
热门标签
热门文章
- 1Redis 7.x 系列【3】多种连接方式_redis连接工具
- 2计算机网络原理系列学习笔记(四)——网络层_直接链路距离
- 3Stable Diffusion基本教程 :ControlNet控图功能_instructp2p
- 4自然语言处理的文本摘要:算法与优化
- 5什么是递归
- 6Android Studio 创建模拟器_安卓开发添加小米模拟器
- 7java&SSM&mysql流浪动物救助网站82131-计算机毕业设计项目选题推荐(附源码)
- 8抽象类练习员工案例
- 9【Elasticsearch】安装配置与使用_elasticsearch配置
- 10政安晨【零基础玩转各类开源AI项目】基于Ubuntu系统部署MimicMotion :利用可信度感知姿势指导生成高质量人体运动视频_mimicmotion 部署
当前位置: article > 正文
autodl 上 使用 LLaMA-Factory 微调 中文版 llama3_autodl微调llama3
作者:小惠珠哦 | 2024-07-30 13:11:51
赞
踩
autodl微调llama3
环境准备
autodl 服务器:
https://www.autodl.com/console/homepage/personal
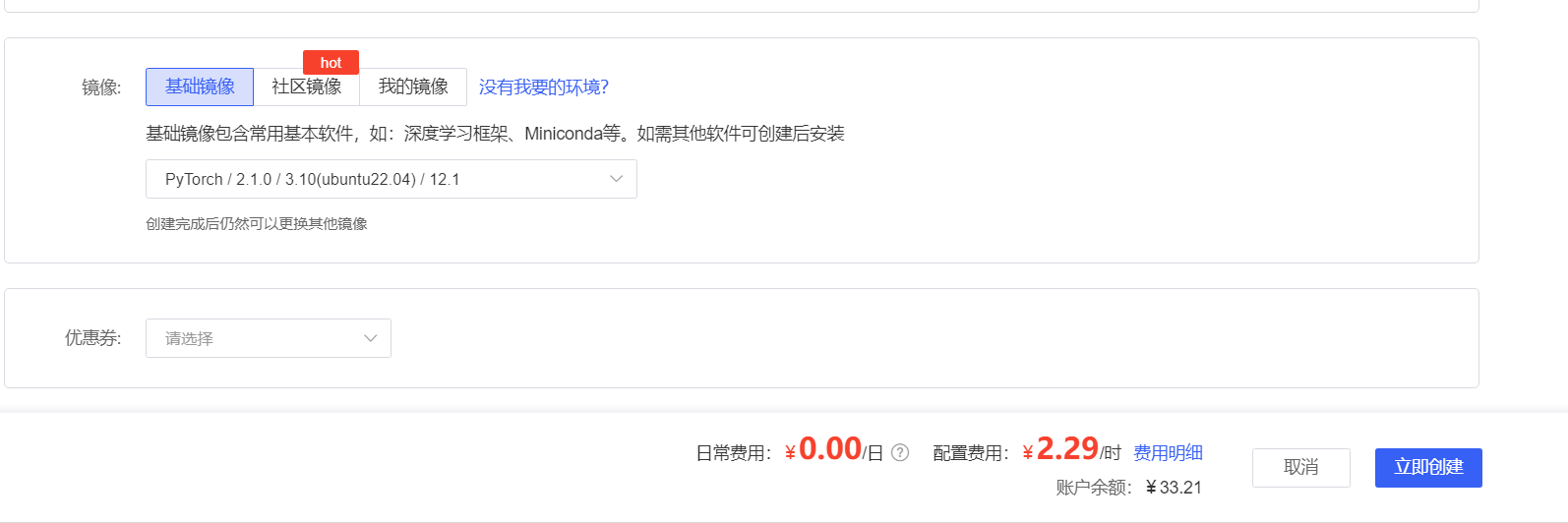
基本上充 5 块钱就可以搞完。
强烈建议选 4090(24G),不然微调的显存不够。
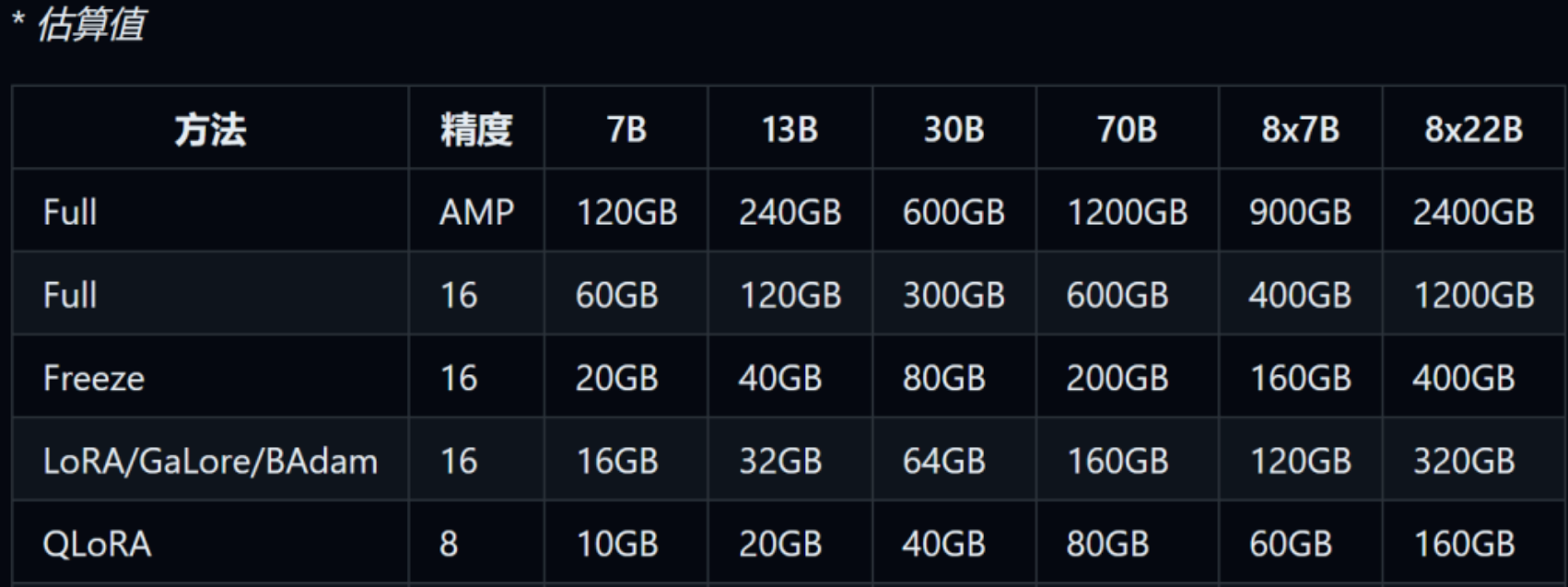
我们用 LoRA 微调,至少得 20G(8B模型)。
微调工具:
模型:
创建虚拟环境
conda activate LLaMA-Factory
- 1
上传中文微调 dpo_zh.json 数据:
下载微调工具 LLaMA-Factory
git clone https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -e .[metrics] # 下载全部依赖
- 1
- 2
- 3
- 4
- 5
下载 llama3-8B
# pip install modelscope
import torch
from modelscope import snapshot_download, AutoModel, AutoTokenizer
import os
model_dir = snapshot_download('LLM-Research/Meta-Llama-3-8B-Instruct', cache_dir='/root/autodl-tmp', revision='master')
- 1
- 2
- 3
- 4
- 5
- 6

模型路径:/root/autodl-tmp/LLM-Research/Meta-Llama-3-8B-Instruct
在 LLaMA-Factory/data 文件夹下找到 dataset_info.json 。
方法一:设置镜像站

这个数据,ta会去hf官方找,我们可以设置镜像站。
pip install -U huggingface_hub # 安装依赖
export HF_ENDPOINT=https://hf-mirror.com/ # 镜像站
- 1
- 2
方法二:改成本地文件路径

俩个地方都要改:file_name、本地数据集路径。
更新 transformers 库:
pip install --upgrade transformers
- 1
开始微调
CUDA_VISIBLE_DEVICES=0 llamafactory-cli train \ --stage orpo \ --do_train True \ --model_name_or_path /root/autodl-tmp/LLM-Research/Meta-Llama-3-8B-Instruct \ --finetuning_type lora \ --template default \ --flash_attn auto \ --dataset_dir LLaMA-Factory/data\ --dataset dpo_mix_zh \ --cutoff_len 1024 \ --learning_rate 1e-05 \ --num_train_epochs 5.0 \ --max_samples 1 \ --per_device_train_batch_size 1 \ --gradient_accumulation_steps 8 \ --lr_scheduler_type cosine \ --max_grad_norm 1.0 \ --logging_steps 5 \ --save_steps 100 \ --warmup_steps 0 \ --optim adamw_torch \ --report_to none \ --output_dir saves/LLaMA3-8B/lora/train_2024-04-25-07-48-56 \ --fp16 True \ --lora_rank 8 \ --lora_alpha 16 \ --lora_dropout 0 \ --lora_target q_proj,v_proj \ --orpo_beta 0.1 \ --plot_loss True

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30

微调后,就找这个路径看一下。
微调上面的参数是自定义的:
- max_samples 1 只使用一个数据微调,一般越多越好,这步为演示,就1条了
stage 当前训练的阶段,枚举值,有“sft”,"pt","rw","ppo"等,代表了训练的不同阶段,这里我们是有监督指令微调,所以是sft
do_train 是否是训练模式
dataset 使用的数据集列表,所有字段都需要按上文在data_info.json里注册,多个数据集用","分隔
dataset_dir 数据集所在目录,这里是 data,也就是项目自带的data目录
finetuning_type 微调训练的类型,枚举值,有"lora","full","freeze"等,这里使用lora
lora_target 如果finetuning_type是lora,那训练的参数目标的定义,这个不同模型不同,请到https://github.com/hiyouga/LLaMA-Factory/tree/main?tab=readme-ov-file#supported-models 获取 不同模型的 可支持module, 比如llama3 默认是 q_proj,v_proj
output_dir 训练结果保存的位置
cutoff_len 训练数据集的长度截断
per_device_train_batch_size 每个设备上的batch size,最小是1,如果GPU 显存够大,可以适当增加
fp16 使用半精度混合精度训练
max_samples 每个数据集采样多少数据
val_size 随机从数据集中抽取多少比例的数据作为验证集
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
测试微调结果
微调后,还可以马上测试微调结果。
- 调不好!重新调整参数和数据。
- 调得好!马上合并权重。
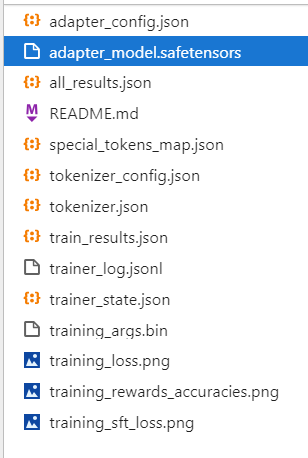
训练完后就可以在设置的output_dir下看到:
-
adapter开头的就是 LoRA 保存的结果了,后续用于模型推理融合
-
training_loss 和trainer_log等记录了训练的过程指标
-
其他是训练当时各种参数的备份
模型合并后导出
如果想把训练的LoRA和原始的大模型进行融合,输出一个完整的模型文件的话:
CUDA_VISIBLE_DEVICES=0 llamafactory-cli export \
--model_name_or_path /root/autodl-tmp/LLM-Research/Meta-Llama-3-8B-Instruct \
--adapter_name_or_path ./saves/LLaMA3-8B/lora/sft \
--template llama3 \
--finetuning_type lora \
--export_dir megred-model-path \
--export_size 2 \
--export_device cpu \
--export_legacy_format False
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
vllm 加速推理
需要提前将LoRA 模型进行merge,使用merge后的完整版模型目录:
CUDA_VISIBLE_DEVICES=0 API_PORT=8000 llamafactory-cli api \
--model_name_or_path megred-model-path \
--template llama3 \
--infer_backend vllm \
--vllm_enforce_eager
- 1
- 2
- 3
- 4
- 5
本文内容由网友自发贡献,转载请注明出处:https://www.wpsshop.cn/w/小惠珠哦/article/detail/903872
推荐阅读
相关标签

