
热门标签
热门文章
- 1zookeeper 安装及配置_zk解压后目录结构
- 2Feign源码问题导致请求参数丢失_feign.codec.decodeexception: error while extractin
- 3【ORACLE】Oracle提高篇之WITH AS_oracle with as用法优点缺点
- 4将人工智能与数据治理结合的挑战与应对策略_数据治理 ai结合
- 5Docker/Podman基础应用_manifest unknown: manifest unknown
- 6Sklearn 入门教程:开启机器学习之旅
- 7这是一份简单到没朋友的上手图数据库的图文教程_图数据库怎么访问
- 8从技术到管理:你必须知道的七个转变
- 9opencv学习笔记1:简单的人脸识别_x+w y+h
- 10保姆教程 Docker 部署微服务项目_docker部署微服务
当前位置: article > 正文
用 Pytorch 训练一个 Transformer模型_pytorch transformer 训练
作者:煮酒与君饮 | 2024-07-17 07:15:23
赞
踩
pytorch transformer 训练
昨天说了一下Transformer架构,今天我们来看看怎么 Pytorch 训练一个Transormer模型,真实训练一个模型是个庞大工程,准备数据、准备硬件等等,我只是做一个简单的实现。因为只是做实验,本地用 CPU 也可以运行。
本文包含以下几部分:
- 准备环境。
- 然后就是跟据架构来定义每一层,包括Embedding、Position Encoding、多头注意力、 网络层。
- 准备Encoder。
- 准备Decoder。
- 运行 Transformer,包括训练和评估。
安装Pytorch 环境
!pip3 install torch torchvision torchaudio
- 1
引入所需工具类库
引入需要的类库,pytorch 是强大的训练框架,深度学习中需要的一些函数和基本功能都已经实现。
import torch
import torch.nn as nn
import torch.optim as optim
import torch.utils.data as data
import math
import copy
- 1
- 2
- 3
- 4
- 5
- 6
Position Embedding
生成位置信息。
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_seq_length):
super(PositionalEncoding, self).__init__()
pe = torch.zeros(max_seq_length, d_model)
position = torch.arange(0, max_seq_length, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * -(math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
self.register_buffer('pe', pe.unsqueeze(0))
def forward(self, x):
return x + self.pe[:, :x.size(1)]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
多头注意力
- 初始化model 维度,头数,每个头的维度。
- 计算是在 forward 这个方法,主要看这个方法。
class MultiHeadAttention(nn.Module): def __init__(self, d_model, num_heads): super(MultiHeadAttention, self).__init__() # Ensure that the model dimension (d_model) is divisible by the number of heads assert d_model % num_heads == 0, "d_model must be divisible by num_heads" # Initialize dimensions self.d_model = d_model # Model's dimension self.num_heads = num_heads # Number of attention heads self.d_k = d_model // num_heads # Dimension of each head's key, query, and value # Linear layers for transforming inputs self.W_q = nn.Linear(d_model, d_model) # Query transformation self.W_k = nn.Linear(d_model, d_model) # Key transformation self.W_v = nn.Linear(d_model, d_model) # Value transformation self.W_o = nn.Linear(d_model, d_model) # Output transformation def scaled_dot_product_attention(self, Q, K, V, mask=None): # Calculate attention scores attn_scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(self.d_k) # Apply mask if provided (useful for preventing attention to certain parts like padding) if mask is not None: attn_scores = attn_scores.masked_fill(mask == 0, -1e9) # Softmax is applied to obtain attention probabilities attn_probs = torch.softmax(attn_scores, dim=-1) # Multiply by values to obtain the final output output = torch.matmul(attn_probs, V) return output def split_heads(self, x): # 转换,每一个 head 独立处理 batch_size, seq_length, d_model = x.size() return x.view(batch_size, seq_length, self.num_heads, self.d_k).transpose(1, 2) def combine_heads(self, x): # Combine the multiple heads back to original shape batch_size, _, seq_length, d_k = x.size() return x.transpose(1, 2).contiguous().view(batch_size, seq_length, self.d_model) def forward(self, Q, K, V, mask=None): # 线性转换并切分 Q = self.split_heads(self.W_q(Q)) K = self.split_heads(self.W_k(K)) V = self.split_heads(self.W_v(V)) # 运行计算公式 attn_output = self.scaled_dot_product_attention(Q, K, V, mask) # 合并并返回 output = self.W_o(self.combine_heads(attn_output)) return output

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
网络定义
class PositionWiseFeedForward(nn.Module):
def __init__(self, d_model, d_ff):
super(PositionWiseFeedForward, self).__init__()
self.fc1 = nn.Linear(d_model, d_ff)
self.fc2 = nn.Linear(d_ff, d_model)
self.relu = nn.ReLU()
def forward(self, x):
return self.fc2(self.relu(self.fc1(x)))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
Encoder
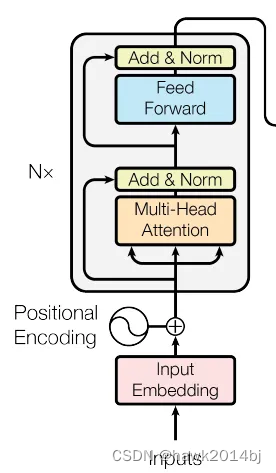
跟据这张图看下面的实现比较直观,初始化了MultiHeadAttention、PositionWiseFeedForward、两个LayerNorm。 forward 方法中 x 是 Encoder 的输入。
class EncoderLayer(nn.Module):
def __init__(self, d_model, num_heads, d_ff, dropout):
super(EncoderLayer, self).__init__()
self.self_attn = MultiHeadAttention(d_model, num_heads)
self.feed_forward = PositionWiseFeedForward(d_model, d_ff)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x, mask):
attn_output = self.self_attn(x, x, x, mask)
x = self.norm1(x + self.dropout(attn_output))
ff_output = self.feed_forward(x)
x = self.norm2(x + self.dropout(ff_output))
return x
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
Decoder
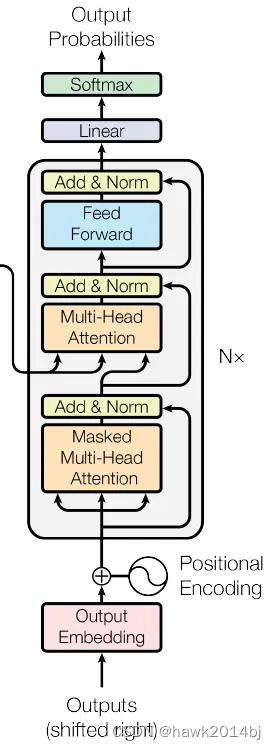
看代码的方式和 Encoder 类似,比较好理解,2 个MultiHeadAttention、3个 Norm,forward 中cross_attn 把 enc_output作为传入的参数。
class DecoderLayer(nn.Module): def __init__(self, d_model, num_heads, d_ff, dropout): super(DecoderLayer, self).__init__() self.self_attn = MultiHeadAttention(d_model, num_heads) self.cross_attn = MultiHeadAttention(d_model, num_heads) self.feed_forward = PositionWiseFeedForward(d_model, d_ff) self.norm1 = nn.LayerNorm(d_model) self.norm2 = nn.LayerNorm(d_model) self.norm3 = nn.LayerNorm(d_model) self.dropout = nn.Dropout(dropout) def forward(self, x, enc_output, src_mask, tgt_mask): attn_output = self.self_attn(x, x, x, tgt_mask) x = self.norm1(x + self.dropout(attn_output)) attn_output = self.cross_attn(x, enc_output, enc_output, src_mask) x = self.norm2(x + self.dropout(attn_output)) ff_output = self.feed_forward(x) x = self.norm3(x + self.dropout(ff_output)) return x
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
Transformer
Transformer主类,包括初始化 embedding、position embedding、encoder 和 decoder。forward 方法进行计算。
class Transformer(nn.Module): def __init__(self, src_vocab_size, tgt_vocab_size, d_model, num_heads, num_layers, d_ff, max_seq_length, dropout): super(Transformer, self).__init__() self.encoder_embedding = nn.Embedding(src_vocab_size, d_model) self.decoder_embedding = nn.Embedding(tgt_vocab_size, d_model) self.positional_encoding = PositionalEncoding(d_model, max_seq_length) self.encoder_layers = nn.ModuleList([EncoderLayer(d_model, num_heads, d_ff, dropout) for _ in range(num_layers)]) self.decoder_layers = nn.ModuleList([DecoderLayer(d_model, num_heads, d_ff, dropout) for _ in range(num_layers)]) self.fc = nn.Linear(d_model, tgt_vocab_size) self.dropout = nn.Dropout(dropout) def generate_mask(self, src, tgt): src_mask = (src != 0).unsqueeze(1).unsqueeze(2) tgt_mask = (tgt != 0).unsqueeze(1).unsqueeze(3) seq_length = tgt.size(1) nopeak_mask = (1 - torch.triu(torch.ones(1, seq_length, seq_length), diagonal=1)).bool() tgt_mask = tgt_mask & nopeak_mask return src_mask, tgt_mask def forward(self, src, tgt): src_mask, tgt_mask = self.generate_mask(src, tgt) src_embedded = self.dropout(self.positional_encoding(self.encoder_embedding(src))) tgt_embedded = self.dropout(self.positional_encoding(self.decoder_embedding(tgt))) enc_output = src_embedded for enc_layer in self.encoder_layers: enc_output = enc_layer(enc_output, src_mask) dec_output = tgt_embedded for dec_layer in self.decoder_layers: dec_output = dec_layer(dec_output, enc_output, src_mask, tgt_mask) output = self.fc(dec_output) return output
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
训练
首先准备数据,这里的数据是随机生成,只是做演示。
src_vocab_size = 5000
tgt_vocab_size = 5000
d_model = 512
num_heads = 8
num_layers = 6
d_ff = 2048
max_seq_length = 100
dropout = 0.1
transformer = Transformer(src_vocab_size, tgt_vocab_size, d_model, num_heads, num_layers, d_ff, max_seq_length, dropout)
# Generate random sample data
src_data = torch.randint(1, src_vocab_size, (64, max_seq_length)) # (batch_size, seq_length)
tgt_data = torch.randint(1, tgt_vocab_size, (64, max_seq_length)) # (batch_size, seq_length)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
开始训练
criterion = nn.CrossEntropyLoss(ignore_index=0)
optimizer = optim.Adam(transformer.parameters(), lr=0.0001, betas=(0.9, 0.98), eps=1e-9)
transformer.train()
for epoch in range(100):
optimizer.zero_grad()
output = transformer(src_data, tgt_data[:, :-1])
loss = criterion(output.contiguous().view(-1, tgt_vocab_size), tgt_data[:, 1:].contiguous().view(-1))
loss.backward()
optimizer.step()
print(f"Epoch: {epoch+1}, Loss: {loss.item()}")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
评估
将模型运行在验证集或者测试集上,这里数据也是随机生成的,只为体验一下完整流程。
transformer.eval()
# Generate random sample validation data
val_src_data = torch.randint(1, src_vocab_size, (64, max_seq_length)) # (batch_size, seq_length)
val_tgt_data = torch.randint(1, tgt_vocab_size, (64, max_seq_length)) # (batch_size, seq_length)
with torch.no_grad():
val_output = transformer(val_src_data, val_tgt_data[:, :-1])
val_loss = criterion(val_output.contiguous().view(-1, tgt_vocab_size), val_tgt_data[:, 1:].contiguous().view(-1))
print(f"Validation Loss: {val_loss.item()}")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
如果你对 Pytorch 和神经网络比较熟悉,Transformer整体实现起来并不复杂,如果想我一样对深度学习不太熟悉,理解起来还是有些困难,这里只是大概跑了一下流程,对Transformer训练有一个概念。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/煮酒与君饮/article/detail/838711
推荐阅读
相关标签

