
- 1MySQL MVCC
- 2深度学习笔记: Sigmoid激活函数_sigmoid函数
- 3leetcode 224:基本计算器_给你个字符串表达式s,请使用一种您熟悉的语言(c java, python)实现一个基本计算器
- 4第一章 Web应用基础_在web应用软件的基本结构中,客户端的基础是
- 5Docker安装jenkins,并且创建maven任务_docker下jenkins配置maven
- 6万字长文!用文本挖掘深度剖析54万首诗歌
- 7C语言[编程入门]链表之报数问题(环链表)_链表 报数问题
- 8Python中的时间序列分析与预测技术_python时间序列相关性什么指标最好
- 9springboot中 druid数据源密码加密_passwordcallbackclassname
- 10QNX在车机系统的应用_车机qnx
电商API接口|爬虫案例|采集某东商品评论信息_电商爬虫
赞
踩
前言:
平常大家都有网上购物的习惯,在商品下面卖的好的产品基本都会有评论,当然也不排除有刷评论的情况,因为评论会影响我们的购物决策。今天主要分享用python+re正则表达式获取京东商品评论。API接口获取京东平台商品详情SKU数据!
环境准备:
pyhon编译器版本python3.7.4
集成开发环境(IDE)pycharm版本2020.1.5
相关包的安装
pip install requests
整体框架:
-
分析商品评论网页
-
发送请求,获取响应内容
-
re正则表达式提取信息
-
pandas保存信息
-
运行主程序
-
总结
-
分析网页
打开京东官网,我搜的是电脑,因为是获取商品的评论,我选了评论数比较多的产品,然后可以在下方可以看到商品的评论。
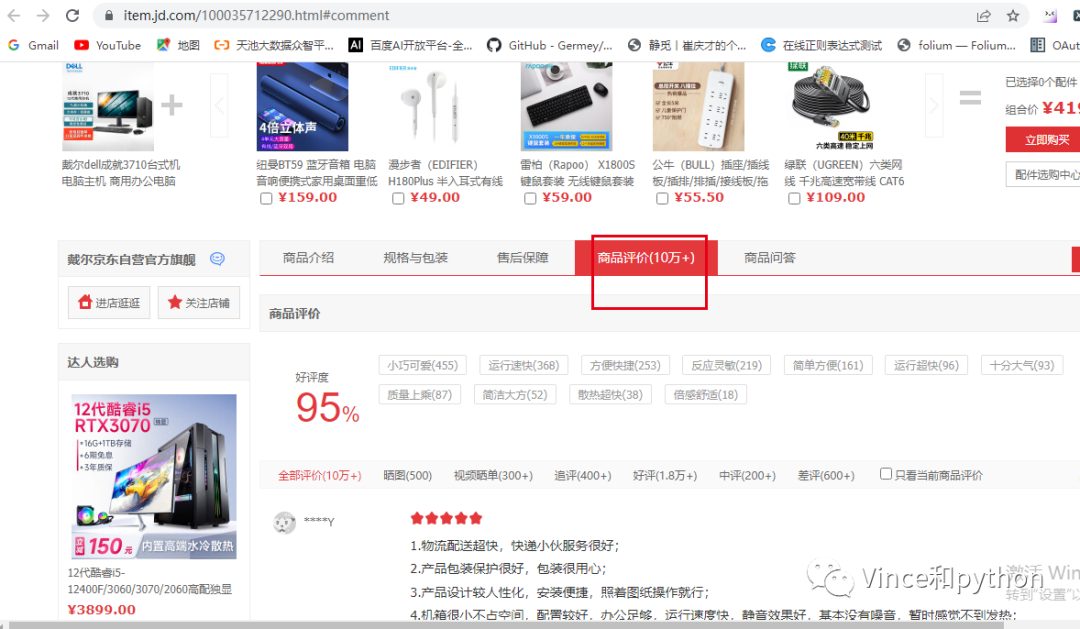
接下来就是按F12,选择网页。然后点击第二页刷新网页。在往下拉的过程中可以看到有个productPageComments.......页面,点击然后看下预览。下方就可以看到评论信息comments,依次点开后查看第一个信息,网页往上拉返回可以看到网页的信息和我们要查看的信息一致。
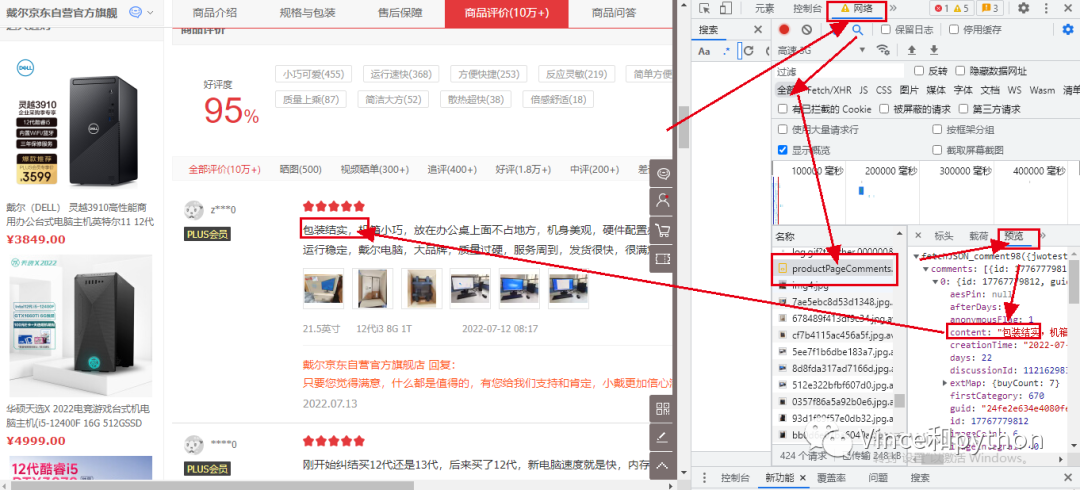
正是我们需要找的信息,这里注意的是因为选择第二页刷新的信息,如果第一页刷新过,也有第一页的网页productPageComments,如何去辨别呢。我们可以看下参数信息,也就是查看载荷。
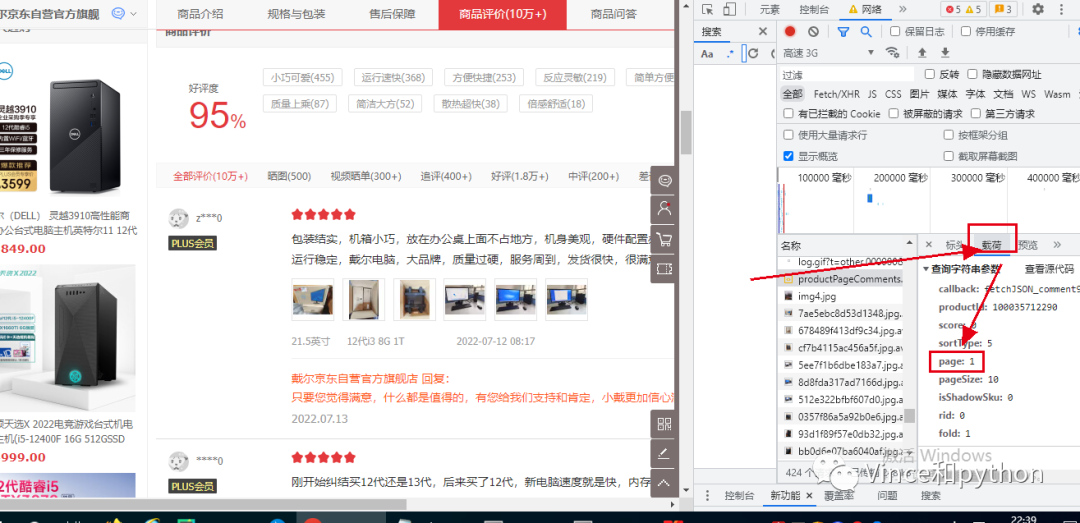
看下参数下面有个page:1。注意刷新的页面还是第二页。这个很容易判断是第一页。我们先滚动页面,继续找到productPageComments,然后可以看到载荷下面的参数page:0
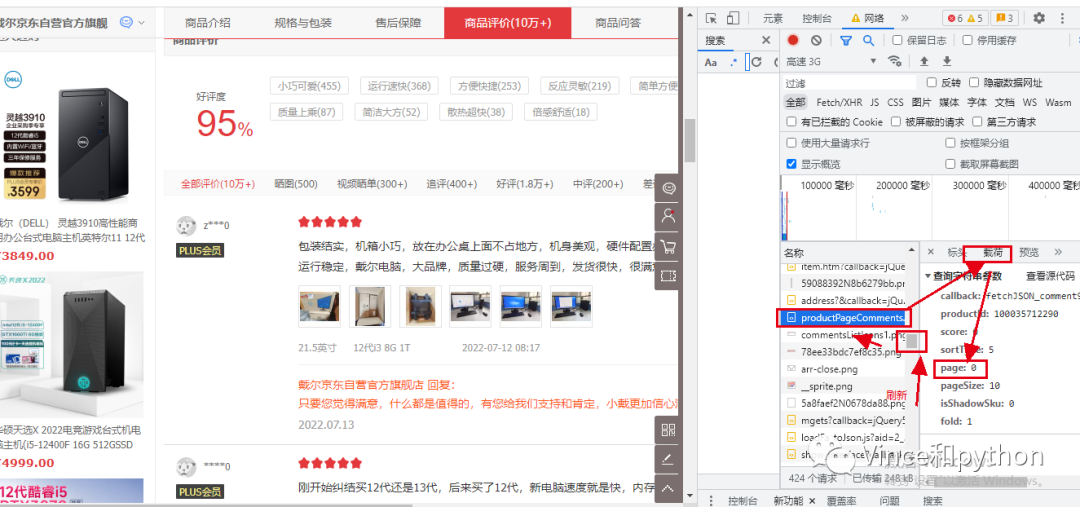
也就是页面的规律是从0开始的,我们可以再验证一下,选择第三页刷新看载荷下方的参数,顺便看下参数是否有加密。
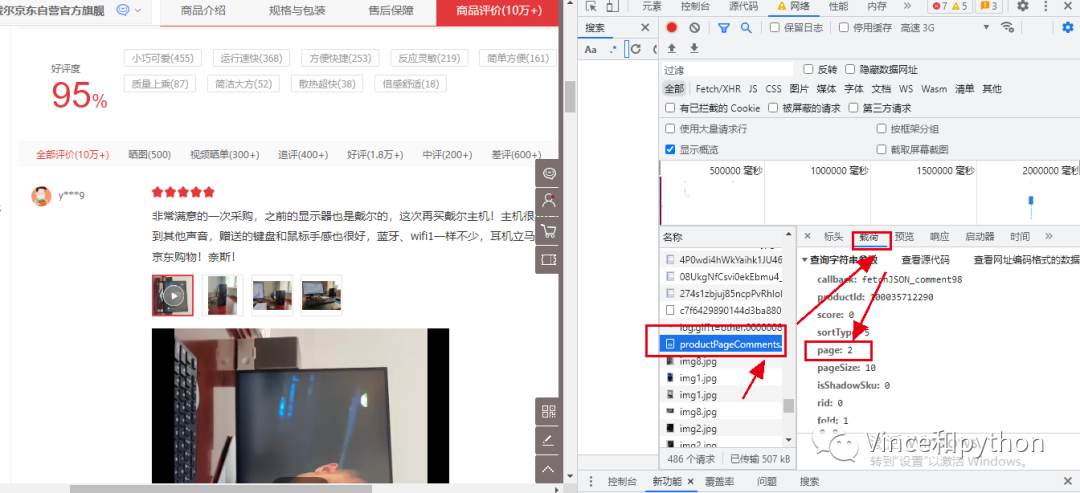
第三页可以发现page:2,说明页面就是从0开始的,然后看下其他的参数基本不变,没有出现加密的情况,变化的主要page。这就是我们要找的网页页面规律。
然后需要看下响应的内容,继续回到预览,可以看到一页有10条评论,初步判断格式比较像json格式,json格式的数据和python数据结构的字典比较类似,这里面涉及python的基本语法,不在这赘述。
2.发送请求,获取响应内容
首先看下标头信息
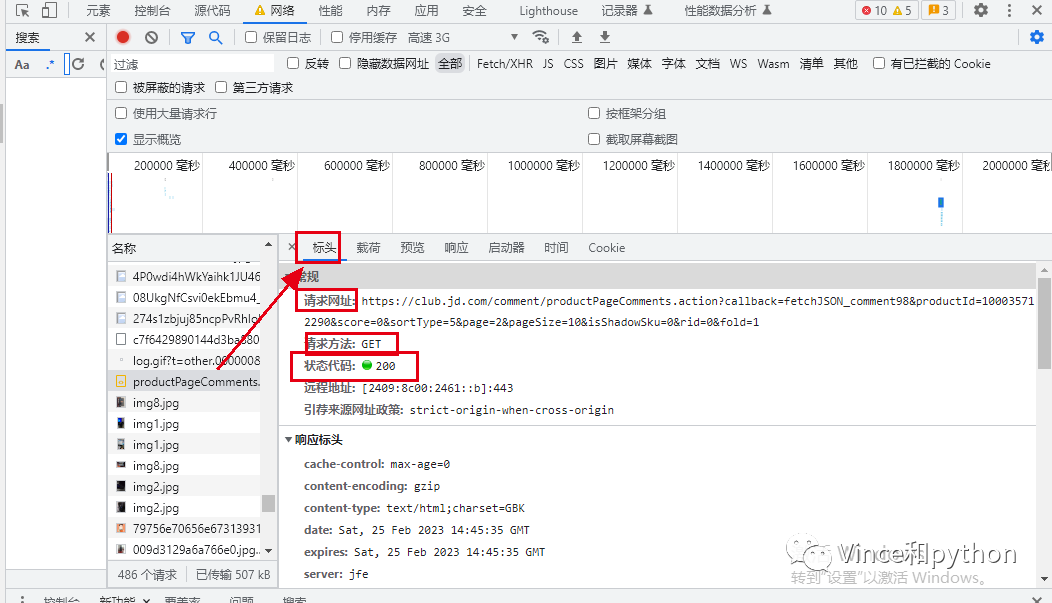
我们需要了解基本的请求网址,请求方法,状态码。
请求方法是get,后面就可以通过get方法向网页发送请求,有些网页是post。状态码是200,说明请求是ok的,如果遇到其他状态码,说明请求不成功,比如304,503。具体的状态码不在这赘述,可以网上查资料了解。不妨借助下ChatGPT的回答


ChatGPT的回答还是比较详细,给它点个赞

另外需要看的是请求标头下方的信息,比如cookie,user_agent。
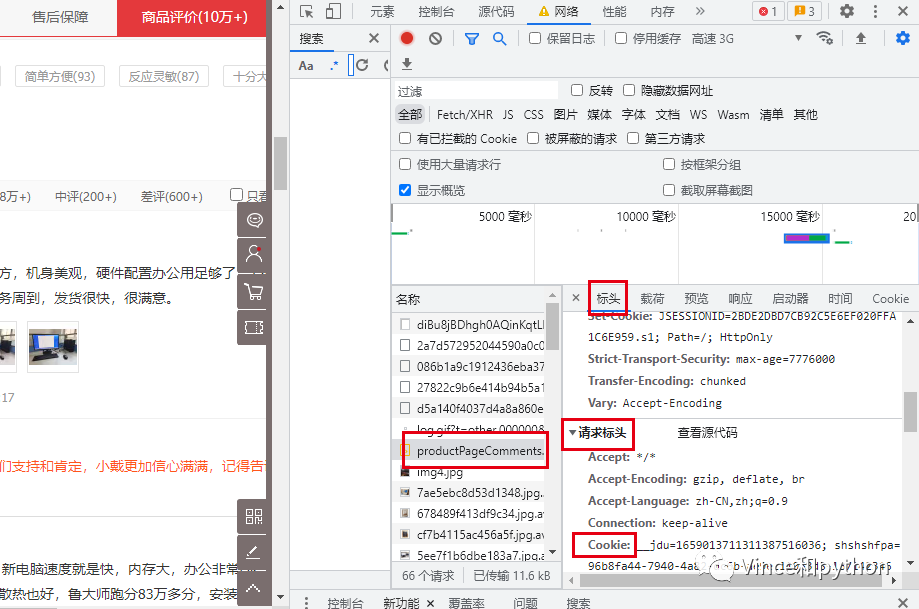
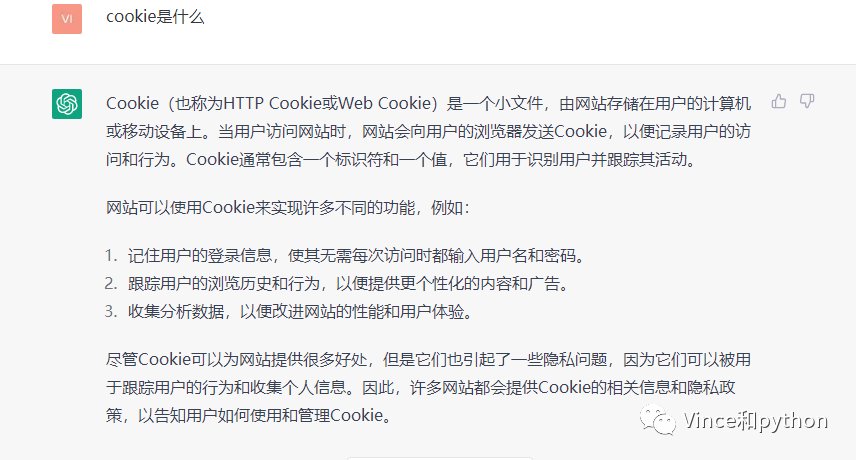
cookie是用来存储用户信息,服务器会去识别用户的信息。一般请求头需要带上cookie来做浏览器的伪装。下面看下百科的解释

然后对比下ChatGPT的回答
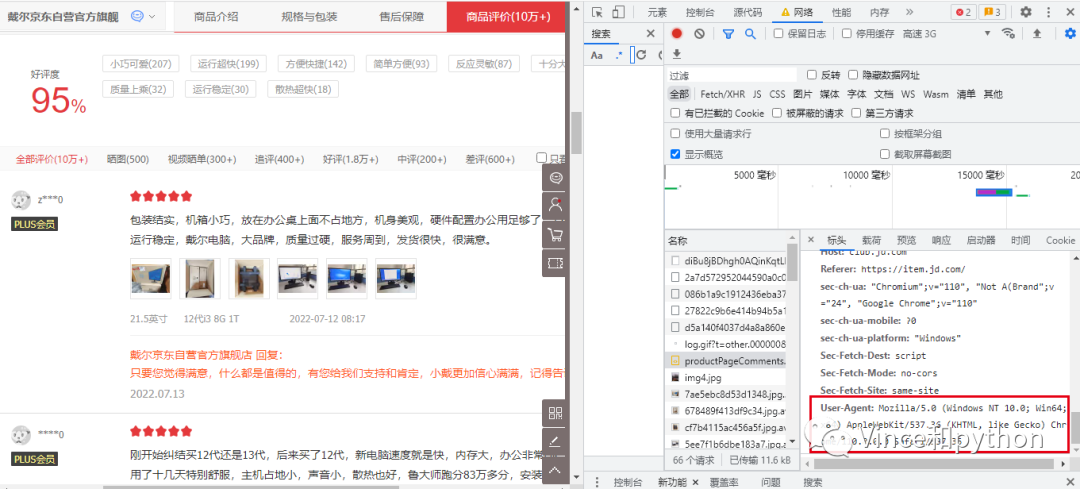
user_agent(用户代理)是电脑的基本信息,电脑系统的版本,用的浏览器版本等,一般也是用来做浏览器的伪装。
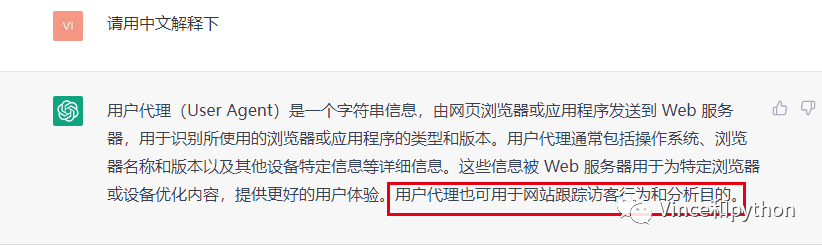
然后看下ChatGPT对User_agent的解释
接下来看下具体的请求代码
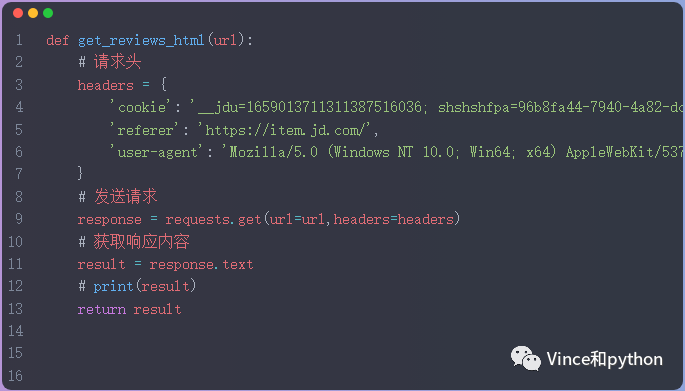
注释:定义函数获取响应内容,带上请求头信息,用requests 和get方法发送请求,text就是响应的内容。
3.re正则表达式提取信息
re(regular expression)正则表达式的作用是精确匹配网页的信息,提取关键信息,功能也是比较强大,比如提取用来数字包括小数,整数等,还可以用来提取邮箱,身份证信息等。
下面看下ChatGPT回答
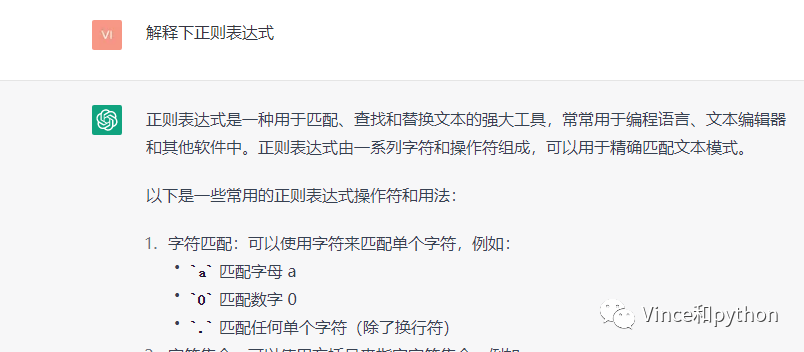
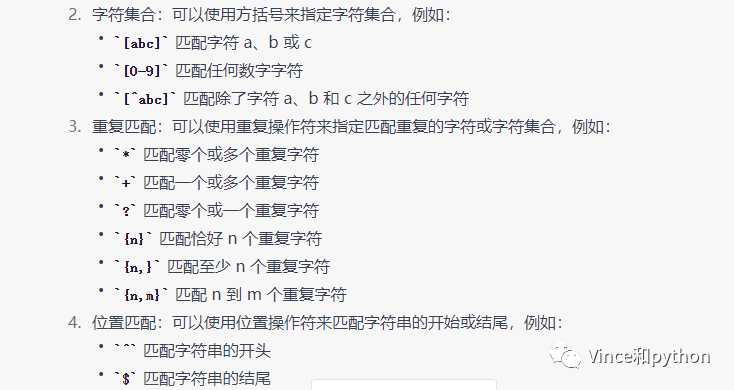
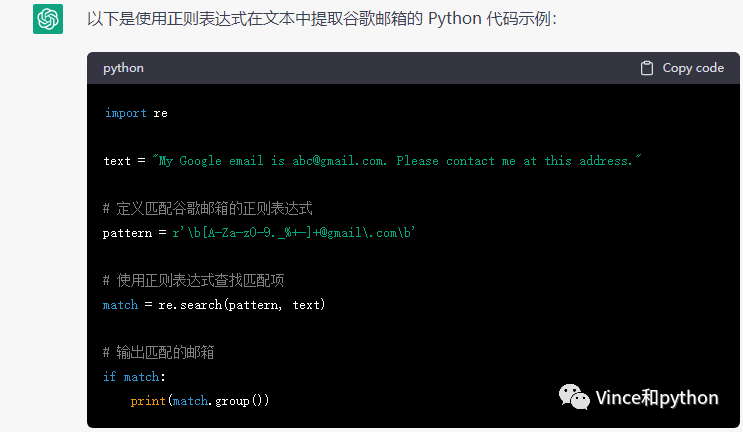
具体也可查阅其他资料详细了解其用法。
re提取信息的关键代码如下:

4.用pandas来保存信息。
相关代码如下

定义函数 参数是data,下面是字段名称,用pandas构造DataFrame保存到excel表格中。
5.运行主程序
考虑到程序的性能和评论的时效性,本次采集前50页信息,用for循环遍历每一页的url,然后批量获取每一页的信息。
相关代码如下
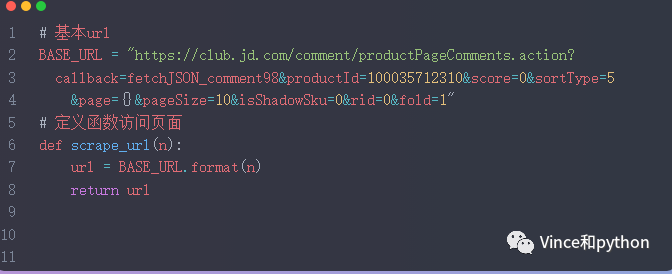

运行结果部分数据展示:


总共获取500条评论。
完整代码:
import requests import re import json import pandas as pd # 基本url
BASE_URL = "https://club.jd.com/comment/productPageComments.action?
callback=fetchJSON_comment98&productId=100035712310&score=0&sortType=5
&page={}&pageSize=10&isShadowSku=0&rid=0&fold=1"
# 定义函数访问页面
def scrape_url(n):
url = BASE_URL.format(n)
return url
def get_reviews_html(url):
# 请求头
headers = {
'cookie': '__jdu=1659013711311387516036; shshshfpa=96b8fa44-7940-4a82-dc6b-ae9ec11053d8-1671423464; shshshfpb=l3JPGq-Nsv3ryl-UYczuTVg; unpl=JF8EAMhnNSttXEhSBh0LG0IZTlsBW11YGx4LbDAHBllbHANXEwFIFBl7XlVdXxRKFB9sYxRUXVNLVA4ZBisSEXteXVdZDEsWC2tXVgQFDQ8VXURJQlZAFDNVCV9dSRZRZjJWBFtdT1xWSAYYRRMfDlAKDlhCR1FpMjVkXlh7VAQrAhwWGEpdVlhdCEkXA21uA1BdX0pWAisDKxUge21WWVwPSRYzblcEZB8MF1cBHwEZF11LWlBWXAhJEQNvZQVUX1FNUAUcAxkVIEptVw; __jdv=76161171|baidu-pinzhuan|t_288551095_baidupinzhuan|cpc|0f3d30c8dba7459bb52f2eb5eba8ac7d_0_5272781a847d41aa892f3c52ffc92b78|1677294929187; areaId=19; PCSYCityID=CN_440000_440300_0; shshshfpx=96b8fa44-7940-4a82-dc6b-ae9ec11053d8-1671423464; shshshfp=edea99a27fbc1b9e7a0a677bc566df49; __jdc=122270672; ip_cityCode=1601; ipLoc-djd=19-1607-4773-62121; jwotest_product=99; 3AB9D23F7A4B3C9B=JLXTWBOH4BNFVY37YNSE4B6N2OLXI7T6WIX336O237ZEYUEAF4RFRCLPN3AEBN5FK556TM2FSRQABIGENHAVETWTGA; jsavif=1; __jda=122270672.1659013711311387516036.1659013711.1677312527.1677330268.7; __jdb=122270672.1.1659013711311387516036|7.1677330268; shshshsID=426d0c1911285cc51524a751262039de_1_1677330269246; JSESSIONID=85D1CE4A20581F98C688EA0EFE2CB175.s1',
'referer': 'https://item.jd.com/',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36',
}
# 发送请求
response = requests.get(url=url,headers=headers)
# 获取响应内容
result = response.text
print(result)
return result
# 创建空列表,用来存放信息
data = []
def get_goods_contents(result):
# 提取评论内容
content = re.findall('"guid".*?"content":"(.*?)"',result)
# print(content)
# 提取产品尺寸
productSize = re.findall('productColor":"(.*?)"',result)
# print(productSize)
# 提取产品配置
productConfig = re.findall('"productSize":"(.*?)"',result)
# print(productConfig)
# 提取评论创建时间
creationTime = re.findall('"creationTime":"(.*?)"',result)
# 用for 循环批次把信息储存到data
for i in range(len(productSize)):
data.append([productSize[i],creationTime[i],productConfig[i],content[i]])
# print(data)
return data
def save_reviews(data):
columns = ['产品尺寸','评论时间','产品配置','产品评论']
df = pd.DataFrame(data,columns=columns)
df.to_excel('电脑评论.xlsx',encoding='utf-8')
# 运行主程序
if __name__=='__main__':
for i in range(0,50):
# 调用函数依次访问页面
url =scrape_url(n=i)
# 调用函数获取响应内容
result = get_reviews_html(url)
# 调用函数获取数据
data = get_goods_contents(result)
# 调用函数保存信息
save_reviews(data)
总结:
-
本次主要实战采集京东商品电脑商品信息评论,其他商品换关键词就可以。
-
文章借助了ChatGPT对一些概念做了一些解释,比如cookie,表达式。加深对基本概念的理解与运用。
-
这些评论如何清洗分析,去挖掘其中的商业价值?

