
- 1【2023最全教程】Python接口测试实战之搭建自动化测试框架(建议收藏)_python接口自动化框架
- 2Sim2Real学习总结:A Short Survey_sim2real end2end
- 3AI无限·兴好有你-【万兴科技】2024届全球校园招聘启动
- 4asp.net ajax使用C#后台代码(无参数)_c# 没有接口参数 ajax怎么写
- 5Git分支打包(zip)的详细教程_如何打包git项目工作区
- 6C语言归并排序(完整代码版)_归并排序c语言代码
- 7vue实现预览编辑ppt、word、pdf、excel、等功能的解决方案(内网-前端)_vue中预览word、ppt、excel文件
- 8python字符串排序、列表排序----sort()函数与sorted()函数
- 9面试:靠着这篇笔记,我拿下了16k车载测试offer!_车载测试常见面试流程(1)_车载车测试项目面试
- 10spark代码sc统一配置_spark sc
机器学习 笔记04 ---决策树(DT):理论+代码实现_dt决策树
赞
踩
目录
4.1.2 条件熵(Conditional Entropy)H(Y|X)
1、概述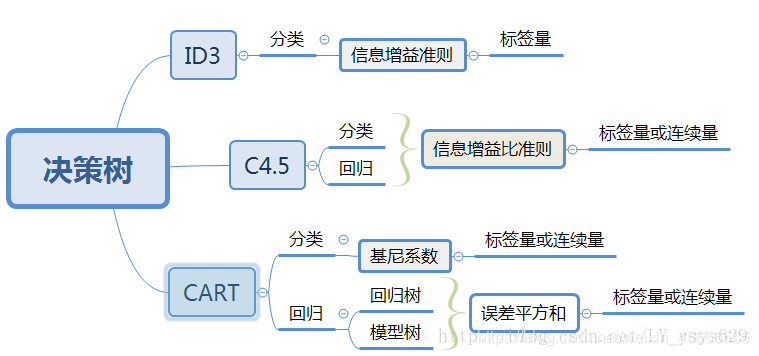
1. 作为机器学习中的一大类模型,树模型一直以来都颇受学界和业界的重视。目前无论是各大比赛各种大杀器的XGBoost、lightgbm,还是像随机森林、AdaBoost等典型集成学习模型,都是以决策树模型为基础的。
2. 决策树学习旨在构建一个与训练数据拟合很好,并且复杂度小的决策树。因为从所有可能的决策树中直接选取最优决策树是NP完全问题,所以现实中决策树学习算法通常采用启发式方法,近似求解这一最优化问题,学习到的决策树是次优的决策树。
决策树学习算法包括3部分:特征选择、决策树的生成和决策树的剪枝。常用的算法有ID3、 C4.5和CART算法。
3. 三大经典决策树算法最主要的区别是其特征选择的准则不同。ID3算法选择特征的依据是信息增益、C4.5是信息增益比,而CART则是基尼指数。
4.分类决策树模型是表示基于特征对实例进行分类的树形结构。决策树可以看成一个if-then规则的集合,也可以看作是定义在特征空间与类空间上的条件概率分布。李航《统计学习方法》P68
2、决策树模型
定义: 分类决策树模型是一种描述对实例进行分类的树形结构。
决策树由结点和有向边组成。结点有两种类型:内部结点和叶结点,其中内部结点表示一个特征或属性,叶结点表示一个类。 用决策树分类:从根节点开始,对实例的某一特征进行测试,根据测试结果将实例分配到其子节点,此时每个子节点对应着该特征的一个取值,如此递归的对实例进行测试并分配,直到到达叶节点,最后将实例分到叶节点的类中。
一般的,一棵决策树包含一个根结点、若干个内部结点和若干个叶结点。叶结点对应于决策结果,其他每个结点则对应于一个属性测试。每个结点包含的样本集合根据属性测试的结果被划分到子结点中,根结点包含样本全集,从根结点到每个叶结点的路径对应了一个判定测试序列。在下图中,圆和方框分别表示内部结点和叶结点。决策树学习的目的是为了产生一棵泛化能力强,即处理未见示例能力强的决策树。
下图为决策树示意图,圆点——内部节点:特征\属性,方框——叶节点:类
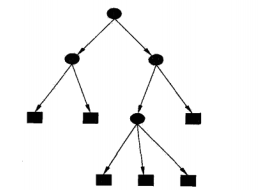
K-近邻算法 可以完成很多分类任务,但是其最大的缺点是无法给出数据的内在含义,决策树的优势在于数据形式非常容易理解。
决策树可以看成一个if-then规则的集合:由决策树的根结点到叶结点的每一条路径构建一条规则; 路径上内部结点的特征对应着规则的条件,二叶结点的类对应这规则的结论。
决策树的路径或其对应的if-then规则集合具有一个重要性质:互斥且完备。每一个实例都被一条路径或者一条规则覆盖,而且只被一条路径或一条规则覆盖。
决策树与条件概率分布:决策树还表示为给定特征条件下类的条件概率分布。这一条件概率分布定义在特征空间的一个划分上。将特征空间划分为互不相交的单元(cell),并在每个单元定义一个类的概率分布就构成了一个条件概率分布。决策树的一条路径对应于划分中一个单元。
3、决策树学习
假设给定训练数据集:
其中,为输入实例(特征向量),n为特征个数,
为类标记,
,N为样本容量。
-
决策树学习的目标:根据给定的训练数据集构建一个决策树模型,使它能够对实例进行正确的分类。
-
决策树学习的本质:从训练集中归纳出一组分类规则,或者说是决策树学习是由训练数据集估计条件概率模型。 选择与训练集矛盾最小的决策树,同时具有很好的泛化能力;或者的条件概率模型不仅对训练数据有很好的拟合,对未知数据也有很好的预测。
-
决策树学习的损失函数:正则化的极大似然函数。
-
决策树学习的策略:最小化损失函数(以损失函数为目标函数的最小化问题)
-
决策树学习的目标:损失函数确定之后,在损失函数的意义下,选择最优决策树的问题。所以
因为从所有可能的决策树中直接选取最优决策树是NP完全问题,所以现实中决策树学习算法通常采用启发式方法,近似求解这一最优化问题,学习到的决策树是次优的决策树。
决策树学习算法通常是一个递归地选择最优特征, 并根据该特征对训练数据进行分割,使得对各个子数据集有一个最好的分类的过程。这一过程对应着对特征空间的划分,也对应着决策树的构建。
-
开始,构建根结点,将所有训练数据都放在根结点。选择一个最优特征,按照这一特征将训练数据集分割成子集,使得各个子集有一个在当前条件下最好的分类。
-
如果这些子集已经能够被基本正确分类,那么构建叶结点,并将这些子集分到所对应的叶结点中去;如果还有子集不能被基本正确分类,那么就对这些子集选择新的最优特征,继续对其进行分割,构建相应的结点。
-
如此递归地进行下去,直至所有训练数据子集被基本正确分类,或者没有合适的特征为止。
-
最后每个子集都被分到叶结点上,即都有了明确的类。这就生成了一棵决策树。
基本算法如下:

以上方法生成的决策树可能对训练数据有很好的分类能力,但对未知的测试数据却未必有很好的分类能力,即可能发生过拟合现象。我们需要对已生成的树自下而上进行剪枝,将树变得更简单,从而使它具有更好的泛化能力。具体地,就是去掉过于细分的叶结点,使其回退到父结点,甚至更高的结点,然后将父结点或更高的结点改为新的叶结点。
如果特征数量很多,也可以在决策树学习开始的时候,对特征进行选择,只留下对训练数据有足够分类能力的特征。
决策树通常有三个步骤:特征选择、决策树的生成、决策树的修剪。
由于决策树表示一个条件概率分布,所以深浅不同的决策树对应着不同复杂度的概率模型。决策树的生成对应于模型的局部选择,决策树的剪枝对应于模型的全局选择。决策树的生成只考虑局部最优,决策树的剪枝则考虑全局最优。
使用决策树做预测需要以下过程:
- 收集数据:可以使用任何方法。比如想构建一个相亲系统,我们可以从媒婆那里,或者通过参访相亲对象获取数据。根据他们考虑的因素和最终的选择结果,就可以得到一些供我们利用的数据了。
- 准备数据:收集完的数据,我们要进行整理,将这些所有收集的信息按照一定规则整理出来,并排版,方便我们进行后续处理。
- 分析数据:可以使用任何方法,决策树构造完成之后,我们可以检查决策树图形是否符合预期。
- 训练算法:这个过程也就是构造决策树,同样也可以说是决策树学习,就是构造一个决策树的数据结构。
- 测试算法:使用经验树计算错误率。当错误率达到了可接收范围,这个决策树就可以投放使用了。
- 使用算法:此步骤可以使用适用于任何监督学习算法,而使用决策树可以更好地理解数据的内在含义。
4、决策树的构建——三步骤
使用决策树做预测的每一步骤都很重要,数据收集不到位,将会导致没有足够的特征让我们构建错误率低的决策树。数据特征充足,但是不知道用哪些特征好,将会导致无法构建出分类效果好的决策树模型。从算法方面看,决策树的构建是我们的核心内容。
决策树要如何构建呢?通常,这一过程可以概括为3个步骤:特征选择、决策树的生成和决策树的修剪。
4.1 特征选择
特征选择在于选取对训练数据具有分类能力的特征。这样可以提高决策树学习的效率,如果利用一个特征进行分类的结果与随机分类的结果没有很大差别,则称这个特征是没有分类能力的。经验上扔掉这样的特征对决策树学习的精度影响不大。
通常特征选择的准则是信息增益(information gain)或信息增益比,后面介绍基尼指数。
那么,什么是信息增益?在讲解信息增益之前,让我们看一组实例,贷款申请样本数据表。
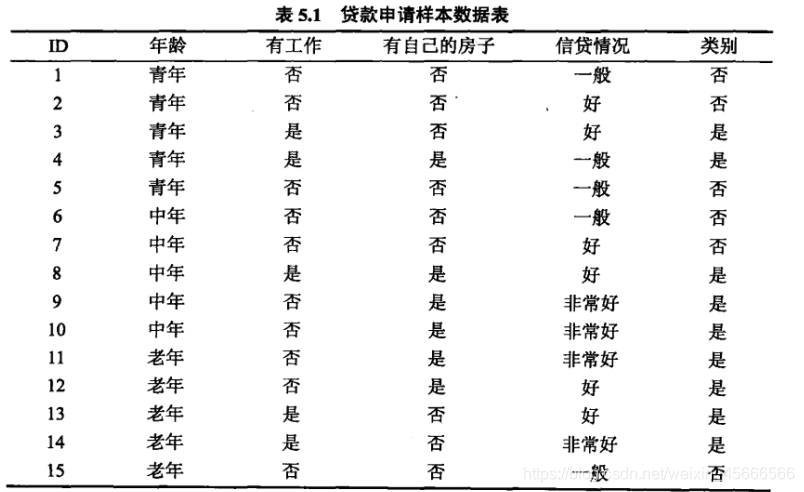
希望通过所给的训练数据学习一个贷款申请的决策树,用以对未来的贷款申请进行分类,即当新的客户提出贷款申请时,根据申请人的特征利用决策树决定是否批准贷款申请。
特征选择就是决定用哪个特征来划分特征空间。比如,我们通过上述数据表得到两个可能的决策树,分别由两个不同特征的根结点构成。

图5.3(a)所示的根结点的特征是年龄,有3个取值,对应于不同的取值有不同的子结点。图5.3(b)所示的根节点的特征是工作,有2个取值,对应于不同的取值有不同的子结点。两个决策树都可以从此延续下去。
问题是:究竟选择哪个特征更好些?这就要求确定选择特征的准则。直观上,如果一个特征具有更好的分类能力,或者说,按照这一特征将训练数据集分割成子集,使得各个子集在当前条件下有最好的分类,那么就更应该选择这个特征。信息增益就能够很好地表示这一直观的准则。
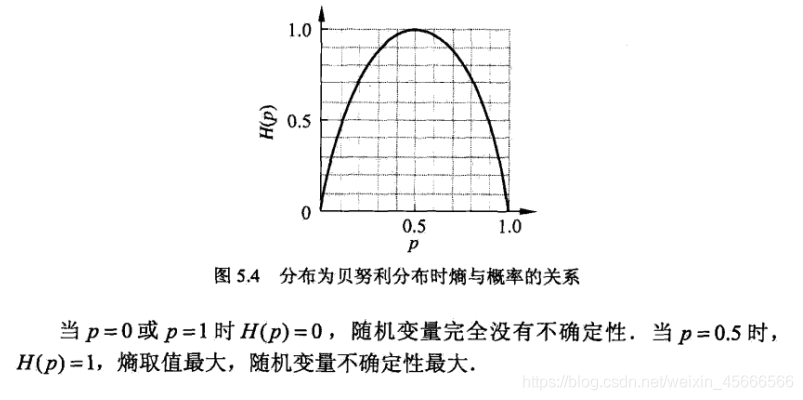
4.1.1 熵(Entropy)
在信息论与概率统计中,熵(entropy) 是表示随机变量 不确定性的度量。熵也指物体内部的混乱程度,熵值越高,混乱程度越高。或者训练集中不同类别的样本分布越均匀,熵越大,即不确定性越大。
设X是一个取有限个值的离散随机变量,其概率分布为:
则随机变量X的熵定义为:

的证明:《西瓜书》
4.1.2 条件熵(Conditional Entropy)H(Y|X)
条件熵H(Y|X)表示在已知随机变量X的条件下随机变量Y的不确定性。
设有随机变量 (X, Y)其联合概率分布为:
随机变量X给定的条件下随机变量Y的条件熵(conditional entropy) H(Y|X),定义为X给定条件下Y的条件概率分布的熵对X的数学期望:
这里,。
当熵和条件熵中的概率由数据估计(如极大似然估计)得到时(由训练集计算得到),所对应的熵与条件熵分别称为经验熵(empirical entropy)和经验条件熵(empirical conditional entropy)。此时,如果有0概率,令。
4.1.3 信息增益(Information Gain)
信息增益表示得知特征X的信息而使得类Y的信息不确定性减少的程度。
定义(信息增益): 特征A对训练数据集D的信息增益g(D,A) ,定义为集合D的经验熵H(D)与特征A给定条件下D的经验条件熵H(D∣A)之差,即:
一般地,熵H(Y)与条件熵H(Y∣X)之差称为互信息(mutual information)。决策树学习中的信息增益等价于训练数据集中类与特征的互信息。
决策树学习应用信息准则选择特征。给定训练数据集D和特征A,经验熵H(D)表示对数据集D进行分类的不确定性。而经验条件熵H(D|A)表示在给定特征A条件下对数据集D进行分类的不确定性。那么它们的差,即信息增益,就表示由于特征A而使得对数据集D的分类的不确定性减少的程度。显然,对于数据集D而言,信息增益依赖于特征,不同的特征往往具有不同的信息增益。信息增益大的特征具有更强的分类能力。
信息增益算法:
输入:训练数据集D和特征A
输出:特征A对训练数据集D的信息增益g(D, A)
其中,H(D)是数据集D的熵,H(D_i)是数据集Di的熵,H(D∣A)是数据集D对特征A的条件熵。 D_i是D中特征A取第i个值的样本子集,C_k是D中属于第k类的样本子集。n是特征A取 值的个数,K是类的个数。

根据此公式计算经验熵H(D),分析贷款申请样本数据表中的数据。最终分类结果只有两类,即放贷和不放贷。根据表中的数据统计可知,在15个数据中,9个数据的结果为放贷,6个数据的结果为不放贷。所以数据集D的经验熵H(D)为:

4.1.4 信息增益比
以信息增益作为划分训练数据集的特征,存在偏向于选择取值较多的特征的问题。使用信息增益比可以对这个问题进行校正,这是特征选择的另一个标准。
定义(信息增益比):
特征A对训练数据集D的信息增益比
定义为其信息增益 g(D,A)与训练数据集D关于特征A的值的经验熵
之比:
其中,n是特征A取值的个数。
信息增益比偏向于取值较少的特征地问题。 特征A地取值越多,样本越混杂,越不纯净;D_{i}中类别分布越均匀,(经验条件)熵越大。为了使变大,必须使经验熵
越小,所以要选n小的特征来保证比值结果大,也就是对取值数目较少的属性有所偏好。
【代码实现经验熵、信息增益、信息增益比】
- import numpy as np
- import pandas as pd
- import matplotlib.pyplot as plt
- %matplotlib inline
- import math
- import operator
- from matplotlib.font_manager import FontProperties
- from math import log
- import pprint
- from sklearn.datasets import load_iris
- from collections import Counter
-
- """
- 函数说明:计算经验熵(香农熵)
- Parameters:
- datasets - 数据集
- j-数据集第j列
- Returns:
- ent - 经验熵(香农熵)
- 当j=-1时,返回训练数据集D的经验熵
- 当j为其他时,返回训练数据集关于第j特征的值的熵
- """
- def single_ent(datasets,j):
- data_length = len(datasets)#返回数据集的行数即样本个数
- label_count = {}#保存每个标签(Label)出现次数的字典
- for i in range(data_length):
- label = datasets[i][j]#数据集的最后一列
- if label not in label_count:#如果标签(Label)没有放入统计次数的字典,添加进去
- label_count[label] = 0
- label_count[label] += 1#Label计数
- ent = -sum([(p / data_length) * log(p / data_length, 2)#计算经验熵
- for p in label_count.values()])
- return ent#返回经验熵
-
- """
- 函数说明:计算各个特征对于训练集的条件经验熵
- Parameters:
- datasets - 数据集
- j - 数据集第j列即特征值索引
- Returns:
- cond_ent - 条件经验熵(香农熵)
- """
- # 经验条件熵$ H(D|A)$
- def cond_ent(datasets, j):#参数j:指定特征
- data_length = len(datasets)
- feature_sets = {}
- for i in range(data_length):
- feature = datasets[i][j]
- if feature not in feature_sets:#如果特征没有放入统计次数的字典,添加进去
- feature_sets[feature] = []
- feature_sets[feature].append(datasets[i])#划分数据集
- cond_ent = sum(
- [(len(p) / data_length) * single_ent(p,-1) for p in feature_sets.values()])
- return cond_ent
-
- """
- 函数说明:计算某特征对于训练集的信息增益
- Parameters:
- datasets - 数据集
- j - 数据集第j列即特征值索引
- Returns:信息增益
-
- """
- # 信息增益
- def info_gain(datasets, j):
- return single_ent(datasets,-1)-cond_ent(datasets,j)
- """
- 函数说明:计算某特征对于训练集的信息增益比
- Parameters:
- datasets - 数据集
- j - 数据集第j列即特征值索引
- Returns:信息增益比
- """
- # 信息增益比
- def info_gain_ratio(datasets,j):
- return 0 if single_ent(datasets,j)==0 else info_gain(datasets,j)/single_ent(datasets,j)
-
- """
- 函数说明:输出所有特征信息增益,并选择信息增益最大的特征,为根结点特征
- Parameters:
- datasets - 数据集
- Returns:
- bestFeature - 信息增益最大的(最优)特征的索引值
- """
- def info_gain_bestfeature(datasets):
- count = len(datasets[0]) - 1 #特征数量
- features = [] #记录各个特征的信息增益
- for c in range(count):
- c_info_gain = info_gain(datasets,c)#信息增益
- features.append((c, c_info_gain))
- print('特征({}) - 信息增益 - {:.3f}'.format(labels[c], c_info_gain))
- # 比较大小
- best_ = max(features, key=lambda x: x[-1])
- bestFeature=best_[0]
- return '特征({})的信息增益最大,选择为根节点特征'.format(labels[best_[0]])
-
- """
- 函数说明:输出所有特征信息增益比,并选择信息增益比最大的特征,为根结点特征
- Parameters:
- datasets - 数据集
- Returns:
- bestFeature - 信息增益最大的(最优)特征的索引值
- """
- def info_gain_ratio_bestfeature(datasets):
- count = len(datasets[0]) - 1 #特征数量
- features1 = [] #记录各个特征的信息增益
- for c in range(count):
- c_info_gain_ratio = info_gain_ratio(datasets,c)#信息增益比
- features1.append((c, c_info_gain_ratio))
- print('特征({}) - 信息增益比 - {:.3f}'.format(labels[c], c_info_gain_ratio))
- # 比较大小
- best_ = max( features1, key=lambda x: x[-1])
- bestFeature=best_[0]
- return '特征({})的信息增益比最大,选择为根节点特征'.format(labels[best_[0]])

实现上述案例表5.1
1. 创建数据表
- def create_data():
- datasets = [['青年', '否', '否', '一般', '否'],
- ['青年', '否', '否', '好', '否'],
- ['青年', '是', '否', '好', '是'],
- ['青年', '是', '是', '一般', '是'],
- ['青年', '否', '否', '一般', '否'],
- ['中年', '否', '否', '一般', '否'],
- ['中年', '否', '否', '好', '否'],
- ['中年', '是', '是', '好', '是'],
- ['中年', '否', '是', '非常好', '是'],
- ['中年', '否', '是', '非常好', '是'],
- ['老年', '否', '是', '非常好', '是'],
- ['老年', '否', '是', '好', '是'],
- ['老年', '是', '否', '好', '是'],
- ['老年', '是', '否', '非常好', '是'],
- ['老年', '否', '否', '一般', '否'],
- ]
- labels = [u'年龄', u'有工作', u'有自己的房子', u'信贷情况', u'类别']
- #返数据集和每个维度的名称
- return datasets, labels
可以表格的形式查看原表格(非必要的一步)
- datasets, labels = create_data()
- train_data = pd.DataFrame(datasets, columns=labels)
- train_data
2. 套用上述模块
info_gain_bestfeature(np.array(datasets))运行结果
查看结果,与航统计学习方法书上例题5.2答案一样。
info_gain_ratio_bestfeature(np.array(datasets))4.2 决策树算法
构建决策树的算法有很多,比如ID3、C4.5和CART。
4.2.1 ID3算法
ID3算法的核心是在决策树各个结点上应用信息增益准则选择特征,递归地构建决策树。
具体方法:
- 从根节点(root node)开始,对结点计算的所有可能的特征的信息增益,选择信息增益最大的特征作为该结点特征。
- 由该特征的不同取值建立子结点,再对子结点递归地调用以上方法,构建决策树;直到所有特征的信息增益均很小或没有特征可以选择为止。
- 最后得到一个决策树。
ID3算法相当于用极大似然法进行概率模型的选择。


决策树ID3算法的局限性
ID3算法虽然提出了新思路,但是还是有很多值得改进的地方。
- ID3没有考虑连续特征,比如长度、密度都是连续值,无法再ID3中运用。这大大限制了ID3的用途。
- ID3采用信息增益大的特征优先建立决策树的结点。很快人们发现,在相同条件下,取值比较多的特征比取值较少的特征信息增益大。比如一个变量由2个值,各为1/2,另一个变量为3个值,各为1/3,其实他们都是完全不确定的变量,但是取3个值得比取两个值得信息增益大。如何校正这个呢?
- ID3算法对于缺失值得情况没有考虑
- 没有考虑过拟合的问题
- ID3算法的作者昆兰基于上述不足,对ID3算法做了改进,这就是C4.5算法,下面我们就介绍C4.5算法。
4.2.2 C4.5算法
上一节我们讲到ID3算法有四个主要不足,一是不能处理连续特征,第二个是用信息增益为标准容易偏向于取值较多的特征,最后两个缺失值的处理问题和过拟合问题。昆兰在C4.5算法中改进了上述四个问题。
- 对于第一个问题,不能处理连续特征,C4.5的思路是将连续的特征离散化。比如m个样本的连续特征A有m个,从小到达排列为
,则C4.5取相邻两样本值得平均数,一共取得m-1个划分点,其中第i个划分点Ti表示为:
。对于这m-1个点,分别计算以该点作为二元分类时得信息增益。选择信息增益最大的点作为该连续特征的二元离散分类点。比如取到的增益最大的点为
,则小于
- 对于第二个问题,信息增益作为标准容易偏向于取值较多的特征的问题。我们引入一个信息增益比,用信息增益比选择特征。
- 对于第三个缺失值处理问题,主要解决的是两个问题,一是在样本某些特征缺失的情况下选择划分的属性,二是选定了划分属性,对于在该属性上缺失特征的样本的处理。《西瓜书》P85
- 对于第四个问题,C4.5引入了正则化系数进行初步的剪枝。

决策树C4.5算法的局限性
C4.5虽然改进或改善了ID3算法的几个主要问题,但是仍然存在优化的空间。
1)由于决策树算法非常容易过拟合,因此对于生成的决策树必须要进行剪枝。剪枝的算法有非常多,C4.5的剪枝方法有优化空间。思路主要有两种:一种是预剪枝,即在生成决策树的时候就决定是否剪枝。另一种是后剪枝,即先生成决策树,再通过交叉验证来剪枝。剪枝算法见下篇。
2)C4.5生成的是多叉树,即一个父结点可以有多个结点。很多时候,在计算机中二叉树模型会比多叉树运算效率高。如果采用二叉树,可以提高效率。
3)C4.5只能用于分类,如果能将决策树用于回归的话,可以扩大它的使用范围。
4)C4.5由于使用了熵模型,里面有大量的耗时的对数运算,如果是连续值还有大量的排序运算。如果能够加以模型简化可以减少运算强度但又不牺牲太多的准确性的话,就更好了。
这四个问题在CART算法里面部分加以了改进。所以目前如果不考虑集成算法学习的话,在普通的决策树算法里,CART算法是比较优的算法了。scikit_learn决策树使用的也是CART算法。在下篇我们会重点介绍CART算法的主要改进思路。
4.2.3 Python实现ID3、C4.5算法
由于ID3算法和C4.5算法相似,因此可以写一个python模块,只不过增加一个选方法(信息增益 or 信息增益比)的函数。
【代码实现,构建决策树】
第一部分:构建决策树
- import numpy as np
- import pandas as pd
- import matplotlib.pyplot as plt
- %matplotlib inline
- import math
- import operator
- from matplotlib.font_manager import FontProperties
- from math import log
- import pprint
- from sklearn.datasets import load_iris
- from collections import Counter
-
- """
- 函数说明:计算经验熵(香农熵)
- Parameters:
- datasets - 数据集
- j-数据集第j列
- Returns:
- ent - 经验熵(香农熵)
- 当j=-1时,返回训练数据集D的经验熵
- 当j为其他时,返回训练数据集关于第j特征的值的熵
- """
- def single_ent(datasets,j):
- data_length = len(datasets)#返回数据集的行数即样本个数
- label_count = {}#保存每个标签(Label)出现次数的字典
- for i in range(data_length):
- label = datasets[i][j]#数据集的最后一列
- if label not in label_count:#如果标签(Label)没有放入统计次数的字典,添加进去
- label_count[label] = 0
- label_count[label] += 1#Label计数
- ent = -sum([(p / data_length) * log(p / data_length, 2)#计算经验熵
- for p in label_count.values()])
- return ent#返回经验熵
- """
- 函数说明:计算各个特征对于训练集的条件经验熵
- Parameters:
- datasets - 数据集
- j - 数据集第j列即特征值索引
- Returns:
- cond_ent - 条件经验熵(香农熵)
- """
- # 经验条件熵$ H(D|A)$
- def cond_ent(datasets, j):#参数j:指定特征
- data_length = len(datasets)
- feature_sets = {}
- for i in range(data_length):
- feature = datasets[i][j]
- if feature not in feature_sets:#如果特征没有放入统计次数的字典,添加进去
- feature_sets[feature] = []
- feature_sets[feature].append(datasets[i])#划分数据集
- cond_ent = sum(
- [(len(p) / data_length) * single_ent(p,-1) for p in feature_sets.values()])
- return cond_ent
- """
- 函数说明:计算某特征对于训练集的信息增益
- Parameters:
- datasets - 数据集
- j - 数据集第j列即特征值索引
- Returns:信息增益
-
- """
-
- # 信息增益
- def info_gain(datasets, j):
- return single_ent(datasets,-1)-cond_ent(datasets,j)
- """
- 函数说明:计算某特征对于训练集的信息增益比
- Parameters:
- datasets - 数据集
- j - 数据集第j列即特征值索引
- Returns:信息增益比
-
- """
- # 信息增益比
- def info_gain_ratio(datasets,j):
- return 0 if single_ent(datasets,j)==0 else info_gain(datasets,j)/single_ent(datasets,j)
-
- """
- 函数说明:选取最优特征
- Parameters:
- datasets - 数据集
- method-选择最优特征准则:ID3:依据信息增益;C4.5:依据信息增益比
- Returns:
- bestFeature - 信息增益最大的(最优)特征的索引值
- """
- def bestfeature(datasets,method='ID3'):
- assert method in ['ID3','C4.5'],"method 须为id3或c45"
- def calcEnt(datasets,j):
- if method=='ID3':
- return info_gain(datasets,j)
- if method=='C4.5':
- return info_gain_ratio(datasets,j)
- count = len(datasets[0]) - 1 #特征数量
- features = [] #记录各个特征的信息增益
-
- for c in range(count):
- c_info_gain = calcEnt(datasets,c)#信息增益
- features.append((c, c_info_gain))
- #print('特征({}) - 信息增益 - {:.3f}'.format(labels[c], c_info_gain))
- # 比较大小
- best_ = max(features, key=lambda x: x[-1])
- bestFeature=best_[0]
- return bestFeature
-
- """
- 函数说明:统计classList中出现最多的类标签
- Parameters:
- classList - 类标签列表
- Returns:
- sortedClassCount[0][0] - 出现此处最多的元素(类标签)
- """
- def majorityCnt(classList):
- classCount = {}
- for vote in classList: #统计classList中每个元素出现的次数
- if vote not in classCount.keys():classCount[vote] = 0
- classCount[vote] += 1
- sortedClassCount = sorted(classCount.items(), key = operator.itemgetter(1), reverse = True) #根据字典的值降序排序
- return sortedClassCount[0][0] #返回classList中出现次数最多的元素
-
-
- """
- 函数说明:按照给定特征划分数据集
- Parameters:
- datasets - 待划分的数据集
- axis - 划分数据集的特征
- value - 需要删除的特征的值
- Returns:
- 无
- """
- def splitDataSet(datasets, axis, value):
- retDataset = [] #创建返回的数据集列表
- for featVec in datasets: #遍历数据集
- if featVec[axis] == value:
- reducedFeatVec = featVec[:axis] #去掉axis特征
- reducedFeatVec.extend(featVec[axis+1:]) #将符合条件的添加到返回的数据集
- retDataset.append(reducedFeatVec)
- return retDataset #返回划分后的数据集
-
-
-
- """
- 函数说明:创建决策树
- Parameters:
- datasets - 训练数据集
- labels - 分类属性标签
- featLabels - 存储选择的最优特征标签
- Returns:
- myTree - 决策树
- """
- def createTree(datasets, labels, featLabels):
- classList = [example[-1] for example in datasets] #取分类标签(是否放贷:yes or no)
- if classList.count(classList[0]) == len(classList): #1、如果类别完全相同则停止继续划分
- return classList[0]
- if len(datasets[0]) == 1: #2、如果特征集为空即数据集只有1列
- return majorityCnt(classList) #遍历完所有特征时返回出现次数最多的类标签
- bestFeat = bestfeature(datasets,method='ID3') #3、选择最优特征,方法可以更改
- bestFeatLabel = labels[bestFeat] #最优特征的标签
- featLabels.append(bestFeatLabel)
- myTree = {bestFeatLabel:{}} #根据最优特征的标签生成树
- del(labels[bestFeat]) # 已经选择的特征不再参与分类
- featValues = [example[bestFeat] for example in datasets] #得到训练集中所有最优特征的属性值
- uniqueVals = set(featValues) #去掉重复的属性值
- for value in uniqueVals: #遍历特征,创建决策树。
- myTree[bestFeatLabel][value] = createTree(splitDataSet(datasets, bestFeat, value), labels, featLabels)
- return myTree
第二部分:决策树可视化
- """
- 函数说明:获取决策树叶子结点的数目
- Parameters:
- myTree - 决策树
- Returns:
- numLeafs - 决策树的叶子结点的数目
- """
- def getNumLeafs(myTree):
- numLeafs = 0 #初始化叶子
- firstStr = next(iter(myTree)) #python3中myTree.keys()返回的是dict_keys,不在是list,所以不能使用myTree.keys()[0]的方法获取结点属性,可以使用list(myTree.keys())[0]
- secondDict = myTree[firstStr] #获取下一组字典
- for key in secondDict.keys():
- if type(secondDict[key]).__name__=='dict': #测试该结点是否为字典,如果不是字典,代表此结点为叶子结点
- numLeafs += getNumLeafs(secondDict[key])
- else: numLeafs +=1
- return numLeafs
- """
- 函数说明:获取决策树的层数
- Parameters:
- myTree - 决策树
- Returns:
- maxDepth - 决策树的层数
- """
- def getTreeDepth(myTree):
- maxDepth = 0 #初始化决策树深度
- firstStr = next(iter(myTree)) #python3中myTree.keys()返回的是dict_keys,不在是list,所以不能使用myTree.keys()[0]的方法获取结点属性,可以使用list(myTree.keys())[0]
- secondDict = myTree[firstStr] #获取下一个字典
- for key in secondDict.keys():
- if type(secondDict[key]).__name__=='dict': #测试该结点是否为字典,如果不是字典,代表此结点为叶子结点
- thisDepth = 1 + getTreeDepth(secondDict[key])
- else: thisDepth = 1
- if thisDepth > maxDepth: maxDepth = thisDepth #更新层数
- return maxDepth
-
- """
- 函数说明:绘制结点
- Parameters:
- nodeTxt - 结点名
- centerPt - 文本位置
- parentPt - 标注的箭头位置
- nodeType - 结点格式
- Returns:
- 无
- """
- def plotNode(nodeTxt, centerPt, parentPt, nodeType):
- arrow_args = dict(arrowstyle="<-") #定义箭头格式
- font = FontProperties(fname=r"c:\windows\fonts\simsun.ttc", size=14) #设置中文字体
- createPlot.ax1.annotate(nodeTxt, xy=parentPt, xycoords='axes fraction', #绘制结点
- xytext=centerPt, textcoords='axes fraction',
- va="center", ha="center", bbox=nodeType, arrowprops=arrow_args, FontProperties=font)
-
- """
- 函数说明:标注有向边属性值
- Parameters:
- cntrPt、parentPt - 用于计算标注位置
- txtString - 标注的内容
- Returns:
- 无
- """
- def plotMidText(cntrPt, parentPt, txtString):
- xMid = (parentPt[0]-cntrPt[0])/2.0 + cntrPt[0] #计算标注位置
- yMid = (parentPt[1]-cntrPt[1])/2.0 + cntrPt[1]
- createPlot.ax1.text(xMid, yMid, txtString, va="center", ha="center", rotation=30)
-
- """
- 函数说明:绘制决策树
- Parameters:
- myTree - 决策树(字典)
- parentPt - 标注的内容
- nodeTxt - 结点名
- Returns:
- 无
- """
- def plotTree(myTree, parentPt, nodeTxt):
- decisionNode = dict(boxstyle="sawtooth", fc="0.8") #设置结点格式
- leafNode = dict(boxstyle="round4", fc="0.8") #设置叶结点格式
- numLeafs = getNumLeafs(myTree) #获取决策树叶结点数目,决定了树的宽度
- depth = getTreeDepth(myTree) #获取决策树层数
- firstStr = next(iter(myTree)) #下个字典
- cntrPt = (plotTree.xOff + (1.0 + float(numLeafs))/2.0/plotTree.totalW, plotTree.yOff) #中心位置
- plotMidText(cntrPt, parentPt, nodeTxt) #标注有向边属性值
- plotNode(firstStr, cntrPt, parentPt, decisionNode) #绘制结点
- secondDict = myTree[firstStr] #下一个字典,也就是继续绘制子结点
- plotTree.yOff = plotTree.yOff - 1.0/plotTree.totalD #y偏移
- for key in secondDict.keys():
- if type(secondDict[key]).__name__=='dict': #测试该结点是否为字典,如果不是字典,代表此结点为叶子结点
- plotTree(secondDict[key],cntrPt,str(key)) #不是叶结点,递归调用继续绘制
- else: #如果是叶结点,绘制叶结点,并标注有向边属性值
- plotTree.xOff = plotTree.xOff + 1.0/plotTree.totalW
- plotNode(secondDict[key], (plotTree.xOff, plotTree.yOff), cntrPt, leafNode)
- plotMidText((plotTree.xOff, plotTree.yOff), cntrPt, str(key))
- plotTree.yOff = plotTree.yOff + 1.0/plotTree.totalD
-
- """
- 函数说明:创建绘制面板
- Parameters:
- inTree - 决策树(字典)
- Returns:
- 无
- """
- def createPlot(inTree):
- fig = plt.figure(1, facecolor='white') #创建fig
- fig.clf() #清空fig
- axprops = dict(xticks=[], yticks=[])
- createPlot.ax1 = plt.subplot(111, frameon=False, **axprops) #去掉x、y轴
- plotTree.totalW = float(getNumLeafs(inTree)) #获取决策树叶结点数目
- plotTree.totalD = float(getTreeDepth(inTree)) #获取决策树层数
- plotTree.xOff = -0.5/plotTree.totalW; plotTree.yOff = 1.0; #x偏移
- plotTree(inTree, (0.5,1.0), '') #绘制决策树
- plt.show() #显示绘制结果
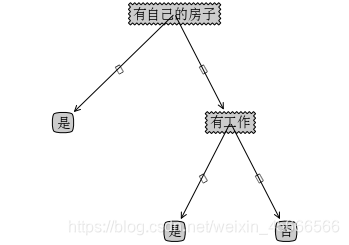
案例:


- if __name__ == '__main__':
- datasets, labels = create_data()#上一例子已创建
- featLabels = []
- myTree = createTree(datasets, labels, featLabels)
- print(myTree)
- createPlot(myTree)
4.3 决策树的剪枝
引言
在上半部分我们介绍了决策树模型,以及决策树生成算法:决策树生成算法递归的产生决策树,直到不能继续下去为止。这样产生的树往往对训练数据的分类很准确,但是对未知的测试数据的分类却没有那么准确,即容易出现过拟合现象。解决这个问题的办法是考虑决策树的复杂度,对已经生成的决策树进行简化,下面来探讨决策树的剪枝算法。
4.3.1 算法目的
决策树的剪枝是为了简化决策树模型,避免过拟合。
- 同样层数的决策树,叶结点的个数越多越复杂;同样的叶结点个数的决策树,层数越多越复杂。
- 剪枝前相比于剪枝后,叶结点个数和层数只能更多或者其中一特征一样多,剪枝前必然更复杂。
- 层数越多,叶结点越多,分的越细致,对训练数据分的也越深,越容易过拟合,导致对测试数据预测时反而效果差,泛化能力差。
4.3.2 算法基本思路
剪去决策树模型中的一些子树或者叶节点,并将其上层的根结点作为新的叶结点,从而减少了叶结点甚至减少了层数,降低了决策树复杂度。
决策树的剪枝往往通过极小化决策树整体的损失函数或代价函数来实现。
4.3.3 决策树损失函数
设树T的叶节点个数为∣T∣,t 是树T的叶节点,该叶结

- C(T)表示模型对训练数据的预测误差,即模型与训练数据的拟合程度,|T|表示模型复杂度。
- α|T|是为了避免过拟合,给优化目标函数增加一个正则项,正则项包含模型的复杂度信息|T|。对于决策树来说,其叶结点的数量|T|越多就越复杂。
- 参数α控制了两者之间的影响程度,较大的α促使选择较简单的模型(树),较小的α促使选择较复杂的模型(树),α=0意味着只考虑模型与训练数据的拟合程度,不考虑模型复杂度。
- 上式定义的损失函数
的极小化等价于正则化的极大似然估计。
剪枝,就是当α确定时,选择损失函数最小的模型,即损失函数最小的子树。当α确定时,子树越大,往往与训练数据的拟合越好,但是模型的复杂度就越高;相反,子树越小,模型的复杂度越低,但是往往与训练数据的拟合不好。损失函数正好表示了对两者的平衡。
4.3.4 剪枝类型——预剪枝、后剪枝、两种剪枝策略对比
决策树的剪枝基本策略有 预剪枝 (Pre-Pruning) 和 后剪枝 (Post-Pruning) [Quinlan, 1933]。根据周志华老师《机器学习》一书中所描述是先对数据集划分成训练集和验证集,训练集用来决定树生成过程中每个结点划分所选择的属性/特征;验证集在预剪枝中用于决定该结点是否有必要依据该属性/特征进行展开,在后剪枝中用于判断该结点是否需要进行剪枝。
(1)预剪枝
预剪枝是在决策树生成过程中,对树进行剪枝,提前结束树的分支生长。
加入预剪枝后的决策树生成流程图如下:

其中的核心思想就是,在每一次实际对结点进行进一步划分之前,先采用验证集的数据来验证划分是否能提高划分的准确性。如果不能,就把结点标记为叶结点并退出进一步划分;如果可以就继续递归生成节点。
(2) 后剪枝
后剪枝是在决策树生长完成之后,对树进行剪枝,得到简化版的决策树。
周志华老师《机器学习》中述说如下:
后剪枝则是先从训练集生成一颗完整的决策树,然后自底向上地对非叶结点进行考察,若将该结点对应的子树替换为叶结点能带来泛化性能提升,则将该子树替换为叶结点。
李航《统计学习方法》中述说如下:
输入:生成算法产生的整个树T,参数α
输出:修剪后的子树Tα
- 计算每个结点的经验熵
- 递地从树的叶结点向上回缩
设一组叶结点回缩到父结点之前与之后的整体树分别为
和
,其对应的损失函数值分别是与
和
,如果
则进行剪枝,即将父节点变为新的叶节点。
3. 返回(2),直至不能继续为止,得到损失函数最小的子树Tα
(3)两种剪枝策略对比
- 后剪枝决策树通常比预剪枝决策树保留了更多的分支;
- 后剪枝决策树的欠拟合风险很小,泛化性能往往优于预剪枝决策树;
- 后剪枝决策树训练时间开销比未剪枝决策树和预剪枝决策树都要大的多。
总结
优点:
- 计算复杂度不高;
- 对中间缺失值不敏感;
- 解释性强,在解释性方面甚至比线性回归更强;
- 与传统的回归和分类方法相比,决策树更接近人的决策模式,可以用图形表示,非专业人士也可以轻松理解;
- 可以直接处理定性的预测变量而不需创建哑变量。
缺点:
-
决策树的预测准确性一般比回归和分类方法弱,但可以通过用集成学习方法组合大量决策树,显著提升树的预测效果;
-
可能会产生过度匹配的问题
1、三种算法对比:
1. ID3算法:
- 采用信息增益作为评价标准
- 只能描述属性为离散型属性的数据集构造决策树(只能处理离散属性数据)
- 缺点是倾向于选择取值较多的属性,有些情况下这类属性可能不会提供太多有价值的信息。
2. C4.5算法(做出的改进,为什么C4.5好)
- 用信息增益比作为评价标准
- 可以处理连续型属性
- 采用了后剪枝方法
- 对于缺失数据的处理
- 优化后解决的ID3分支过程中总喜欢偏向取值较多得属性 这个问题
优点: 产生的分类规则易于理解,准确率较高
缺点: 在构造树过程中,需要对数据进行多次的顺序扫描和排序,因而导致算法的低效。此外,由于使用后剪枝方法,所以只适合于能够驻留于内存的数据集,当数据集大得无法在内存中容纳时程序无法运行。
3.CART算法
- 相比于C4.5,采用了简化得二叉树模型,同时特征选择采用了近似得基尼指数来简化计算,是信息增益得简化版本,不再需要log计算
- C4.5不一定时二叉树,但CART一定是二叉树
- 可以进行分类和回归,可以处理离散属性和连续属性。
2、CART剪枝
剪枝原因
- 原因1:噪声、样本冲突,即错误的样本数据
- 原因2:特征即属性不能完全作为分类标准
- 原因3:巧合的规律性,数据量不够大。
预剪枝
- 限制结点最小样本数:每一个结点所包含的最小样本数,则该结点总数小于该数时,则不再分;
- 指定树的高度和深度:例如树的最大深度为4;
- 指定结点的最小熵:小于某个值时不再划分。随着树结点的增多,在训练集熵的精度单调上升,然而在测试集上的精度先上升后下降。
后剪枝
- 在已生成过拟合决策树上进行剪枝,可以得到简化版的剪枝决策树。
- C4.5耗内存,如果内存较小,树画不完就结束了;后剪枝也很消耗内存。
4、决策树算法API
sklearn.tree.DecisionTreeClassifier(criterion=‘gini’, max_depth=None, random_state=None)
参数介绍
- criterion
- 特征选择标准
- 默认基尼指数 ‘gini’,即CART算法
- 'entropy’为信息增益
剪枝的限制
- min_samples_split
- 内部节点再划分所需最小样本数
- 这个值限制了子树继续划分的条件,如果某节点的样本数少于min_samples_split,则不会继续再尝试选择最优特征来进行划分,默认是2
- 如果样本量不大,不需要管这个值;如果样本量级非常大,则推荐增大这个值,如十万样本时,建立决策树时,选择用min_samples_split=10。
- min_samples_leaf
- 叶子节点最少样本数
- 限制了叶子节点最少的样本数的整数。如果某叶子节点数目小于min_samples_leaf,则会和兄弟节点一起被剪枝。默认是1
- 可以输入最少的样本树的整数,或者最少样本数占样本总数的百分比。如果样本量不大,不需要管这个值;如果样本量级非常大,则推荐增大这个值,如十万样本时,建立决策树时,选择用min_samples_split=5。
- max_depth
- 决策树最大深度
- 默认可以不输入,此时决策树建立子树时不会限制子树的深度。如果样本量不大,不需要管这个值;如果模型样本量多,特征也多的情况下,推荐限制这个最大深度,具体取值取决于数据的分布,常用的可以取值在10-100之间
- random_state
- 随机数种子
4.1 案例:泰坦尼克号乘客生存预测
在泰坦尼克号和titanic2数据帧描述泰坦尼克号上的个别乘客的生存状态。我们提取的数据集中的特征时票的类别,存活,乘坐班,年龄,登陆,home.dest,房间,票,船,性别等
数据:http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic.txt
- 乘坐班是指乘客班(1,2,3),是社会经济阶层的代表
- 其中age数据存在缺失
1. 步骤分析
- 1.获取数据
- 2.数据基本处理
- 2.1 确定特征值,目标值
- 2.2 缺失值处理
- 2.3 数据集划分
- 3.特征工程
- 4.机器学习
- 5.模型评估
2. 代码过程
- 导入需要的模块
- import pandas as pd
- import numpy as np
- from sklearn.feature_extraction import DictVectorizer
- from sklearn.model_selection import train_test_split
- from sklearn.tree import DecisionTreeClassifier
- from sklearn.tree import export_graphviz
- 1. 获取数据
-
- data = pd.read_csv("http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic.txt")
- data
data.describbe()
- 2. 数据基本处理
2.1 确定特征值,目标值
- x = data[['pclass','age','sex']]
- x.head()
- y = data['survived']
- y.head()
2.2 缺失值处理
- x['age'].fillna(value=data['age'].mean(), inplace=True)
- x
2.3 数据集划分
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=22, test_size=0.2)
- 3.特征工程(字典特征抽取)
特征中出现类别符号,需要进行one-hot编码处理(DictVectorizer)
x.to_dict(orient=‘records’) 需要将数组特征转化成字典数据
- x_train = x_train.to_dict(orient='records')
- x_test = x_test.to_dict(orient='records')
- x_train
- x_test
- #字典特征抽取
- transfer = DictVectorizer(sparse=False)
-
- x_train = transfer.fit_transform(x_train)
- x_test = transfer.fit_transform(x_test)
- #整合到一起
- # transfer = DictVectorizer(sparse=False)
-
- # x_train = transfer.fit_transform(x_train.to_dict(orient='records'))
- # x_test = transfer.fit_transform(x_test.to_dict(orient='records'))
x_train #变成一个对象
- 4.决策树模型训练:机器学习
决策树API中,如果没有指定max_depth那么会根据信息熵的条件知道最终结束。这里我们指定树的深度来进行限制树的大小。
- estimator = DecisionTreeClassifier(criterion='entropy')
- estimator.fit(x_train,y_train)
min_samples_split、min_samples_leaf、max_depth三个参数可以控制树的大小,相当于CART剪枝
- 5.模型评估
- #模型预测
- y_pre = estimator.predict(x_test)#预测值
- ret = estimator.score(x_test, y_test)#准确率
决策树是可以展示的
3. 决策树可视化
- sklearn.tree.export_graphviz() 该函数能够导出DOT格式
- tree.export_graphviz(estimator, out_file=‘tree.dot’, feature_names=[‘’,‘’])
- estimator:哪个训练模型
- out_file:输出的名字
- feature_names:特征名字
- tree.export_graphviz(estimator, out_file=‘tree.dot’, feature_names=[‘’,‘’])
- # 6.决策树可视化
- export_graphviz(estimator, out_file="./data/titan_tree.dot", feature_names=['age','pclass=1st','pclass=2nd','pclass=3rd','女性','‘男性'])
注意
export_graphviz()可以导出一个DOT文件,打开复制全部内容,进入网址http://webgraphviz.com,将DOT文件的内容复制进去就可以产生树。可以通过DecisionTreeClassifer训练机器模型时设置三个参数进行CART剪枝,减轻过拟合
总结
- import numpy as np
- import pandas as pd
- from sklearn.selection import train_test_split#数据集划分
- from sklearn.feature_extraction import DictVectorizer #特征工程:字典特征提取(类别)
- from sklearn.tree import DecisionTreeClassifier
- from sklearn.tree import export_graphviz
-
- # 1.获取数据
- data = pd.read('')
- data.describe()
- # 2.数据基本处理
- # 2.1 确定特征值,目标值
- x = data[['pclass','age','sex']]
- y = data['survived']
- # 2.2 缺失值处理
- x['age'].fillna(value=x['age'].mean(), inplace = True)
- # 2.3 数据集划分
- x_train, x_test, y_train, y_test = train_test_split(x,y,random_state=22,test_size=0.2)
- # 3.特征工程(文字特征提取——字典特征提取)
- x_train =x_train.to_dict(orient='records')
- x_test = x_test.to_dict(orient='records')#转化为字典
- # x = x.to_dict(orient='records')
- transfer = DictVectorizer(sparse=False)
- x_train = transfer.fit_transform(x_train)
- x_test = transfer.fit_transform(x_test)
- # 4.机器学习
- estimator = DecisionTreeClassifier(criterion='entropy',max_depth=5) #min_samples_split、min_samples_leaf、max_depth参数可以做CART剪枝
- estimator.fit(x_train,y_train)
- # 5.模型评估
- y_pre = estimator.predict(x_test)
- ret = estimator.score(x_test,y_test)
- # 6.决策树可视化
- export_graphviz(estimator, out_file='./data/titan_tree.dot', feature_names=['age','pclass=1st','pclass=2nd','pclass=3rd','男性','女性'])
- # 输出DOT文件,将文件内容复制到http://webgraphviz.com,即可得到决策树
决策树优点:
- 简单容易理解和解释,树木可视化
缺点:
- 决策树学习者可以创建不能很好地推广数据的过于复杂的树,容易发生过拟合
过拟合的改进:
- CART剪枝算法:max_depth、min_samples_split、min_samples_leaf参数的设置,DecisionTreeClassifier中
- 随机森林(集成学习的一种):一棵树代表不了全部,那么就用一片森林来代表全部
注:企业重决策,由于决策树由很好的分析能力,在决策过程中应用很多,可以选择特征。保守,需要知道每一步在干什么。
回归问题API
sklearn.tree.DecisionTreeRegressor


