
- 1android前台服务_android 怎么停止前台服务
- 2中介分析(三):R语言实现多重中介分析_r语言中介分析代码
- 3PX4使用yolo仿真环境搭建_px4yolov5仿真
- 4Git版本管理工具使用知识汇总_config-conventional length
- 5Android控件篇 实时显示时间控件 【TextClock】_android实时显示时间控件
- 6【ElasticSearch】RestClient查询文档_resthighlevelclient 查询文档
- 7工业机器人和PLC是什么关系_plc和机器人
- 8Alibaba Fastjson 入门详细教程_alibaba(2),面试Golang_com.alibaba.fastjson
- 9java算法原理
- 10计算机网络-PIM协议基础概念
Big Model Weekly | 第31期
赞
踩
点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!
01
Scaling Laws with Vocabulary: Larger Models Deserve Larger Vocabularies
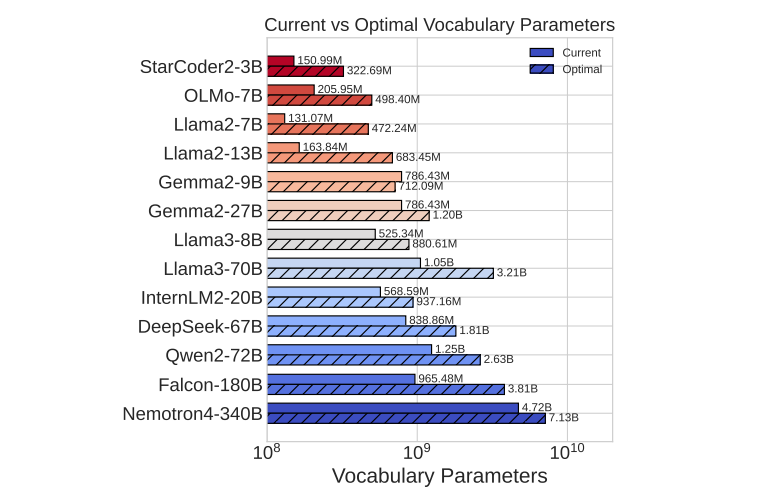
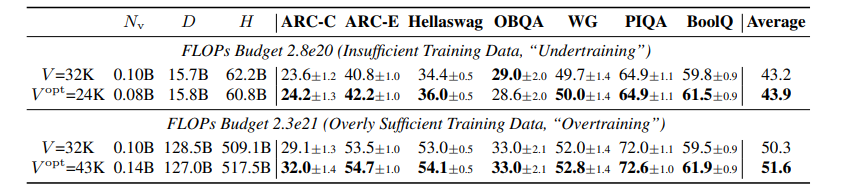
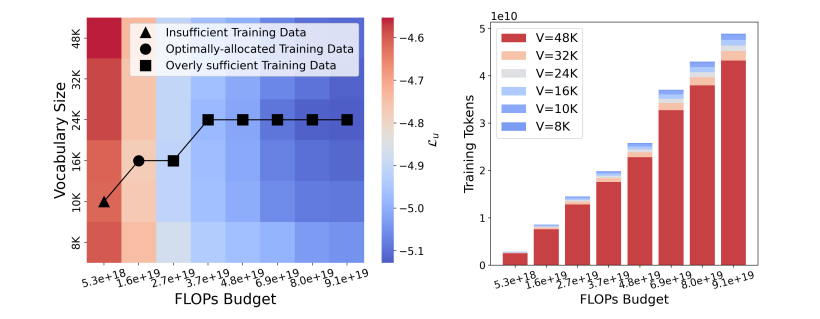
研究对大规模语言模型(LLMs)的扩展主要集中在模型参数和训练数据规模上,忽视了词汇量大小的作用。本文通过训练从3300万到30亿参数的模型,并使用高达5000亿字符的不同词汇配置,研究了词汇量大小如何影响LLM扩展法则。作者提出了三种互补的方法来预测计算最优的词汇量大小:等FLOPs分析、导数估计和损失函数的参数拟合。本文方法得出了相同的结果,即最优词汇量大小取决于可用的计算预算,并且更大的模型值得拥有更大的词汇量。然而,大多数LLMs使用的词汇量过小。例如,预测Llama2-70B的最优词汇量应该是至少21.6万,比其32K的词汇量大7倍。本文通过在不同的FLOPs预算下训练3B参数的模型,实证验证了预测。采用预测的最优词汇量大小,一致地改善了下游性能,超过了常用的词汇量大小。通过将词汇量从传统的32K增加到43K,在相同的2.3e21 FLOPs下,将ARC-Challenge的性能从29.1提高到32.0。该篇工作强调了同时考虑模型参数和词汇量大小对于有效扩展的必要性。
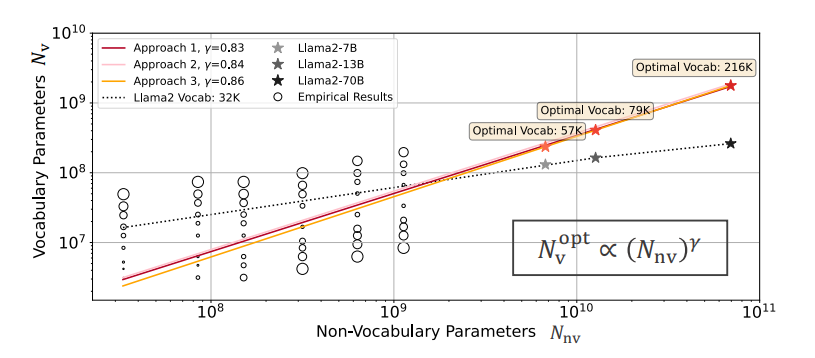
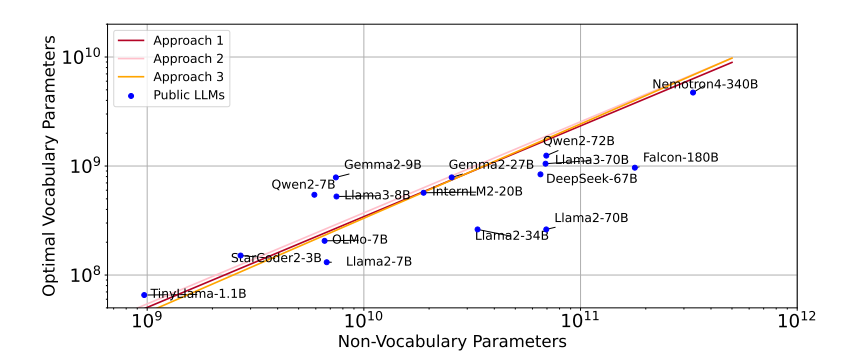
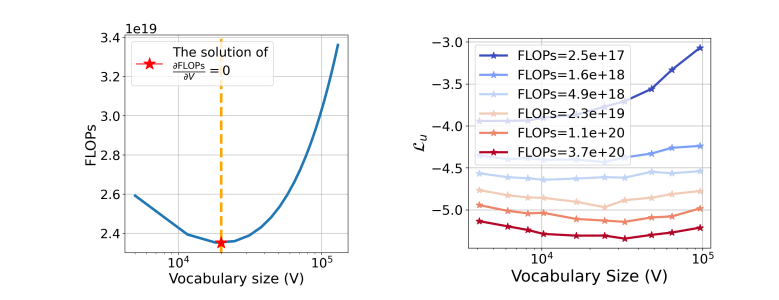
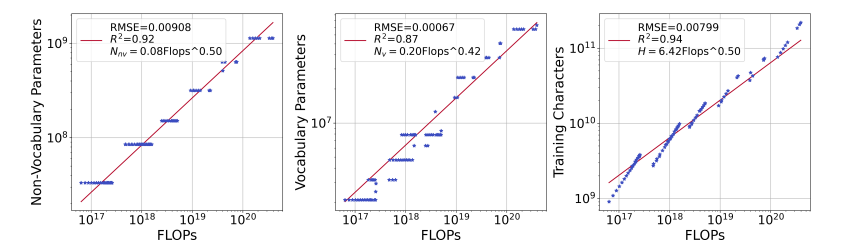
文章链接:
https://arxiv.org/pdf/2407.13623
02
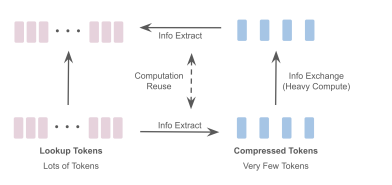
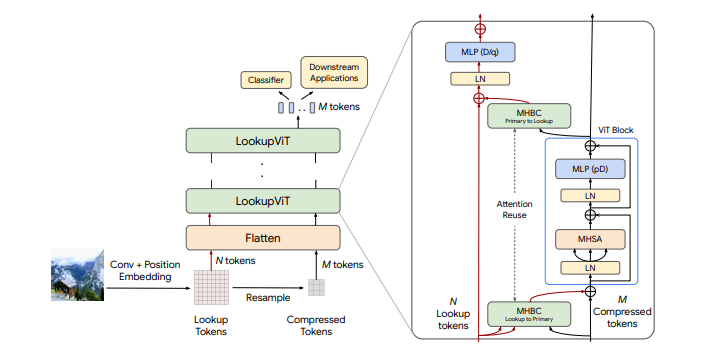
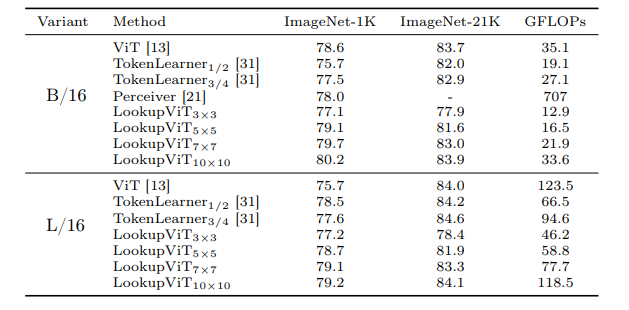
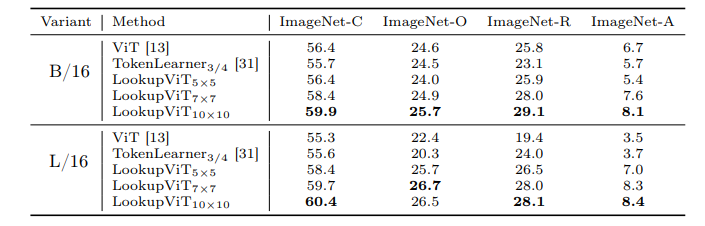
LookupViT: Compressing visual information to a limited number of tokens
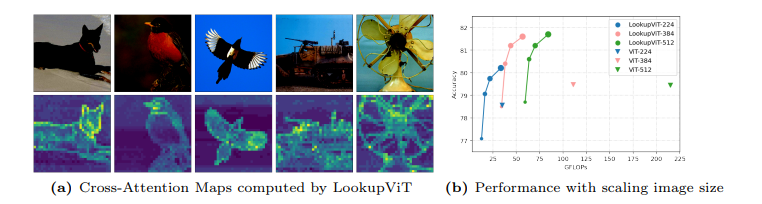
视觉变换器(ViT)已成为众多工业级视觉解决方案的实际选择。但是,它们的推理成本可能对许多设置来说过高,因为它们在每一层计算自注意力,这在令牌数量上具有二次计算复杂度。另一方面,图像中的空间信息和视频中的时空信息通常是稀疏和冗余的。这项工作引入了LookupViT,旨在利用这种信息稀疏性来降低ViT推理成本。LookupViT提供了一种新颖的通用视觉变换器模块,通过将高分辨率tokens中的信息压缩到固定数量的tokens来操作。这些少量压缩后的tokens经过精心处理,而高分辨率tokens则通过计算成本较低的层。通过双向交叉注意力机制,实现了这两组令牌之间的信息共享。这种方法提供了多重优势:(a) 易于在标准机器学习加速器(GPU/TPU)上通过标准高级操作实现,(b) 适用于标准ViT及其变体,因此可以推广到各种任务,(c) 可以处理不同的令牌化和注意力方法。LookupViT还为压缩tokens提供了灵活性,使单一训练模型能够在性能和计算之间进行权衡。本文在多个领域展示了LookupViT的有效性:(a) 图像分类(ImageNet-1K和ImageNet-21K),(b) 视频分类(Kinetics400和SomethingSomething V2),(c) 图像描述(COCO-Captions)使用冻结的编码器。LookupViT在这些领域提供了2倍的FLOPs减少,同时保持或提高了准确性。此外,LookupViT还展示了即开即用的鲁棒性和泛化能力,在图像分类(ImageNet-C,R,A,O)上提高了高达4%的性能,超过了ViT。

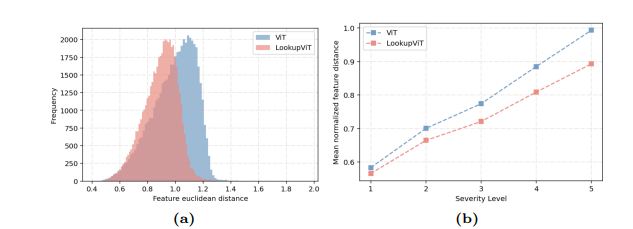
文章链接:
https://arxiv.org/pdf/2407.12753
03
Rethinking Video-Text Understanding: Retrieval from Counterfactually Augmented Data
最近的视频-文本基础模型在各种下游视频理解任务上展现出了强大的性能。这些视频-文本模型真的能够理解自然视频的内容吗?标准的视文评估可能会产生误导,因为许多问题仅从单个帧中的对象和上下文或数据集中固有的偏见就可以推断出来。本文旨在更好地评估当前视频-文本模型的能力并理解它们的局限性。作者提出了一种新颖的视频文本理解评估任务,即从反事实增强数据中检索(RCAD),以及一个新的Feint6K数据集。为了在新评估任务上取得成功,模型必须通过跨帧推理来获得对视频的全面理解。分析表明,先前的视频文本基础模型可以被反事实增强数据轻易愚弄,并且远远落后于人类级别的性能。为了缩小视频-文本模型与人类在RCAD上的性能差距,作者确定了当前视频-文本数据对比方法的一个关键限制,并引入了LLM-teacher,这是一种更有效的方法,通过利用从预训练的大型语言模型中获得的知识来学习动作语义。实验和分析表明,该方法成功地学习了更具区分性的动作嵌入,并在应用于多个视频-文本模型时在Feint6K上提高了结果。
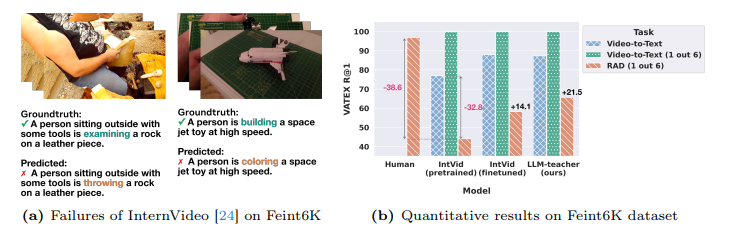
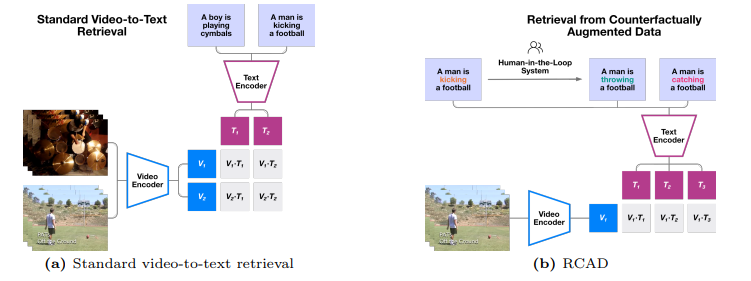

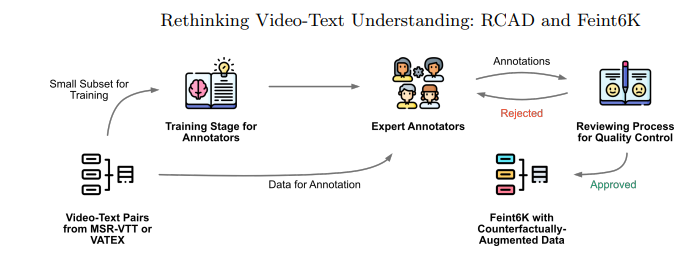
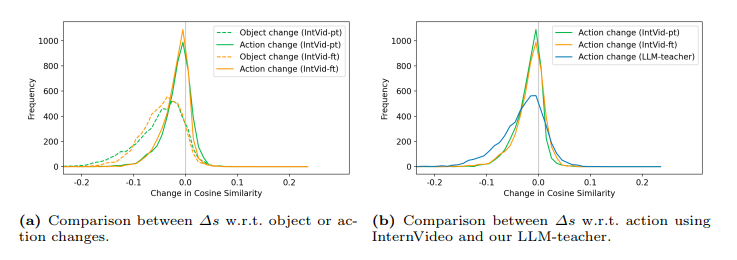
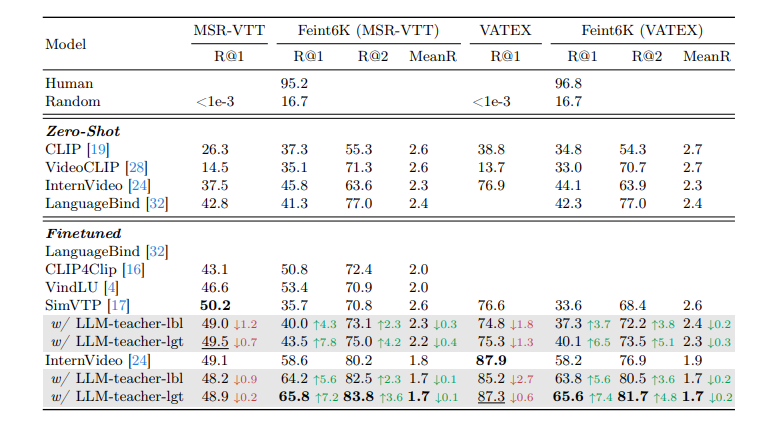
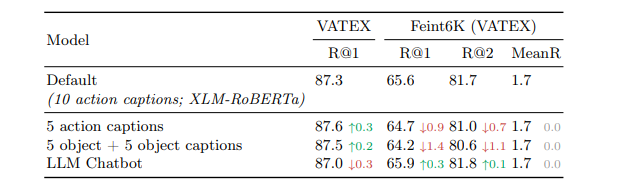
文章链接:
https://arxiv.org/pdf/2407.13094
04
E5-V: Universal Embeddings with Multimodal Large Language Models
多模态大型语言模型(MLLMs)在通用视觉和语言理解方面显示出了有希望的进步。然而,使用MLLMs表示多模态信息仍然大部分未被探索。这项工作引入了一个新框架E5-V,旨在适应MLLMs以实现通用多模态嵌入。本文的发现突出了MLLMs在表示多模态输入方面的显著潜力,与以往方法相比。通过使用提示的MLLMs,E5-V有效地弥合了不同类型输入之间的模态差距,即使没有微调,也展示了在多模态嵌入中的强性能。作者为E5-V提出了一种单一模态训练方法,其中模型仅在文本对上进行训练。这种方法在图像-文本对的传统多模态训练上显示出显著的改进,同时将训练成本降低了约95%。此外,这种方法消除了昂贵的多模态训练数据收集的需要。在四种类型的任务中的广泛实验证明了E5-V的有效性。作为一个通用的多模态模型,E5-V不仅实现了,而且经常超越了每个任务中的最新技术水平,尽管它是在单一模态上训练的。
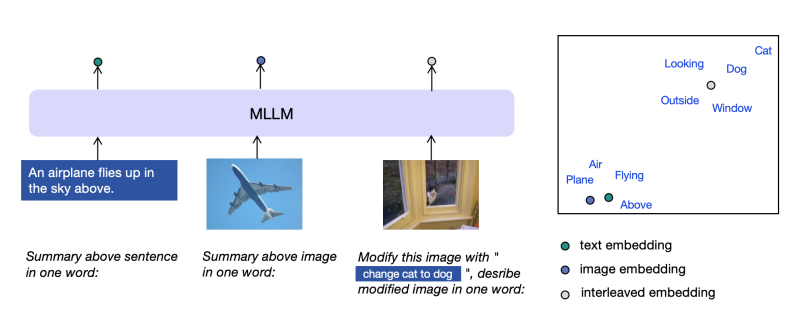
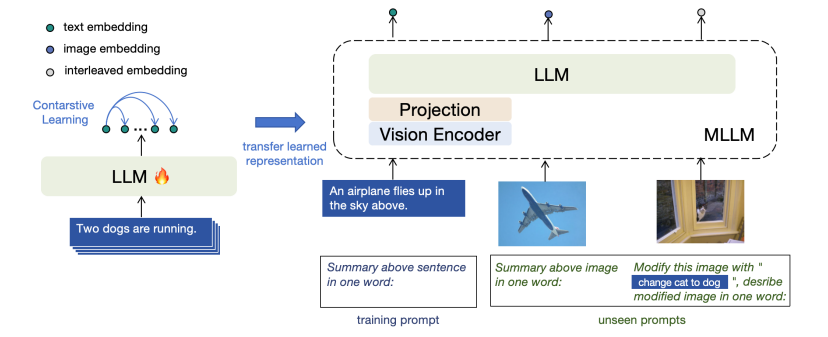
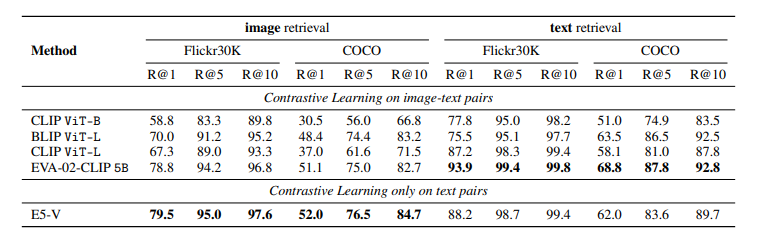
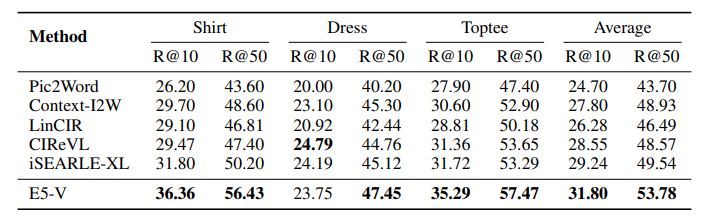
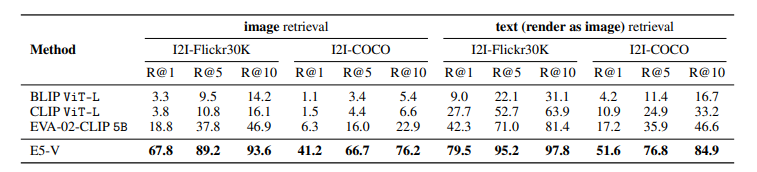

文章链接:
https://arxiv.org/pdf/2407.12580
05
Halu-J: Critique-Based Hallucination Judge
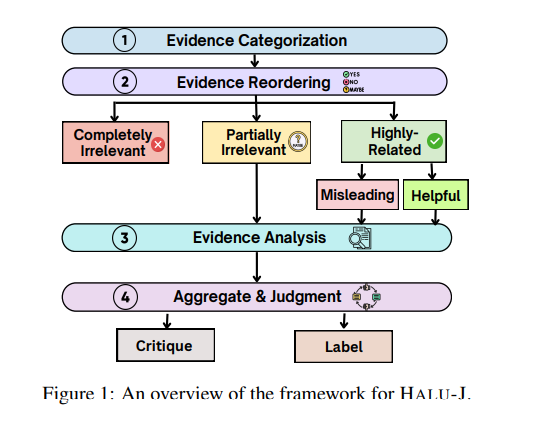
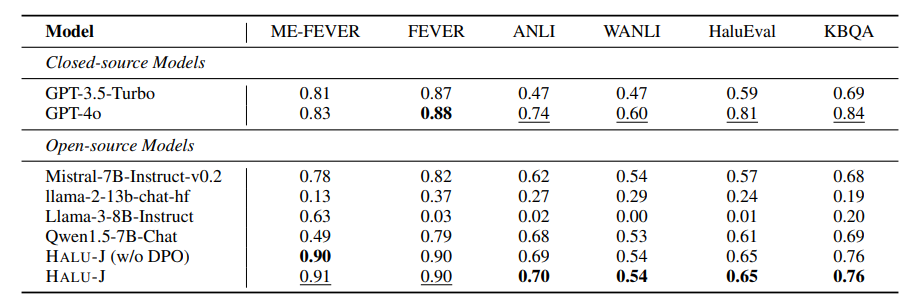
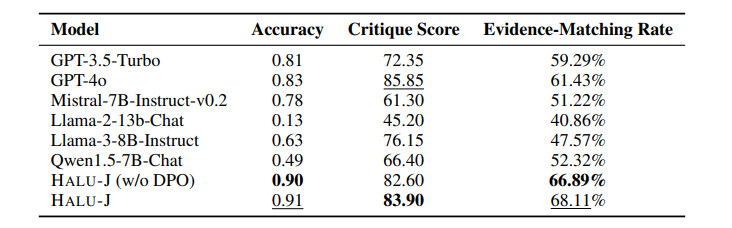
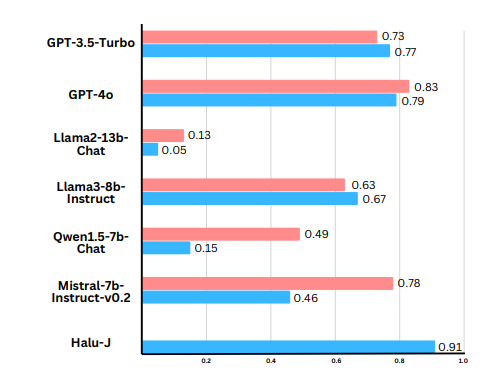
大型语言模型(LLMs)经常生成非事实内容,即所谓的幻觉。现有的基于检索增强的幻觉检测方法通常通过将其框架化为分类任务来解决这个问题,根据其与检索证据的一致性来评估幻觉。然而,这种方法通常缺乏对这些评估的详细解释,并且不评估这些解释的可靠性。此外,检索系统的不足可能导致检索到不相关或部分相关的证据,从而损害检测过程。而且,虽然现实世界的幻觉检测需要分析多件证据,但当前系统通常统一对待所有证据,不考虑其与内容的相关性。为了应对这些挑战,本文引入了HALU-J,一个具有70亿参数的基于批评的幻觉裁判。HALU-J通过选择相关证据并提供详细批评来增强幻觉检测。实验表明,HALU-J在多证据幻觉检测中的表现优于GPT-4o,并在批评生成和证据选择方面与其能力相匹配。本文还引入了ME-FEVER,一个为多证据幻觉检测设计的新数据集。

文章链接:
https://arxiv.org/pdf/2407.12943
06
Understanding Reference Policies in Direct Preference Optimization
直接偏好优化(DPO)已成为用于大型语言模型(LLMs)指令微调的广泛使用的培训方法。这项工作探索了DPO的一个研究不足的方面——它对参考模型或策略的依赖性。这些参考策略通常被具体化为需要进一步微调的模型,它们很重要,因为它们可以对DPO的有效性施加上限。因此,这项工作中解决了三个相关研究问题。首先,作者探索了DPO中KL散度约束的最优强度,该约束惩罚偏离参考策略的行为,并发现DPO对这种强度很敏感。接下来,作者通过提供DPO与相关学习目标之间的理论和实证比较,检验了参考策略对指令微调的必要性,展示了DPO的优越性。此外,作者还研究了DPO是否从更强的参考策略中受益,发现更强的参考策略可以带来改进的性能,但只有在它与正在微调的模型相似时。本文发现突出了参考策略在DPO中的混淆作用,并为最佳实践提供了见解,同时也确定了未来研究的开放性问题。
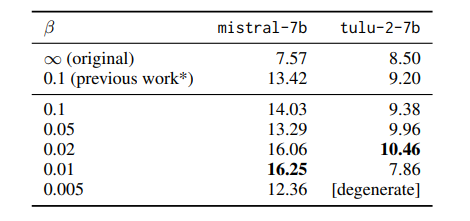
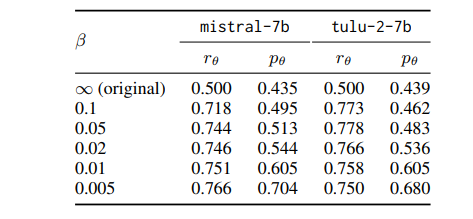
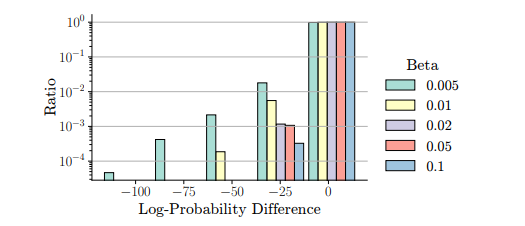
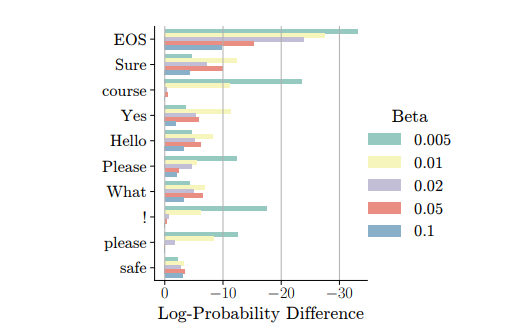
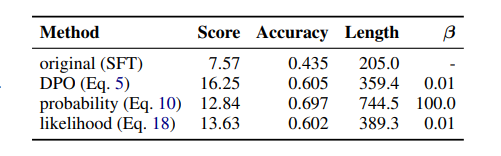
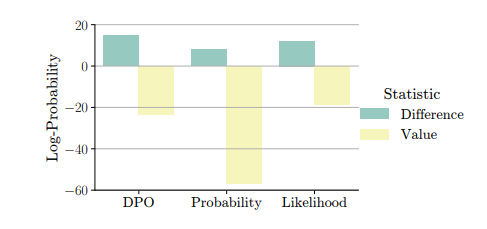
文章链接:
https://arxiv.org/pdf/2407.13709
07
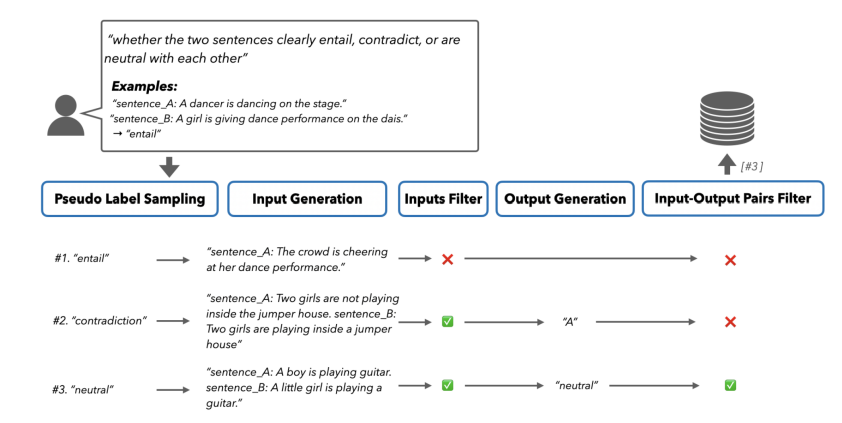
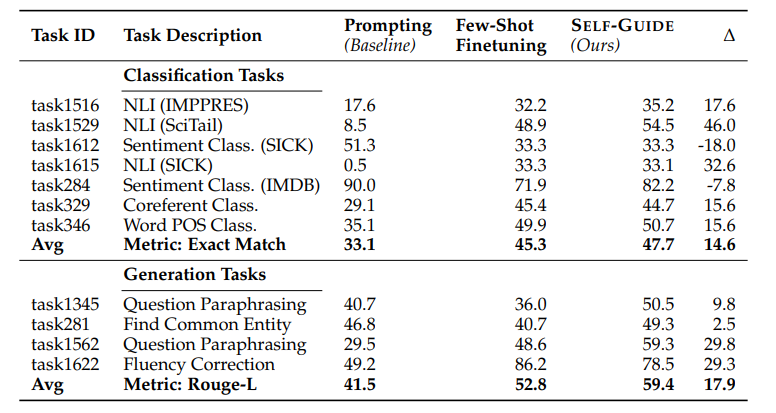
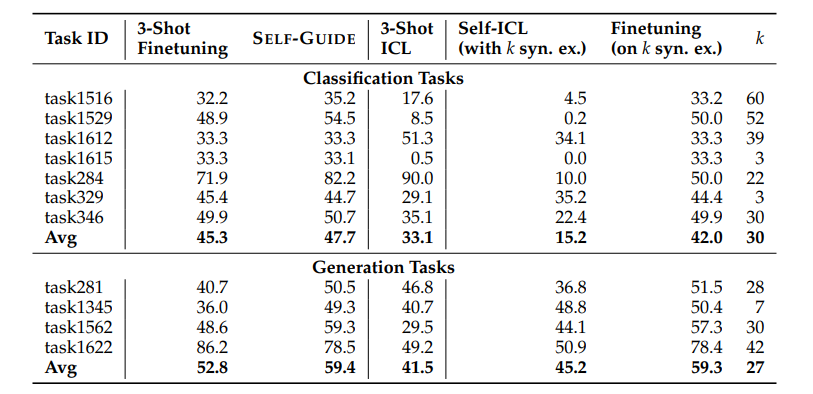
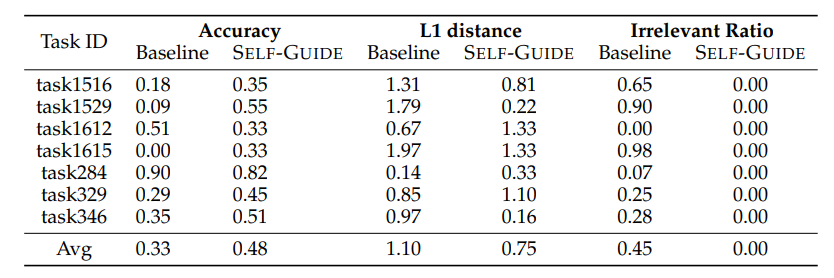
SELF-GUIDE: Better Task-Specific Instruction Following via Self-Synthetic Finetuning
大型语言模型(LLMs)在提供适当的自然语言提示时,有望解决多样化的任务。然而,提示通常会导致模型的预测准确度低于使用大量训练数据进行微调的模型。另一方面,虽然针对特定任务对LLMs进行微调通常会提高它们的表现,但并不是所有任务都有充足的标注数据集可用。以前的工作探索了从最先进的LLMs生成任务特定数据,并使用这些数据来微调较小的模型,但这种方法需要访问正在训练之外的语言模型,这引入了成本、可扩展性挑战以及与持续依赖更强大的LLMs相关的法律障碍。为了应对这些问题,本文提出了SELF-GUIDE,这是一个多阶段机制,作者从学生LLM合成任务特定的输入-输出对,然后使用这些输入-输出对来微调学生LLM本身。在对Natural Instructions V2基准的实证评估中,作者发现SELF-GUIDE显著提高了LLM的性能。具体来说,本文在基准指标中报告了分类任务大约15%的绝对改进和生成任务18%的绝对改进。这揭示了自我合成数据引导LLMs成为特定任务专家的希望,而无需任何外部学习信号。
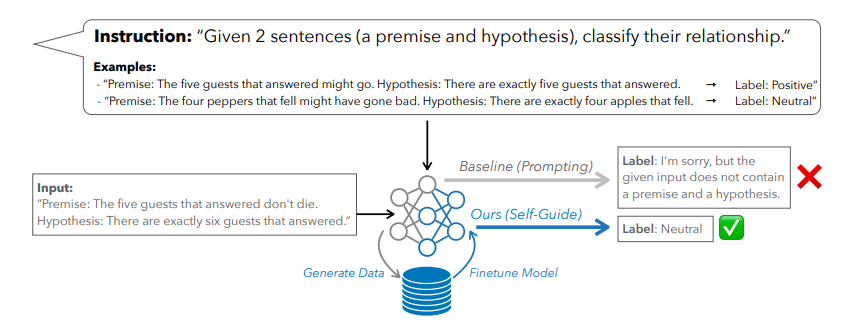
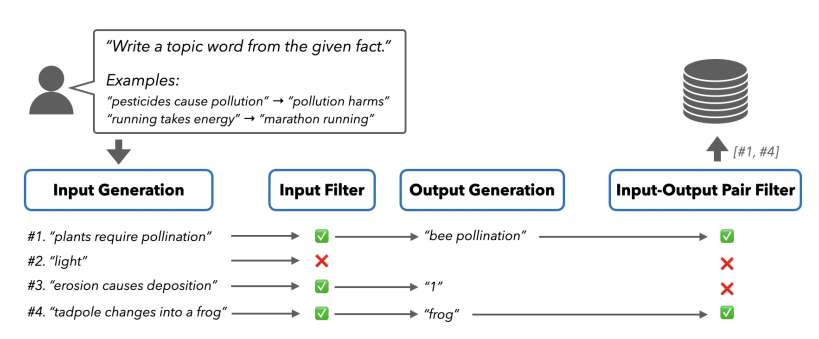
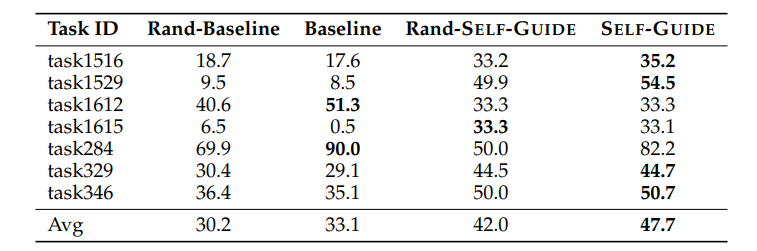
文章链接:
https://arxiv.org/pdf/2407.12874
本期文章由陈研整理
往期精彩文章推荐

记得关注我们呀!每天都有新知识!
关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了1800多位海内外讲者,举办了逾600场活动,超700万人次观看。

我知道你
在看
欢迎讨论,期待你的
留言

点击 阅读原文 查看更多!

