
- 1V字形研发模式中的测试_v字测试流程
- 2项目管理工具git_git管理工具
- 3LVGL移植到ARM开发板(GEC6818)_gec6818移植lvgl
- 4LeetCode 算法:找到字符串中所有字母异位词c++
- 5《IT 领域准新生暑期预习指南:开启未来科技之旅》
- 6在Linux系统yum安装报错Cannot find a valid baseurl for repo解决方案_error: cannot find a valid baseurl for repo: livna
- 7谷粒商城--分布式基础篇(P1~P27)_谷粒商城分布式基础篇课件
- 8在ROS中用opencv订阅摄像头图像并显示_ros2查看订阅到的图片
- 9dockerfile更改docker镜像源(1)_dockerfile指定镜像源
- 10pycorrector训练自己的模型,pycharm如何训练模型_pycharm中基于keras的模型搭建
【图神经网络】手把手利用PyTorch Genometric创建第一个图神经网络模型_torch 图神经网络
赞
踩
PyG(PyTorch Geometric)是一个基于PyTorch的图神经网络框架,简称为PyG。PyG包含图神经网络训练中的数据集处理、多GPU训练、多个经典的图神经网络模型、多个常用的图神经网络训练数据集而且支持自建数据集,主要包含以下几个模块:
- torch_geometric:主模块
- torch_geometric.nn:搭建图神经网络层
- torch_geometric.data:图结构数据的表示
- torch_geometric.loader:加载数据集
- torch_geometric.datasets:常用的图神经网络数据集
- torch_geometric.transforms:数据变换
- torch_geometric.utils:常用工具
- torch_geometric.graphgym:常用的图神经网络模型
- torch_geometric.profile:监督模型的训练
1. 整体介绍
PyG (PyTorch 几何图形)是构建在 PyTorch 之上的一个库,可以方便地编写和训练图形神经网络(GNN) ,用于与结构化数据相关的广泛应用程序。
它包括各种在图形和其他不规则结构(也称为几何深度学习)上的各种方法组成的方法。此外,它由易于使用的mini-batch加载器组成,用于在许多小型和单个巨型图,多GPU支持,DataPipe支持,通过Quiver分布图学习,大量常见的基准数据集(基于简单的简单基础)创建自己的界面),GraphGym实验管理器和有用的转换,既可以在任意图以及3D网格或点云上学习。
使用Anaconda安装PyG:
conda install pyg -c pyg
- 1
使用Pip安装PyG:
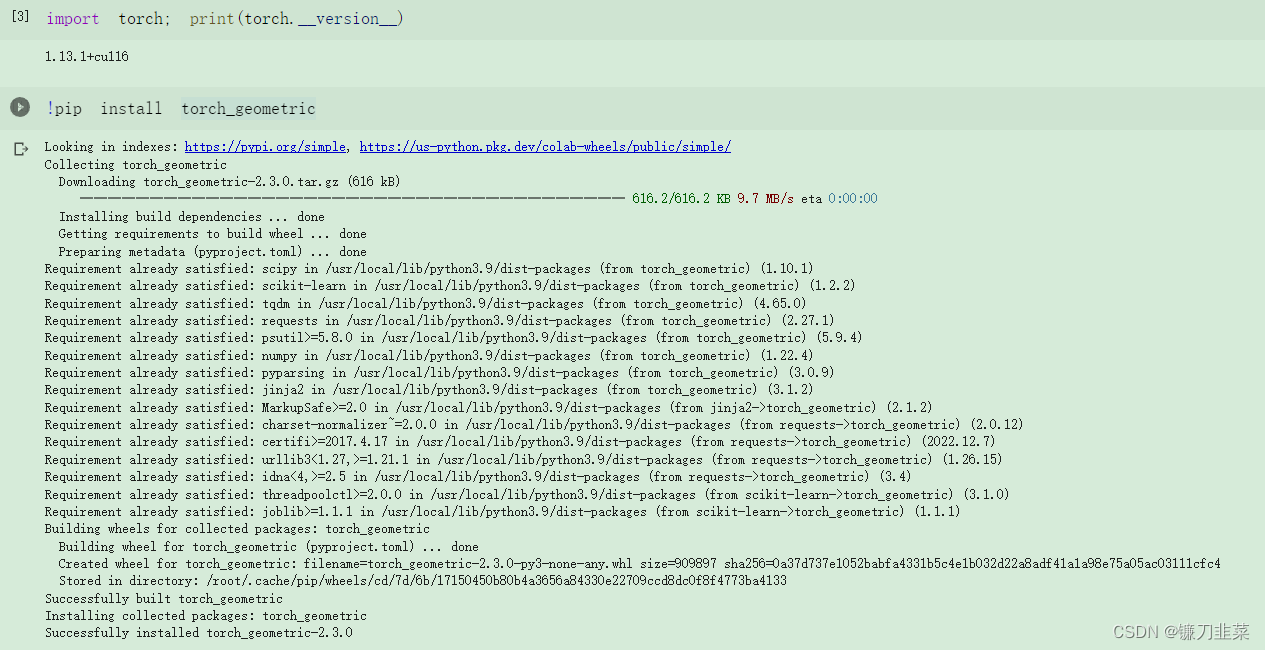
如果希望利用 PyG 的全部特性,那么还有几个额外的库需要安装:
pyg-lib: 异构 GNN 算子与图抽样routinestorch-scatter: 加速和有效的sparse reductionstorch-sparse:SparseTensor支持,参考Memory-Efficient Aggregationstorch-cluster: 图聚类的routinestorch-spline-conv:SplineConv支持
安装代码:
!pip install pyg_lib torch_scatter torch_sparse torch_cluster torch_spline_conv -f https://data.pyg.org/whl/torch-1.13.0+cu116.html
- 1
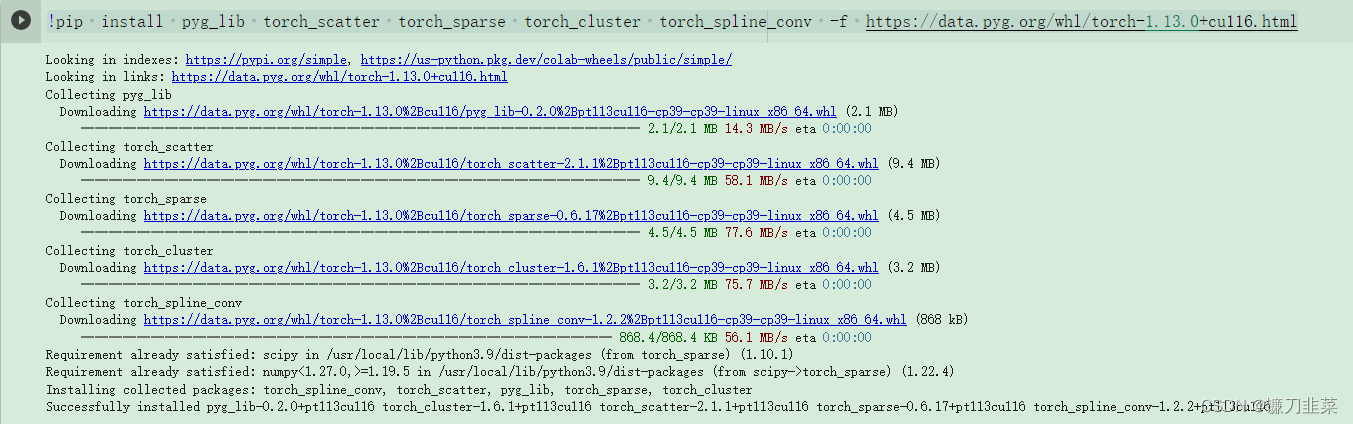
这些软件包带有基于Pytorch C ++/CUDA扩展接口的CPU和GPU内核实现。对于PYG的基本用法,这些依赖项是完全可选的。我们建议从最小安装开始,并在您真正需要它们后安装其他依赖项。
2. 图数据的处理
PyG用torch_geometric.data.Data保存图结构的数据,导入的data(这个data指的是你导入的具体数据,不是前面那个torch_geometric.data)在PyG中会包含以下属:
data.x:图节点的属性信息,比如社交网络中每个用户是一个节点,这个x可以表示用户的属性信息,维度为[num_nodes,num_node_features]data.edge_index:COO格式的图节点连接信息,类型为torch.long,维度为[2,num_edges](具体包含两个列表,每个列表对应位置上的数字表示相应节点之间存在边连接)data.edge_attr:图中边的属性信息,维度[num_edges,num_edge_features]data.y:标签信息,根据具体任务,维度是不一样的,如果是在节点上的分类任务,维度为[num_edges,类别数],如果是在整个图上的分类任务,维度为[1,类别数]data.pos:节点的位置信息(一般用于图结构数据的可视化),维度为[num_nodes, num_dimensions]
除了以上属性,还可以通过data.face自定义属性。下面看如何利用PyG表示下面这个图:
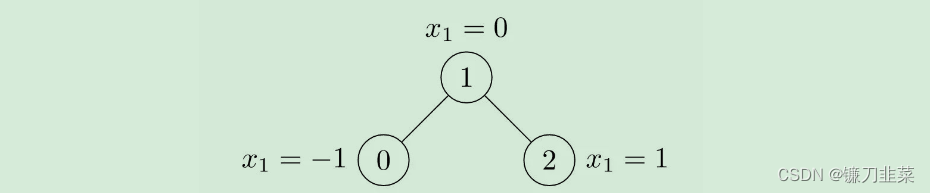
代码:
import torch
from torch_geometric.data import Data
# 边的连接信息
edge_index = torch.tensor([ # 注意,无向图的边要定义两次,
[0,1,1,2], # 上下对应着看,节点0和节点1有连接,那么节点1和节点0也有连接
[1,0,2,1]
], dtype=torch.long) # 指定数据类型
# 指定节点属性信息,这里有三个节点,每个节点的属性向量维度为1
x = torch.tensor([[-1], [0], [1]], dtype=torch.float)
# 实例化一个图结构的数据对象
data = Data(x=x, edge_index=edge_index)
data
>>> Data(x=[3, 1], edge_index=[2, 4])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
注意 edge_index,即定义所有边的源节点和目标节点的张量,不是索引元组的列表。如果你想这样写你的索引,你应该在将它们传递给数据构造函数之前对它进行转置和调用:
import torch
from torch_geometric.data import Data
# 另一种定义边索引的写法
edge_index = torch.tensor([[0, 1], # 节点0连接节点1
[1, 0], # 节点1连接节点0
[1, 2],
[2, 1]], dtype=torch.long)
x = torch.tensor([[-1], [0], [1]], dtype=torch.float)
data = Data(x=x, edge_index=edge_index.t().contiguous())
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
尽管图只有两条边,但我们需要定义四个索引元组来说明边的两个方向。
注意,edge_index 中的元素必须只保存范围{0,... ,num _ node-1}内的索引。这是必需的,因为我们希望最终数据表示尽可能紧凑,例如,希望通过x [0]和x [1]分别索引第一个边(0,1)的源和目标节点特征。可以通过运行validate()来检查最终Data 对象是否满足这些要求:
data.validate(raise_on_error=True)
>>>True
- 1
- 2
其他一些常规操作如下:

遍历data对象:
for key, item in data:
print(f'{key} in data')
>>>x in data
>>>edge_index in data
- 1
- 2
- 3
- 4
将data对象迁移到GPU上:
device = torch.device('cuda')
data = data.to(device)
- 1
- 2
3. 常用的图神经网络数据集
PyG包含了一些常用的图深度学习公共数据集,如
- Planetoid数据集(Cora、Citeseer、Pubmed)
- 一些来自于
http://graphkernels.cs.tu-dortmund.de/常用的图神经网络分类数据集 - QM7、QM9
- 3D点云数据集,如FAUST、ModelNet10等
初始化数据集很简单。数据集的初始化将自动下载其原始文件并将其处理为前面描述的Data格式。.接下来拿ENZYMES数据集(包含600个图,每个图分为6个类别,图级别的分类)举例如何使用PyG的公共数据集:
from torch_geometric.datasets import TUDataset # 导入数据集 dataset = TUDataset( # 指定数据集的存储位置 # 如果指定位置没有相应的数据集 # PyG会自动下载 root='../data/ENZYMES', # 要使用的数据集 name='ENZYMES', ) # 数据集的长度 print(len(dataset)) # 数据集的类别数 print(dataset.num_classes) # 数据集中节点属性向量的维度 print(dataset.num_node_features) # 600个图,我们可以根据索引选择要使用哪个图 data = dataset[0] print(data) # 随机打乱数据集 dataset = dataset.shuffle()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22

可以看到数据集中的第一个图包含37个节点,每个节点有3个特性。有168/2 = 84个无向边,图被分配到正好一个类。此外,数据对象正好持有一个图级目标。
我们甚至可以使用切片、长张量或布尔张量来分割数据集。例如,要创建一个90/10的train/test分割,输入:
train_dataset = dataset[:540]
>>> ENZYMES(540)
test_dataset = dataset[540:]
>>> ENZYMES(60)
- 1
- 2
- 3
- 4
- 5
再试一个数据集。下载Cora,这是一个半监督图节点分类的标准基准数据集:
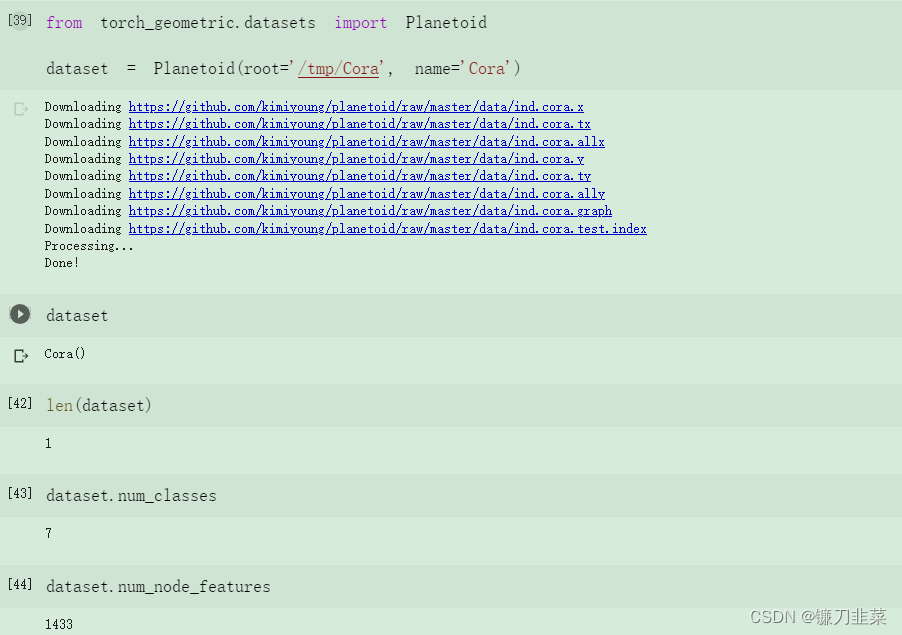
这个数据集仅包含一个单一的无向引文图:
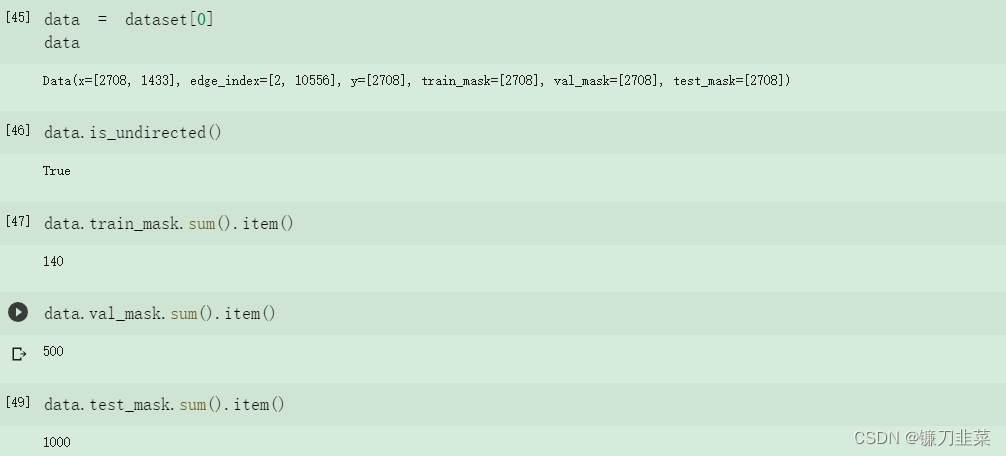
这一次,Data 对象为每个节点持有一个标签,以及附加的节点级属性: train_mask、val_mask 和test_mask,其中:
train_mask:表示要对哪些节点进行训练(140个节点) ,val_mask:表示用于验证的节点,例如,执行提前停止(500个节点) ,test_mask:表示要对哪些节点进行测试(1000个节点)。
4. Mini-batches
神经网络通常以批处理的方式进行训练。PyG通过创建稀疏块对角邻接矩阵(由edge_index定义)并在节点维度中连接特征和目标矩阵来实现小批处理上的并行化。这种组合允许在一个批处理中的示例中有不同数量的节点和边:
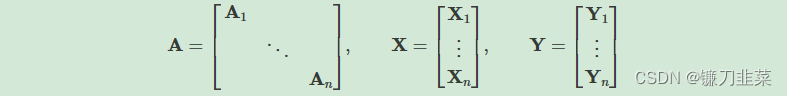
PyG包含自己的torch_geometric.loader.DataLoader,它已经负责这个串联过程。通过一个例子来了解它:
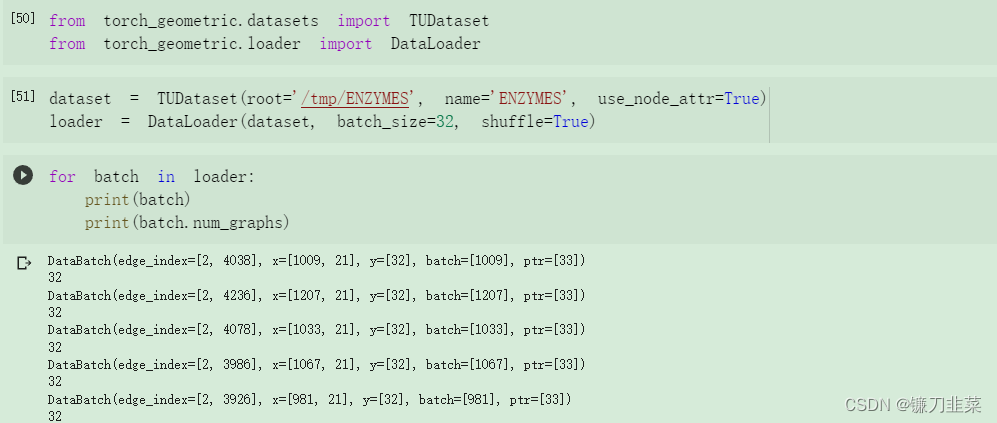
torch_geometric.data.Batch继承自torch_geometric.data.data,并包含一个名为batch的附加属性。batch是一个列向量,它将每个节点映射到批处理中的相应图:
batch
=
[
0
.
.
.
0 1
.
.
.
n-2 n-1
.
.
.
n-1
]
T
\text{batch} = [\text{0 } ... \text{ 0 } \text{ 1 } ... \text{ n-2 } \text{ n-1 } ... \text{ n-1 }]^T
batch=[0 ... 0 1 ... n-2 n-1 ... n-1 ]T
例如,可以使用它来分别对每个图的节点维度中的节点特征进行平均:
for data in loader:
x = scatter(data.x, data.batch, dim=0, reduce='mean')
print(x.size()) # torch.Size([32, 21])
- 1
- 2
- 3
5. 数据转换
Transfoms是torchvision中变换images和执行augmentation的常用方法。PyG有自己的转换,它期望一个Data对象作为输入,并返回一个新的转换后的Data对象。可以使用torch_geometric.transforms.Compose将转换链接在一起,并在将处理后的数据集保存到磁盘上之前(pre_transform)或在访问数据集中的图之前(transform)应用转换。
看一个例子,在ShapeNet数据集上应用变换(包含17000个3D形状点云和来自16个形状类别的每个点标签)。可以通过转换从点云生成最近邻图,将点云数据集转换为图数据集:

但是,从结果上看,似乎没什么变化。
注意,在将数据保存到磁盘之前,使用pre_transform来转换数据(从而加快加载时间)。请注意,下次初始化数据集时,它将已经包含图形边,即使没有传递任何变换。如果pre_transform与已经处理的数据集中的不匹配,则会发出警告。
此外,可以使用transform参数来随机增强Data对象,例如,将每个节点位置平移一个小数字:
dataset = ShapeNet(root='/tmp/ShapeNet', categories=['Airplane'],
pre_transform=T.KNNGraph(k=6),
transform=T.RandomJitter(0.01))
- 1
- 2
- 3
6. 在Graphs上的学习方法
在学习了PyG中的数据处理、数据集、加载器和转换之后,是时候实现我们的第一个图神经网络了!我们将使用一个简单的GCN层,并在Cora引文数据集上复制实验。有关GCN的高级解释,请查看GRAPH CONVOLUTIONAL NETWORKS。
首先,下载Cora数据集
from torch_geometric.datasets import Planetoid
dataset = Planetoid(root='/tmp/Cora', name='Cora')
- 1
- 2
- 3
注意,我们不需要使用transforms或dataloader。现在实现一个两层的GCN:
import torch import torch.nn.functional as F from torch_geometric.nn import GCNConv class GCN(torch.nn.Module): def __init__(self): super().__init__() self.conv1 = GCNConv(dataset.num_node_features, 16) self.conv2 = GCNConv(16, dataset.num_classes) def forward(self, data): x, edge_index = data.x, data.edge_index x = self.conv1(x, edge_index) x = F.relu(x) x = F.dropout(x, training=self.training) x = self.conv2(x, edge_index) return F.log_softmax(x, dim=1)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
构造函数定义了两个GCNConv层,它们在网络的前向传递中被调用。请注意,非线性没有集成在conv调用中,因此需要在之后应用(PyG中的所有运算符都是一致的)。在这里,我们选择使用ReLU作为中间非线性层,并最终输出类数量上的softmax分布。在200个epochs的训练节点上训练这个模型:
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = GCN().to(device)
data = dataset[0].to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=0.01, weight_decay=5e-4)
model.train()
for epoch in range(200):
optimizer.zero_grad()
out = model(data)
loss = F.nll_loss(out[data.train_mask], data.y[data.train_mask])
loss.backward()
optimizer.step()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
最后,可以在测试节点上评估我们的模型:
model.eval()
pred = model(data).argmax(dim=1)
correct = (pred[data.test_mask] == data.y[data.test_mask]).sum()
acc = int(correct) / int(data.test_mask.sum())
print(f'Accuracy: {acc:.4f}')
>>>Accuracy: 0.8140
- 1
- 2
- 3
- 4
- 5
- 6
- 7
这就是实现第一个图神经网络所需要的一切。了解更多关于图神经网络的最简单方法是研究examples/directory中的示例,并浏览torch_geometry.nn。
7. 使用PyTorch 2.0
如何安装PyTorch 2.0?
安装最新的nightlies
- CUDA 11.7
pip3 install numpy --pre torch[dynamo] torchvision torchaudio --force-reinstall --extra-index-url https://download.pytorch.org/whl/nightly/cu117
- 1
- CUDA 11.6
pip3 install numpy --pre torch[dynamo] torchvision torchaudio --force-reinstall --extra-index-url https://download.pytorch.org/whl/nightly/cu116
- 1
- CPU
pip3 install numpy --pre torch torchvision torchaudio --force-reinstall --extra-index-url https://download.pytorch.org/whl/nightly/cpu
- 1
PyTorch 2.0代码是否向下兼容1.x?
是的,2.0 不要求修改 PyTorch workflow,只需一行代码model = torch.compile(model) 即可优化模型使用 2.0 stack,并与 PyTorch 其他代码顺利运行。该选项不强制,开发者仍可使用先前的版本。
PyTorch 2.0 是否默认启用?
不是,必须在 PyTorch 代码中明确启用 2.0,方法是通过一个单一函数调用 (single function call) 来优化模型。
如何将 PT1.X 代码迁移到 PT2.0?
先前的代码不需要任何迁移,如果想使用 2.0 中引入的全新的 compiled mode 功能,可以先用一行代码来优化模型:model = torch.compile(model)。速度提升主要体现在训练过程中,如果模型运行速度快于 eager mode,则表示可以用于推理。

