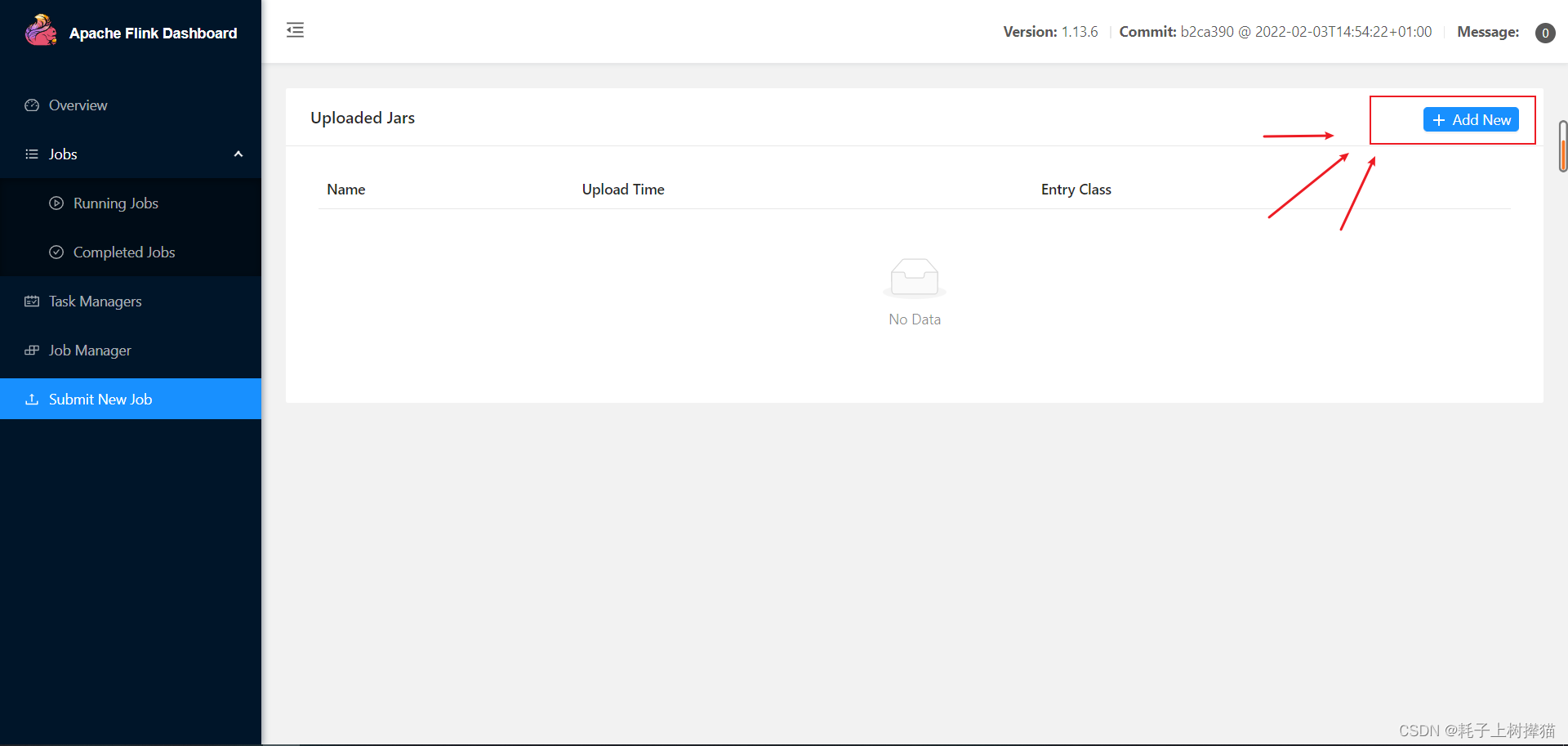
6、submit new job
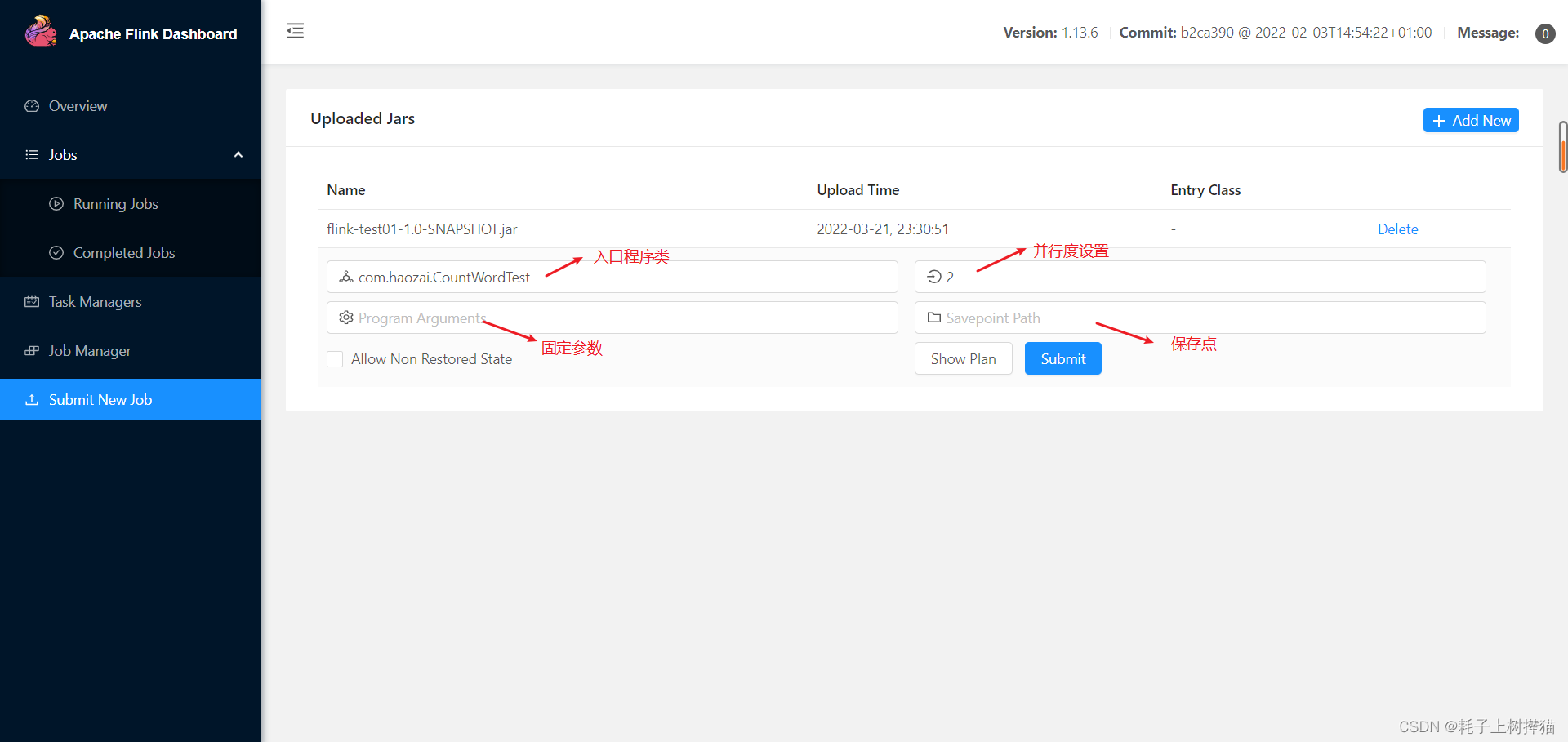
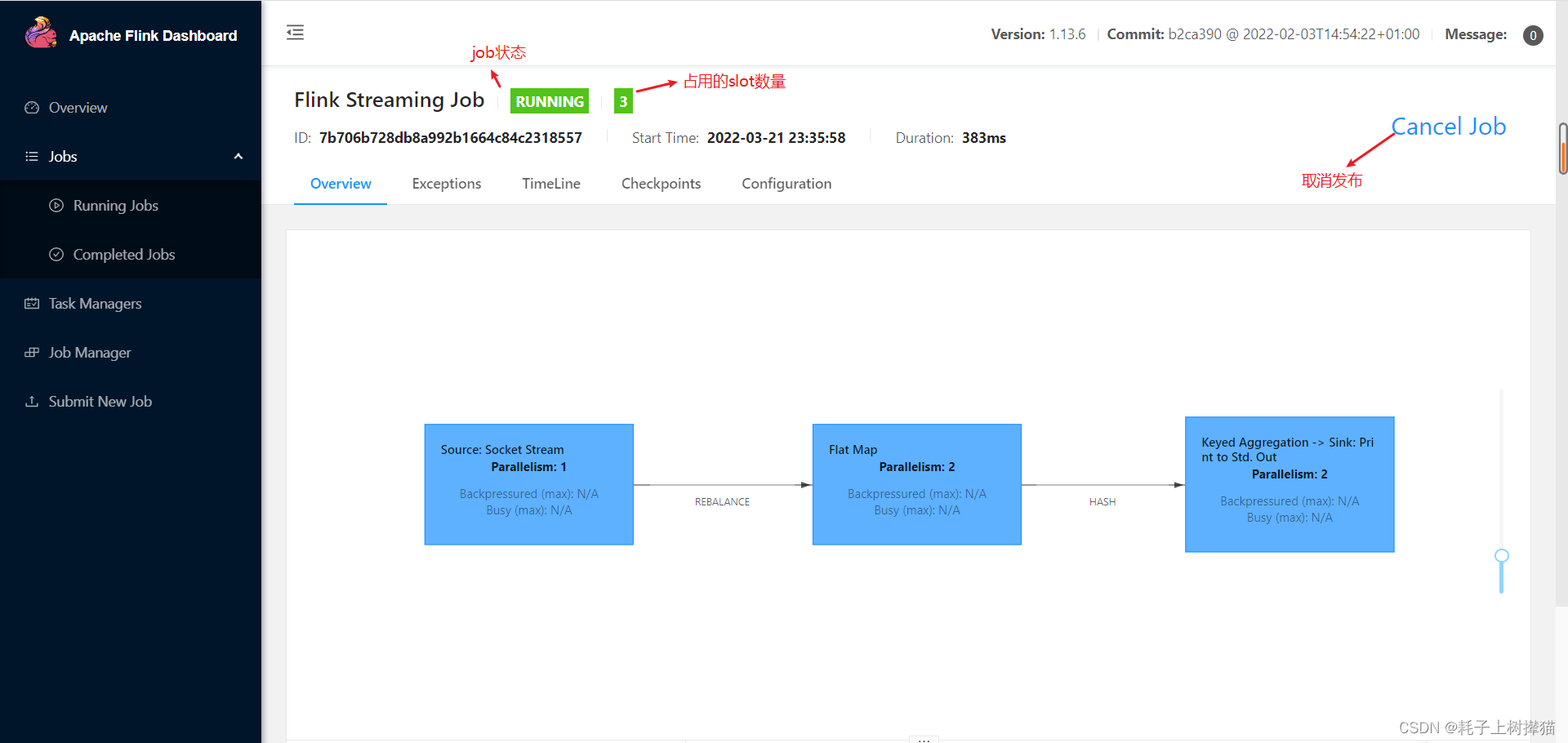
并行度设置的优先级:
代码中单个步骤设置并行度 > 代码中全局设置并行度 > 可视化界面提交job时设置的并行度 > flink-config中配置的并行度
并行度的使用会消耗flink的插槽(slot)数,因为一个任务对应一个slot,当任务数大于flink配置的slot数时,任务就会处于等待分配资源的状态。
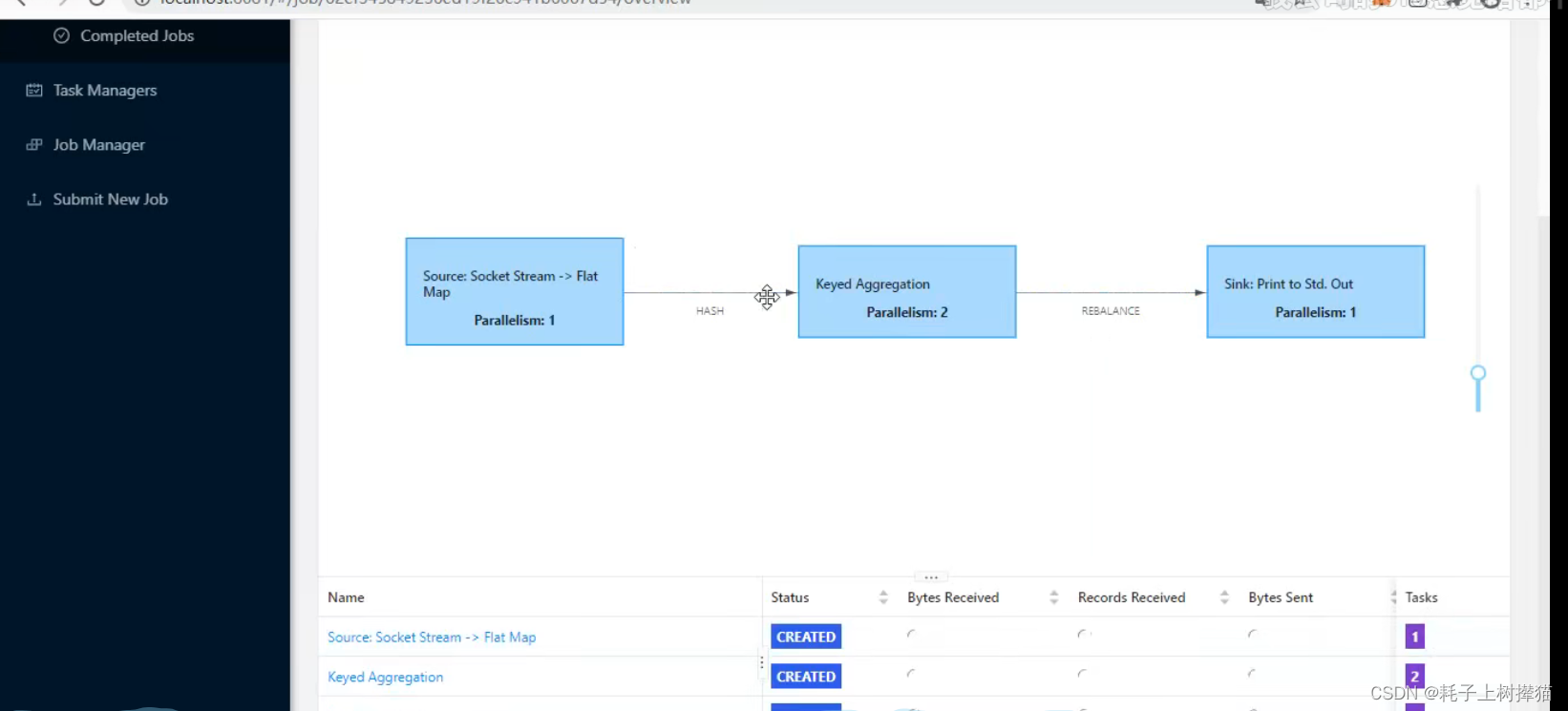
举个例子,如上图,flatMap并行度为1,表示一个任务;keyBy并行度为2,表示并行的两个任务;sink并行度为1,表示一个任务;所以当前job总的任务数是4,也就是说我们执行这个job时,这个job执行了四个任务,但是我们给flink配置的插槽数为1,也就是我们当前的flink可以同时运行的任务数量为1,所以就会出现以下情况
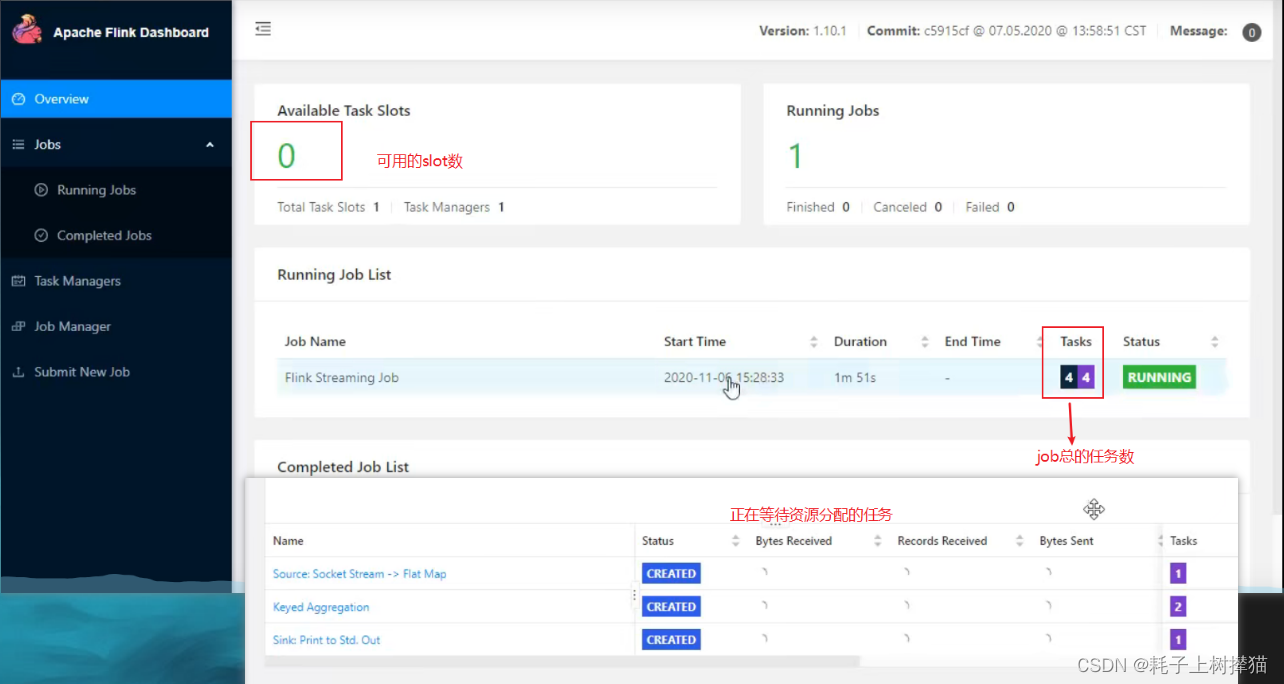
可以看到,有一个任务已经在运行,但是还有三个任务正在等待分配资源,所以这个job是没有真正运行起来的
那如果我们将flink的插槽数设置为4,会出现什么情况呢?
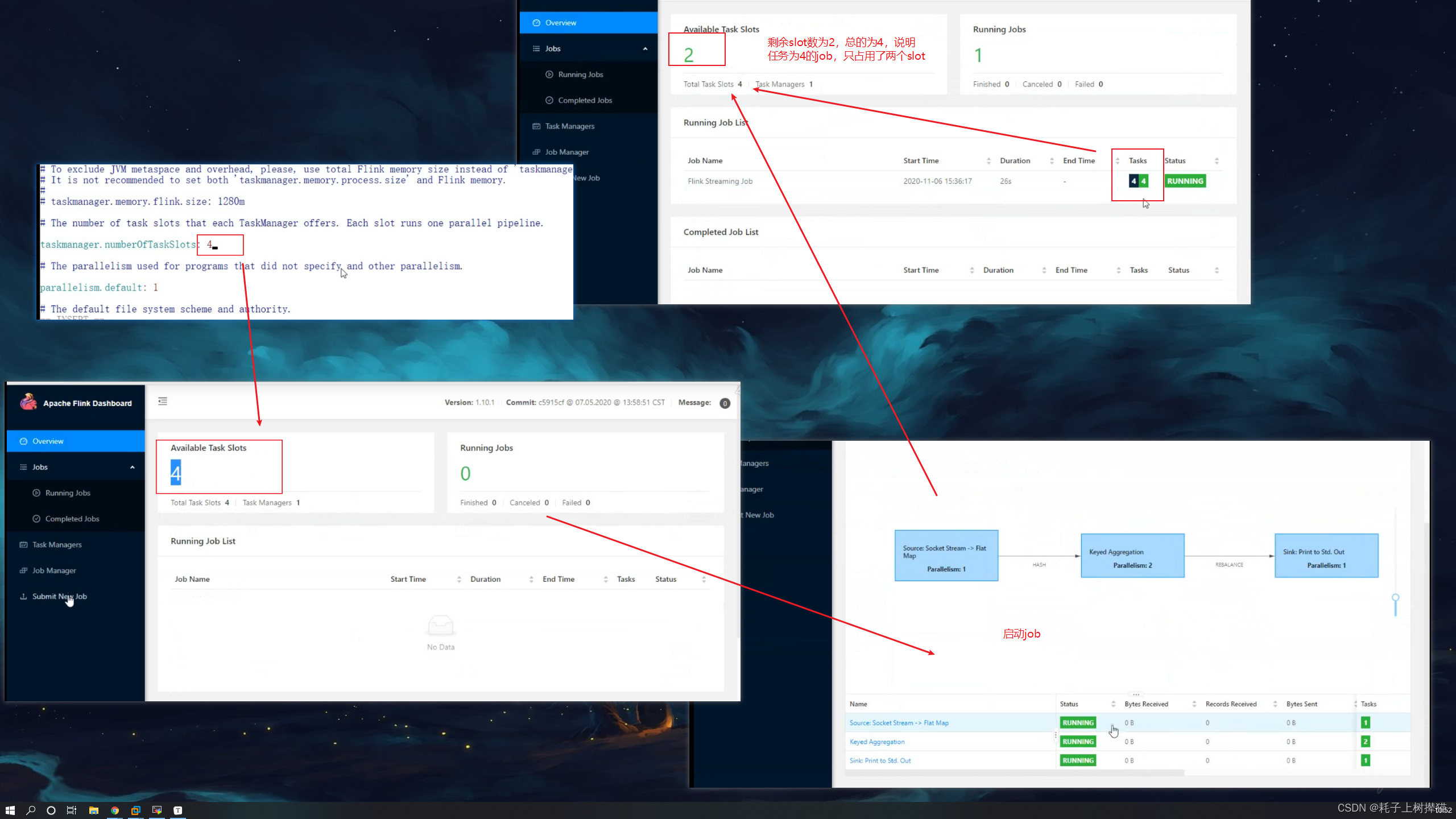
会发现,job任务跑起来了,并且消耗总共两个插槽,为什么是两个呢,返回去再看,我们设置的并行度里,最大的并行度为2
7、测试
7.1 jar包中的示例代码
public class CountWordTest { public static void main(String[] args) throws Exception { //获取flink操作的上下文环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); //设置数据源 DataStream<String> dataStream = env.socketTextStream("localhost", 7777); //中间操作 SingleOutputStreamOperator<Tuple2<String, Integer>> sum = dataStream.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() { @Override public void flatMap(String value, Collector<Tuple2<String, Integer>> collector) throws Exception { String[] words = value.split(" "); for (String word : words) { collector.collect(new Tuple2<>(word, 1)); } } }).keyBy(0).sum(1); //打印到控制台 sum.print(); //执行流操作 env.execute(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
7.2 使用nc发送一条数据

7.3 在UI界面查看任务执行的结果