
- 1NLP技术的应用及思考
- 2AI换脸 不求人_roop-unleashed一键安装
- 3Verilog 状态机 示例_verilog状态机实例
- 4传统的数据处理方式能否应对大数据?_大数据可以通过传统的数据处理应用软件进行处理
- 5一文带你了解大模型——智能体(Agent)_大模型agent
- 6linux设备树-linux内核对设备树的处理
- 7Swin Transformer:Hierarchical Vision Transformer using Shifted Windows (论文阅读笔记)_hierarchical transformer - vision transformer (vit
- 8[Unity] Catan Universe: Unity 的移动设备优化_catan universe安卓
- 9在gitee中新建一个仓库,将本地文件与gitee仓库做关联_gitee关联本地仓库
- 10千锋云计算学习第一天
【大模型学习】Transformer架构(非常详细)零基础入门到精通,收藏这一篇就够了_transformer基础架构
赞
踩
Transformer模型由Google在2017年的论文“Attention is All You Need”中提出,旨在解决传统RNN和CNN在处理序列数据时存在的并行计算效率低下和长期依赖捕捉不足的问题。Transformer模型通过全注意力机制(即不依赖RNN或CNN)来处理输入和输出序列,实现了高效的并行计算和长距离依赖关系的捕捉。
Transformer模型采用Encoder-Decoder架构,包括编码器(Encoder)和解码器(Decoder)两个部分。
编码器(Encoder)
编码器由多个相同的层堆叠而成,每个层都由两个子层组成:一个自注意力层和一个前馈神经网络(Feed Forward Neural Network,简称FFN)。
自注意力层是Transformer模型的核心,它通过计算输入序列中每个位置的表示与其他所有位置的表示之间的相关性,来捕捉输入序列中的依赖关系。
FFN层对自注意力层的输出进行非线性变换,进一步增强模型的表达能力。
在实际使用中,通常会使用多个编码器层(如6层)来提取输入序列中的深层次特征。
解码器(Decoder)
解码器同样由多个相同的层堆叠而成,但与编码器不同的是,解码器中的每个层还包括一个额外的编码器-解码器注意力层(Encoder-Decoder Attention)。
编码器-解码器注意力层用于计算解码器当前位置的表示与编码器输出之间的相关性,以便在生成输出序列时能够关注到输入序列中的相关信息。
与编码器类似,解码器中的每个层也包含自注意力层和FFN层。
模型特点
并行计算:由于Transformer模型采用全注意力机制,其计算过程可以并行化,从而大大提高了训练速度。
长距离依赖捕捉:通过自注意力机制,Transformer模型能够捕捉到输入序列中的长距离依赖关系,这对于处理自然语言等具有长距离依赖特性的数据具有重要意义。
灵活性:Transformer模型可以处理可变长度的输入和输出序列,这使得它在处理不同长度的文本数据时具有很高的灵活性。
可扩展性:通过堆叠更多的编码器和解码器层,可以进一步提高Transformer模型的性能。此外,还可以将Transformer模型与其他神经网络结构(如卷积神经网络)结合使用,以构建更强大的混合模型。
应用场景
Transformer模型在自然语言处理领域具有广泛的应用,包括但不限于机器翻译、文本生成、文本分类、问答系统等。同时,随着计算机视觉和语音处理等领域的发展,Transformer模型也逐渐被应用于图像分类、目标检测、语音识别等任务中。
Transformer《Attention is All You Need》

在深度学习时代早期,人们使用RNN(循环神经网络)来处理机器人翻译任务。一段输入先是会被预处理成一个token序列。RNN会对每个token逐个做计算,并维护一个表示整段文字整体信息的状态。根据当前时刻的状态,RNN可以输出当时时刻的一个token。
这种简单的RNN架构仅适用于输入和输出等长的任务。然后,大多数情况下,机器翻译的输出和输入都不是等长的。因此,人们使用了一种新的架构,前半部分的RNN只有输入,后半部分的RNN只有输出(上一轮的输出会当做下一轮的输入以补充信息)。把该状态看成输入信息的一种编码的话,前半部分可以叫做编码器,后半部分可以叫做解码器,这种架构因而被称为编码器-解码器架构。
这种架构存在不足:编码器和解码器之间只通过一个隐状态来传递信息。在处理较长的文章时,这种架构的表现不够理想。为此,有人提出了基于注意力的架构,这种架构依然使用了编码器和解码器,只不过解码器的输入是编码器的状态的加权和,而不再是一个简单的中间状态。每一个输出对每一个输入的权重叫做注意力,注意力的大小取决于输出和输入的相关关系,这种架构优化了编码器和解码器之间的信息交流方式,在处理长文章时更加有效。
尽管注意力模型的表现已经足够优秀,但所有基于RNN的模型都面临着同样一个问题:RNN本轮的输入状态取决于上一轮的输出状态,这使RNN的计算必须串行执行,因此,RNN的训练通常比较缓慢。这就使得只使用注意力机制的Transformer架构出现了。
摘要
目前占主导地位的序列转换模型都是基于包含编码器和解码器的复杂递归或卷积神经网络。表现最好的模型通过注意力机制连接了编码器和解码器。我们提出了一种新的简单网络架构,Transformer,它完全基于自注意机制,不使用任何递归或卷积。在两个机器翻译任务上的实验证明了这些模型具有更高的质量,并且可以并行化,训练时间也显著缩短。我们的模型在WMT 2014英语到德语翻译任务上达到了28.4 BLEU,超过了包括集成方法在内的现有最佳结果,提高了超过2 BLEU。在WMT 2014英语到法语翻译任务中,我们的模型在8个GPU上训练3.5天后达到了41.8的单模型最佳BLEU分数,仅消耗了文献中最好的模型一小部分的训练成本。我们证明了Transformer成功地推广到了其他任务,比如用大量和有限的训练数据成功的应用于英语的句法分析。
介绍
循环神经网络、长短期记忆和门控循环神经网络,尤其是这些循环神经网络已经被牢固地建立为序列建模和转换问题的先进技术,例如语言建模和机器翻译。自那时以来,许多努力继续推动循环语言模型和编码器 - 解码器架构的边界。
注意力机制已成为各种任务中引人注目的序列建模和转录模型的重要组成部分,它允许在输入或输出序列中不考虑距离来建模依赖关系。然而,在除少数情况下外,这种注意机制与递归网络一起使用。
在这项工作中,我们提出了一种新的架构——Transformer,它避免了循环计算,并且完全依靠一种注意力机制来捕捉输入和输出之间的全局依赖性。Transformer 允许更多的并行化,并且经过训练后仅需十二小时即可达到最新的翻译质量基准,使用八个 P100 GPU 即可实现。
背景
减少顺序计算的目标也是扩展神经GPU、ByteNet和 ConvS2S的基础,它们都使用卷积神经网络作为基本构建块,并为所有输入和输出位置并行计算隐藏表示。在这些模型中,从两个任意的输入或输出位置之间关联信号所需的运算次数随着距离的增长而增加,对于 ConvS2S 来说是线性的,对 ByteNet 来说是对数增长的。这使得学习远处位置之间的依赖关系更加困难。在 Transformer 中,这一数量被减小到一个常数,尽管由于平均加权注意力位置而导致的有效分辨率降低。
自注意力,有时也称为内注意力,是一种关联序列中不同位置的注意力机制,用于计算该序列的表示。自注意力已成功应用于各种任务,包括阅读理解、抽象总结、文本蕴含以及学习与任务无关的句子表示。
据我们所知,Transformer 是第一个完全依赖自注意计算其输入和输出表示的转录模型,而无需使用序列对齐的 RNN 或卷积。
模型架构
大多数竞争神经序列转换模型都有一个编码器-解码器结构。在这里,编码器将符号表示的输入序列(x1,…,xn)映射到连续表示的序列z =(z1,…,zn)。给定z,解码器然后按元素生成输出序列(y1,…,ym)的符号。每次迭代时,该模型都是自回归的,在生成下一个元素时消耗先前生成的符号作为附加输入。
Transformer 使用堆叠的自注意力机制和点对点全连接层,分别用于编码器和解码器,如下图左右两部分所示。
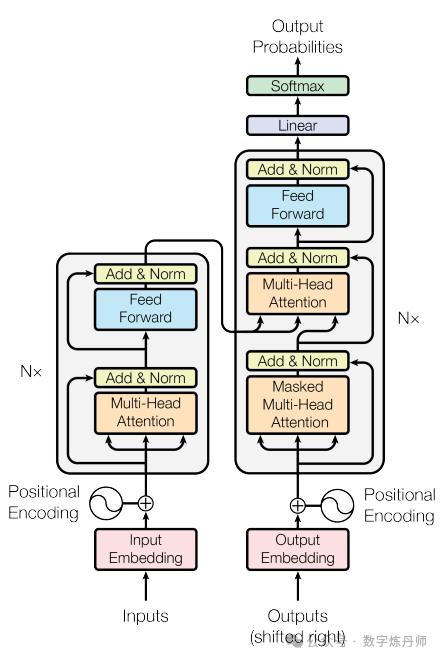
模型架构(Encoder and Decoder Stacks)
编码器由堆叠的N = 6个相同的层组成。每一层有两个子层:第一个是多头自注意力机制,第二个是简单的全连接前馈网络。我们在每个子层周围使用残差连接,后跟层归一化。即,每个子层的输出为LayerNorm(x+Sublayer(x)),其中Sublayer(x)是由子层自身实现的功能。为了便于这些残差连接,模型中的所有子层以及嵌入层都产生大小为dmodel = 512的输出。
解码器也由N = 6个相同的层堆叠而成。除了每个编码层中的两个子层之外,解码器还插入了一个第三个子层,该子层对编码堆栈的输出执行多头注意力运算。与编码器一样,我们在每个子层周围使用残差连接,后跟层归一化。我们还将解码器堆栈中的自我注意子层修改为防止位置关注后续位置。这种掩码,加上输出嵌入向右偏移一个位置的事实,确保了位置i的预测仅依赖于其前面的位置中已知的输出。
模型架构(Attention)
注意力函数可以被描述为映射一个查询到一组键值对来获得输出,其中查询、键、值和输出都是向量。输出是由加权求和计算而来的。
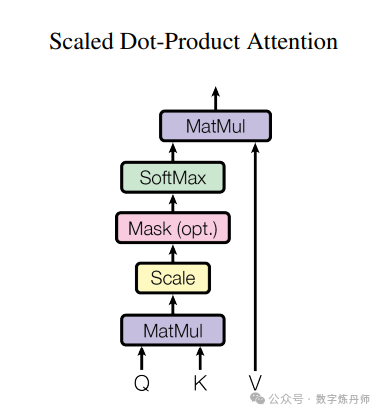
模型架构(Scaled Dot-Product Attention)
实际上,我们对一组查询同时计算注意力函数,并将它们打包到一个矩阵Q中。键值也会被压缩到K和V矩阵中。输出矩阵的计算如下:
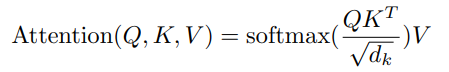
模型架构(Multi-Head Attention)
我们发现,与其使用 dmodel-dimension 的键、值和查询执行单个注意力函数,不如对查询、键和值分别进行 h 次线性投影到dk、dk 和 dv 维度上更有利于模型的学习。在这些查询、键和值的投影版本上,我们并行地执行注意力函数,产生一个具有dv维的结果。
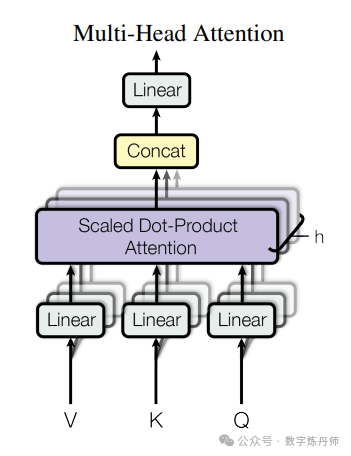
多头注意力机制允许模型在不同位置同时关注来自不同表示子空间的信息。单个注意力头的平均操作会抑制这种能力:

模型架构(Applications of Attention in our Model)
在“编码器-解码器注意力”层中,查询来自前一层的解码器,而存储键和值来自编码器的输出。这使得解码器中的每个位置都可以关注输入序列的所有位置。这与典型的序列到序列模型中的编码器-解码器注意力机制相似。
编码器包含自注意力层。在自注意力层中,所有键、值和查询都来自同一个地方,在这种情况下,来自编码器的前一层的输出。编码器中的每个位置都可以关注编码器的前一层的所有位置。
类似地,解码器中的自注意力层允许解码器的每个位置关注所有位置,包括该位置。我们需要防止信息流回到解码器来保持自回归性。我们在缩放点积注意力中通过设置不合法连接的输入的softmax值为负无穷来实现这一点。
模型架构(Position-wise Feed-Forward Networks)
除了注意力子层之外,我们的编码器和解码器的每一层都包含一个全连接前馈网络,它分别应用于每个位置。这包括两个线性变换以及它们之间的 ReLU 激活。
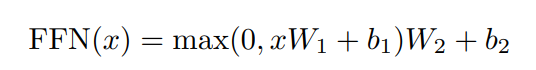
虽然不同位置的线性变换是一样的,但是它们使用了来自不同层的不同参数。另一种描述这个过程的方式是用两个卷积核大小为 1 的卷积来描述。输入和输出的维度都是 dmodel=512,内层的维度是 df f=2048。
模型架构(Embeddings and Softmax)
与其它序列转换模型一样,我们使用学习到的嵌入来将输入标记和输出标记转换为 dmodel 维度的向量。我们也使用了通常的学习线性变换和 softmax 函数将解码器的输出映射到预测下一个标记的概率分布上。
模型架构(Positional Encoding)
由于我们的模型没有循环结构,也没有卷积操作,所以为了利用序列的顺序信息,我们必须为模型注入一些关于序列中标记相对或绝对位置的信息。为此,在编码器和解码器堆栈底部,我们向输入嵌入添加“位置编码”。位置编码具有与嵌入相同维度 dmodel,因此两者可以相加。有许多种位置编码的方法,它们既可以学习也可以固定。
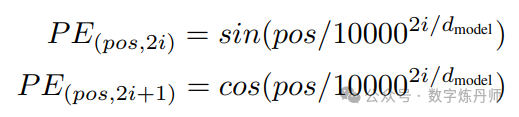
为什么用自注意力
一是每层的总计算复杂度。另一个衡量标准是并行化的计算量,即所需的最少串行操作数。
第三,网络中长程依赖关系之间的路径长度。学习长程依赖性是在许多序列转换任务中的一个关键挑战。影响学习这种依赖性的关键因素之一是信号在网络中前向和后向传播时必须经过的路径长度。输入和输出序列之间任何两个位置之间这些路径越短,就越容易学习到长程依赖性。因此我们也在不同层类型的网络中比较了任意两个输入和输出位置之间的最大路径长度。
如下表所示,自注意力层通过执行固定数量的顺序操作来连接所有位置,而循环层需要 O(n) 的顺序操作。在计算复杂性方面,当序列较短时,自注意力层比循环层更快。

训练
训练(Training Data and Batching)
我们在标准的WMT 2014 英德数据集上进行了训练,该数据集包含约450万句对。句子使用字节对编码进行了编解码,共享源目标词汇表包含约37000个标记。对于英法语,我们使用了显著更大的WMT2014 英法数据集,其中包含3600万条句子,并将标记拆分为一个32000词的词块词汇表。按近似序列长度分批处理双句。每个训练批次包含一组近似包含25000个源标记和25000个目标标记的双句。
训练(Hardware and Schedule)
我们在一台拥有8块NVIDIA P100 GPU的机器上训练模型。对于本文中描述的基础模型,使用超参数进行训练,每个训练步骤大约需要0.4秒。我们对基础模型进行了总共10万个步骤或12小时的训练。对于我们的大模型,每个步骤的时间为1秒。大型模型训练了30万个步骤(3.5天)。
结果
结果(Machine Translation)
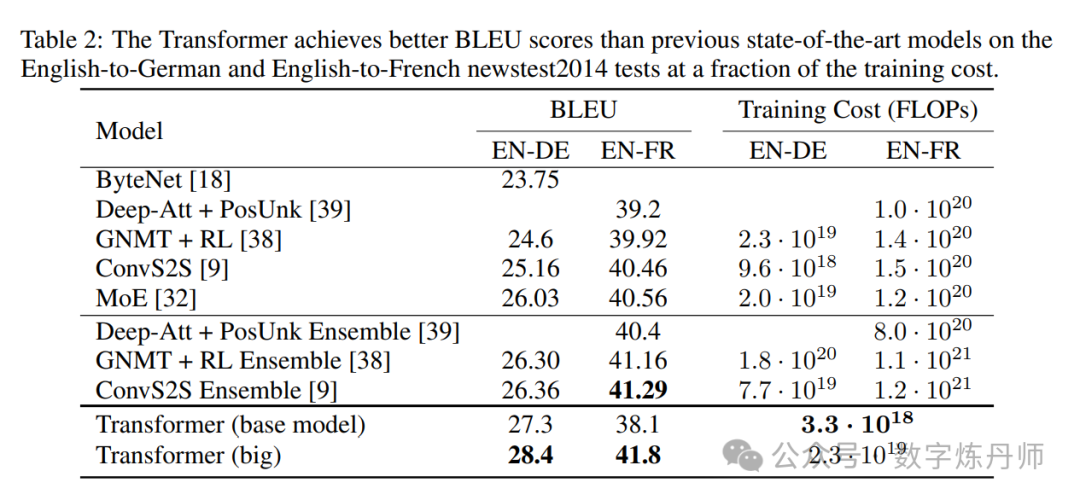
在 2014 年的 WMT 英德翻译任务中,大模型(下表中的 Transformer(big))比之前报道的最佳模型(包括集成模型)高出 2.0 以上的 BLEU 分数,达到了新的最佳 BLEU 得分 28.4。使用 8 块 P100 GPU 进行了 3.5 天的训练。即使我们的基础模型也超过了所有之前发表的模型和集成模型,并且其训练成本还不到任何竞争模型的一小部分。
结果(Model Variations)
为了评估Transformer不同组件的重要性,我们在不同的方式下改变了我们的基础模型,并测量了在英语到德语的翻译任务上性能的变化。
我们在下表中展示了这些结果。在下表行(A)中,我们改变了注意力头的数量和注意关键值维度,保持计算量恒定,虽然单头注意力比最佳设置差0.9 BLEU,但质量也会随着过多的头部而下降。
在下表行(B)中,我们观察到减少注意键大小dk会损害模型的质量。这表明确定兼容性并不容易,可能需要比点积更复杂的兼容函数来实现收益。
我们在行(C)和(D)中进一步观察到,正如预期的那样,更大的模型更好,并且dropout对于避免过拟合非常有帮助。在行(E)中,我们将正弦位置编码替换为学习的位置嵌入,并观察到与基线模型几乎相同的结果。

结果(English Constituency Parsing)
为了评估 Transformer 是否能够推广到其他任务,我们在英语句法分析任务上进行了实验。这项任务具有特殊挑战:输出受到强烈的结构约束,并且显著长于输入。此外,在小数据集上,RNN 序列到序列模型尚未取得最先进的结果。
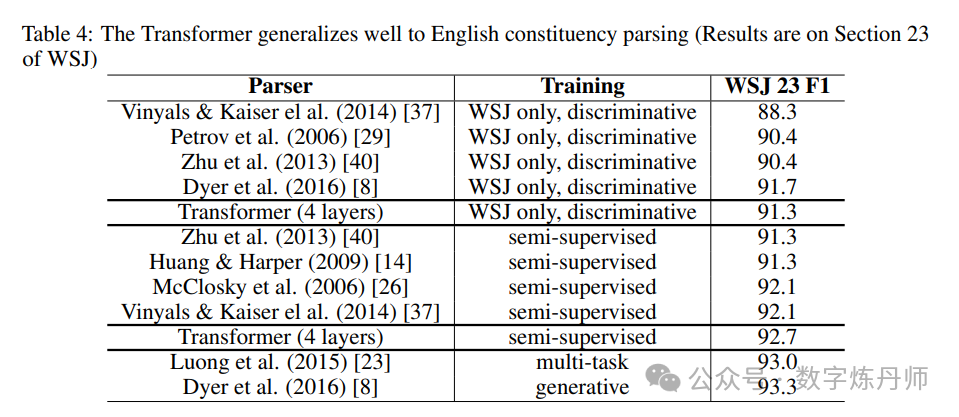
我们在 Wall Street Journal (WSJ) 部分的Penn Treebank 上训练了一个有四层transformer的模型,包含大约4万个训练句子。我们还在一个半监督设置中训练了它,使用来自约1700万条记录的大规模高置信度和BerkleyParser语料库。在仅针对 WSJ 的设置中,我们使用了16K个标记的词汇表,在半监督设置中,我们使用了32K个标记的词汇表。
如下表所示,尽管我们的模型没有针对特定任务进行微调,但它表现得非常出色。它产生的结果比之前报道的所有模型都要好,只有循环神经网络语法例外。
Transformer,这是第一个完全基于注意力的序列转换模型,在编解码器架构中用多头自注意替换最常用的递归层。对于翻译任务,与基于循环或卷积层的架构相比,Transformer可以训练得更快。在WMT 2014英语到德语和WMT 2014英语到法语的翻译任务上,我们都达到了新的最先进的水平。
AI大模型学习福利
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
四、AI大模型商业化落地方案

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

