
- 1Java调用Elasticsearch API实现全文检索,搭配MinIO文件存储_java如何使用es ingest-attachment插件去读文件内容
- 2Neo4j入门到精通_neo4j菜鸟教程
- 3加密解决HTTP协议带来的安全问题
- 4SQL Server 常用语句介绍_sql语句 server
- 5谷粒商城实战笔记-27-分布式组件-SpringCloud-Gateway-创建&测试API网关
- 6银河麒麟桌面操作系统v10保姆级安装_银河麒麟操作系统v10
- 7nacos 不进行健康检查_健康检查禁用 nacos
- 8c 语言整人代码大全,C 语言整人代码大全.doc
- 9浅谈Elasticsearch性能优化和调优_es调优参数说明
- 10git相关操作(一) —— git工作区域&基本信息设置&初始化init & git本地操作 & git分支管理_git工作目录
昇思MindSpore 25天学习打卡营|day3_昇思 25天打卡
赞
踩
虽然是周五,但也要学习,虽然很多地方看不懂,但我认为知识都是非线性的,是复利增长的,坚持学习,最后当你回头看的时候就会发现轻舟已过万重山。
数据集 Dataset
数据是深度学习的基础,高质量的数据输入将在整个深度神经网络中起到积极作用。MindSpore提供基于Pipeline的数据引擎,通过数据集(Dataset)和数据变换(Transforms)实现高效的数据预处理。
数据集加载
我们使用Mnist数据集作为样例,介绍使用mindspore.dataset进行加载的方法。
mindspore.dataset提供的接口仅支持解压后的数据文件,因此我们使用download库下载数据集并解压。
- # Download data from open datasets
- from download import download
-
- url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/" \
- "notebook/datasets/MNIST_Data.zip"
- path = download(url, "./", kind="zip", replace=True)
- # Download data from open datasets
- from download import download
-
- url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/" \
- "notebook/datasets/MNIST_Data.zip"
- path = download(url, "./", kind="zip", replace=True)
- Downloading data from https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/datasets/MNIST_Data.zip (10.3 MB)
-
- file_sizes: 100%|██████████████████████████| 10.8M/10.8M [00:02<00:00, 4.15MB/s]
- Extracting zip file...
- Successfully downloaded / unzipped to ./

数据集迭代
数据集加载后,一般以迭代方式获取数据,然后送入神经网络中进行训练。我们可以用create_tuple_iterator或create_dict_iterator接口创建数据迭代器,迭代访问数据。
访问的数据类型默认为Tensor;若设置output_numpy=True,访问的数据类型为Numpy。
数据集常用操作
Pipeline的设计理念使得数据集的常用操作采用dataset = dataset.operation()的异步执行方式,执行操作返回新的Dataset,此时不执行具体操作,而是在Pipeline中加入节点,最终进行迭代时,并行执行整个Pipeline。
下面分别介绍几种常见的数据集操作。
shuffle
数据集随机shuffle可以消除数据排列造成的分布不均问题。
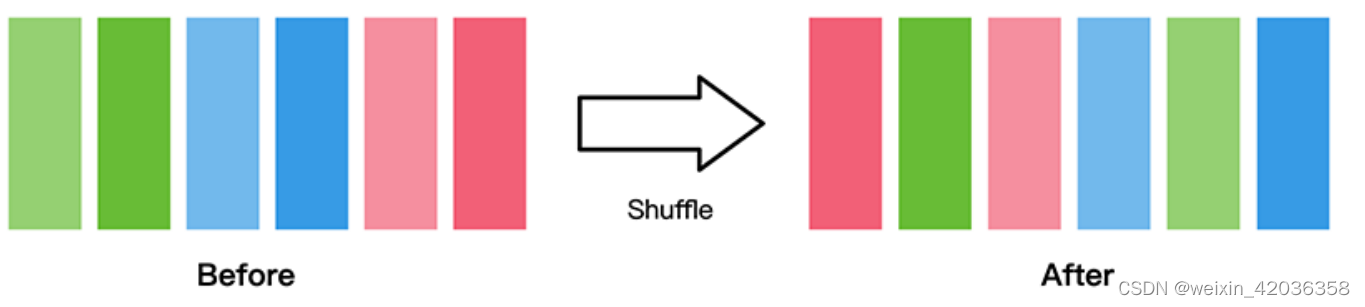
map
map操作是数据预处理的关键操作,可以针对数据集指定列(column)添加数据变换(Transforms),将数据变换应用于该列数据的每个元素,并返回包含变换后元素的新数据集。
Dataset支持的不同变换类型详见数据变换Transforms。
batch
将数据集打包为固定大小的batch是在有限硬件资源下使用梯度下降进行模型优化的折中方法,可以保证梯度下降的随机性和优化计算量。
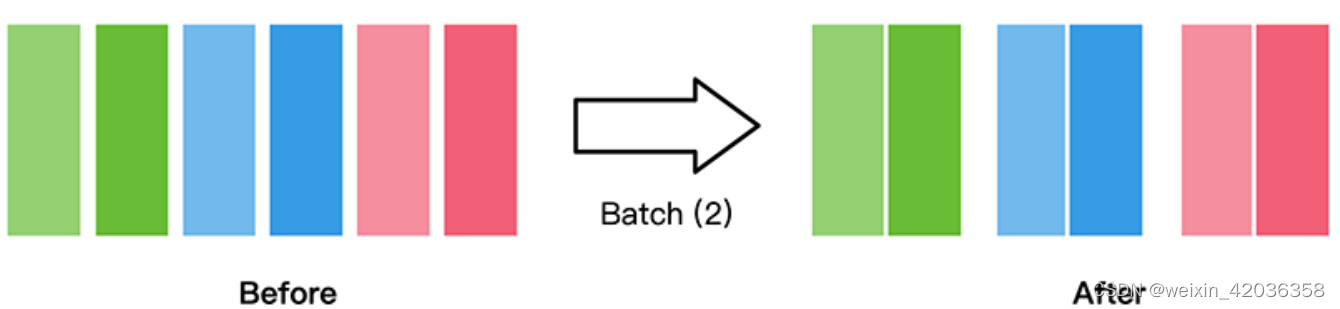
自定义数据集
mindspore.dataset模块提供了一些常用的公开数据集和标准格式数据集的加载API。
对于MindSpore暂不支持直接加载的数据集,可以构造自定义数据加载类或自定义数据集生成函数的方式来生成数据集,然后通过GeneratorDataset接口实现自定义方式的数据集加载。
GeneratorDataset支持通过可随机访问数据集对象、可迭代数据集对象和生成器(generator)构造自定义数据集,下面分别对其进行介绍。
可随机访问数据集¶
可随机访问数据集是实现了__getitem__和__len__方法的数据集,表示可以通过索引/键直接访问对应位置的数据样本。
例如,当使用dataset[idx]访问这样的数据集时,可以读取dataset内容中第idx个样本或标签。
可迭代数据集
可迭代的数据集是实现了__iter__和__next__方法的数据集,表示可以通过迭代的方式逐步获取数据样本。这种类型的数据集特别适用于随机访问成本太高或者不可行的情况。
例如,当使用iter(dataset)的形式访问数据集时,可以读取从数据库、远程服务器返回的数据流。
生成器
生成器也属于可迭代的数据集类型,其直接依赖Python的生成器类型generator返回数据,直至生成器抛出StopIteration异常。

