
- 12024.8.20 Python,链表,二叉树
- 2linux的静态ip配置之ping不通外网找了n久_linux 固定ip后无法ping百度
- 3IDEA使用Git插件提交代码缓慢(正在执行代码分析)_为啥我得idea上传代码总分析代码
- 4python 字符串 f_Python格式化字符串(f,F,format,%)
- 5Python Q-learning 算法 --2023博客之星候选--城市赛道_python double q-learning
- 6OWASP发布大语言模型网络安全与治理清单_owasp llm top 10
- 7第一问 ARM和单片机有什么区别?_单片机和arm的区别
- 8Java项目硅谷课堂学习笔记-P6整合腾讯云对象存储和课程分类管理_腾讯云文件存储整合java
- 9你和艺术家之间差个AI!如何向AI绘图发出正确指令?Midjourney+SD案例展示汇总!_ai设计图片如何写指令
- 10docker的inspect使用方法_docker inspect --format 驱动graphdriver.name
利用Transformer进行端到端的目标检测及跟踪(附源代码)_transformer做目标检测
赞
踩

现存的用检测跟踪的方法采用简单的heuristics,如空间或外观相似性。这些方法,尽管其共性,但过于简单,不足以建模复杂的变化,如通过遮挡跟踪。
1、简要
多目标跟踪(MOT)任务的关键挑战是跟踪目标下的时间建模。现存的用检测跟踪的方法采用简单的heuristics,如空间或外观相似性。这些方法,尽管其共性,但过于简单,不足以建模复杂的变化,如通过遮挡跟踪。所以现有的方法缺乏从数据中学习时间变化的能力。

在今天分享中,研究者提出了第一个完全端到端多目标跟踪框架MOTR。它学习了模拟目标的长距离时间变化。它隐式地执行时间关联,并避免了以前的显式启发式方法。MOTR建立在TRansformer和DETR之上,引入了“跟踪查询”的概念。每个跟踪查询都会模拟一个目标的整个跟踪。逐帧传输和更新,以无缝地执行目标检测和跟踪。提出了时间聚合网络(Temporal aggregation network)结合多框架训练来建模长期时间关系。实验结果表明,MOTR达到了最先进的性能。
2、简单背景
多目标跟踪(MOT)是一种视觉目标检测,其任务不仅是定位每一帧中的所有目标,而且还可以预测这些目标在整个视频序列中的运动轨迹。这个问题具有挑战性,因为每一帧中的目标可能会在pool environment中被遮挡,而开发的跟踪器可能会受到长期和低速率跟踪的影响。这些复杂而多样的跟踪方案在设计MOT解决方案时带来了重大挑战。
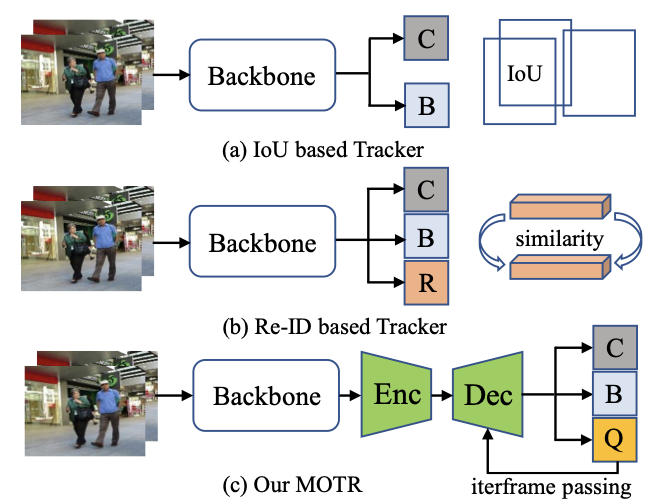
对于基于IoU的方法,计算从两个相邻帧检测到的检测框的IoU矩阵,重叠高于给定阈值的边界框与相同的身份相关联(见上图(a))。类似地,基于Re-ID的方法计算相邻帧的特征相似性,并将目标对与高相似性相关起来。此外,最近的一些工作还尝试了目标检测和重识别特征学习的联合训练(见上图(b))。
由于DETR的巨大成功,这项工作将“目标查询”的概念扩展到目标跟踪模型,在新框架中被称为跟踪查询。每个跟踪查询都负责预测一个目标的整个跟踪。如上图©,与分类和框回归分支并行,MOTR预测每一帧的跟踪查询集。
3、新框架分析
最近,DETR通过采用TRansformer成功地进行了目标检测。在DETR中,目标查询,一个固定数量的学习位置嵌入,表示一些可能的实例的建议。一个目标查询只对应于一个使用bipartite matching的对象。考虑到DETR中存在的高复杂性和慢收敛问题,Deformable DETR用多尺度deformable attention取代了self-attention。为了展示目标查询如何通过解码器与特征交互,研究者重新制定了Deformable DETR的解码器。
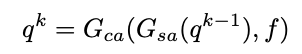
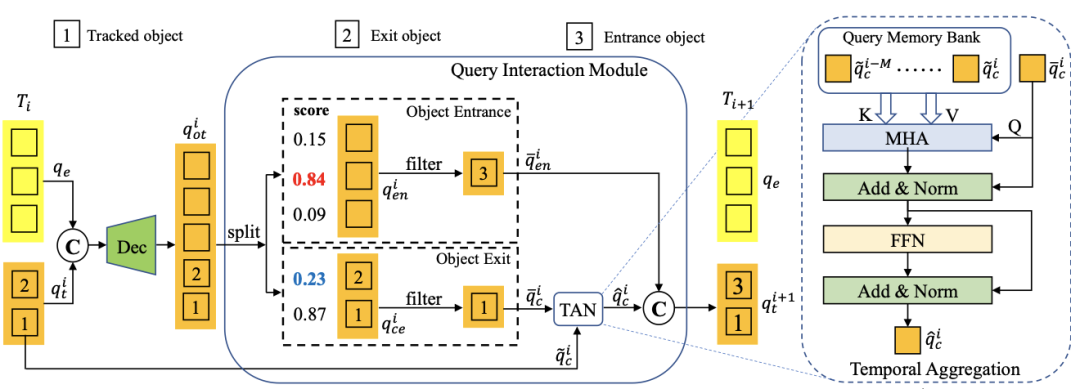
MOTR
在MOTR中,研究者引入了跟踪查询和连续查询传递,以完全端到端的方式执行跟踪预测。进一步提出了时间聚合网络来增强多帧的时间信息。
DETR中引入的目标(检测)查询不负责对特定目标的预测。因此,一个目标查询可以随着输入图像的变化而预测不同的目标。当在MOT数据集的示例上使用DETR检测器时,如上图(a),相同检测查询(绿色目标查询)预测两个不同帧预测两个不同的目标。因此,很难通过目标查询的身份来将检测预测作为跟踪值联系起来。作为一种补救措施,研究者将目标查询扩展到目标跟踪模型,即跟踪查询。在新的设计中,每个轨迹查询都负责预测一个目标的整个轨迹。一旦跟踪查询与帧中的一个目标匹配,它总是预测目标,直到目标消失(见上图(b))。
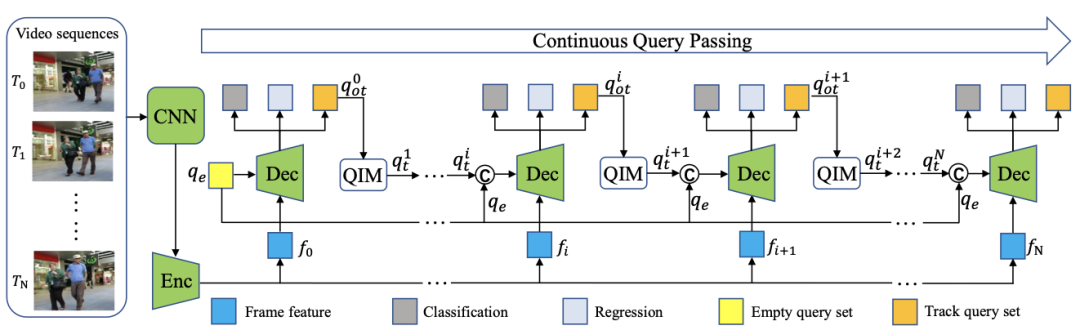
Overall architecture of the proposed MOTR
Query Interaction Module
在训练阶段,可以基于对bipartite matching的GTs的监督来实现跟踪查询的学习。而对于推断,研究者使用预测的轨迹分数来确定轨道何时出现和消失。
Overall Optimization
我们详细描述下MOTR的训练过程。给定一个视频序列作为输入,训练损失,即track loss,是逐帧计算和逐帧生成的预测。总track loss是由训练样本上的所有GT的数量归一化的所有帧的track loss的总和:
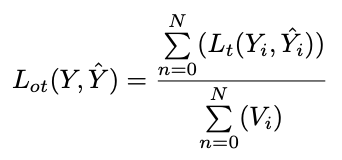
单帧图像Lt的track loss可表示为:
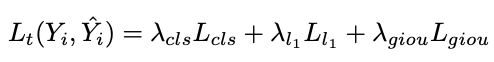
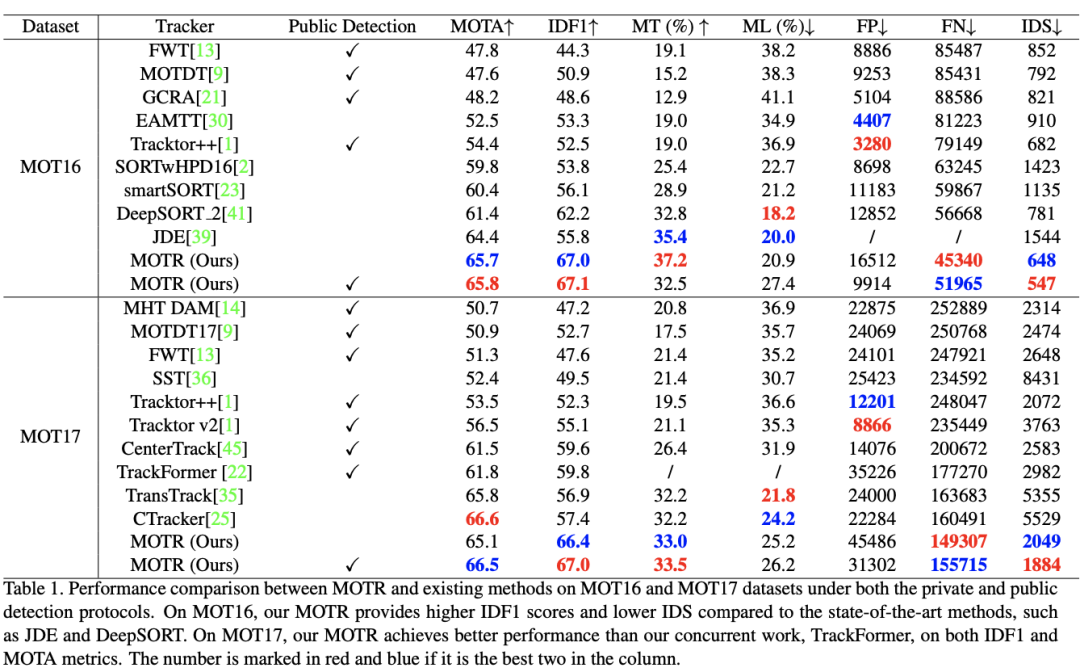
4、实验
Implementation Details
All the experiments are conducted on PyTorch with 8 Tesla V100 GPUs. We use the Deformable-DETR with ResNet50 as our basic network. The basic network is pretrained on the COCO detection dataset. We train our model with the AdamW optimizer for total 200 epochs with the initial learning rate of 2.0 · 10−4. The learning rate decays to 2.0 · 10−5 at 150 epochs. The batch size is set to 1 and each batch contains 5 frames.

The effect of multi-frame continuous query passing on solving ID switch problem. When the length of video sequence is set to two (top), the objects that are occluded will miss and switch the identity. When improving the video sequence length from two to five (bottom), the track will not occur the ID switch problem with the help of enhanced temporal relation.

如何学习大模型
现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
我已将重要的AI大模型资料包括市面上AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。

二、AI大模型视频教程

三、AI大模型各大学习书籍

四、AI大模型各大场景实战案例

五、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。

