
- 1学习笔记:CMD常用命令_cmd需要输入y的命令
- 2计算机通信领域期刊,适合计算机通信专业投稿的刊物哪些
- 3前端新手电脑环境配置(保姆级)_前端环境配置
- 4ubuntu server 安装openpose python api docker_can not find openpose python api.
- 5音乐创作的AI算法:从基础到实践
- 6国开计算机应用基础中考答案,国开计算机应用基础模块4PowerPoint2010电子演示文稿系统答案...
- 72023最新计算机毕业设计题目汇总大全_计算机最新毕业设计题目
- 8如何看待鸿蒙HarmonyOS?
- 9Pycharm 2020 社区版常用快捷键_pycharm社区版2020
- 10云计算实训笔记(day02)
保姆级scrapy框架实践:爬取当当网java图书数据_当当网robots.txt
赞
踩
学习scrapy做的实践,写一篇日记梳理一下内容。
我会详细解释scrapy的具体使用,以及MySQL数据库的基础使用。
上一篇实践忘了说,爬虫伦理的其中一点就是各网站的robots协议,协议规定了爬虫可以访问的内容,其协议在每个网站根目录下的robots.txt里。
这里我爬取的是当当的图书数据,也先查询一下robots协议。
挺尴尬的,当当的不在主站,在搜索页。
第一部分:MySQL
1、MySQL的安装
以上准备就绪后,即可。
2、命令行创建数据库与表
第二部分:scrapy
1、scrapy的安装
打开命令行cmd,输入pip install scrapy即可下载,下载完毕后在命令行执行scrapy -h,测试是否安装成功,-h可以得到帮助文档。
#关于命令行的操作,我会慢慢做总结的,这里是草稿版➡CMD基础。
2、scrapy创建工程
scrapy的操作是在命令行进行的。
格式如下:
| 命令 | 说明 | 格式 |
|---|---|---|
| startproject | 创建一个新工程 | scrapy startproject name [dir] |
| genspider | 创建一个爬虫 | scrapy genspider [options] name domain |
| settings | 获得爬虫配置信息 | scrapy settings [options] |
| crawl | 运行一个爬虫 | scrapy crawl spider |
| list | 列出工程中所有爬虫 | scrapy list |
| shell | 启动URL调试命令行 | scrapy shell [url] |
打开命令行,cd 选择文件夹,md创建scrapy的工程文件夹。
cd进入文件夹,输入scrapy startproject demo,demo是工程名,任意输入即可。这个命令会在相应的文件夹创建一个工程文件组:如下
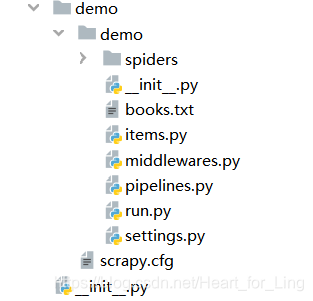
创建工程文件demo后,cd demo。
然后执行:scrapy genspider demo xxx.io;这个命令是在spiders文件夹里创建一个名为demo.py的文件,所以这一步可以直接手动生成一个爬虫文件即可。
!以上操作都在命令行进行。
到这里,工程的初始化就完成了。
3、修改配置
3.1 修改item.py
因为这次的实践是爬取图书信息,比如爬取当当上所有与java相关的图书数据,包括:书名、作者、出版社、日期、价格和详细介绍。
因此我们要建立一个图书的类,类中包含上述条目。在我们的 scrapy 框架中的demo目录下有一个文件 items.py 就是用来设计数据项目类的,如下:
将文件修改为:
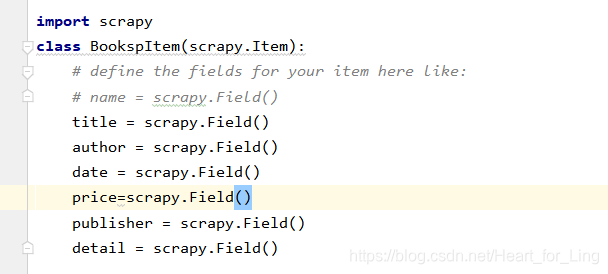
这个类继承自 scrapy.Item 类,在类中定义的每个字段项目都是一个 scrapy.Field 对象。可以通过
item=BookItem()
item["title"]="Python 程序设计"
item["author"]="James"
item["publisher"]="清华大学出版社"
- 1
- 2
- 3
- 4
来赋值。
3.2 修改settings.py
基本来说,打开settings文件,42-45行是浏览器的头,取消掉注释后,爬虫就带上了浏览器的header;67-69行是设置通道,使得爬虫每爬取一个item文件都会送到pipelines.py并调用process_item方法。修改也是取消注释即可。

4、编写爬虫文件
这是核心的一步。
如果是自行编写爬虫文件的,一定注意scrapy的爬虫文件是在spiders文件夹下,且如下:
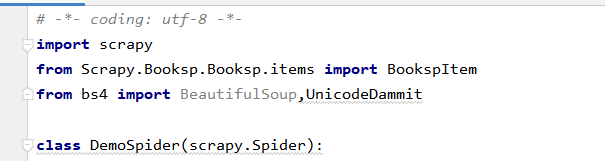
class DemoSpider(scrapy.Spider):爬虫是继承自scrapy.Spider!!!

固定格式如上!
这里我们爬取的是java,所以把start_urls里key=后面的dsa修改为java即可。如果搜索的内容是汉字,还需要一个转换的步骤,这里暂且不谈。
class DemoSpider(scrapy.Spider):
name = 'demo'
start_urls =['http://search.dangdang.com/?key=java']
def parse(self, response):
try:
#print(response.url)
#data=BeautifulSoup(response.body,'lxml')
#data=response.body.decode()
data=UnicodeDammit(response.body,['utf-8','gbk']).unicode_markup
selector = scrapy.Selector(text=data)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
运行scrapy会返回一个response对象。指路➡response对象详情
response.body是网站返回的二进制数据,deconde()转化为文本,但是某些格式不支持解码。比如当当,于是就用到了bs4的UnicodeDammit:
data=UnicodeDammit(response.body,['utf-8','gbk']).unicode_markup
- 1
提取数据
scrapy自带搜索方法xpath,非常强大好用。详细语法指南!
写爬虫文件是scrapy的核心,那么数据提取就是爬虫文件的核心,如果事先没有很好的解析网页,编写提取数据的语句,那么爬虫运行很长一段时间后爬取到的可能都是一些垃圾数据罢了。
打开当当,搜索java,然后在一本图书上右键,检查。

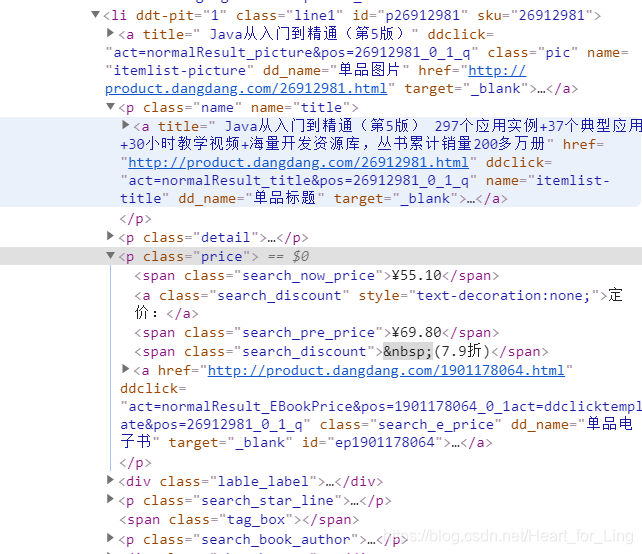
可以较轻易的发现,所有的图书数据都保持在li标签下,再尝试几个,也是如此。所以:
data=UnicodeDammit(response.body,['utf-8','gbk']).unicode_markup
selector = scrapy.Selector(text=data)
lis = selector.xpath("//li['@ddt-pit'][starts-with(@class,'line')]")
- 1
- 2
- 3
以上的xpath语法表示在所有节点查找具有属性ddt-pit以及属性class以line开头的节点li。
得到一个列表赋值给lis
然后:
for li in lis:
title = li.xpath("./a[position()=1]/@title").extract_first()
price =li.xpath("./p[@class='price']/span[@class='search_now_price']/text()").extract_first()
author =li.xpath("./p[@class='search_book_author']/span[position()=1]/a/@title").extract_first()
date =li.xpath("./p[@class='search_book_author']/span[position()=last()-1]/text()").extract_first()
publisher =li.xpath("./p[@class='search_book_author']/span[position()=last()]/a/@title").extract_first()
detail = li.xpath("./p[@class='detail']/text()").extract_first()
item = BookspItem()
item["title"] = title.strip() if title else ""
item["author"] = author.strip() if author else ""
item["date"] = date.strip()[1:] if date else ""
item["publisher"] = publisher.strip() if publisher else ""
item["price"] = price.strip() if price else ""
item["detail"] = detail.strip() if detail else ""
yield item
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
提取到所有所需数据,然后item = BookspItem(),通过3.1所讲的方式来填入数据,然后yield item。
返回item,通过之前对settings的设置,使得item传递给pipelines。
这里告一段落,现在开始编写pipelines.py。
5、编写pipelines.py
这里面有两个很重要的方法:def open_spider(self,spider):与def close_spider(self, spider):,在 scrapy 的过程中一旦打开一个 spider 爬虫就会执行这个类的 open_spider(self,spider)函数,一旦这个 spider 爬虫关闭就执行这个类的 close_spider(self,spider)函数。
因此程序在open_spider 函数中连接 MySQL 数据库,并创建操作游标 self.cursor,在 close_spider 中提交数据库并关闭数据库,程序中使用 count 变量统计爬取的书籍数量。
在数据处理函数中每次有数据到达,就显示数据内容,并使用 insert 的 SQL 语句把数据插入到数据库中。
因为要把爬取到的数据保存到数据库,所以第一步即是与数据库建立连接:
def open_spider(self,spider):
print('opened')
try:
#以下内容具体参见MySQL的文档
self.con = pymysql.connect(host="", port=3306, user="root", passwd="", db='db1',charset="utf8")
#建立游标
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
这里又有两种方法创建表,第一种是前文在sql的命令行里创建表,第二种是在py文件里创建。
如果已经在sql里创建过表books:
create table books
(
bTitle varchar(512) primary key,
bAuthor varchar(256),
bPublisher varchar(256),
bDate varchar(32),
bPrice varchar(16),
bDetail text
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
那么:
def open_spider(self,spider):
print('opened')
try:
#以下内容具体参见MySQL的文档
self.con = pymysql.connect(host="", port=3306, user="root", passwd="", db='db1',charset="utf8")
#建立游标
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
self.opened = True
self.count = 0
except Exception as err:
print(err)
self.opened=False
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
如果是在py文件里建表:
def open_spider(self,spider): print('opened') try: self.con = pymysql.connect(host="", port=3306, user="root", passwd="", db='',charset="utf8") self.cursor = self.con.cursor(pymysql.cursors.DictCursor) try: self.cursor.execute("drop table books") except Exception as err: print(err) try: sql = """ create table books ( bTitle varchar(512) primary key, bAuthor varchar(256), bPublisher varchar(256), bDate varchar(32), bPrice varchar(16), bDetail text ) """ self.cursor.execute(sql) except Exception as err: print(err) self.cursor.execute("delete from books") self.opened = True self.count = 0 except Exception as err: print(err) self.opened=False

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
再就是close__spider:
def close_spider(self, spider):
if self.opened:
self.con.commit()
self.con.close()
self.opened = False
print("closed")
print("总共爬取", self.count, "本书籍")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
最后是process_item(self, item, spider):
def process_item(self, item, spider):
try:
print(item["title"])
print(item["author"])
print(item["publisher"])
print(item["date"])
print(item["price"])
print(item["detail"])
print()
if self.opened:
self.cursor.execute("insert into books(bTitle, bAuthor, bPublisher, bDate, bPrice, bDetail)values( % s, % s, % s, % s, % s, % s)",(item["title"],item["author"],item["publisher"],item["date"],item["price"],item["detail"]))
self.count += 1
except Exception as err:
print(err)
return item
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
最后是爬虫文件如何自动翻页:
link = selector.xpath("//div[@class='paging']/ul[@name='Fy']/li[@class='next']/a/@href").extract_first()
if link:
url = response.urljoin(link)
yield scrapy.Request(url=url, callback=self.parse)
- 1
- 2
- 3
- 4
6、运行
爬虫程序必须使用 scrapy 中专门的命令 scrapy crawl。我们回到命令行窗体,在 cmd中执行命令:
scrapy crawl mySpider -s LOG_ENABLED=False那么就可以看到执行的结果如下图 所示,其中 mySpider 就是我们爬虫程序的名称,后面的参数是不显示调试信息。

为了简单起见,我们专门设计一个 Python 程序 run.py,它包含执行命令行的语句:
from scrapy import cmdline
cmdline.execute("scrapy crawl mySpider -s LOG_ENABLED=False".split())
- 1
- 2
直接运行 run.py 就可以执行 MySpider.py 的爬虫程序了,效果与在命令行窗体中执行一样,结果还直接显示在 PyCharm 中。
7、运行结果

spider完整代码
#!/usr/bin/env python # -*- coding:utf-8 -*- # Author:LingInHeart # Time:2019/12/17 import scrapy from Scrapy.Booksp.Booksp.items import BookspItem from bs4 import BeautifulSoup,UnicodeDammit class DemoSpider(scrapy.Spider): name = 'demo' start_urls =['http://search.dangdang.com/?key=dsa'] def parse(self, response): try: #print(response.url) #data=BeautifulSoup(response.body,'lxml') #data=response.body.decode() data=UnicodeDammit(response.body,['utf-8','gbk']).unicode_markup selector = scrapy.Selector(text=data) lis = selector.xpath("//li['@ddt-pit'][starts-with(@class,'line')]") for li in lis: title = li.xpath("./a[position()=1]/@title").extract_first() price =li.xpath("./p[@class='price']/span[@class='search_now_price']/text()").extract_first() author =li.xpath("./p[@class='search_book_author']/span[position()=1]/a/@title").extract_first() date =li.xpath("./p[@class='search_book_author']/span[position()=last()-1]/text()").extract_first() publisher =li.xpath("./p[@class='search_book_author']/span[position()=last()]/a/@title").extract_first() detail = li.xpath("./p[@class='detail']/text()").extract_first() item = BookspItem() item["title"] = title.strip() if title else "" item["author"] = author.strip() if author else "" item["date"] = date.strip()[1:] if date else "" item["publisher"] = publisher.strip() if publisher else "" item["price"] = price.strip() if price else "" item["detail"] = detail.strip() if detail else "" yield item link = selector.xpath("//div[@class='paging']/ul[@name='Fy']/li[@class='next']/a/@href").extract_first() if link: url = response.urljoin(link) yield scrapy.Request(url=url, callback=self.parse) except Exception as err: print(err)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41

