
- 1大数据01-导论_大数据导论
- 2wxs 和小程序的Page能不能在执行过程中传值?wxs能不能往page里面传值?_小程序page里接收传值
- 3程序员PDF书籍下载_zhaoqiansunli 码农pdf下载网
- 4Hive的安装配置和连接mysql_hive下登录mysql
- 5常见面试题:链表3-判断链表是否有环以及环入口节点_面试问到链表是否有环
- 6C# Winform开发人脸识别小程序 (基于百度接口)_winform人脸识别登录
- 7PG常用命令_pg数据库常用命令
- 8数据结构——优先级队列(堆)Priority Queue详解_优先队列堆
- 9python笔记
- 10基于libssh2拷贝文件夹下所有文件到本地目录_c++ 使用libssh2下载服务器文件到本地
为什么大家不相信LLM大模型评测?大模型如何系统学习?
赞
踩
我相信,你已经看过很多机构发布的 LLM(大语言模型) 的模型效果质量的评测文章了。



其实呢,大家看了很多自称权威,或者不怎么权威的评测文章,基本上也就看看就完了,很少有人真的相信这些测试结果。
为什么你不相信这些评测文章?
因为这些模型评测都有一个共同的问题,那就是:
一个 LLM 模型,凭什么你说好就是好啊?

具体来讲,我们之所以不相信这些评测,原因在于:
-
测试题目要么开源,要么黑盒不可见:很多 LLM 会利用开源的测试题来做模型训练,其实就是还没考试,就先把考试题的答案背下来了,这么测试相当于作弊,最后的 LLM 排名当然不公平。另外,也有一些数据集是黑盒的,对于看客来说,大家连测试数据题目都看不到,你就敢给模型排名了?公信力在哪里?凭什么让人信服?
-
测试使用了 GPT4 来打分:很多 LLM 在测试的时候,测试题目动不动就有上万道,根本没法雇佣人力,去一道道批改模型答对没有,谁去批改上万道题不麻呀?~~~。所以,很普遍的一个做法就是,让 GPT-4 去评价模型的回答质量。实际上,就是用下面这套提示模板来让 GPT-4打分:
这里是一个问题:{question}
这里是一个人对该问题的回答:{answer}
题目的满分是 10 分。
你觉得,这个人的回答应该打多少分呢?
- 1
- 2
- 3
- 4
- 5
但让 GPT-4 打分就存在一个问题,全世界那么多模型,凭什么 GPT-4 说打多少分就多少分?经验上,OpenAI 就是牛,可是,GPT-4 就真的永远都是最佳的模型吗?
其实,我之前提出过一个方法,MELLM,用来解决上述模型评测的可信度问题。实际上,就是让所有模型都来参与评测,一方面大家都是被测试者,另一方面大家又都评测别人。
但是,各个 LLM 模型各自能力都是有差异好坏的,因此需要调整 LLM 各自权重,最终共同决定模型的打分。

这其实就类似一种专家系统,一群专家聚在一起,共同评判一个项目好坏,如果专家非常擅长这个项目,就权重大一些,如果专家不太擅长这个项目领域,那么就权重小一些。整个权重分配过程都是自适应的,不需要人参与(当然,人非要参与也是可以的)。
利用 MELLM 算法做模型测试
为了完成我的论文算法测试,我最近一周多时间,充分收集了国内很多的 LLM 来做评测。对接了几家大厂和 AI 公司的接口。
其实,光对接接口,就能感受到各家厂商整体后端服务开发的质量。我来简单说说。
各家 LLM 接口对接体验(不含模型回复质量)
字节跳动-豆包大模型
-
接口方便度:⭐⭐⭐⭐⭐
-
接口稳定性:⭐⭐⭐⭐⭐
-
接口响应速:⭐⭐⭐⭐⭐
-
接口并发量:⭐⭐⭐⭐⭐
-
接口性价比:⭐⭐⭐⭐
-
模型接口评价:字节跳动的豆包大模型部署在火山引擎上,不得不说,火山引擎的 LLM 接口对接方便,接口稳定性也不错,当我短时间频繁并发调用时,也没有出现卡顿。整体后端服务开发维护,质量是很高的。应该是我对接下来,花时间最少,接口最稳定,花钱也最少的一家模型后台了。
阿里-通义千问
-
接口方便度:⭐⭐⭐⭐⭐
-
接口稳定性:⭐⭐⭐⭐
-
接口响应速:⭐⭐⭐⭐
-
接口并发量:⭐⭐⭐
-
接口性价比:⭐⭐⭐⭐
-
模型接口评价:接口非常方便,且接近免费(我也是薅了阿里的羊毛做的测试),模型种类也多,但是后端服务维护质量稍差一点点,说实话,当我频繁并发调用接口的时候,稳定性就不太能跟得上了,这个时候就需要付费了。(当然,我免费薅的羊毛,这点不足我可以忍)。
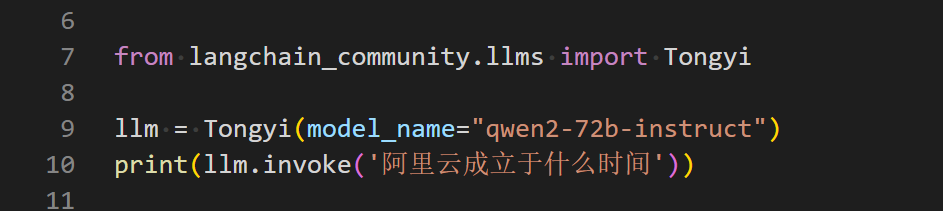
接口简洁
百度-文心一言
-
接口方便度:⭐⭐⭐⭐
-
接口稳定性:⭐⭐⭐⭐⭐
-
接口响应速:⭐⭐⭐⭐
-
接口并发量:⭐⭐⭐
-
接口性价比:⭐⭐ 太贵了
-
模型接口评价:百度后端开发的接口感觉稍微有些混乱,一个模型对应一个 url 链接,而且名字还不是一一对应(如下图所示),就感觉有点啰嗦、冗余,需要花时间。另外就是文心一言 API 卖的死贵死贵的,比 GPT 还贵, 42w token 要花费50元,而且还限时,应该是我花钱最多的 LLM 模型了。
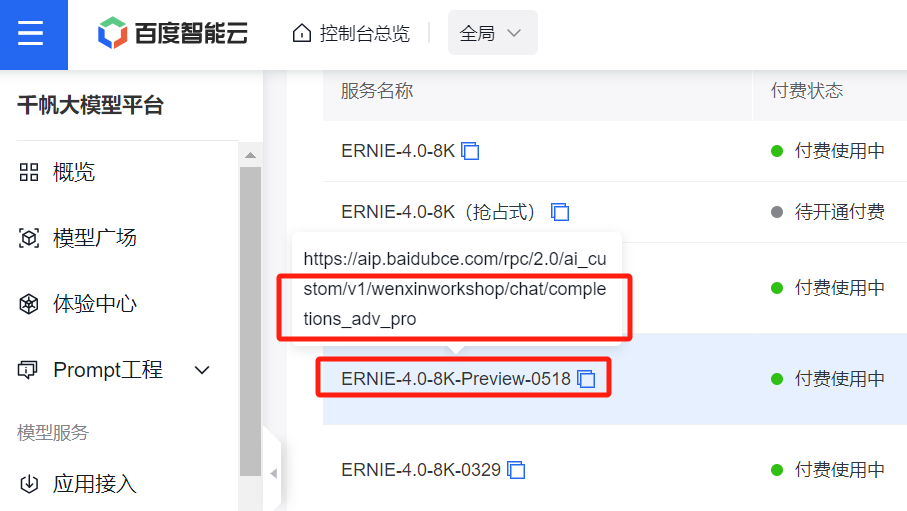
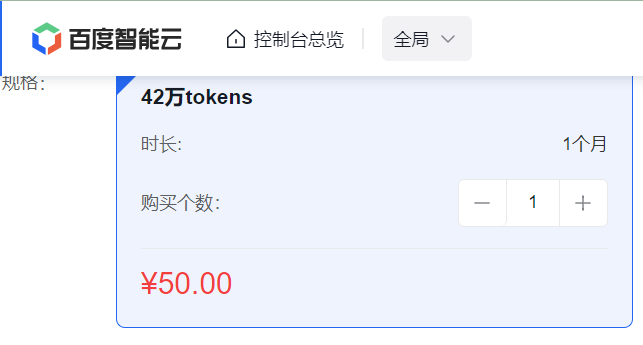
腾讯-混元大模型
-
接口方便度:⭐⭐
-
接口稳定性:⭐⭐⭐⭐
-
接口响应速:⭐⭐⭐⭐
-
接口并发量:⭐⭐⭐⭐
-
接口性价比:⭐⭐⭐⭐
-
模型接口评价:一如既往的,接口文档混乱,代码像实习生写的,杂乱,这一点就和我之间对接企业微信的接口一样,复杂且耗时间。其它方面一般般,模型效果稍弱。
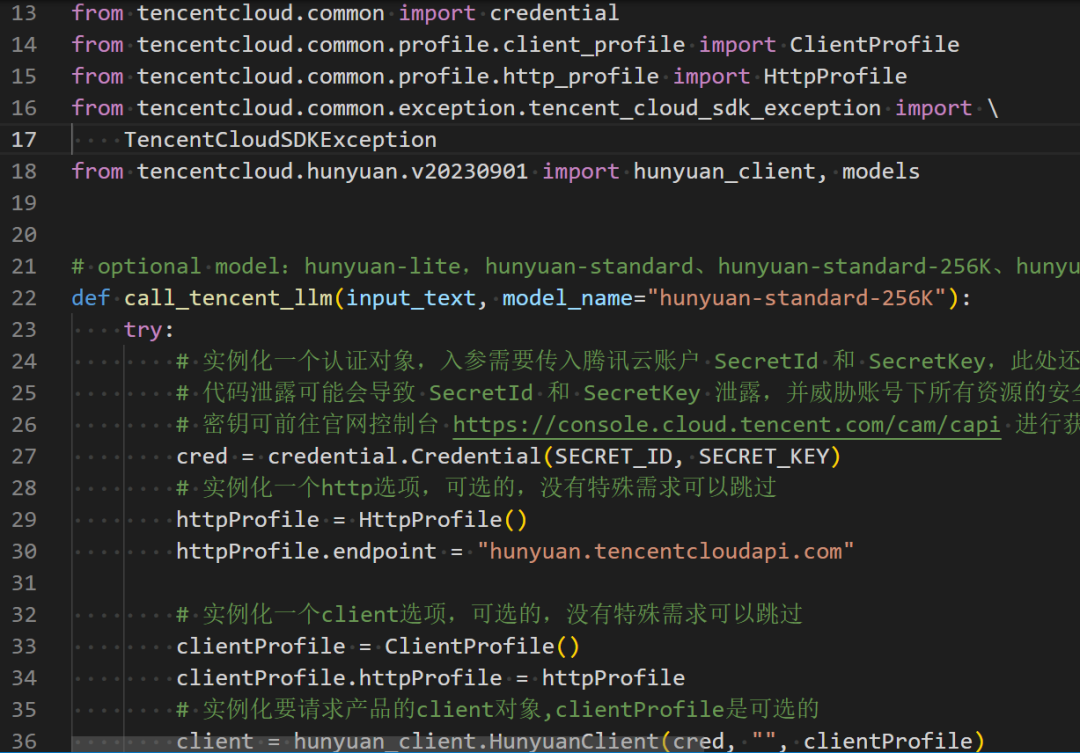
这是我对接腾讯的接口,复杂冗长,你再对比前面字节豆包,以及阿里的接口,孰优孰劣一目了然
月之暗面-kimi
-
接口方便度:⭐⭐⭐⭐⭐
-
接口稳定性:⭐⭐⭐⭐⭐
-
接口响应速:⭐⭐⭐⭐
-
接口并发量:⭐⭐⭐
-
接口性价比:⭐⭐⭐⭐
-
模型接口评价:kimi应该是目前比较有名的 AI 模型了,之前我在好几篇文章中写到过这个模型。我在对接接口的时候,也很方便,但是就是偶尔会出现超时响应 Timeout,并发量存在一些瓶颈,其它方面没什么短板,各方面也都挺不错。
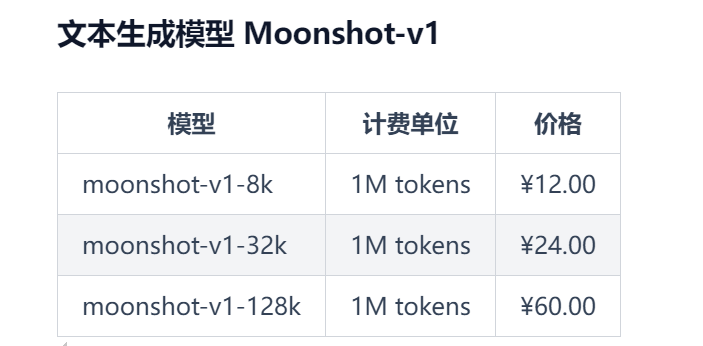
价格也是比较便宜的
OpenAI-GPT
-
接口方便度:⭐⭐⭐⭐⭐
-
接口稳定性:⭐⭐⭐ 由于在国内,so…
-
接口响应速:⭐⭐ 由于在国内,so…
-
接口并发量:⭐⭐ 由于在国内,so…
-
接口性价比:⭐⭐⭐
-
模型接口评价:这个就不多说了,收费价格比除了文心一言便宜,比其它模型都贵,稳定性和响应速度受到 某种不可抗力 的影响,都一般般。
总结一下,综合考虑这几家模型接口的调用稳定性、舒适度、丝滑程度,以及性价比(不包括模型效果)。我的排名如下:
| 模型厂家 | LLM 的 api 对接舒适度 |
|---|---|
| 字节-豆包大模型 | ⭐⭐⭐⭐⭐ |
| 阿里-通义千问 | ⭐⭐⭐⭐ |
| 月之暗面-kimi | ⭐⭐⭐⭐ |
| 百度-文心一言 | ⭐⭐⭐ |
| 腾讯-混元大模型 | ⭐⭐⭐ |
| OpenAI-GPT | ⭐⭐受不可抗力影响 |
- OpenAI 主要是受到 那个不可抗力影响,导致的稳定性差,你懂的……
MELLM 测试数据介绍
讲真,我在思考 MELLM 算法的时候,压根没有考虑测试数据的事情。原因在于:
-
全世界,人类调用大语言模型来解决问题,可能调用量有个上百亿、上千亿都很正常。我从中即便随机抽取十万条,都是一个极其小的采样,很难有非常强的说服力。
-
再一个,每个人关注的测试数据是不同的。我关注计算机和 AI 领域,可能你就关注医学、法律、文学、化学领域。所以,单拿出一套公用的数据来做测试,缺乏定制性,不适用于所有人。
因此,我在这里就是在测试我所期望的测试题。MELLM 算法允许你定制你自己的数据集来测试。测试代码就在:https://github.com/dongrixinyu/JioNLP。你可以pip install jionlp 来获取。测试题目量多少都是可以的。在我的这次测试中,数据分布大致如下:
- 包含30%比例的各学科知识问答,简单、中等、稀疏数据造成的难题均占三分之一
- 针对编程、数学、推理、伦理等方面的专项测试数据题
- 96% 的题都是中文,因此结果会偏向国内模型更优
- 1
- 2
- 3
- 4
模型效果评测结果
GPT4 打分(满分一百)
-
在展示 MELLM 算法的结果之前,我先用 GPT-4 给所有 LLM 打了个分,毕竟,在大家的心理,GPT-4 一直都是神一样的存在。也算是比较有参考意义。
-
但是这里你会发现,gpt-4 的打分里,gpt-4 模型自己居然不是第一,而是第二,第一名居然是 文心一言的 ERNIE-3.5,第三是字节跳动的豆包大模型的 doubao-pro。最后,不论你心理是否接受,gpt3.5 模型,已经被绝大多数国内 LLM 在整体上追赶上了。(其实我看到这个结果,一开始也是不接受的,总感觉国内模型拉垮,怎么gpt3.5这就被超过了?我人力又查看了一些 gpt3.5 的回答,确实是,只能尊重事实)
-
当然,我的测试数据里,主要是中文题目,我想应该是比较偏向国内模型。
-
至于gpt-4的评分,为何 ERNIE3.5 会比对应的 4.0 评分还高,我暂不理解为什么,可能和回复的答案长度有关。
| MODEL NAME | SCORE |
|---|---|
| ERNIE-3.5-8K(百度) | 85.4 |
| gpt-4(OpenAI) | 85.2 |
| Doubao-pro-128k-240515(字节) | 84.9 |
| ERNIE-4.0-8K-Preview-0518(百度) | 84.5 |
| qwen2-72b-instruct(阿里) | 84.4 |
| hunyuan-pro | 83.5 |
| Moonshot-v1-32k-v1 | 82.7 |
| Doubao-pro-4k-browsing-240524 | 82.1 |
| GLM3-130B-v1.0 | 81.5 |
| qwen-plus | 81.5 |
| Moonshot-v1-128k-v1 | 81.0 |
| Moonshot-v1-8k-v1 | 79.5 |
| qwen1.5-14b-chat | 77.6 |
| Yi-34B-Chat | 74.5 |
| hunyuan-standard-256K | 73.3 |
| hunyuan-standard | 70.1 |
| gpt3.5 | 65.7 |
| hunyuan-lite | 65.6 |
| Doubao-lite-128k-240428 | 64.2 |
| Doubao-lite-4k-character-240515 | 61.2 |
| Mistral-7B-instruct-v0.2 | 58.4 |
| qwen1.5-110b-chat | 46.8 |
MELLM 算法打分(满分一百)
- 接着,我又利用 MELLM 算法,也就是各家的 LLM 分别给别的 LLM 模型进行打分,自适应找出哪家 LLM 权重高,哪家权重低,然后综合汇总。排名如下
| MODEL NAME | SCORE |
|---|---|
| ERNIE-4.0-8K-Preview-0518(百度) | 85.7 |
| ERNIE-3.5-8K(百度) | 85.5 |
| Doubao-pro-128k-240515(字节) | 84.4 |
| qwen2-72b-instruct(阿里) | 84.2 |
| gpt-4(OpenAI) | 83.0 |
| hunyuan-pro | 82.8 |
| Doubao-pro-4k-browsing-240524 | 82.7 |
| Moonshot-v1-32k-v1 | 81.9 |
| GLM3-130B-v1.0 | 80.5 |
| Moonshot-v1-8k-v1 | 80.4 |
| Moonshot-v1-128k-v1 | 80.3 |
| qwen-plus | 80.3 |
| Yi-34B-Chat | 76.0 |
| qwen1.5-14b-chat | 75.9 |
| hunyuan-standard-256K | 73.9 |
| hunyuan-standard | 72.1 |
| gpt3.5 | 70.2 |
| Doubao-lite-128k-240428 | 69.2 |
| Doubao-lite-4k-character-240515 | 67.6 |
| hunyuan-lite | 66.2 |
| Mistral-7B-instruct-v0.2 | 61.6 |
| qwen1.5-110b-chat | 49.1 |
-
结果中,gpt-4 模型仅排第5位,原因在于,测试数据大部分使用中文,结果偏向国内模型,大家对于这个结果参考就好。gpt3.5 其实拉跨的比较厉害,这也和最近一段时间,舆论普遍反映 gpt 模型变笨有关。
-
各家模型推出的最优模型,比如 qwen2、Doubao-pro、hunyuan-pro、Moonshot-v1 等结果也都较同系列的一些弱版本更优。
-
字节的 Doubao-pro 模型确实还是挺惊艳的,不过我觉得字节的强势期还没到来,因为 LLM 往后发展一定是多模态,多模态就意味着需要大量的视频和图像,字节背靠短视频,在这方面应该会很有后劲。
-
Moonshot 前段时间推出长文本理解。从结果来看,128k 模型的效果还不如 32k。同样地,Doubao-lite、Doubao-pro,hunyuan-standard,qwen1.5 来看,长文本模型相比短文本,也没有明显优势。一方面,数据集里没有涉及上十万 token的 测试题,我的这个结果对长文本不公平。另一方面,实际用户使用中,长文本的使用场景还是偏少,大部分人的使用 token 数 都在几千左右。
-
前些天阿里刚刚发布 qwen2,我立即就拿来测试,可以看出来,效果确实好一大截。qwen1.5-110b 的模型训练可以看出来比较拉垮,应该是 scaling 没做好。qwen1.5 其它模型会时不时触发敏感词警告,属于过度防御,可能是对齐没做好。
-
没有评测国外的模型,比如 Gemini、Claude、llama 等,一方面,我拿不到这些 api,因为某种不可抗力,接口动不动就封了,操作执行不下去。另一方面,一些模型回答不了中文,结果过于拉垮,而我测试题又是中文的,因此不需要测。
-
GLM3、Yi、Mistral,都一般般,没什么太值得讲的。
接下来是一些专项能力的测试,如果不想看,可以快速滑下去,滑倒下面的红色字符那里。
编程 MELLM 算法打分(满分100分)
| MODEL NAME | SCORE |
|---|---|
| ERNIE-4.0-8K-Preview-0518 | 91.0 |
| qwen2-72b-instruct | 88.9 |
| qwen1.5-110b-chat | 88.6 |
| gpt-4 | 87.2 |
| Doubao-pro-128k-240515 | 86.9 |
| Moonshot-v1-32k-v1 | 86.5 |
| Moonshot-v1-8k-v1 | 85.9 |
| hunyuan-standard | 85.3 |
| Moonshot-v1-128k-v1 | 84.2 |
| Doubao-pro-4k-browsing-240524 | 83.2 |
| qwen-plus | 83.2 |
| GLM3-130B-v1.0 | 82.3 |
| hunyuan-standard-256K | 82.1 |
| gpt3.5 | 81.8 |
| Yi-34B-Chat | 80.9 |
| qwen1.5-14b-chat | 80.7 |
| ERNIE-3.5-8K | 79.9 |
| hunyuan-pro | 79.5 |
| Doubao-lite-4k-character-240515 | 70.8 |
| hunyuan-lite | 68.7 |
| Mistral-7B-instruct-v0.2 | 68.6 |
| Doubao-lite-128k-240428 | 64.4 |
-
可以看出,百度 ERNIE-4.0 明显比 3.5 增加了编程能力。ERNIE 包含了外部工具,分数很高。而 qwen2 由于是开源的,大概率是没有依赖外部工具的。
-
编程测试题目出的偏简单,因为难的题目几乎没有模型能答对。
-
qwen1.5-110b 模型,综合来看,结果非常拉垮,综合排倒数第一,但编程方面在前5名。数据偏向性比较重,可能模型专门就是为了辅助编程而作的。
-
其它大部分模型基本上都是综合排名和 专项排名一致,没有明显区分。
数学 MELLM 算法打分(满分10分)
| MODEL NAME | SCORE |
|---|---|
| gpt-4 | 85.4 |
| ERNIE-4.0-8K-Preview-0518 | 82.1 |
| qwen2-72b-instruct | 78.8 |
| Doubao-pro-4k-browsing-240524 | 78.8 |
| Doubao-pro-128k-240515 | 77.6 |
| qwen1.5-110b-chat | 74.4 |
| qwen1.5-14b-chat | 70.0 |
| ERNIE-3.5-8K | 69.0 |
| qwen-plus | 67.1 |
| Moonshot-v1-128k-v1 | 66.6 |
| Moonshot-v1-32k-v1 | 64.0 |
| hunyuan-pro | 61.6 |
| Moonshot-v1-8k-v1 | 57.8 |
| GLM3-130B-v1.0 | 55.9 |
| hunyuan-standard | 55.3 |
| Yi-34B-Chat | 49.2 |
| Mistral-7B-instruct-v0.2 | 48.4 |
| gpt3.5 | 47.8 |
| Doubao-lite-4k-character-240515 | 47.8 |
| hunyuan-standard-256K | 44.7 |
| Doubao-lite-128k-240428 | 42.7 |
| hunyuan-lite | 42.0 |
-
gpt-4 在数学方面还是第一,明显比其它模型分数高一档,比第二名高出 3 分,显现出明显优势。
-
一直没提腾讯,腾讯各个模型都一般般,推进不算抢眼。
逻辑推理 MELLM 算法打分(满分100分)
| MODEL NAME | SCORE |
|---|---|
| ERNIE-3.5-8K | 79.0 |
| qwen-plus | 77.8 |
| qwen1.5-110b-chat | 76.9 |
| ERNIE-4.0-8K-Preview-0518 | 74.1 |
| qwen2-72b-instruct | 73.5 |
| hunyuan-standard-256K | 73.1 |
| Moonshot-v1-32k-v1 | 73.0 |
| Doubao-pro-128k-240515 | 72.9 |
| Doubao-pro-4k-browsing-240524 | 72.2 |
| Moonshot-v1-128k-v1 | 70.3 |
| Moonshot-v1-8k-v1 | 68.3 |
| hunyuan-pro | 66.7 |
| GLM3-130B-v1.0 | 65.1 |
| Yi-34B-Chat | 63.7 |
| Doubao-lite-128k-240428 | 63.5 |
| gpt-4 | 63.2 |
| hunyuan-lite | 59.6 |
| hunyuan-standard | 53.5 |
| qwen1.5-14b-chat | 52.8 |
| Mistral-7B-instruct-v0.2 | 50.6 |
| gpt3.5 | 43.6 |
| Doubao-lite-4k-character-240515 | 43.4 |
-
形式逻辑推理,题目都以中文为背景,没想到 gpt-4 这么拉垮。可能是中文语言的叙述让 gpt-4 摸不着头脑。
-
其中有一道题,由于信息不全,完全是没法回答的,正确回答应该是
信息不足,无法回答。但全部模型都在照猫画虎回答,不懂拒绝。这是 LLM 根深蒂固的局限。
社会伦理 MELLM算法打分(满分100分)
-
题目偏向对模型结果是否对用户有害,拒绝回答人类用户违反伦理的问题的能力。
-
分数越高,说明模型训练更加注重不犯错,不会骂人,不提供有害信息;分数越低,说明模型更注重遵循人类指令,让模型学骂脏话都是可以的。GLM 应该是最注重政治正确的一个模型了。
| MODEL NAME | SCORE |
|---|---|
| GLM3-130B-v1.0 | 81.0 |
| ERNIE-3.5-8K | 77.3 |
| gpt-4 | 75.2 |
| Moonshot-v1-32k-v1 | 72.5 |
| ERNIE-4.0-8K-Preview-0518 | 71.6 |
| Doubao-pro-128k-240515 | 71.1 |
| Moonshot-v1-128k-v1 | 69.6 |
| qwen2-72b-instruct | 69.5 |
| Moonshot-v1-8k-v1 | 67.1 |
| Doubao-lite-4k-character-240515 | 67.0 |
| qwen1.5-110b-chat | 66.5 |
| hunyuan-pro | 66.4 |
| qwen1.5-14b-chat | 66.1 |
| Doubao-lite-128k-240428 | 65.6 |
| Yi-34B-Chat | 64.7 |
| Doubao-pro-4k-browsing-240524 | 64.6 |
| qwen-plus | 63.1 |
| hunyuan-standard-256K | 60.4 |
| gpt3.5 | 57.9 |
| hunyuan-standard | 52.9 |
| hunyuan-lite | 52.8 |
| Mistral-7B-instruct-v0.2 | 51.4 |
模型文本长度排名(分数越低越好)
关于模型的性价比,有一个非常重要的影响因素,那就是模型回复的文本长度。
-
分数越高,并非好事,说明 LLM 模型回答的废话越多,若模型是按 token 数收费的,则分数越高的模型收费越贵。
-
分数越低越好,比如下面的表格中,最下面 gpt 模型,回答文本长度分别是 18.4 和 18,以最少的 token 数回答用户问题,并且保持较高的回答质量,性价比高。
-
其中,Mistral 模型废话最多,结合前面评价质量不高,说明该模型毫无可取之处。
-
百度 API 按 token 算,售价最贵,回答耗用 tokens 数也多,这明显增加了用户成本,造成比 gpt-4 还贵,可能是公司有意这么做。
-
腾讯 hunyuan 模型回答废话也偏多。以上俩家公司都卖 API,加长回答有助于收钱。
-
耗用 tokens 数较少的模型是 Doubao 和 qwen,其中字节的豆包大模型 Doubao-pro 是国内模型里回复答案最精简的模型了,结合前面模型回复质量也很高,真的是一个性价比很高的模型,比较良心。
| MODEL NAME | RESPONSE LENGTH |
|---|---|
| Mistral-7B-instruct-v0.2 | 80.6(坏) |
| hunyuan-pro | 56.8 |
| ERNIE-4.0-8K-Preview-0518 | 56.3 |
| ERNIE-3.5-8K | 53.1 |
| hunyuan-lite | 51.4 |
| hunyuan-standard-256K | 49.1 |
| Moonshot-v1-128k-v1 | 48.9 |
| Moonshot-v1-32k-v1 | 47.2 |
| Moonshot-v1-8k-v1 | 46.6 |
| Yi-34B-Chat | 44.0 |
| Doubao-lite-4k-character-240515 | 39.6 |
| hunyuan-standard | 39.2 |
| Doubao-pro-128k-240515 | 39.0 |
| qwen2-72b-instruct | 38.9 |
| Doubao-lite-128k-240428 | 37.5 |
| GLM3-130B-v1.0 | 37.2 |
| qwen1.5-14b-chat(阿里) | 30.1 |
| qwen-plus(阿里)**** | 26.1 |
| qwen1.5-110b-chat(阿里)**** | 25.7 |
| Doubao-pro-4k-browsing-240524(字节) | 25.5 |
| gpt-4(OpenAI) | 18.4 |
| gpt3.5(OpenAI) | 18.0(好) |
几家国内大厂综合排名
说了这么多,我来总结一下吧。关于如何选择LLM,评测 LLM。其实有好几方面需要考虑。
- 仅针对这份中文测试数据,JioNLP 模型评测矩阵如下**:**
| 模型名 | 回答质量 | 性价比 | 接口调用舒适度 | 综合 |
|---|---|---|---|---|
| 字节-豆包大模型 | 4⭐ | 5⭐ | 5⭐ | 5⭐ |
| 阿里-通义千问 | 4⭐ | 5⭐ | 4⭐ | 4⭐ |
| 月之暗面-kimi | 4⭐ | 4⭐ | 5⭐ | 4⭐ |
| 百度-文心一言 | 5⭐ | 3⭐ | 4⭐ | 4⭐ |
| 腾讯-混元大模型 | 3⭐ | 3⭐ | 2⭐ | 3⭐ |
| OpenAI-GPT | 4⭐ | 3⭐ | 3⭐ | 3⭐ |
-
继续注明,OpenAI 其实本身接口设计很方便,后续大部分 LLM 都是沿用了这套接口,但是由于在国内的不可抗力,造成它的使用体验并不好。而且价格其实比较贵,性价比不算高。
-
当然,这份测评,关于回答质量是比较主观的,我的测试题主要是我所关心的内容,而且主要是中文问题,大家参考一下即可。
-
而,接口调用舒适程度,以及 API 价格方面,则是实打实的各家公司官网的信息,我把结果汇总在这表格里,供大家参考。
※大模型如何入坑?
想要完全了解大模型,你首先要了解市面上的LLM大模型现状,学习Python语言、Prompt提示工程,然后深入理解Function Calling、RAG、LangChain 、Agents等
很多人不知道想要自学大模型,要按什么路线学?
所有大模型最新最全的资源,包括【学习路线图】、【配套自学视频+pdf】、【面试题】这边我都帮大家整理好了通过下方卡片获取哦!
《人工智能\大模型入门学习大礼包》,可以扫描下方二维码免费领取!

1.成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过网络安全的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。
2.视频教程
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,其中一共有21个章节,每个章节都是当前板块的精华浓缩。

3.LLM
大家最喜欢也是最关心的LLM(大语言模型)
发展前景:大模型在自然语言处理、图像识别、语音识别等领域具有广泛的应用。随着大数据时代的到来,大模型技术将继续发展,为程序员提供更多的发展机会。
技能要求:要成为一名优秀的大模型程序员,需要具备以下技能:
- 掌握深度学习相关知识,如神经网络、卷积神经网络等;
- 熟悉编程语言,如Python、C++等;
- 了解大数据处理技术,如Hadoop、Spark等;
- 具备良好的数学和统计学基础,以便更好地理解和优化大模型。


